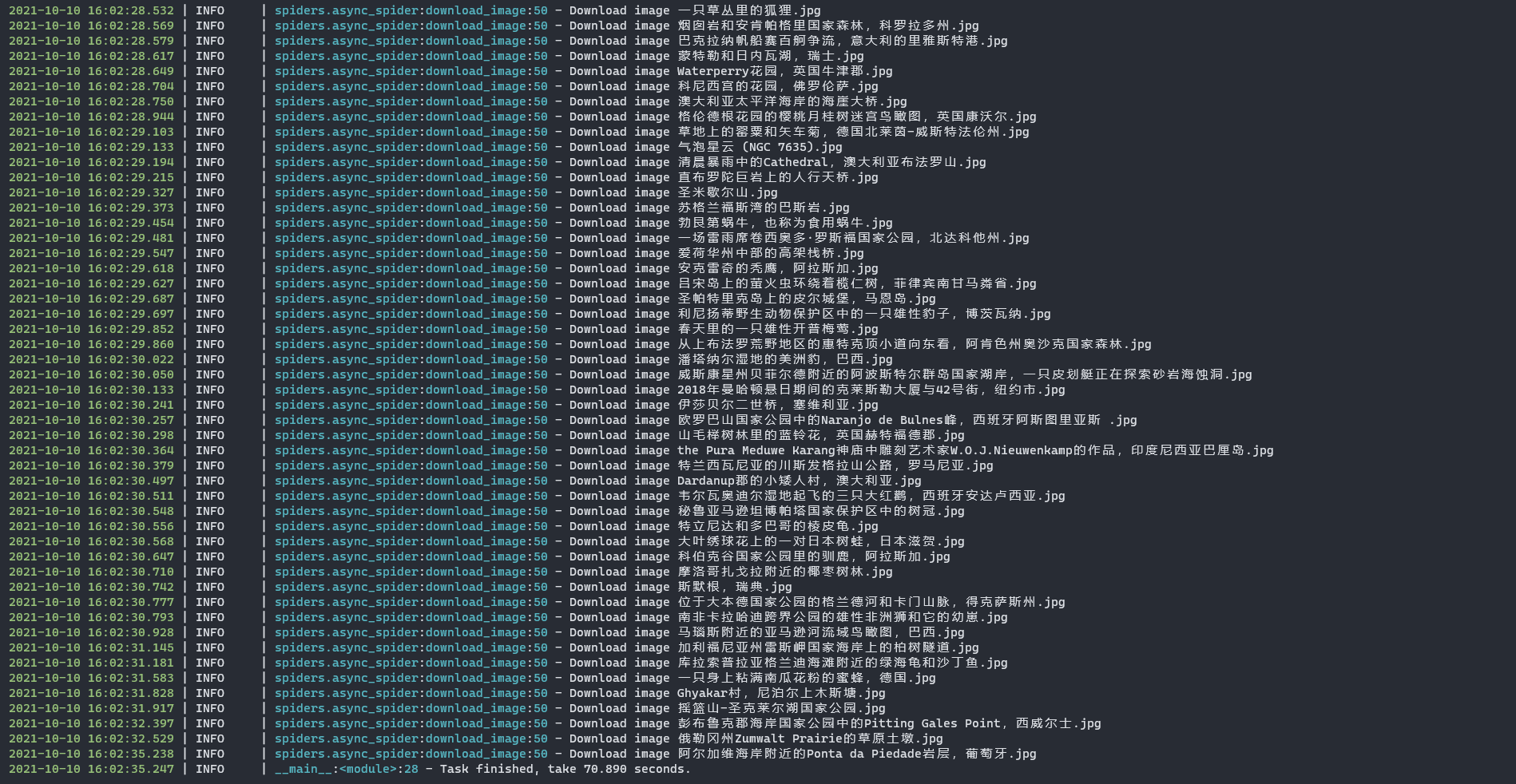
Python 高性能异步爬虫 一分钟下载 3.5G Bing 高清壁纸
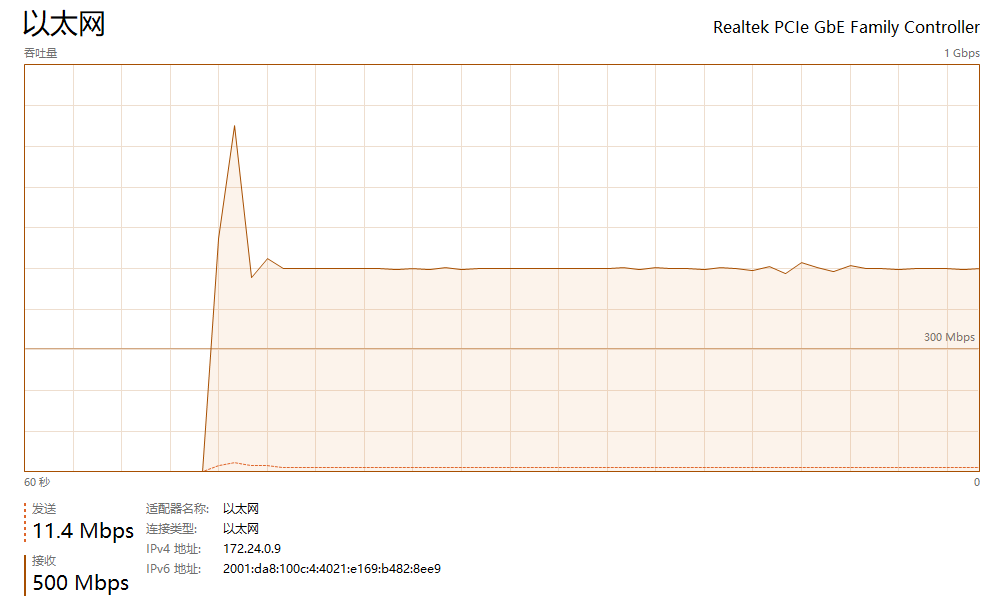
保存壁纸信息到数据库 + 保存高清壁纸(约3.5G)只需70s
大体思路
Bing 官方的壁纸 API 是https://www.bing.com/HPImageArchive.aspx?format=js&idx=0&n=1&mkt=zh-cn
返回的是一个json格式的数据,里面有今日壁纸的相关信息
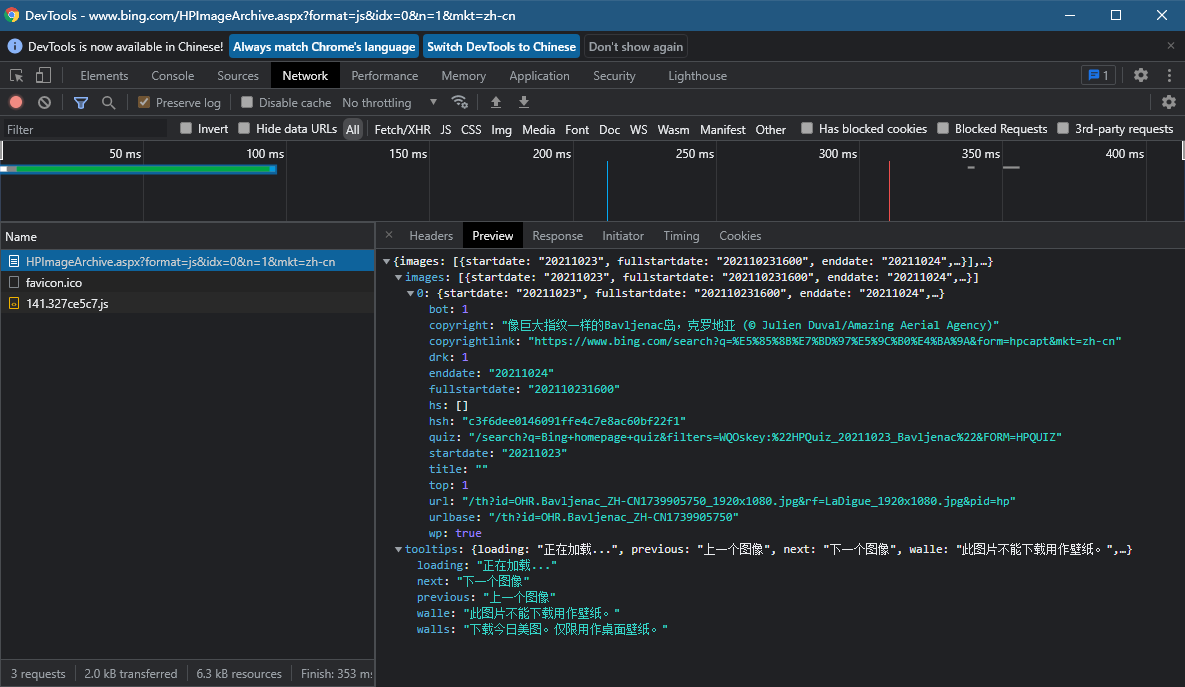
其中图片地址为https://www.bing.com + url
这里的 url 为 /th?id=OHR.Bavljenac_ZH-CN1739905750_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&pid=hp
参数n控制着返回图片的信息个数,但最大只能返回8条
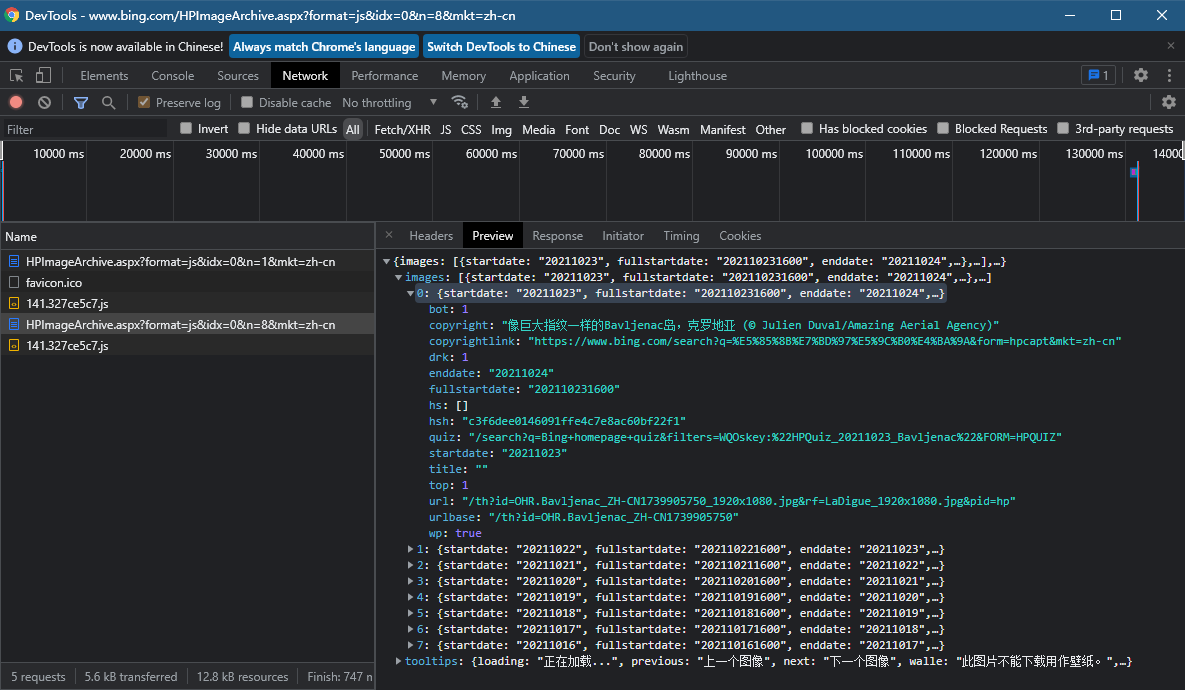
例如,将 n 设置为80后,依然只能返回8条信息
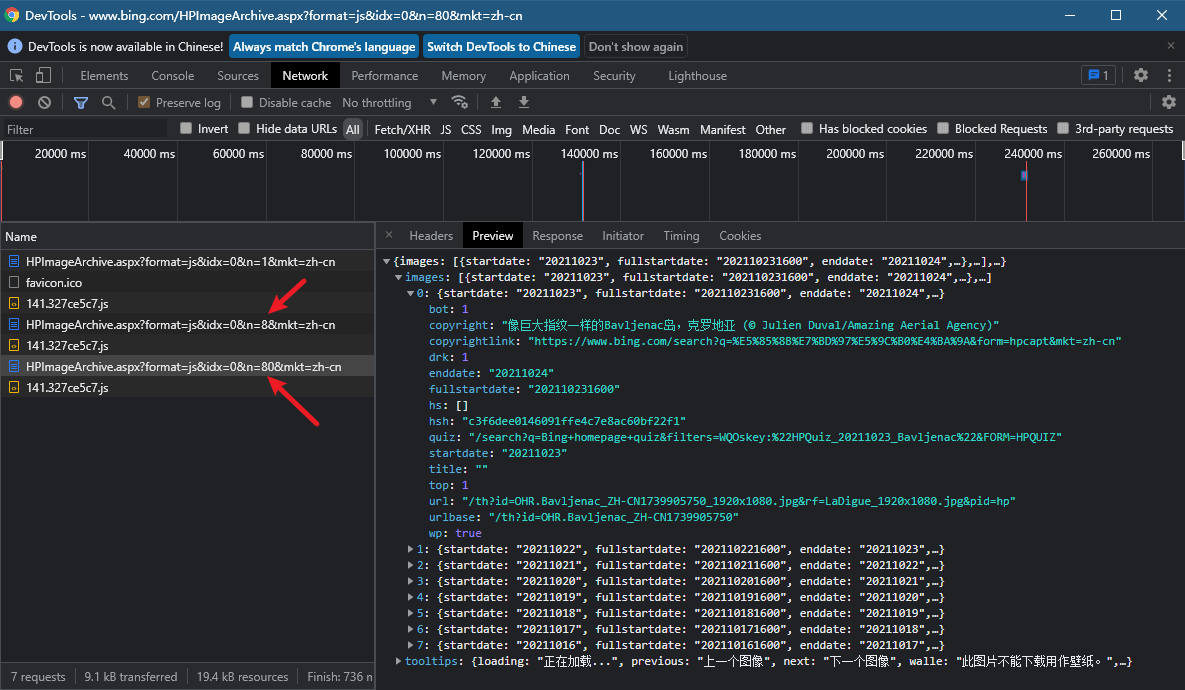
经过观察发现,图片地址的格式为 https://www.bing.com/th?id=OHR. + 图片id + _ + 图片大小,可以把图片大小默认设置成OHR最高画质,那么只要获取到图片id,就可以得到图片的地址。
获取图片ID和更多信息
有一个很不错的网站,https://bing.ioliu.cn/,作者从2016年就开始收集Bing壁纸,并把壁纸放在网站上共大家免费下载,而且项目也在Github上开源:https://github.com/xCss/bing。
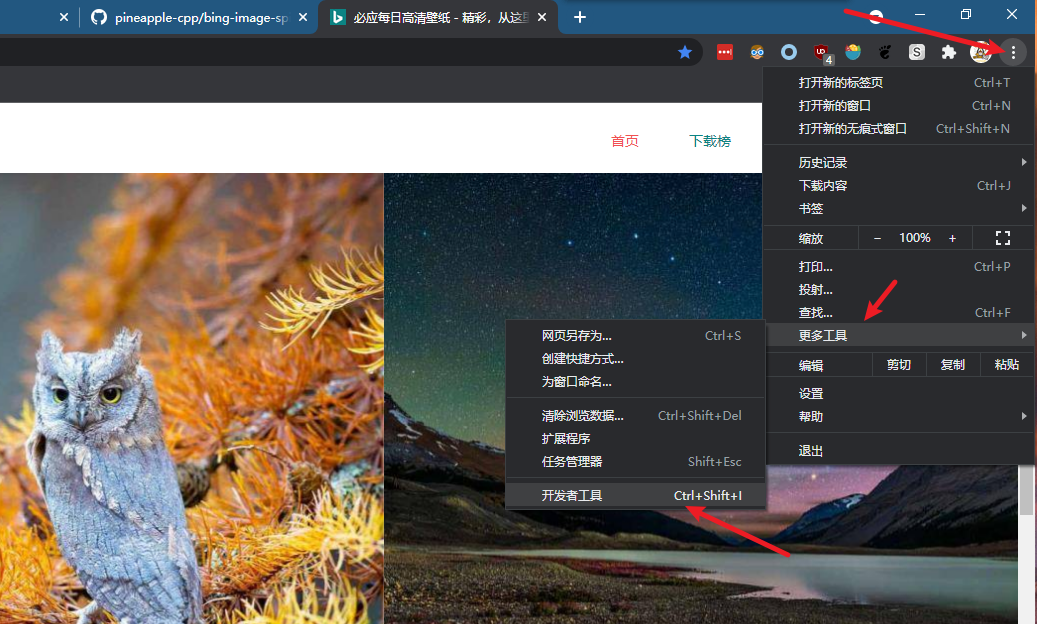
恕我冒昧借用以下这位好心人的网站,爬一下图片的相关信息。具体的信息有:图片ID,图片名,版权信息,时间。剩下的就是解析网站这些基础的活了,这里我不做过多解释。需要注意的一点是,作者关闭了 f12 按键,打开开发者工具需要点击浏览器右上角的三个小点:
编写爬虫
为了追求效率,我使用了协程 aiohttp 作为异步网络请求工具,aiofiles 作为异步文件读写工具,aiomysql 作为异步MySQL读写工具。有关Python 协程和这几个库的用法请参考下面的链接:
asyncio --- 异步 I/O:https://docs.python.org/zh-cn/3/library/asyncio.html?highlight=asyncio#module-asyncio
aiohttp docs:https://docs.aiohttp.org/en/stable/
aiofiles docs:https://pypi.org/project/aiofiles/
aiomysql docs:https://aiomysql.readthedocs.io/en/latest/
核心代码为:spiders/aync_spider.py
mysql操作相关代码为:database/mysql.py
配置文件代码为:settings.py
工具函数文件:utils.py
程序入口:main.py
相关程序细节不想介绍,感兴趣的话可以阅读我的代码,必要的注释都有,可以给我提供建议或反馈BUG。
如何使用
> python main.py --help
usage: main.py [-h] [--daily DAILY]
Bing Image Spider
optional arguments:
-h, --help show this help message and exit
--daily DAILY Daily update or not.
默认情况下运行main.py会执行每日更新,即爬取今日壁纸的信息保存到数据库,下载壁纸到的images目录下。
所以请先配置好数据库,日常更新会向数据库中插入一条壁纸信息。而将daily设为False的话,将执行全面下载,这会清空数据表。
官方的API只支持2019年5月10日之后的壁纸,请合理配置MAX_PAGE(我测试的时候最大爬到73页)。
喜欢我的文章的话,欢迎关注👇点赞👇评论👇收藏👇 谢谢支持!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号