
Frangipani: A Scalable Distributed File System 论文阅读
Frangipani是一篇1997年“分布式文件系统”的论文,其中关于缓存一致性,分布式事务和分布式故障恢复的简单并且优秀的设计思想,依旧值得我们学习和借鉴
本文将按照以下几个方面透彻介绍Frangipani的方方面面
一、Background
1.历史背景
- 在1997年,笔记本还不流行,主要是工作站,也就是一个带有键盘鼠标显示器和操作系统的计算机。
- 随着工作站用户和文件的不断增长,需要不断增加disk(当时的存储介质)和machine,以及大量的人工管理(运维)
- 作者们是一个研究所的成员,他们习惯于使用共享的基础设施,因此想让所有的工作站共享一个大容量的“disk”
2.技术背景
同作者在1996年发表了《Petal: Distributed virtual disks》
一个分布式shared disk,具有如下的特点:
- 1 << 64 的地址空间,需要实际存储时,才会分配实际存储资源
- 可增加数据副本,提高可用性
- 可在线生成snapshot
- 对外提供disk接口
由此,同作者想把Petal的特性,发挥到上层file system中,于是设计了Frangipani
Frangipani的设计feature包括
- 一致性:强一致(线性一致性)
- 拓展性:可透明的增加,去掉机器,尽量少的人工参与
- 容错性:可以failover
- 可在线生成snapshot
二、System Structure
1.架构图

有三种机器:
- mount Frangipani fs的机器
- Petal cluster的机器
- Lock Service的机器
三种机器,在不影响相互工作的情况下,理论上可以分布在任意机器上,并非图中那样的分布
比如,第一种和第二种机器可以是一台机器,第二种和第三种也不必在一台机器上
2.两层设计
- 上层:Frangipani file system
- 下层:Petal Shared disk
3.Frangipani file system
- 运行在kernel
- 作为一个fs实现,提供标准的文件系统接口
4.安全性考虑
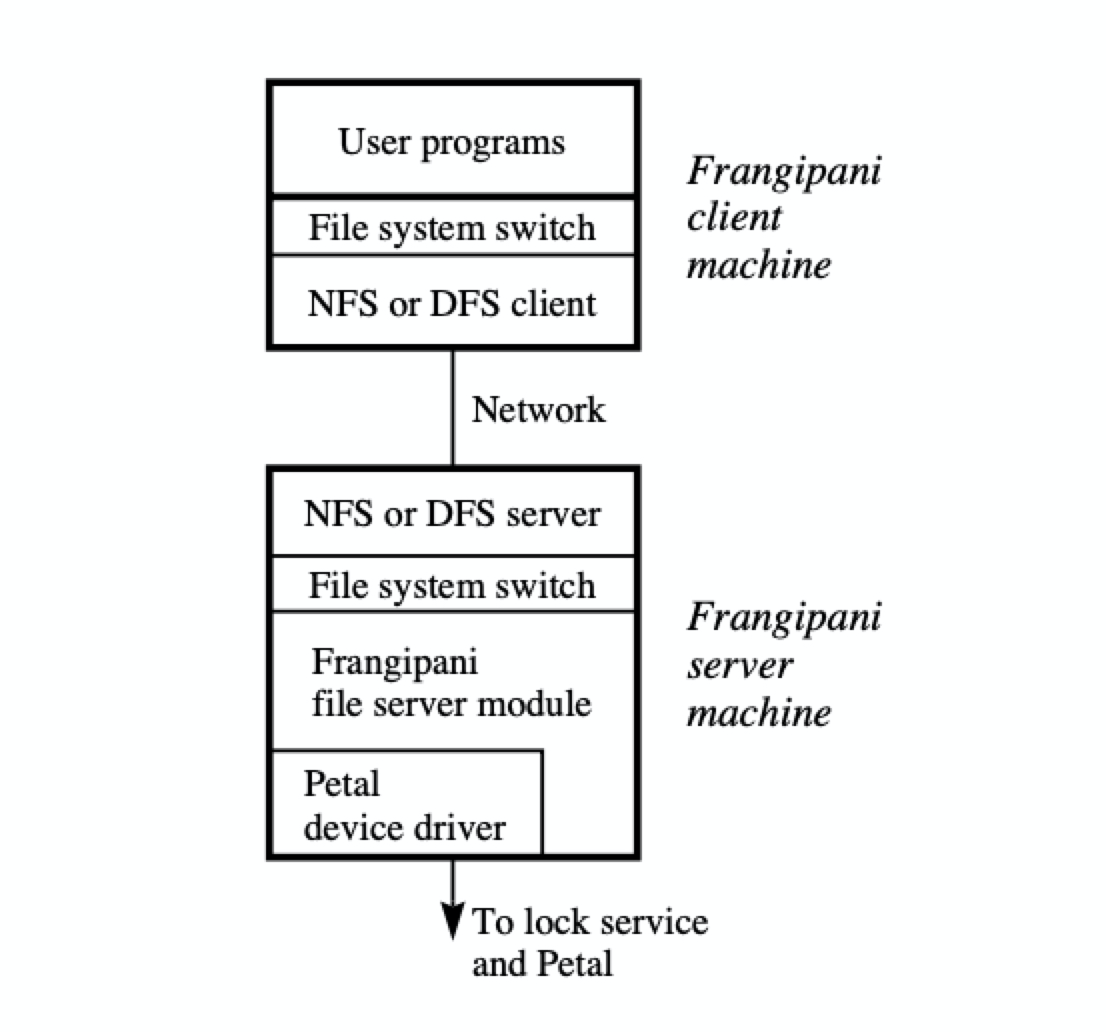
并非所有mount了Frangipani的机器都可以访问Petal,原因是kernel不同,可能存在bug
但可以通过在已有Frangipani机器上,再搭建一层Service来实现C-S访问Frangipani,如图中的架构
三、 Disk Layout
本节会介绍Petal的layout
1.Layout
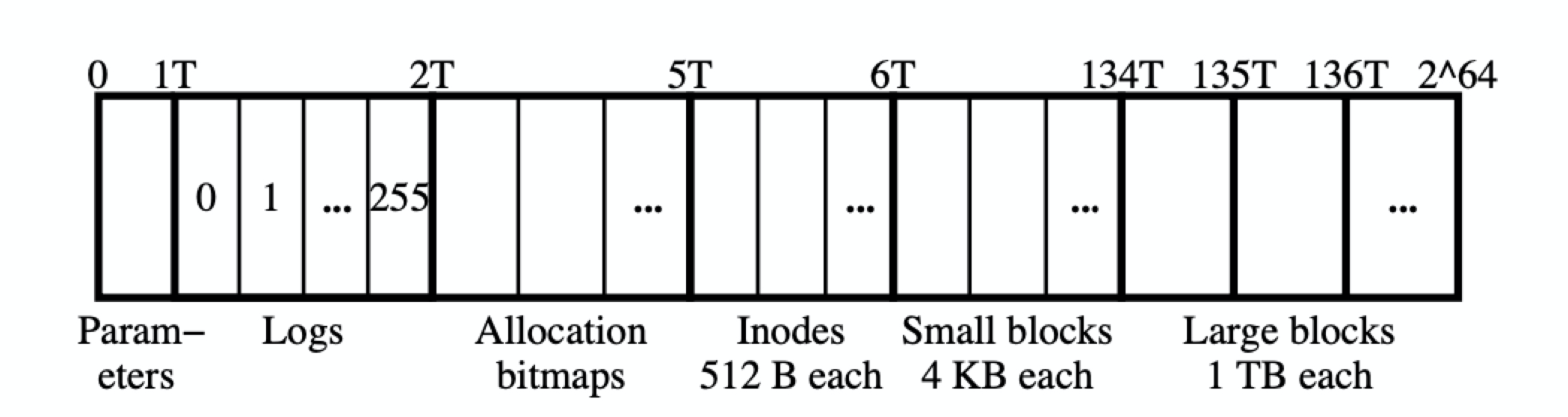
- 0 - 1T : 全局配置参数,论文中约占几K
- 1 - 2T : 256份logs (每份4GB)
- 2 - 5T : 块申请的bitmaps,也被分为若干份,但论文未给出多少份
- 5 - 6T : 2G个inodes (每个512B)
- 6 - 134T : 32G个data blocks (每个4KB)
- 134T-264 : 略小于16M个data blocks (每个1TB)
2.details
- 注意到每部分的大小是固定的,原因是简单,可以低成本地更改大小的配置
- logs每个Frangipani Server独占一份log,因此没有全局有序的log
- 每个bitmap被一个Frangipani Server独占,bitmap较多,一个bitmap被用完后,Frangipani Server会重新申请一个
- bitmap和inode有固定的映射关系,拥有bitmap的Frangipani Server只能alloc对应的inode,但可以读写任意位置的inode
- 文件大小的上限是16 * 4KB + 1 * 1TB,也就是一个文件,最多申请16个小data block和1个大data block
四、 The Lock Service
简单来说,Frangipani的cache coherence和failover是通过读写锁实现的
1.features
- 分布式锁
- 读写锁
- sticky,拿到锁的客户端不会释放锁,直到Lock Server请求客户端释放锁
- lease,持锁超过lease还没有renew,Lock Server会收回这把锁,客户端锁也会无效
2.架构
文章并没有详细描述分布式锁的架构,但可以从描述中窥见一二
- 一个分布式Lock Server集群 + Frangipani Server内置clerk module
- 分布式Lock Server集群
- 通过Paxos在所有Server之间共享meta:Lock Server list;Lock 和 Lock Server的对应关系; active clerk list
- 每把Lock只被一个Lock Server拥有
- 当Lock Server crash后,通过meta去进行failover
- 可以自动进行负载均衡
- clerk module
- 当Frangipani Server存活时,clerk 持有Lock table,维护持有那些锁以及锁的状态
3.锁的划分
-
每份log一把Lock,确保一份log只被一个Frangipani Server独占
-
每个bitmap一把锁,确保一个bitmap只被一个Frangipani Server独占;
同时bitmap锁,还保护:他所对应的data block,他所对应的inode,前提是这些block或者inode还没被alloc
-
每个file/directory/symbolic link一把锁,保护inode,以及对应的data block;该类锁的key应该是inode号
4.实现
处于性能考虑,采用异步消息来实现分布式锁的部分功能
- clerk -> Lock Server
- Request : 请求某锁
- Release : 释放某锁
- Lock Server -> clerk
- Grant : 赋予某锁
- Revoke : 剥夺某锁
他们的用法会在之后叙述中介绍
五、Cache coherence
简单来说,是利用读写锁实现
- 获得锁的权利
- 读锁:读取数据,并cache
- 写锁:读取数据,并cache,更改数据,允许本地cache和Petal存储不一致
- 释放锁的义务
- 释放读锁:失效cache
- 释放写锁:把dirty cache写回Petal,然后失效cache
- 写锁降级为读锁:把dirty cache写回Petal,可以继续持有cache
下面通过两个例子介绍锁的机制
假设有两个workstation(WS1,WS2),一个Lock Server(LS),以及涉及的文件(F)
Case1:WS1想要写F
- WS1 request -> 请求写锁 LS
- LS 查看该写锁没有被其他WS占用,或者还没有该写锁(可能是个新文件),会直接创建个新读写锁,并利用Paxos同步
- LS grant -> 赋予写锁 WS1
- WS1可以读取数据,cache数据,并更改数据
- WS1使用完该写锁后,依旧持有这把写锁(busy -> idle),并不断renew lease,直到LS剥夺
Case2:WS2之后也想要写F
-
WS2 request -> 请求写锁 LS
-
LS 发现这把写锁被 WS1占用,于是剥夺WS1的写锁
-
LS revoke -> 剥夺写锁 WS1
-
WS1收到消息后,发现写锁处于idle状态,会先把dirty cache写入Petal,失效cache,然后释放锁
如果写锁处于busy状态,会等WS1处理完自己的事情,置于idle后继续上述流程
-
WS1 release -> 释放写锁 LS
-
LS grant -> 赋予写锁 WS2
-
WS2可以读取数据,cache数据,并更改数据
-
WS2使用完该写锁后,依旧持有这把写锁(busy -> idle),并不断renew lease,直到LS剥夺
可能出现的情形包括以下几种
- 请求读锁
- 没WS持锁: 直接获得读锁
- 一些WS持有读锁: 直接获得读锁
- 一个WS持有写锁: 先剥夺该写锁,或者降级该写锁为读锁
- 请求写锁
- 没WS持锁: 直接获得写锁
- 一些WS持有读锁: 先剥夺所有WS的读锁
- 一个WS持有写锁: 先剥夺该写锁
六、Log and crash recovery
简单来说,通过WAL实现failover
写log流程
- 获取涉及更改的所有锁
- 关于meta data更改的事务,把所有的更改写进一条log里,放在memory或者sync进Petal
- log写进Petal后,才可以更改Petal的实际存储
details
- WAL只记录meta data相关的log,比如创建文件,删除文件,重命名文件等
- log记录在Petal而非Frangipani,每个Frangipani Server独占一份log(前面介绍一共256份log,所以最多256个Server,但是可调)
- 论文介绍,log最大128KB,满了reuse
- 因为reuse,可能出现找不到log起始位置的情况,因此每个log block附带一个递增的序列号
- 因为log没有全局有序,所以重演log时要遵守以下规则
- 持有log内涉及的所有写锁:说明没有其他客户端更改
- meta data block维护递增版本号,log内附带该版本号,只重演符合预期的log
failure detect
- Lock Server:lease过期;或者no reply for request
- client of Frangipani Server:no reply for request
failover
failover步骤如下:
- Lock Server让另一台Frangipani Server去执行Failover
- Lock Server会赋予recovery Server之前crash Server的所有锁
- 重演合适的log(条件见上details)
- 释放crash Server的所有锁
- 其他被crash Server持有锁阻塞请求的Server可以继续工作
- 可以选择restart这台机器
七、Other details
1.问题
论文中指出了几个问题
- 两层设计可能会log两次
- Lock的粒度是file而不是block
- 不知道file的确切物理位置
2.增删机器
可以几乎透明,不影响其他机器地增删机器
- 增加机器:指明Lock Service 和 Petal 即可
- 删除机器:直接关机即可
- Petal集群增删机器也是类似的
3.数据备份
-
Petal层面可以在线生成snapshot,用copy on write技术;
因为是Petal层面,所以依然存在file system的log,需要recovery才能使用
-
未来会采用一把特殊的锁,任何写操作都需要持有锁,锁可以shared
当需要snapshot时,back up 进程会让Lock Server会要求所有Frangipani Server释放该锁,此时dirty Data会写到Petal,并阻塞其他写操作,当所有机器都完成后,back up生成snapshot,并恢复正常
4.timestamp问题
问题:锁的lease检查之后在Frangipani Server,如果网络delay过大,request到达Petal时已经过期,这是不符合预期的
解决:使用maigin Time, 容忍一定的delay
未来的解决:到达Petal的request附带过期时间戳,如果时间没有误差,可以保证正确
5.性能
由于是1997年的论文(比我的年龄还大),并没有关注性能
但是可以看到,随着机器的增加,吞吐近乎线性的增长,这归功于去中心化的设计
以上就是我对于Frangipani主要内容的理解
欢迎一起讨论

 浙公网安备 33010602011771号
浙公网安备 33010602011771号