Hadoop 解决本地运行出错Cannot initialize Cluster. Please check your configuration for mapreduce.framework...
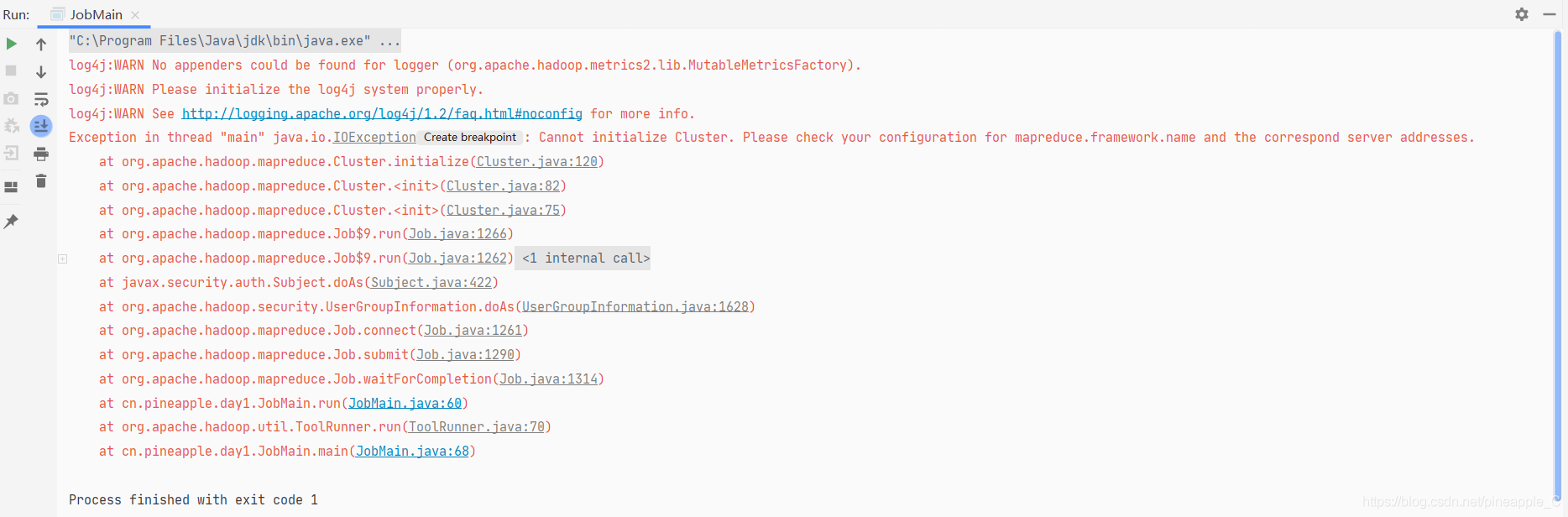
一、问题描述
二、问题分析
之前都是写完程序后直接打包到集群上运行的,这样确实有点麻烦,所以尝试了一下在本地运行,修改了以下几行
// TextInputFormat.addInputPath(wordCount, new Path("hdfs://nsv:8020/input/wordcount"));
TextInputFormat.addInputPath(wordCount, new Path("file:///D:\\IDEA\\MapReduceTest\\input"));
// TextOutputFormat.setOutputPath(wordCount, new Path("hdfs://nsv:8020/output/wordcount"));
TextOutputFormat.setOutputPath(wordCount, new Path("file:///D:\\IDEA\\MapReduceTest\\output"));
注释掉的为修改之前的代码,本以为这样修改就能直接在本地运行了,结果报错。。。
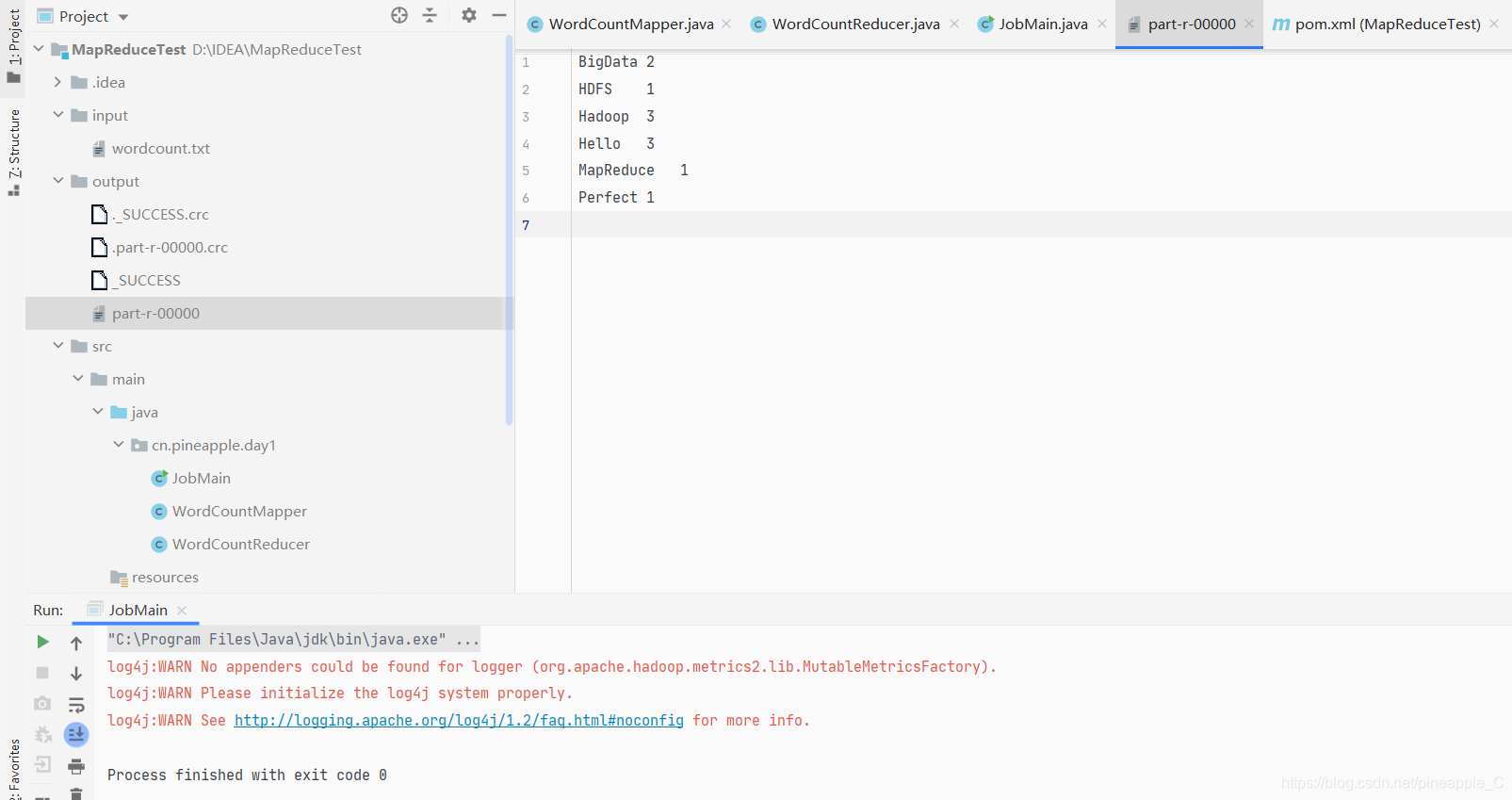
三、解决问题
百度了一下,得出了如下两条条结论:
1、hadoop-mapreduce-client-core.jar是支持放在集群上运行的
2、hadoop-mapreduce-client-common.jar是支持在本地运行的
所以修改pom文件,加上这个依赖就行了
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
走!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号