Python selenium破解腾讯滑块验证码,Github开源项目分析
一、前言
最近一直在搞滑块验证码,发现它比之前的极验验证码又提升了一个档次。验证码只提供两张拼图,不提供原图。所以通过对比两张图片来寻找缺口的方法已经不适用了!所以要用一些图像处理和计算机视觉相关的方法,比如openCV。但是这个东西太深奥了,又和python的另一个第三方库:numpy紧密结合,所以一时半会是学不完的。咱毕竟是搞数据的又不是搞图像的,我就在git上找了一些大佬的项目,然后拿过来分析一下,做了下简单的修改,加了一些注释。测试了一下,除了个别几张图片,大多还是能正确识别的。
二、分析
文件名login,类名Tencent
相关依赖
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
from selenium import webdriver
import cv2 as cv
import requests
import random
import time
安装第三方库openCV:pip install opencv-python
构造函数
def __init__(self, url, username, password):
"""
初始化浏览器配置,声明变量
:param url: 要登录的网站地址
:param username: 账号
:param password: 密码
"""
# profile = webdriver.FirefoxOptions() # 配置无头
# profile.add_argument('-headless')
self.browser = webdriver.Chrome()
self.wait = WebDriverWait(self.browser, 20)
self.url = url # 目标url
self.username = username # 用户名
self.password = password # 密码
注释掉的代码是大佬的,因为我要看一下滑块滑动的过程,所以没有配置无头模式。
程序退出后的操作
def end(self):
"""
结束后退出,可选
:return:
"""
self.browser.quit()
大佬没有写析构函数,大概是因为end()可选吧
填写个人信息
def set_info(self):
"""
填写个人信息,在子类中完成
"""
pass
这个是我后面加上去的,通过后期子类的继承,可以定制不同网站的登录。感觉在父类里面写的话太乱了,于是写个空的放在这里。
(强迫症)
保存图片
@staticmethod
def save_img(bk_block):
"""
保存图片
:param bk_block: 图片url
:return: bool类型,是否被保存
"""
try:
img = requests.get(bk_block).content
with open('bg.jpeg', 'wb') as f:
f.write(img)
return True
except:
return False
缺口识别
@staticmethod
def get_pos():
"""
识别缺口
注意:网页上显示的图片为缩放图片,缩放 50% 所以识别坐标需要 0.5
:return: 缺口位置
"""
image = cv.imread('bg.jpeg')
# 高斯滤波
blurred = cv.GaussianBlur(image, (5, 5), 0)
# 边缘检测
canny = cv.Canny(blurred, 200, 400)
# 轮廓检测
contours, hierarchy = cv.findContours(
canny, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
for i, contour in enumerate(contours):
m = cv.moments(contour)
if m['m00'] == 0:
cx = cy = 0
else:
cx, cy = m['m10'] / m['m00'], m['m01'] / m['m00']
if 6000 < cv.contourArea(contour) < 8000 and 370 < cv.arcLength(contour, True) < 390:
if cx < 400:
continue
x, y, w, h = cv.boundingRect(contour) # 外接矩形
cv.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
# cv.imshow('image', image) # 显示识别结果
print('【缺口识别】 {x}px'.format(x=x / 2))
return x / 2
return 0
重点难点来了,openCV的高级应用。边缘检测和轮廓检测看似简单,但其中的参数很难把控,到了下面的for循环,我就晕了,大概就是找出轮廓的具体位置。
关于openCV目前我是不会再研究下去了,感兴趣的朋友可以看看CSDN上的一个大佬的博客专栏:分享链接----<<<<
模拟滑块轨迹
@staticmethod
def get_track(distance):
"""
轨迹方程
:param distance: 距缺口的距离
:return: 位移列表
"""
distance -= 75 # 初始位置
# 初速度
v = 0
# 单位时间为0.2s来统计轨迹,轨迹即0.2内的位移
t = 0.2
# 位移/轨迹列表,列表内的一个元素代表0.2s的位移
tracks = []
# 当前的位移
current = 0
# 到达mid值开始减速
mid = distance * 4 / 5
distance += 10 # 先滑过一点,最后再反着滑动回来
# a = random.randint(1,3)
while current < distance:
if current < mid:
# 加速度越小,单位时间的位移越小,模拟的轨迹就越多越详细
# a = random.randint(2, 4) # 加速运动
a = 3
else:
# a = -random.randint(3, 5) # 减速运动
a = -2
# 初速度
v0 = v
# 0.2秒时间内的位移
s = v0 * t + 0.5 * a * (t ** 2)
# 当前的位置
current += s
# 添加到轨迹列表
tracks.append(round(s))
# 速度已经达到v,该速度作为下次的初速度
v = v0 + a * t
# 反着滑动到大概准确位置
for i in range(4):
tracks.append(-random.randint(2, 3))
for i in range(4):
tracks.append(-random.randint(1, 3))
return tracks
因为人们在滑动滑块的时候大多是先加速后减速,有时还会倒退,所以不可以做匀速直线运动,要做变速,变加速直线运动。
高中物理知识:
初速度:v0、位移:x、时间:t、加速度:a,满足如下公式:
x = v0 * t + 1/2 * a * t^2
滑块的缺口位置一开始是-37的,但我经过调试后发现老是会滑到最右端超出了界限,所以改成了-75。mid为减速阈值,到了mid距离即开始减速。另外为了提高通过率,大佬还模仿了后退的操作。
主要实现函数
def tx_code(self):
"""
主要部分,函数入口
:return: bool值,是否识别成功
"""
self.set_info()
WebDriverWait(self.browser, 20, 0.5).until(
EC.presence_of_element_located((By.ID, 'tcaptcha_iframe'))) # 等待 iframe
self.browser.switch_to.frame(
self.browser.find_element_by_id('tcaptcha_iframe')) # 加载 iframe
time.sleep(0.5)
bk_block = self.browser.find_element_by_xpath(
'//img[@id="slideBg"]').get_attribute('src')
print(bk_block)
if self.save_img(bk_block):
dex = self.get_pos()
if dex:
track_list = self.get_track(dex)
time.sleep(0.5)
slid_ing = self.browser.find_element_by_xpath(
'//div[@id="tcaptcha_drag_thumb"]') # 滑块定位
ActionChains(self.browser).click_and_hold(
on_element=slid_ing).perform() # 鼠标按下
time.sleep(0.2)
print('轨迹', track_list)
for track in track_list:
ActionChains(self.browser).move_by_offset(
xoffset=track, yoffset=0).perform() # 鼠标移动到距离当前位置(x,y)
time.sleep(1)
ActionChains(self.browser).release(
on_element=slid_ing).perform() # print('第三步,释放鼠标')
time.sleep(1)
# 识别图片
return True
else:
self.re_start()
else:
print('缺口图片捕获失败')
return False
这个就还是定位元素的老套路了,不多做解释。
准备开始
def re_start(self):
"""
准备开始
:return: None
"""
self.tx_code()
# self.end()
三、完整代码及如何使用
基于PyCarm、python3.8、selenium3.141.0、opencv-python4.3.0.36
完整代码
# -*- coding: utf-8 -*-
"""
@author:Pineapple
@contact:cppjavapython@foxmail.com
@time:2020/8/2 17:29
@file:login.py
@desc: login with Tencen .
"""
from selenium.webdriver.support import expected_conditions as EC # 显性等待
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
from selenium import webdriver
import cv2 as cv
import requests
import random
import time
class Tencent:
"""
识别腾讯验证码
"""
def __init__(self, url, username, password):
"""
初始化浏览器配置,声明变量
:param url: 要登录的网站地址
:param username: 账号
:param password: 密码
"""
# profile = webdriver.FirefoxOptions() # 配置无头
# profile.add_argument('-headless')
self.browser = webdriver.Chrome()
self.wait = WebDriverWait(self.browser, 20)
self.url = url # 目标url
self.username = username # 用户名
self.password = password # 密码
def end(self):
"""
结束后退出,可选
:return:
"""
self.browser.quit()
def set_info(self):
"""
填写个人信息,在子类中完成
"""
pass
def tx_code(self):
"""
主要部分,函数入口
:return:
"""
self.set_info()
WebDriverWait(self.browser, 20, 0.5).until(
EC.presence_of_element_located((By.ID, 'tcaptcha_iframe'))) # 等待 iframe
self.browser.switch_to.frame(
self.browser.find_element_by_id('tcaptcha_iframe')) # 加载 iframe
time.sleep(0.5)
bk_block = self.browser.find_element_by_xpath(
'//img[@id="slideBg"]').get_attribute('src')
print(bk_block)
if self.save_img(bk_block):
dex = self.get_pos()
if dex:
track_list = self.get_track(dex)
time.sleep(0.5)
slid_ing = self.browser.find_element_by_xpath(
'//div[@id="tcaptcha_drag_thumb"]') # 滑块定位
ActionChains(self.browser).click_and_hold(
on_element=slid_ing).perform() # 鼠标按下
time.sleep(0.2)
print('轨迹', track_list)
for track in track_list:
ActionChains(self.browser).move_by_offset(
xoffset=track, yoffset=0).perform() # 鼠标移动到距离当前位置(x,y)
time.sleep(1)
ActionChains(self.browser).release(
on_element=slid_ing).perform() # print('第三步,释放鼠标')
time.sleep(1)
# 识别图片
return True
else:
self.re_start()
else:
print('缺口图片捕获失败')
return False
@staticmethod
def save_img(bk_block):
"""
保存图片
:param bk_block: 图片url
:return: bool类型,是否被保存
"""
try:
img = requests.get(bk_block).content
with open('bg.jpeg', 'wb') as f:
f.write(img)
return True
except:
return False
@staticmethod
def get_pos():
"""
识别缺口
注意:网页上显示的图片为缩放图片,缩放 50% 所以识别坐标需要 0.5
:return: 缺口位置
"""
image = cv.imread('bg.jpeg')
# 高斯滤波
blurred = cv.GaussianBlur(image, (5, 5), 0)
# 边缘检测
canny = cv.Canny(blurred, 200, 400)
# 轮廓检测
contours, hierarchy = cv.findContours(
canny, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
for i, contour in enumerate(contours):
m = cv.moments(contour)
if m['m00'] == 0:
cx = cy = 0
else:
cx, cy = m['m10'] / m['m00'], m['m01'] / m['m00']
if 6000 < cv.contourArea(contour) < 8000 and 370 < cv.arcLength(contour, True) < 390:
if cx < 400:
continue
x, y, w, h = cv.boundingRect(contour) # 外接矩形
cv.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
# cv.imshow('image', image) # 显示识别结果
print('【缺口识别】 {x}px'.format(x=x / 2))
return x / 2
return 0
@staticmethod
def get_track(distance):
"""
轨迹方程
:param distance: 距缺口的距离
:return: 位移列表
"""
distance -= 75 # 初始位置
# 初速度
v = 0
# 单位时间为0.2s来统计轨迹,轨迹即0.2内的位移
t = 0.2
# 位移/轨迹列表,列表内的一个元素代表0.2s的位移
tracks = []
# 当前的位移
current = 0
# 到达mid值开始减速
mid = distance * 4 / 5
distance += 10 # 先滑过一点,最后再反着滑动回来
# a = random.randint(1,3)
while current < distance:
if current < mid:
# 加速度越小,单位时间的位移越小,模拟的轨迹就越多越详细
# a = random.randint(2, 4) # 加速运动
a = 3
else:
# a = -random.randint(3, 5) # 减速运动
a = -2
# 初速度
v0 = v
# 0.2秒时间内的位移
s = v0 * t + 0.5 * a * (t ** 2)
# 当前的位置
current += s
# 添加到轨迹列表
tracks.append(round(s))
# 速度已经达到v,该速度作为下次的初速度
v = v0 + a * t
# 反着滑动到大概准确位置
for i in range(4):
tracks.append(-random.randint(2, 3))
for i in range(4):
tracks.append(-random.randint(1, 3))
return tracks
def move_to(self, index):
"""
移动滑块
:param index:
:return:
"""
pass
def re_start(self):
"""
准备开始
:return: None
"""
self.tx_code()
# self.end()
如何使用
前面说过了,或者代码注释里也有,要写一个子类继承它,并完成set_info()函数。
#text.py 和 login.py在同一目录下
# -*- coding: utf-8 -*-
"""
@author:Pineapple
@contact:cppjavapython@foxmail.com
@time:2020/7/29 9:00
@file:#test.py
@desc: 测试-登录腾讯网
"""
from selenium.common.exceptions import TimeoutException
from login import Tencent
from login import EC
from login import By
import time
class Tencent_net(Tencent):
"""
Tencent的子类,完成set_info()函数
"""
def set_info(self):
"""
填写表单信息
:return: None
"""
self.browser.get(url=self.url)
try:
# 首页登录按钮
login_button = self.wait.until(EC.element_to_be_clickable((
By.CSS_SELECTOR, 'div#top-login > div.item.item-login.fl > a.l-login'
)))
login_button.click()
# 登录子页面
self.wait.until(EC.presence_of_all_elements_located((
By.ID, 'ptlogin_iframe'
)))
# 进入登录子页面
self.browser.switch_to.frame(
self.browser.find_element_by_id('ptlogin_iframe')
)
# qq账号登录
qq_login = self.wait.until(EC.element_to_be_clickable((
By.ID, 'switcher_plogin'
)))
qq_login.click()
# 用户名
input_username = self.wait.until(EC.presence_of_element_located((
By.ID, 'u'
)))
# 密码
input_password = self.wait.until(EC.presence_of_element_located((
By.ID, 'p'
)))
input_username.send_keys(self.username)
input_password.send_keys(self.password)
time.sleep(1)
qq_login_button = self.wait.until(EC.element_to_be_clickable((
By.ID, 'login_button'
)))
qq_login_button.click()
except TimeoutException as e:
print('Error:', e.args)
self.set_info()
if __name__ == '__main__':
url=input('url:')
username=input('账号:')
password=input('密码:')
tencent=Tencent_net(url,username,password)
tencent.re_start()
填坑1
在写子类的过程中还是遇到了一些问题,就比如点击账号密码登录这个链接:
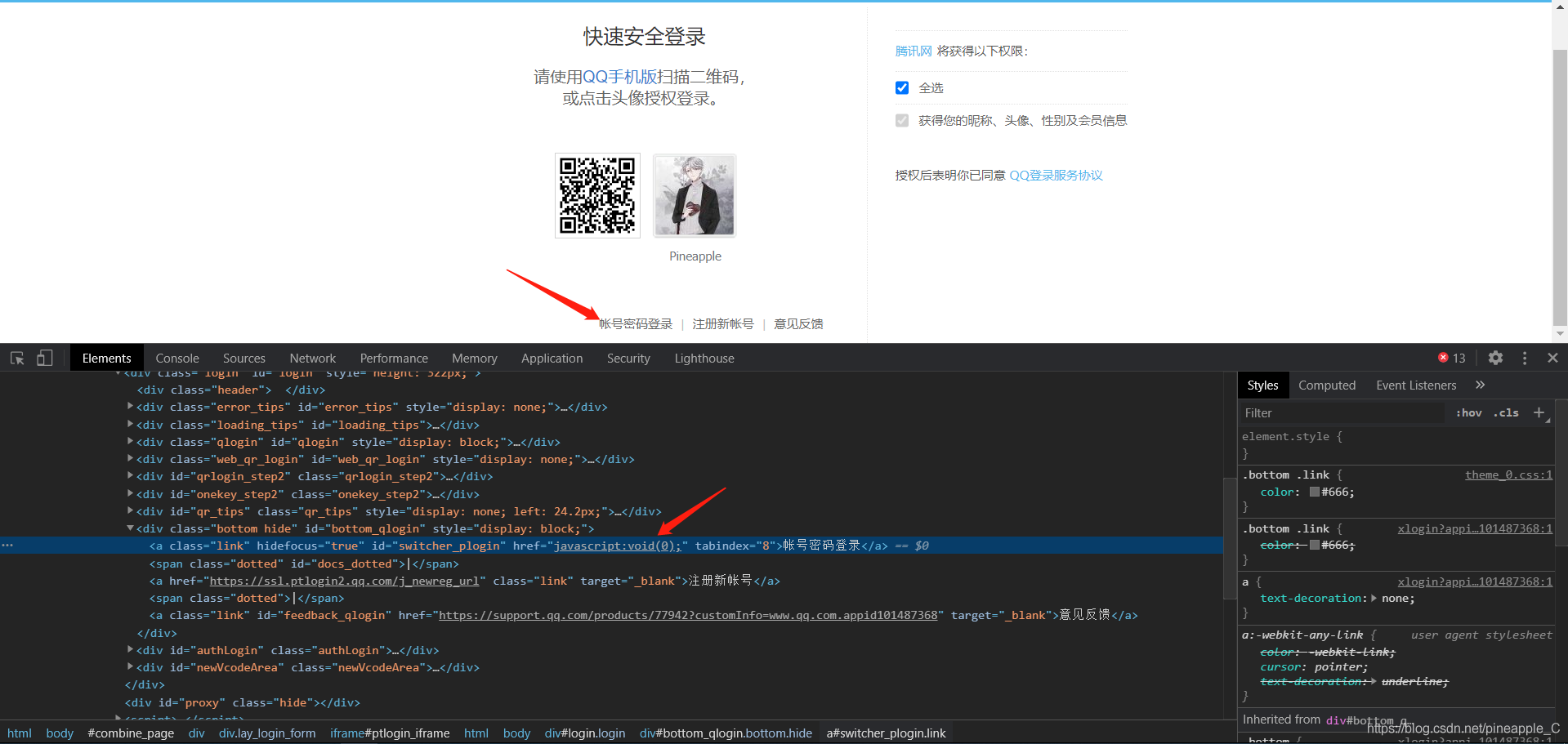 又是JavaScript:void(0)链接!!!和之前微博登录的那个还不一样,这个人为点击是可以的,可就是模拟浏览器狂点无效。让我一度误认为这种链接不可点击。
又是JavaScript:void(0)链接!!!和之前微博登录的那个还不一样,这个人为点击是可以的,可就是模拟浏览器狂点无效。让我一度误认为这种链接不可点击。
后来我把检查元素的窗口放在右边后才发现了问题:
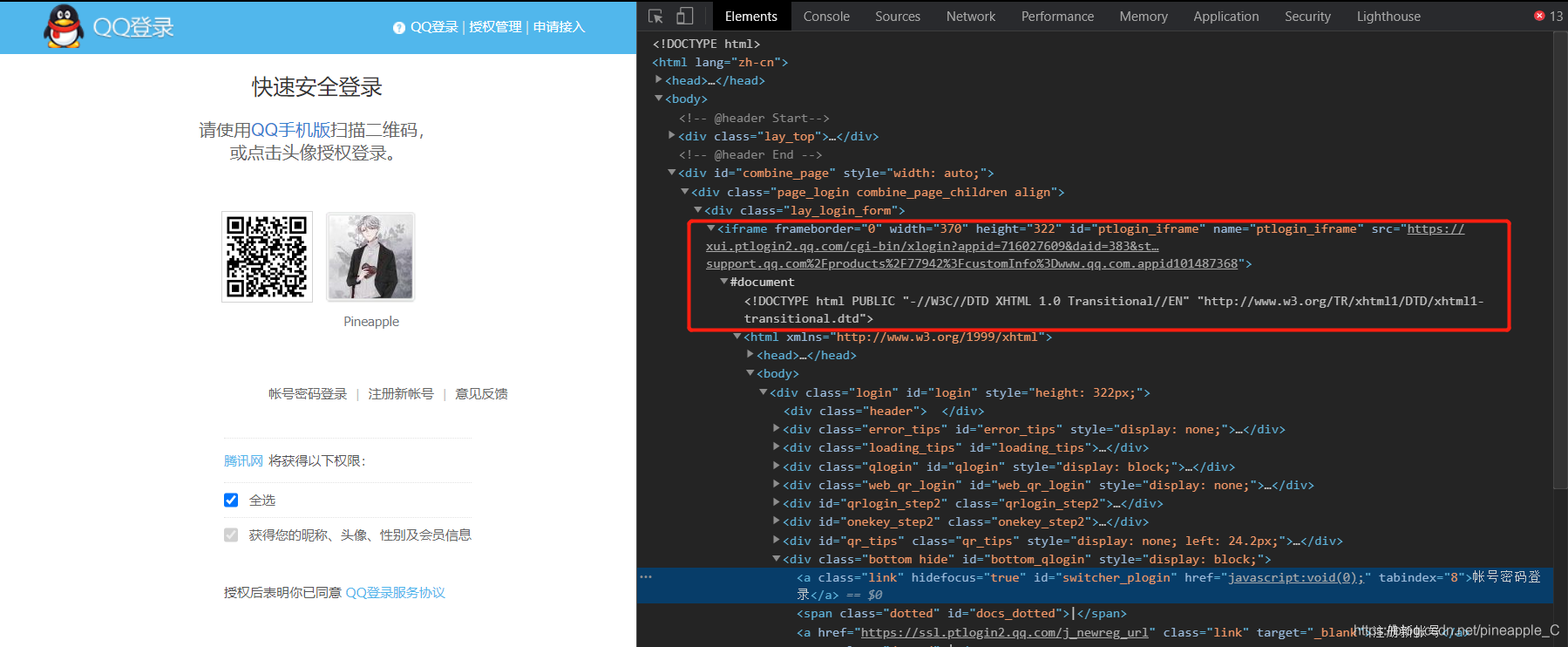
原来登录部分的页面是个子页面,之前被我盖住了没看到!selenium打开页面后默认是在父级Frame里操作的,如果还有子Frame,它是不能获取到子Frame的结点的。这时候就要用swith_to.frame()方法来切换Frame。
填坑2
如过你取消了配置无头模式,在打开浏览器的时候:
不要把鼠标放在浏览器内!!!
不要把鼠标放在浏览器内!!!
不要把鼠标放在浏览器内!!!
重要的事情说三遍,因为识别到缺口后,selenium已经模拟鼠标按住并拖动了,这时候你把鼠标移到浏览器里面,而你又没有按住,那它就会人为鼠标已经松开,释放滑块!
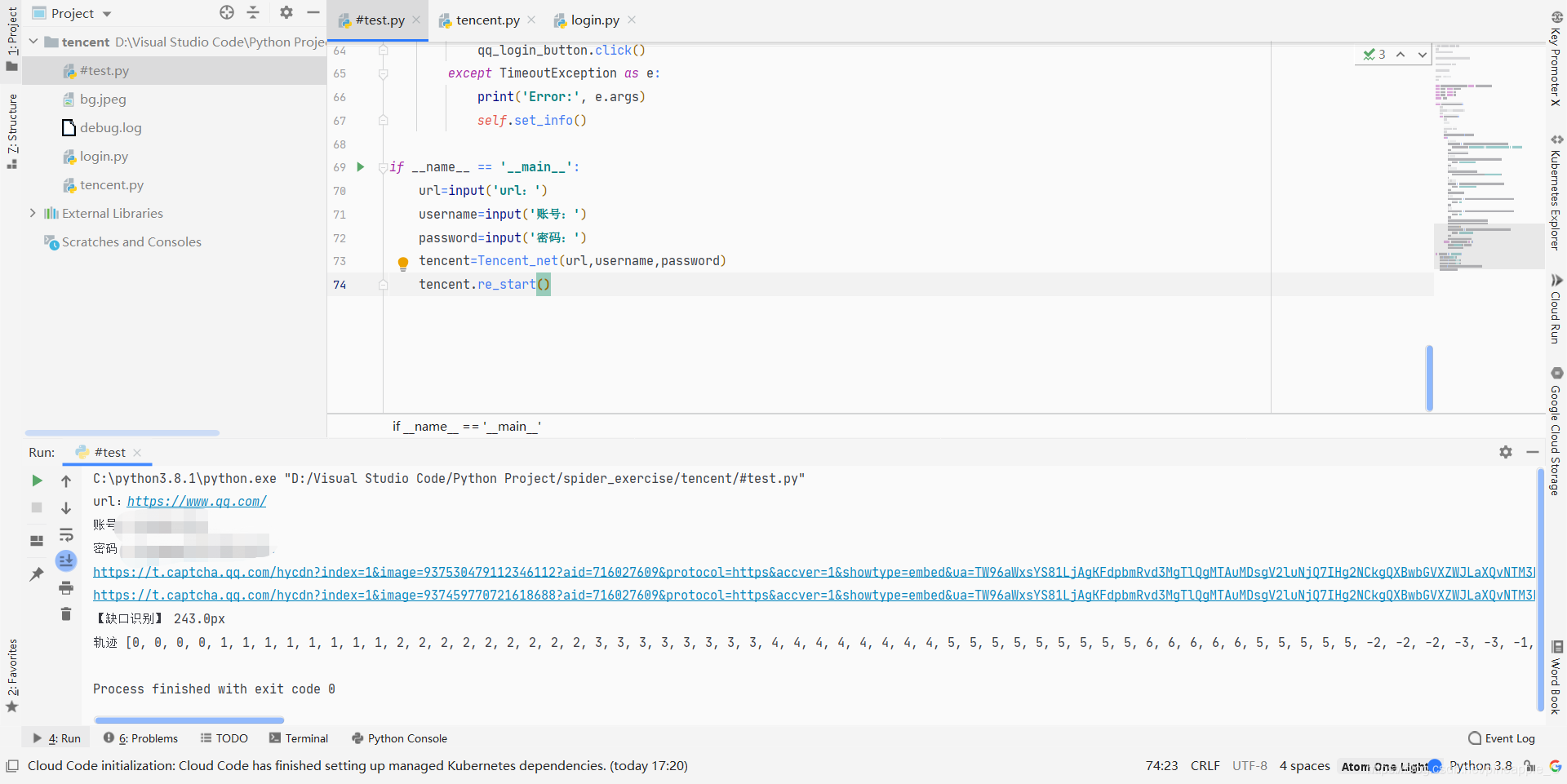
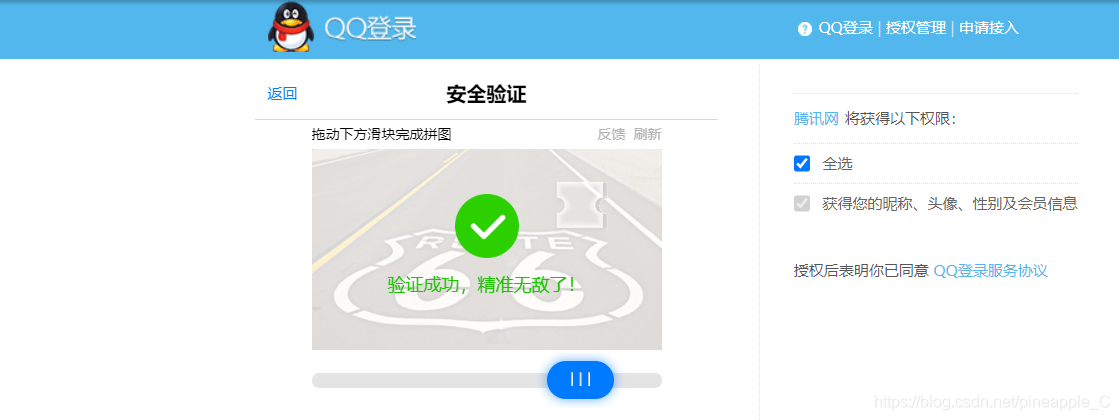
四、结果展示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号