
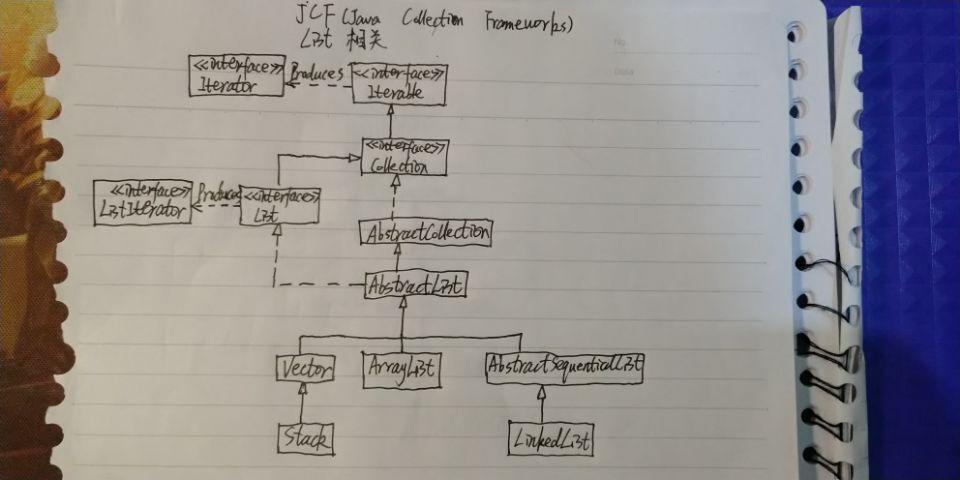
Java容器解析系列(4) ArrayList Vector Stack 详解
ArrayList
这里关于ArrayList本来都读了一遍源码,并且写了一些了,突然在原来的笔记里面发现了收藏的有相关博客,大致看了一下,这些就是我要写的(╹▽╹),而且估计我还写不到博主的水平,这里直接将收藏的博客列出来:
- 从源码角度彻底搞懂ArrayList
这篇博客的重要内容包括:
1. ArrayList使用的数据结构;
2. ArrayList的增删改查实现方式和时间复杂度分析;
3. ArrayList的自动扩容机制;
4. ArrayList的随机访问特性;
5. ArrayList与垃圾回收(因为对元素是强引用,在删除元素或移动元素时,被删除/被移动的元素原来的位置需要手动置为null)
6. ArrayList的并发修改,fail-fast机制
7. ArrayList的浅复制
8. ArrayList的序列化和反序列化
- ArrayList遍历方式以及效率比较
这篇博客的关键内容:
1. 探讨不同遍历方式(foreach iterator for循环)的遍历效率差原因;
2. ArrayList的随机访问特性,并且和顺序访问的LinkedList进行效率比较;
-
面试题:Java中ArrayList循环遍历并删除元素的陷阱
除了上面的博文内容外,这里做些无关痛痒的补充....:
/**
* ArrayList本身没有同步,如果需要在并发情况下使用,可以通过Collections.synchronizedList(List)进行包装,实现同步;
* @since 1.2
*/
// 这个继承了AbstractList,但是还是实现了List接口,想了半天,实现List接口这一点完全可以去掉.....,没有什么实际意义
// ArrayList实现了RandomAccess接口,证明其具有随机访问
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
// 将当前list中的数组大小缩减到size,以节约空间
public void trimToSize() {
modCount++;
int oldCapacity = elementData.length;
if (size < oldCapacity) {
elementData = Arrays.copyOf(elementData, size);
}
}
........
}
Vector
其实在jdk中,有一个与ArrayList实现非常相似,且在jdk1.0就已经存在的Vector类,我们来粗略看一下.
首先看一下Vector的类型定义
/**
* @since JDK1.0
*/
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
Vector与ArrayList同样继承自AbstractList,实现相同的接口,那么其中必然有很多相同的方法,且仔细看,其中实现几乎全部都与ArrayList一致,这里不做多余分析
这里只对一些差异进行分析:
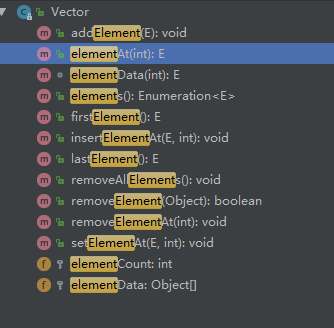
- 在jdk1.0,Vector的作者似乎很喜欢element这个单词:
![]()
ArrayList中的size,在Vector中为elementCount,所有的增删改查方法都有以element开头或结尾的方法,如果去看其具体实现,和ArrayList中的相关增删改查方式没有什么区别; - Vector的所有方法都加了锁(有些方法没有加锁,但是是被同步方法调用或内部调用同步方法实现),是线程安全的类;
- 除了添加的Iterator和ListIterator之外,Vector还有一个jdk1.0就存在的遍历方式:elments()返回一个Enumeration对象来遍历;
- Vector每次扩容时容量扩大的数量,通过一个成员变量:capacityIncrement来控制,如果capacityIncrement<=0,每次扩容后容量为原来的2倍;
- Vector的subList()方法返回的list是一个同步的list对象;
- 如果细看,Vector的序列化实现方式也和ArrayList不同,应该是为了兼容老代码,没有必要对此进行研究;
因为Vector每次操作都要获取锁,效率太低,因此如果没有线程安全的需求,一般推荐使用 ArrayList(其实如果有线程安全,也没有必要使用Vector,直接使用Collections.synchronizedList(List)包装出一个同步的list使用即可,将Vector踢进历史长河中)
既然讲了Vector这个被抛弃的类,那么也顺带说一下在Java中被公认为设计不良好的Stack类,从名字就可以看出来其预期是表示一个栈,但是我们看一下其类声明:
/**
* @since JDK1.0
*/
public
class Stack<E> extends Vector<E> {
public Stack() {
}
// 压栈
public E push(E item) {
addElement(item);
return item;
}
// 弹栈
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
// 获取栈顶元素,但是不弹栈
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
// 获得指定对象o离栈顶的距离,如果o就是栈顶元素,则为1;如果栈中不存在元素o,返回-1;
public synchronized int search(Object o) {
int i = lastIndexOf(o);
if (i >= 0) {
return size() - i;
}
return -1;
}
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = 1224463164541339165L;
}
Stack之所以被认为设计不良好,是因为其继承了Vector类:
- 所有Vector中可被调用的方法,在相同情况下也可以在Stack中调用,这与Stack本身的定义就不符,Stack本身是一个LIFO的数据结构,只允许在一端压入,同一端取出(也即压栈和弹栈)的操作;
- Vector内部使用数组方式实现,有自动扩容机制,Stack继承Vector类,也就同样限制了Stack内部实现方式也是数组,也有动态扩容机制,这对Stack的实现没有必要(完全可以简单地使用链表实现);
- 可能是为了保持Vector线程安全的特点,Stack中的方法也全部为同步方法,这使得其效率低;
除此之外,Stack类还要注意pop()和peek()的区别:
- pop()是弹栈,及获取栈顶元素,并把栈顶元素删除;
- peek()只是获取栈顶元素,相当于查询,并不对栈进行其他操作;
在《Java编程思想》中,提供了另一中Stack实现方式:
// Making a stack from a LinkedList.
import java.util.LinkedList;
public class Stack<T>{
private LinkedList<T> storage = new LinkedList<T>();
public void push(T v){
storage.addFirst(v);
}
public T peek(){
return storage.getFirst();
}
public T pop(){
return storage.removeFirst();
}
public boolean empty(){
return storage.isEmpty();
}
public String toString(){
return storage.toString();
}
}
这个栈的实现方式避免了上面说的Stack继承自Vector的问题;
Stack只含有一个LinkedList对象的引用,而不是继承LinkedList.
奇怪的是,jdk文档推荐使用Deque来代替Stack,如果查看LinkedList的类定义就知道其实现了Deque接口,但是这并不能避免上面的问题(只是非线程安全了,使效率有所提高);
而且jdk在明确了Stack之后,没有提供其他的Stack相关的类,《Java编程思想》中给出的解释"可能是因为Stack这个名字已经被占用",但是这并不能说通,因为完全可以弄出个"ArrayStack,LinkedStack"之类的名字;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号