
《A1 A Distributed In-Memory Graph Database》论文阅读
A1是微软的一篇SIGMOD 2020年“分布式内存图数据库”的论文,其中关于图系统的讨论,以及新技术的运用,值得我们学习和借鉴
本文将按照以下几个方面透彻介绍A1的方方面面
一、Background
1.历史背景
- 有钱 : 便宜的DRAM
- 有技术:商业应用的RDMA
- bypass local kernel
- bypass remote CPU
- tcp中可靠传输和拥塞控制特性,由网卡、交换机实现
- 利用unreliable datagrams (UD) 进行时钟同步
2.技术背景
FaRM 微软在2014年发表了《FaRM: Fast Remote Memorys》
特征
- 线性一致性
- 支持事务
- 支持生成索引
- 提供基本数据结构,如BTree
架构设计
- 主从同步,3副本设计
- 2PC,支持事务
- MVCC实现线性一致性
- 一群运行FaRM进程的机器 + Configuration Manager(负责机器管理 + data placement(可以理解为MMU))
- 每2G内存作为一个region,每个region一个ID
- 可申请并管理 64B - 1M 的object,由64位寻址,32位为region id,32位为region offset
API
- alloc:带有hint参数
- 默认参数本机申请内存
- hint为别的object的地址时,则尽量在一个region
- read
- write
- free


二、System Structure
1.架构图

- 后4层: FaRM
- 前面几层: 定义图的数据结构,定义查询引擎
2.设计原则
- 多用指针
- 如链表,BTree等
- 只存有用数据
- 例如不存图片等信息
- 关注位置
- 可能一起访问的数据存在一台机器
- 处理某个节点时,到相应的机器上处理
- realloc的时候传递旧地址
- 高并发
- 避免热点
3.实际部署方式
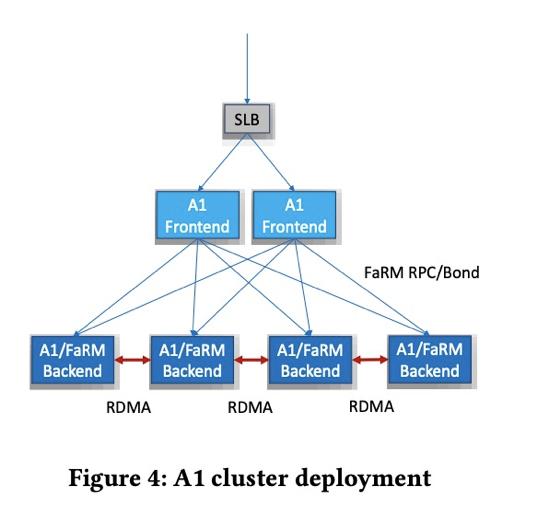
- SLB(Software Load balancer)
- 负载均衡
- Frontend
- 路由
- 限流
- Backend
- 执行查询
- 数据处理等
三、 Data structure and query engine
1.点和边的定义
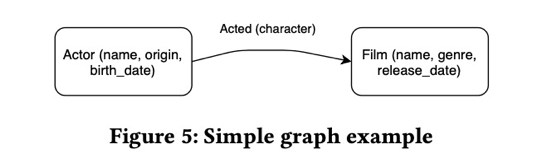
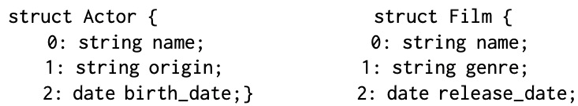
如上图,点和边具有一些相同的定义
- 异构图,必须有type
- 属性图,可以定义kv属性,v的类型多样
- 第二张图片可以理解为pb
- 此pb支持的数据类型有int float string等基本类型,数组 map等类型,同时支持嵌套
点的多出限制
- 必须有主键,非空且唯一
- 由type + primary key唯一标识
边的唯一标识
- src vertex + edge type + dst vertex
和传统数据库的类比如下
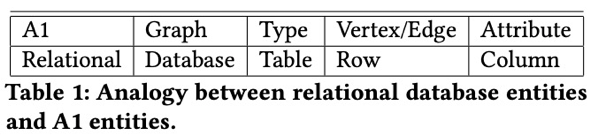
2.Catalog
作用
- 寻址全局变量
用法
- 是个map
- key为全局变量的name,value为该变量的64位地址
- 也存在FaRM
- 各个机器可以cache找到的数据,ttl后renew
例如
-
若要寻找全局BTree a
可以在 Catalog 中找到由key为a时的value,也即Btree a的64位地址,由此可以找到BTree的根节点
3.数据布局
点
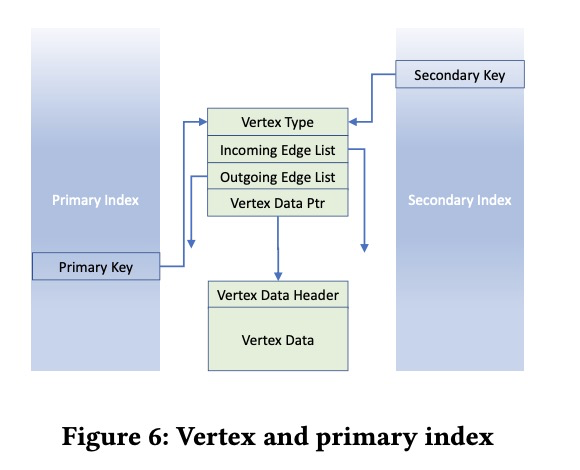
点的表示分为两部分
- 点指针
- 点的type
- 入边列表指针
- 出边列表指针
- 点的数据指针
- 点的数据指针
- 点的序列化后的数据
点可以由两种途径找到
- 索引找到
- 边的遍历过程中找到
边

普通节点
边的表示由两个半边组成:出边和入边,数据表示分为两部分
- 出边列表指针
- 边的type
- 入点的指针
- 边的数据指针
- 数据大小
- 由以上4项循环组成list
- 边的数据指针
- 边的序列化后的数据
边可以由一种途径找到
- 由点的出入边列表指针找到
点可以通过边找到
- 出边列表指针中包含入点的指针
超级节点
定义
- 代表边数超过1000条的边
方案
- 全部存在全局 BTree
- key是<src vertex pointer, edge type, dest vertex pointer>
- value是边的数据指针
4.Query
场景
- 读多写少
流程
- client 请求发到SLB,负载均衡
- SLB 转发给 frontend,路由和限流
- frontend 转发给 backend,处理请求
- 生成 logical plan
- 生成 physical plan
- 执行 physical plan
- 2PC:处理请求的 backend 作为 coordinator
- 写请求,本机利用RDMA去读写数据
- 读请求,分散计算到相应的机器,汇总所有的结果,类似Map Reduce
例如
查询和斯皮尔贝格合作的演员,可以有如下查询语句(A1自研的查询语言,为json格式)

查询的执行过程如下,为两跳查询
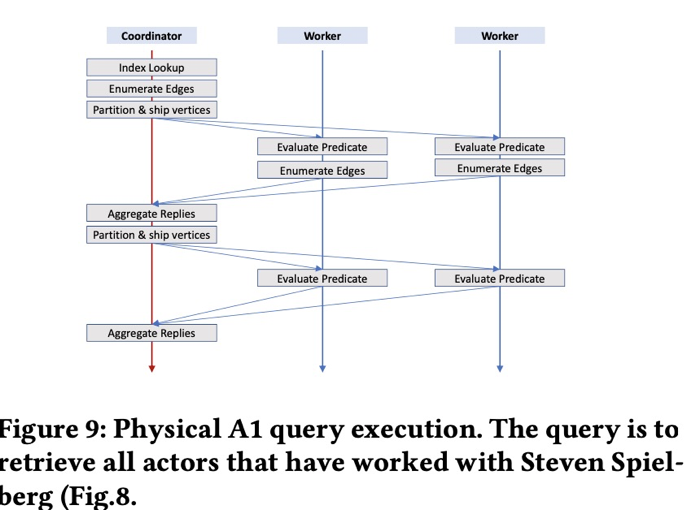
- 通过 index 找到起始点 (斯皮尔伯格)
- 通过 RDMA 读取点 (斯皮尔伯格) 的出边列表值,并在本地遍历 (点数较少时,在本地计算)
- 分散遍历得到的点 (斯皮尔伯格的电影) 到点所在的机器,进行 谓词运算 & 边的遍历 (点数较多时,分散计算)
- 汇总结果 (符合条件的演员)
- 分散上述结果 (符合条件的演员) 到点所在的机器,进行谓词运算 (反序列化,筛选等)
- 汇总结果,返回客户端,查询完成
四、 Disaster recovery
1.方案
- 三副本,主从同步 (需要参考FaRM实现)
- 持久化
2.实现
这里只提及持久化的实现
- 写WAL,WAL 也写在 FaRM 内存中,3副本
- update事务处理之前,写WAL
- update事务commit之后,把WAL异步apply到持久化存储中
- 有后台线程,按照FIFO顺序,及时apply WAL到持久化存储中
由此
- 内存有副本保留时,使用副本恢复
- 内存3副本均丢失时,使用持久化存储恢复
- 此时,永久丢失的数据就是还没有 apply 到持久化存储的 WAL
关于持久化存储
- 包含两个table
- vertex table 存储所有的点
- edge table 存储所有的边
3.恢复过程
当有内存副本时,因为主从强一致,所以我们使用内存副本恢复;故只考虑3内存副本均丢失,由持久化存储恢复的过程,包含两个恢复模式
-
consistent recovery
- 相对事务而言,事务一致
-
best-effort recovery
- 相对 graph 而言,图内数据一致
我们举个例子说明这个过程
存在事务:写入点A,写入点B,写入A到B的边,事务提交
当出现故障,3副本均丢失后,持久化存储中只有点A 和 A到B的边,没有点B
-
consistent recovery
- 为事务一致,删除点A 和 A到B的边
-
best-effort recovery
- 为图一致,因为B点不存在,删除 A到B的边,保留A点
-
由此可见,best-effort recovery 比 consistent recovery 更新
由于不同的恢复,对持久化数据有不同的要求
-
best-effort recovery
-
数据格式为 key -> value
-
Update由事务时间戳判断数据新旧
- 时间戳更新的数据 apply
- 时间戳更旧的数据 丢弃
- created无条件执行
- lazy删除
- 等待GC
- 或者重新创建
-
consistent recovery
-
数据格式为 key + ts -> value
- 持续持久化TR,代表当前未apply的log的最小时间戳,也表示小于该时间戳的数据,其所属事务均apply
- 恢复时,小于TR的数据形成事务一致性snapshot
4.优化
方案一:进程地址空间 和 存储数据地址空间 分离
- PyCo (a kernel driver) 在机器启动时,占据一块连续的内存,作为数据存储区域
- 在 FaRM 启动时,FaRM进程获取PyCo的地址空间,在此空间存取数据,逻辑上类似于把内存分为了 内存 + SSD的分布
- 由此,FaRM进程挂掉,并不影响本机数据,但不能防止机器挂掉
- CM监控进程故障
- 非所有副本进程故障时
- 重启FaRM进程,FaRM进程或获取PyCo的内存数据
- 有PyCo中的WAL,处理PyCo中未完成事务
- 所有副本进程故障时
- 暂停整个集群服务,此时不可用
- 等待重启进程,进行上述操作
- 非所有副本进程故障时
五、Performance evaluation
场景
- 数据规模
- 37亿个点,value序列化之后220B
- 62亿条边
- 机器规模
- 245台机器,由此 99.6% (244 / 245) 的点在其他机器
- 机器配置
- two Intel E5-2673 v3 2.4 GHz processors
- 128G DRAM,80G用于存储
- Mellanox Connect-X Pro NIC with 40Gbps bandwidth
- 集群位置
- 位于15个机架
- 4个T1交换机,连接所有机架
- client 和 cluster 在一个数据中心
测试一
- 查询和斯皮尔贝格合作的演员
- 2跳
- 1785次遍历结果,类似于放大

- delay 控制在 10ms 以内

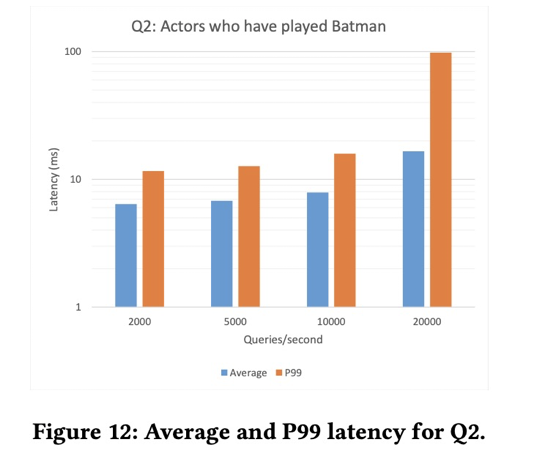
测试二
- 查询演过BatMan的演员
- 3跳

- delay也在10ms
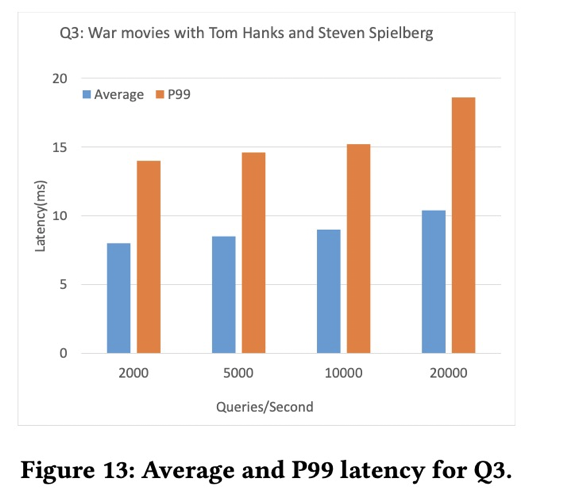
测试三
-
查询斯皮尔伯格导演,Tom Hanks参演的动作电影
-
3跳
-
含有筛选

-
-
delay也在10ms
RDMA测试
RDMA总延时和RDMA次数成正比

拓展性测试
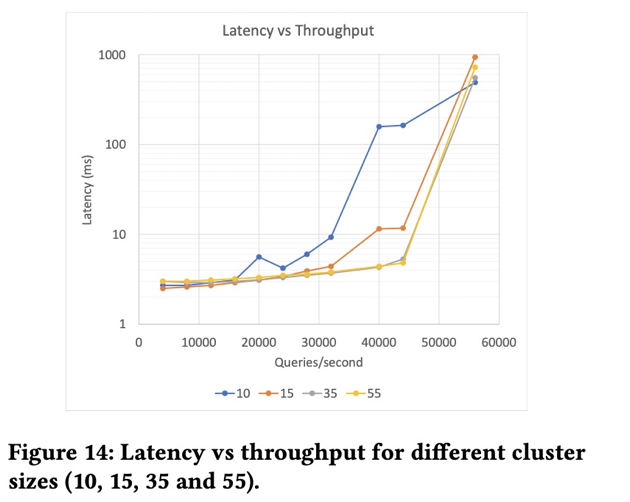
机器数目越多,delay平稳承受的qps越高
以上就是我对于A1主要内容的理解,如有不对之处,烦请批评指正
欢迎有兴趣的同学一起交流讨论

 浙公网安备 33010602011771号
浙公网安备 33010602011771号