coco_music 个人总结

一、项目相关文档汇总
二、个人工作报告与总结
这次大作业,我在小组内的工作主要是音乐数据收集处理,后端模块的实现,以及前端的改造。
一. 数据爬取和处理
由于我们搭建是一个在线音乐网站,所以必然涉及要获取大量音乐相关的数据,比如音乐专辑,图片,作者等信息。像音乐文件本身其实是很好爬取的,因为音乐的地址为http://music.163.com/song/media/outer/url? id=加上音乐id信息即可 ,由于我们后来弃用了本地音乐播放,而采用获取网站的mp3信息而导致我们爬下来的音乐信息,很多是没有版权播放的,所以又必须要爬取到音乐的完整信息,获取到该音乐是否有版权,并对其过滤。这其中也涉及到了网易云很多数据Request HEaders里的Cookie值、FromData里的params、encSecKey都是加密过的,需要查询资料了解怎么解密,过程很辛苦但也学到了不少东西。
二.前后端交互以及各个模块的实现
由于对前后端框架了解的比较少,在我们的项目中采用了 js 的 ajax 与 后台 serverlet 的技术路线进行数据的互传交互。并且为了代码的简洁和不必要的冗余,对数据库操作进行了封装,让实际操作中的数据存取与写入更加方便快捷。
-
发现界面中歌单,mv的添加,歌单歌曲的获取以及侧边播放列表的实现
在进入发现界面获取歌单的时候首先通过ajax 向servelet请求数据,数据请求成功后,每一条数据(也就是歌单的数据)都对应一个div,采用左浮动的模式,这样添加歌单的时候,歌单超过边界会自动浮动到下面,对每个div都用值为歌单id的data-id标注,这样在监听到点击事件后,就可以很方便从数据库中获取到该歌单中的歌曲列表。
在监听到歌单的点击事件进入到歌单后,从后端传到前端的歌曲信息不仅需要在页面中展示出来,还需要存入到一个全局的列表中(对于我喜欢的歌,最近播放也是同理),这样在检测到鼠标的点击事件以后只要获取当前点击列表的相对位置就可以从全局中拿到这首歌进行播放,同时这个全局的歌曲表单还用于可显示和隐藏播放列表中,使得不管我到了哪个界面都可以选择上一次播放的音乐列表中的任何歌曲。
-
最近播放、我喜欢的音乐模块及播放器的改造
为了记录最近播放的歌曲,不管是用户模式还是非用户模式下,当进入coco music 界面时,自动为其创建 一个列表,每当用户点击歌曲的时候,获取到当首歌曲的信息,并将其push到这个最近播放歌曲的列表中即可,当然需要注意当用户重复播放歌曲的时候,不能让最近播放表单中有重复的歌曲,而是要让以往播放的歌曲放在第一位。
我喜欢的音乐则通过播放器栏的爱心点击事件获得,在这里为了减少数据库的操作,当用户进入coco音乐界面的时候,除了将用户的喜好歌曲加入我喜欢的音乐界面外,还要自动为其创建一个喜欢音乐的列表,这样每次打开一首歌,播放栏爱心的红与不红的设置不需要每次去数据库查找,而是直接在js中查找即可,加快界面反应速度。当然,当发生爱心的点击事件时,也需要在数据库喜好歌曲表单中添加删除该歌曲。同时我喜欢的音乐也为音乐推荐模块打下了基础。
三.音乐推荐功能实现
本项目的音乐推荐功能采用人工智能的个性化推荐方式,通过对个人的喜好歌单中的歌曲与歌库中的音乐计算曲风的相似度,使得推荐的歌曲更加符合用户口味。
-
数据准备
在网易云web版本中,可以通过歌曲风格选择歌单。这里我挑选了音乐类型中比较有代表性的古典、爵士、金属、轻音乐、说唱、乡村、摇滚、流行、古风 9种类型的音乐。对每个类型的音乐收集了100左右首歌并打上分类标签。
-
数据处理
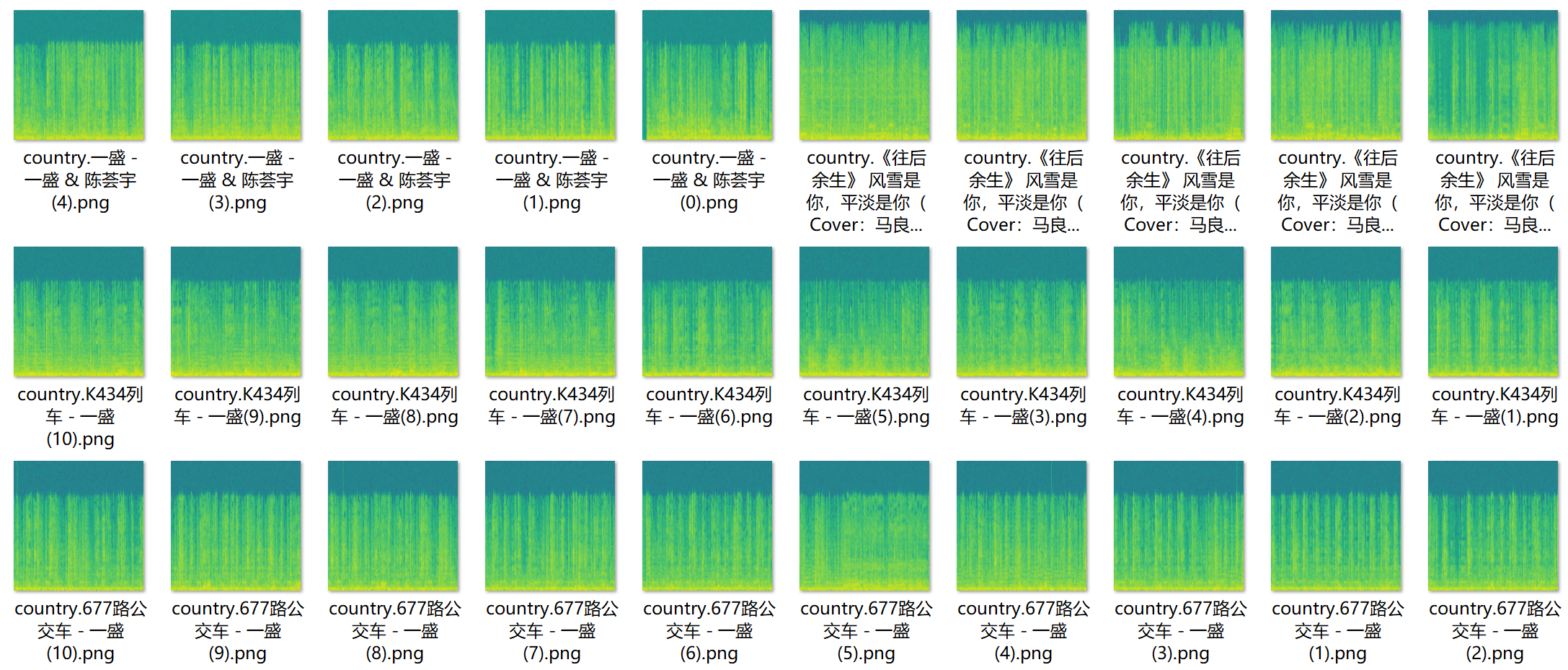
首先,从网页版中爬下来的音乐是.mp3 格式,为了在后面方便生成频谱图,将数据转换为.wav 格式后取出其中一个声道(由于两个声道的频谱图十分类似,若都采用则可能使数据重复过多导致模型训练过拟合而达不到好的效果),并生成整首歌的频谱图。频谱图如下:

为了便于我们后续模型的搭建(CNN 一般用标准正方形图输入)以及数据量的增加,我将一首歌的长频谱图切分成了total_length/256 个 256*256 的小频谱图,并将多余的数据删去。于是我们得到了以下处理好的带标签训练数
-
模型搭建
(简介)CNN网络主要特点是使用卷积层,其实是模拟了人的视觉神经,单个神经元只能对某种特定的图像特征产生响应,比如横向或者纵向的边缘,本身是非常简单的,但是这些简单的神经元构成一层,在层数足够多后,就可以获取足够丰富的特征。
在这里我采用了resnet34 的预训练模型,由于我们的数据是9个类别的,所以我需要将resnet 的最后一层 fc 替换为输出为9维的全连接层参与我们数据的训练。在训练的过程中对resnet34 的模型进行finetune,使其更好的适应我们的音乐频谱数据。

以下为模型在测试集上的准确度信息:
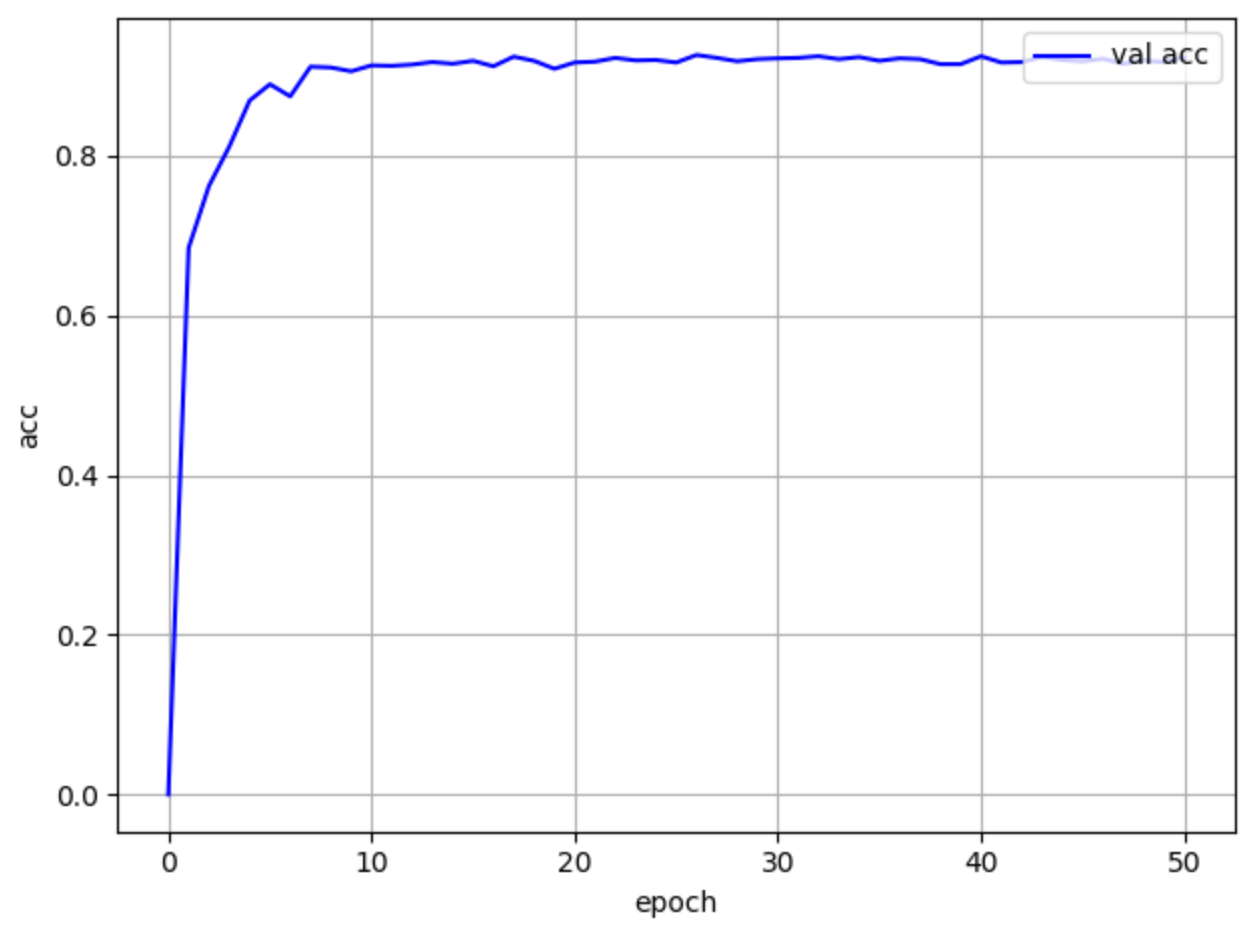
随后将测试集上到达最高准确率的模型保存下来,重新加载模型时去除最后一层的全连接层,使得每张图片输入模型后可以得到512维的特征数据,这512维的特征数据可以认为是这首歌的表示。下图为某一首歌的部分特征信息。

当我们得到了词库中所有歌词的特征表示后,两首歌之间的相似度可以定义为 sim(x,y) = $ \frac{1}{1+\sqrt{\sum_{i= 1}\left ( x_{i}-y_{i}\right )^{2}}}$
这样我们就可以根据歌曲的相似度来推荐歌曲了,每当我们coco_music 用户往自己的 ”喜欢“ 歌单中添加歌曲时,我们将用户添加的歌曲与其他歌曲进行相似度的计算,进行排序后,取出相似度高于一定闸值的歌或是前几位的歌对用户进行推荐。这不同于现在各个音乐平台所用的协同过滤,聚类算法等需要大量的用户信息才能进行音乐推荐,我们只需要得到用户的喜好歌曲就可以进行歌曲的推荐。
以下为对”骂醒你“歌曲计算出的词库中的相似度排序
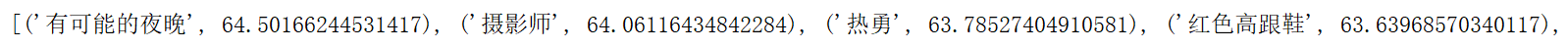
当然这里也有一个坑,当用户的喜好歌曲中,不同的歌曲的推荐中可能会得到一样的歌曲,这个时候就需要对数据库进行处理,保证添加推荐歌曲时歌曲的唯一性。
- 效果
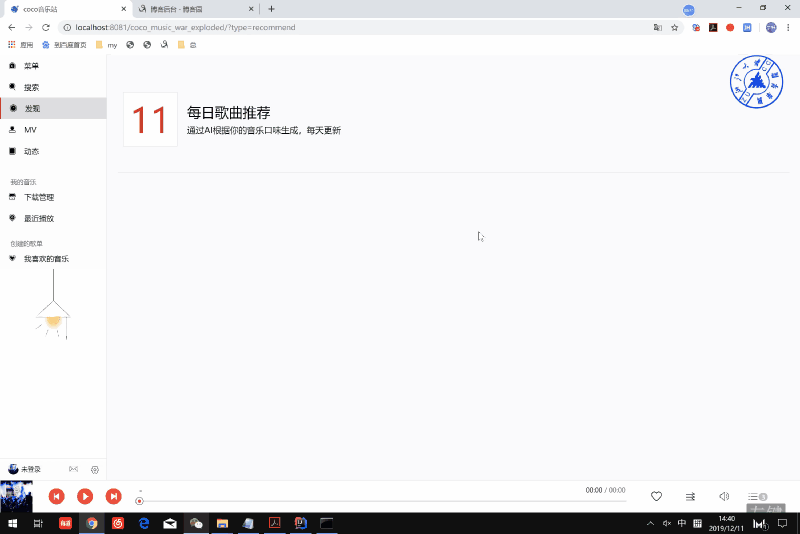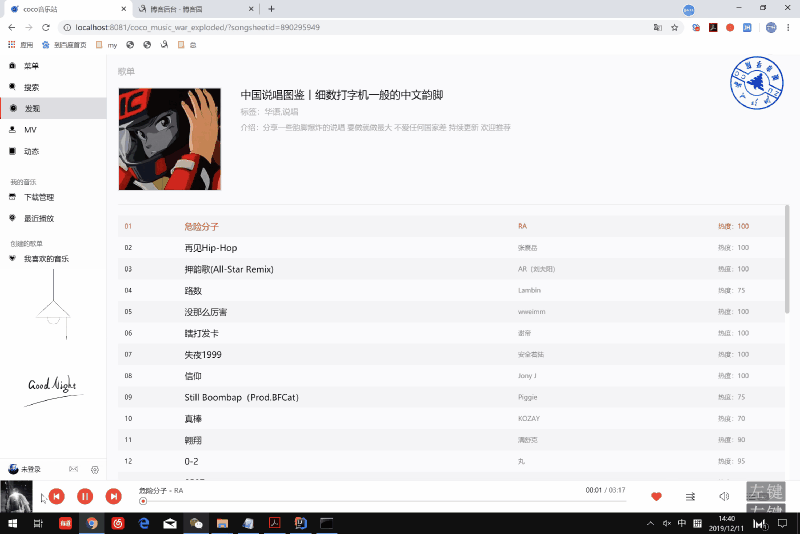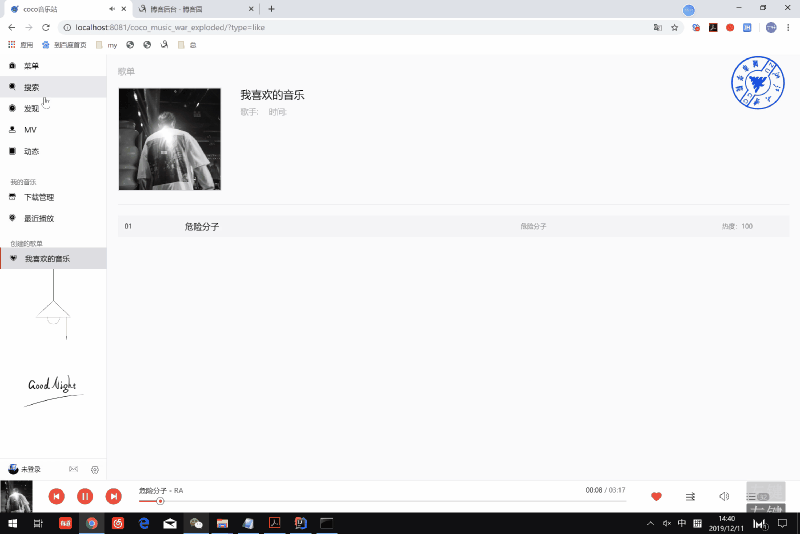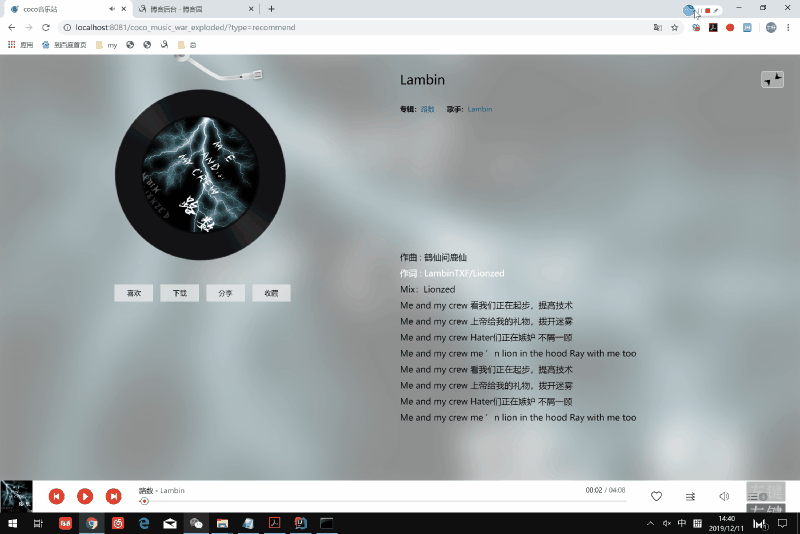
四.总结与展望
1. 课程收获
经历了本学期的软件工程课程,不仅让我从理论上了解软件工程的概念。并且在个人项目和集体项目的实作中,亲身经历了开发一个完整的软件需要经历的种种,让理论和实践得到了很好的结合。课程中,我感受到了需求分析的重要性,在开发一套软件之前,需要完整、清晰、具体的要求,我们这个项目需要做什么,实现哪些功能,做这些功能又是为了什么。作为一名软件开发者必须深入用户的实际需求,从用户的角度思考,开发能让用户满意的软件。同时,除了软件的功能性需求,也需要考虑到软件在不同的运行环境下能够跑的起来,做出一款”包容性“ 强的软件也是十分重要的。
2.反思
- 由于这是我们第一个集体开发一个相对比较大的项目,我们需要更加严谨的开发流程,需要对项目完成进度进行总体的控制与规划。在项目开始前需要一个总体的计划,到什么时间点我们需要有怎么样的成果,如果到该时间点延期了,该怎么做。同时,我们需要增加集体高效率开发的时间,增加组员之间的交流合作,而不是自己做自己的。所有大的程序离不开团队合作,团队的分工,团队的合作在整个项目的推进过程中是至关重要的。
- 对项目初期提出的需要,应该按部就班的落实,或是在项目初期思考需求的时候根据实际情况考虑周到,项目的完成度对于整个项目来说也是非常重要的。
3.展望
我们希望本项目不是为了完成软件工程的大作业而完成,在后面的时间能对软件还没有实现的功能进行完善,比如在歌曲推荐的功能上用RNN 加入歌词的风格信息,让推荐更加灵活完善。同时也希望在后面的编程开发中更加注重编码素养,将理论的学习更多的用于实践之中。
五. 课程感受及建议
- 首先要对课改《构建之法》给予肯定,课程中 “项目驱动”,“以学生为主体,以老师为主导” 的思想让我们学生能走出课本的框框,以实际项目推动理论知识的学习。
- 课程中老师对现实社会中各个软件工程相关的故事和自己的看法,扩宽了我们的知识面,活跃了课堂氛围。
- 在课程教学中,可以适当增加小项目,即使是搭建一个很小的组件也好,同时增加灵活性,给与同学更大的选择空间,让我们可以从不同的角度感受软件工程的意义。
- 对于最后的项目,其实大家都集中在组内的讨论与推进,组与组之间的交流和沟通太少了。可以在项目达到一定程度的时候,请每个组分享一下经验,和当前所遇到的坑。这样让大家不仅能从自己的项目中获取经验,也能从别的组的历程与遇到的问题中学习,同时也活跃了课堂气氛。在分组上,也应该适当照顾一下学生的方向(比如说有些同学对前端懂的多,后端有所欠缺,那么如果6个都会前端的人组在一起可能会导致资源浪费,或是项目推进较慢),同时,也要适当照顾一下在某个方向有所欠缺的同学,让每一个人都能充分得到互相学习的机会。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号