
《TAO: Facebook’s Distributed Data Store for the Social Graph》论文阅读
TAO(The Associations and Objects)是Facebook的社交图谱存储系统,作为一个经典的早期图存储方案,其中对于性能和一致性的设计,值得我们学习和借鉴
本文将按照以下几个方面透彻介绍TAO的方方面面
一、Background
TAO是一个有Facebook研发的图存储系统
- 分布式的,运行在成千上万台机器上
- 存储量巨大,维护PB级别的数据
- 性能优越,适合读多写少的场景,提供十亿级别的读 + 百万级别的写
1.诞生的背景
- Facebook的社交图谱一开始采用 MySQL + memcache 架构
- 优点是
- lookaside cache 架构很适合快速迭代周期,因为client能够很快调整memcache的cache数据
- 在上述的使用过程中,逐步抽象除了边和点的图模型,但也遇到了很多问题
- PHP API的封装失败
- 支持非PHP访问
- memcache的kv模型,使边列表维护在1个kv,更新和查询有严重的读写放大
- Cache的维护逻辑分布在各个client端,使得cache维护低效
- 写后读的一致性难以维护
- 因此,我们想要重新设计系统架构,满足Facebook对社交图谱的需求
2.设计目标
- 多region部署
- 保证极高读性能
- 不要求很强的一致性
二、Data Model and API
Model
- 异构属性有向图
- 点由int64的id唯一确定,边由起点,终点和type唯一确定
- 属性有schema,规定有哪些key,value是什么类型
- 边有时间戳
- 支持自动创建反向边,不保证原子性
API
-
assoc add(id1, atype, id2, time, (k→v)*)
-
assoc delete(id1, atype, id2)
-
assoc change type(id1, atype, id2, newtype)
-
assoc get(id1, atype, id2set, high?, low?)
-
assoc count(id1, atype)
-
assoc range(id1, atype, pos, limit)
-
assoc time range(id1, atype, high, low, limit)
-
边查询每次有上限,通过多次查询获取所有边
三、Architecture
1.架构图
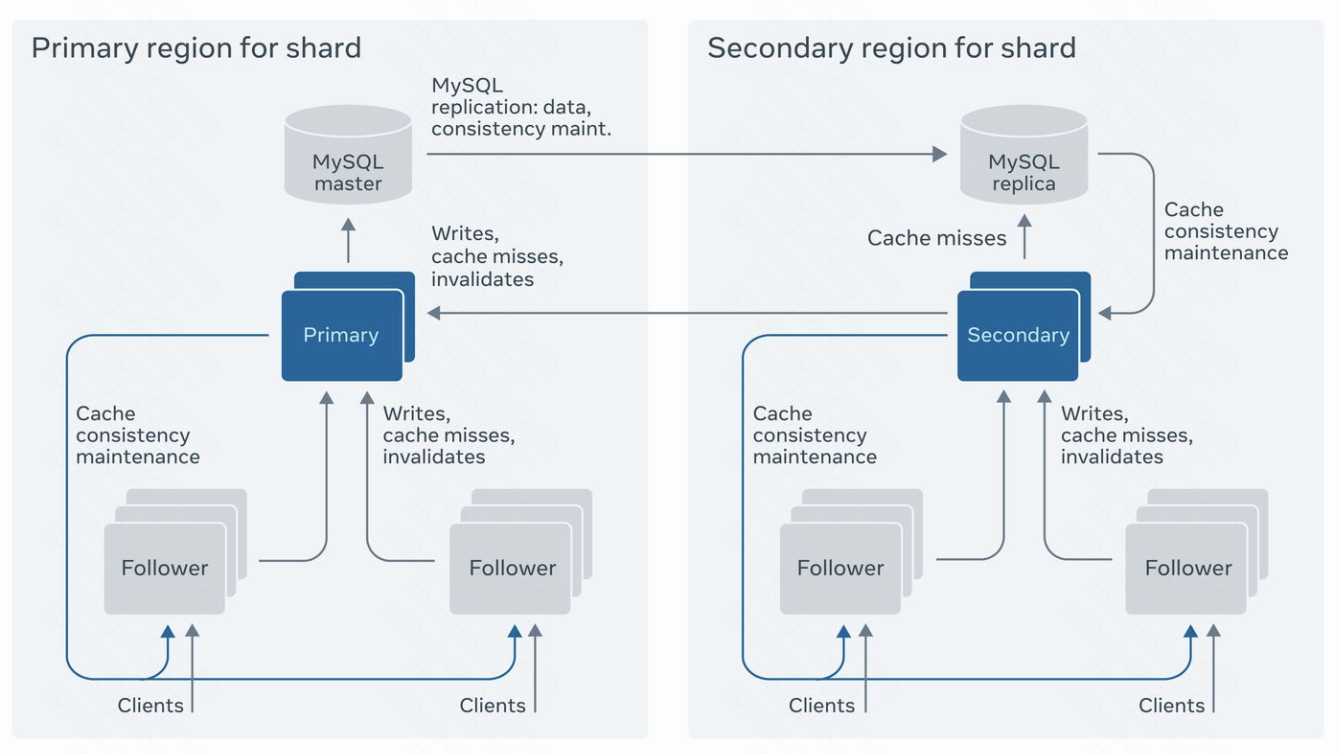
- 1层持久化存储层 + 2层cache层
2.持久化存储层
- 历史原因,使用MySQL
- 考虑因素
- 数据备份
- 批量导入、删除
- 副本创建
- 异步备份
- 一致性监控工具
- 运维debug
- 事务
- 数据分布在很多个逻辑shard内,每个逻辑shard由一个逻辑database维护
- Database Server 维护一个或者多个shard
- shard远多于Server数量,便于shard在Server间负载均衡
- 所有边在1个table,所有点在1个table
- 点的id含有shard id,不会改变
- 边的shard id等于起点的shard id,便于查询所有出边
3.Cache 层
- Cache层包含很多个cache servers,称为tier,接受request
- client 发 request 到 cache server,该cache server就负责这个request,遇到写或者cache miss,就访问database
- Cache层存边列表,点和边数量;使用LRUcache
- 写反向边可能涉及到两个shard
- 本Server发送rpc到 另一个shard 的cache server
- 另一个shard 的cache server,访问database写边
- 另一个shard 写完,本Server访问database写边
- 不保证两个边的原子性,有后台进程校验
- cache server太多也会有问题
- 更容易出现热点
- 连接会更多
- 2层cache
- 1个leader
- 每个shard对应1个leader cache server
- 负责该shard 的写和读database
- 多个follower
- 发送cache miss和写请求到leader
- client只能和follower交互
- cache 一致性
- 最终一致性
- 一个shard 一个leader,leader负责写,天然一致,follower 需要被其他follower 通知更新
- leader的写,会异步发送invalid信息到多有follower;发送该写的follower,会伴随写返回同步更新
- leader对该shard的读写请求进行限流
- 1个leader
4.多region部署
- follower的个数,拓展了集群的读性能;当follower部署在距离较远的位置时,网络成为瓶颈
- 由于cache miss比写请求大25倍,采用master slave架构
- 写由master负责,数据同步是异步的
- 读可以有本地slave负责
- 每个region一个完整数据副本
- follower在每个region内,把cache miss 和 写发送给本地leader
- 本地leader读本地,读延时和region间延时无关
- 本地leader发送写到master database,写失败会返回给client
- 每个shard 的master在region间failover
- master都在一个region更方便,因为写反向边不用跨region
- master的写数据log同步到slaver之后,master发送invalid和refill给cache server
- 发送早了会使cache server读到本地的旧数据
- 发送写请求到master的cache server会受到两个invalid
- 一次是写成功
- 一次是master异步同步数据
三、Implementation
1.Cache设计
- 线程安全的hash table
- LRU
- 把RAM分成多个arenas,通过边或点的type确定arena
- 延长重要type的arena的生命周期
- 其他优化等
2.MySQL
- 边一个table,点一个table
- 点的属性序列化成一个string,存在一个字段
- 边的属性序列化成一个string,存在一个字段;对起点,边type,时间建索引
- 边数存在另一个table
3.Sharding and hot spots
- 在cache server之前,有一个一致性哈希层,方便拓展和路由,但可能负载不均衡
- 通过调节follower的数量负载均衡,一致性信息发送给所有follower
- cache server返回client结果时,带上cache 命中率和版本号;下一次请求时,如果命中率超过阈值,版本号没变,使用client本地数据
4.High-Degree Objects
- 不cache所有边列表
- 查询一条边时,经查访问database
- 通过获取边数量,控制查询方向,避免超级节点
- 根据时间,判断边是否存在,缩小边列表范围
四、 Consistency and Fault Tolerance
1.一致性
- 优先可用性和性能,牺牲一致性 -> 最终一致性
- 写成功后,会发送invalid和refill到所有server
- 写成功后,本次cache server会根据返回结果自动更新
- 如果写双向边,写成功的返回结果会带有两个边的结果,本地server,需要把写成功结果发送反向边的server
- 数据持久化版本号,每次写递增,防止本地更新错误
- 如果本地database数据比server旧,server cache失效后将读到旧数据,但不常见
- 写同步更新到slave,可以保证更好的一致性
2.容灾
检测
- 超时,连续超时认为失联,避免向其发送请求
- 检测合适恢复
Database failure
- 宕机或者数据太久
- master宕机,slaver成为new master
- slave宕机
- cache miss发送至master 的leader
- master持久化binlog,invalid信息依旧同步到region
- slave重启之后,apply binlog
Leader failures
- Cache miss直接访问database
- 写发送至随机的leader,这个leader完全替代原leader的作用,并持久化binlog
- leader重启之后,apply binlog
Refill and invalidation failures
- follower长时间失联后,可以考虑失效大量数据
- leader被替换后,follower的数据应该全部失效
Follower failures
- 重新添加一个follower即可
- 但是换follower可能导致写后读不一致

 浙公网安备 33010602011771号
浙公网安备 33010602011771号