Hadoop 用Java编写MapReduce去重程序
一、任务目标
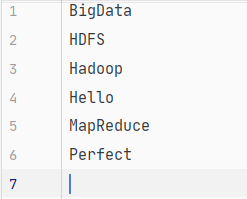
针对一个文本的内容,提取其中的所有单词并去重
文本去重前

去重后
二、代码实战
这个和之前的词频统计任务有很多的相似之处,甚至更简单。因为默认在shuffle阶段会有一个去重的操作,所以我们只需要将单词提取出来就好。
做完词频统计再做这个会显得特别简单,不同的就是最后的v3为空。我们可以利用MapReduce的数据类型NullWritable
Map
package cn.pineapple.RemoveRepeatedWords;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class RepeatMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text text = new Text();
NullWritable nullWritable = NullWritable.get();
String[] split = value.toString().split(",");
for (String word : split) {
text.set(word);
context.write(text, nullWritable);
}
}
}
k2的类型为NullWritable,在这里要注意的是,NullWritable不能像Text、LongWritable、IntWritable一样直接new出一个对象
NullWritable构造函数的访问权限为private
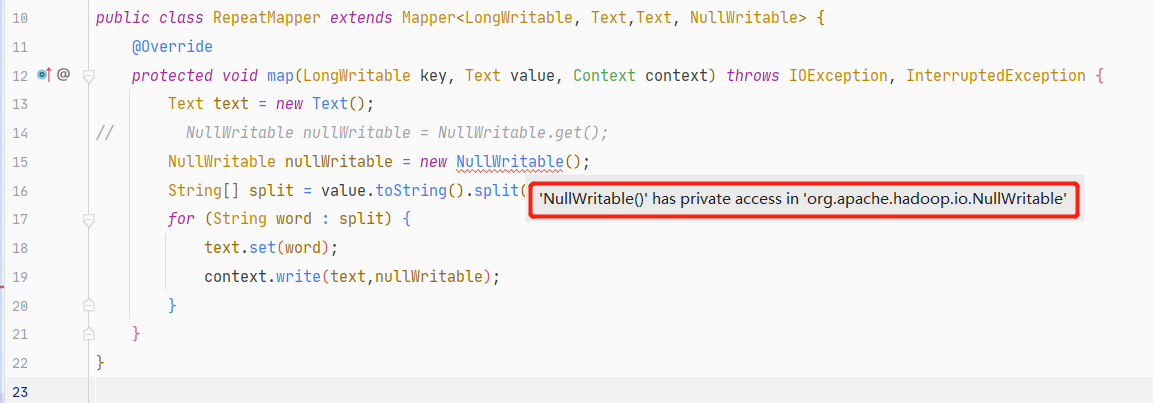 查看一下源码,发现它的get()方法可以返回一个NullWritable类的实例
查看一下源码,发现它的get()方法可以返回一个NullWritable类的实例
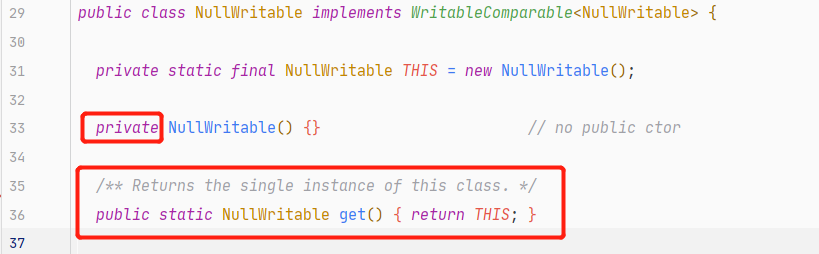
所以我们要用NullWritable nullWritable = NullWritable.get();的方法来创建一个NullWritable对象
Reduce
package cn.pineapple.RemoveRepeatedWords;
import org.apache.commons.lang.ObjectUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class RepeatReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
与词频统计比,省去了计算集合的合,直接将shuffle出来的key写入上下文,当然value还是空的NullWritable类型。
Main
package cn.pineapple.RemoveRepeatedWords;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//1、创建一个job任务对象
Job removeRepeat = Job.getInstance(super.getConf(), "RemoveRepeat");
//打包出错,加此配置
removeRepeat.setJarByClass(JobMain.class);
//2、配置job任务对象的八个步骤
//第一步、指定文件的读取方式
removeRepeat.setInputFormatClass(TextInputFormat.class);
// 读取路径
TextInputFormat.addInputPath(removeRepeat, new Path("file:///D:\\IDEA\\MapReduceTest\\input"));
//第二步、指定Map阶段的处理方式和数据类型
removeRepeat.setMapperClass(RepeatMapper.class);
// 指定K1的类型
removeRepeat.setMapOutputKeyClass(LongWritable.class);
// 指定v1的类型
removeRepeat.setMapOutputValueClass(Text.class);
//第三、四、五、六shuffle阶段采用默认的方式
//第七步、指定Reduce阶段的处理方式和数据类型
removeRepeat.setReducerClass(RepeatReducer.class);
// 指定k2的类型
removeRepeat.setMapOutputKeyClass(Text.class);
// 指定v2的类型
removeRepeat.setMapOutputValueClass(NullWritable.class);
//第八步、指定输出类型
removeRepeat.setOutputFormatClass(TextOutputFormat.class);
Path path = new Path("file:///D:\\IDEA\\MapReduceTest\\output");
TextOutputFormat.setOutputPath(removeRepeat, path);
//获取FileSystem
FileSystem fileSystem = FileSystem.get(new Configuration());
//判断目录是否存在
boolean exists = fileSystem.exists(path);
if (exists) {
fileSystem.delete(path, true);
}
//等待任务结束
boolean bl = removeRepeat.waitForCompletion(true);
return bl ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动job任务
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
这里和之前的流程基本一样,只要修改一下k2的类型为NullWritable就行
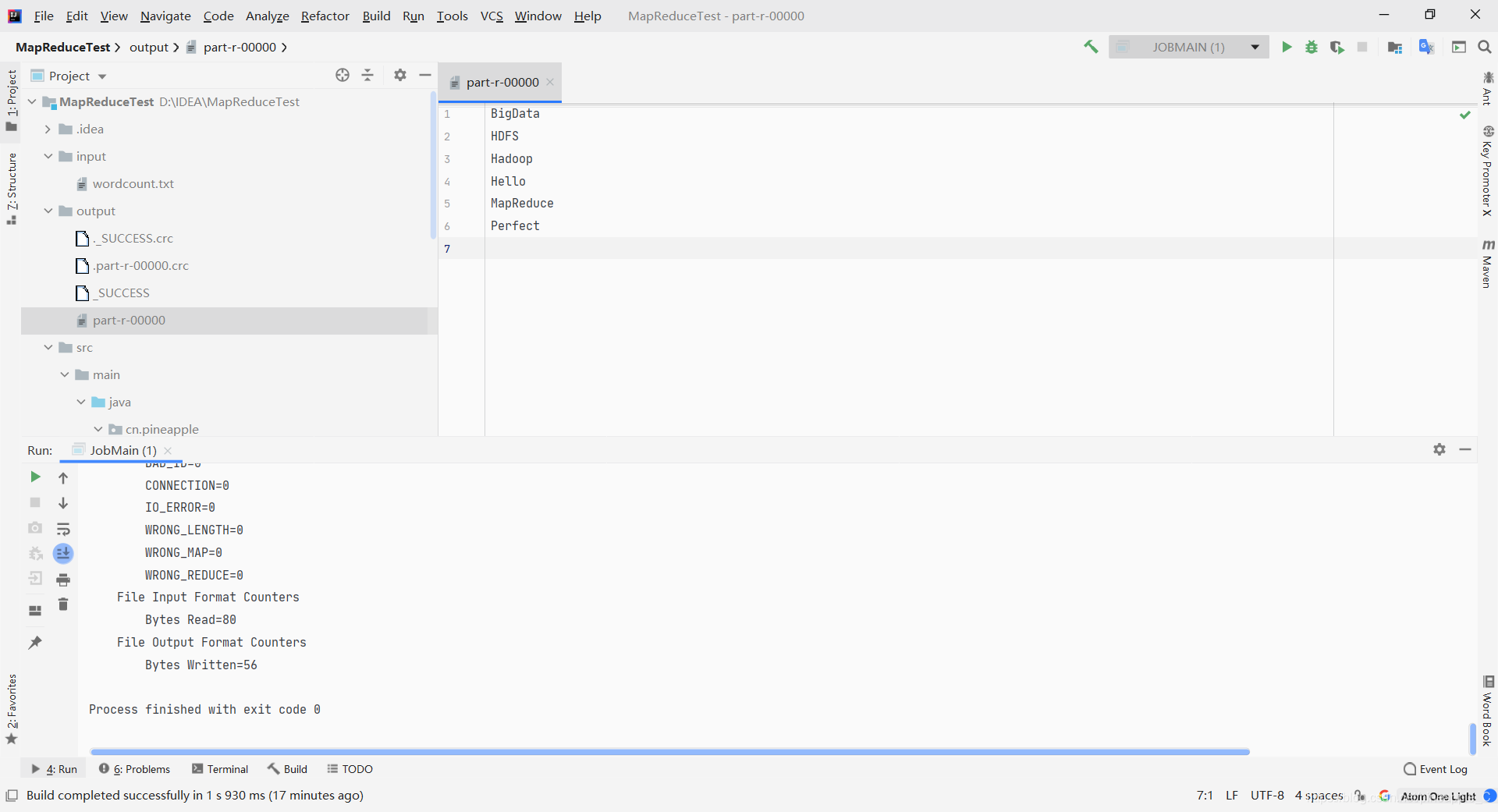
这次直接在本地上运行
走!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号