


准备阶段
Beautifulsoup是Python的一个第三方库,它的作用和 xpath 作用一样,都是用来解析html数据
urllib.quote() 是将中文进行编码
List 的理解:desc = ['Google', 'Runoob', 'Taobao','roger','james']
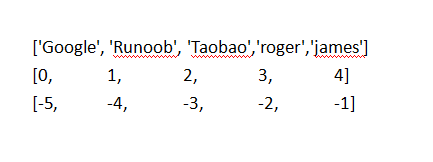
desc[0:-3] 从最左边开始取,一直到下标为-3,取值的时候是最闭右开,所以不会取下标为-3的数据;和desc[0:2]的效果是一样的 ['Google', 'Runoob']
desc[-3:]:['Taobao', 'roger', 'james']
join() 方法的理解:用于将序列中的元素以指定的字符连接生成一个新的字符串 '/'.join(desc_list[-3:]) 用"/"将list里面的数据连接起来成一个新字符串
strip()方法的理解:用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列,比如 people_num.strip('人评价') 移除people_num字符串头尾的"人评价"
基础的抓取操作
1、urllib
import urllib.request
response = urllib.request.urlopen('https://blog.csdn.net/weixin_43499626')
print(response.read().decode('utf-8'))
2、requests
requests库是一个非常实用的HTPP客户端库,是抓取操作最常用的一个库。Requests库满足很多需求
import requests # get请求 response = requests.get(url='https://blog.csdn.net/qq_21526409') print(response.text) #打印解码后的返回数据 # 带参数的requests get请求 response = requests.get(url='https://blog.csdn.net/qq_21526409', params={'key1':'value1', 'key2':'value2'})
代码:
#-*- coding: UTF-8 -*-
import sys
import time
import urllib
import urllib2
import requests
import numpy as np
from bs4 import BeautifulSoup
from openpyxl import Workbook
reload(sys)
sys.setdefaultencoding('utf8')
#Some User Agents
hds=[{'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'},\
{'User-Agent':'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11'},\
{'User-Agent': 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)'}]
def book_spider(book_tag):
page_num=0;
book_list=[]
try_times=0
while(1):
#url='http://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/book?start=0' # For Test
url='http://www.douban.com/tag/'+urllib.quote(book_tag)+'/book?start='+str(page_num*15)
time.sleep(np.random.rand()*5)
#Last Version
try:
req = urllib2.Request(url, headers=hds[page_num%len(hds)])
source_code = urllib2.urlopen(req).read()
plain_text=str(source_code)
except (urllib2.HTTPError, urllib2.URLError), e:
print e
continue
##Previous Version, IP is easy to be Forbidden
#source_code = requests.get(url)
#plain_text = source_code.text
soup = BeautifulSoup(plain_text)
list_soup = soup.find('div', {'class': 'mod book-list'})
try_times+=1;
if list_soup==None and try_times<200:
continue
elif list_soup==None or len(list_soup)<=1:
break # Break when no informatoin got after 200 times requesting
for book_info in list_soup.findAll('dd'):
title = book_info.find('a', {'class':'title'}).string.strip()
desc = book_info.find('div', {'class':'desc'}).string.strip()
desc_list = desc.split('/')
book_url = book_info.find('a', {'class':'title'}).get('href')
try:
author_info = '作者/译者: ' + '/'.join(desc_list[0:-3])
except:
author_info ='作者/译者: 暂无'
try:
pub_info = '出版信息: ' + '/'.join(desc_list[-3:])
except:
pub_info = '出版信息: 暂无'
try:
rating = book_info.find('span', {'class':'rating_nums'}).string.strip()
except:
rating='0.0'
try:
#people_num = book_info.findAll('span')[2].string.strip()
people_num = get_people_num(book_url)
people_num = people_num.strip('人评价')
except:
people_num ='0'
book_list.append([title,rating,people_num,author_info,pub_info])
try_times=0 #set 0 when got valid information
page_num+=1
print 'Downloading Information From Page %d' % page_num
return book_list
def get_people_num(url):
#url='http://book.douban.com/subject/6082808/?from=tag_all' # For Test
try:
req = urllib2.Request(url, headers=hds[np.random.randint(0,len(hds))])
source_code = urllib2.urlopen(req).read()
plain_text=str(source_code)
except (urllib2.HTTPError, urllib2.URLError), e:
print e
soup = BeautifulSoup(plain_text)
people_num=soup.find('div',{'class':'rating_sum'}).findAll('span')[1].string.strip()
return people_num
def do_spider(book_tag_lists):
book_lists=[]
for book_tag in book_tag_lists:
book_list=book_spider(book_tag)
book_list=sorted(book_list,key=lambda x:x[1],reverse=True)
book_lists.append(book_list)
return book_lists
def print_book_lists_excel(book_lists,book_tag_lists):
wb=Workbook(optimized_write=True)
ws=[]
for i in range(len(book_tag_lists)):
ws.append(wb.create_sheet(title=book_tag_lists[i].decode())) #utf8->unicode
for i in range(len(book_tag_lists)):
ws[i].append(['序号','书名','评分','评价人数','作者','出版社'])
count=1
for bl in book_lists[i]:
ws[i].append([count,bl[0],float(bl[1]),int(bl[2]),bl[3],bl[4]])
count+=1
save_path='book_list'
for i in range(len(book_tag_lists)):
save_path+=('-'+book_tag_lists[i].decode())
save_path+='.xlsx'
wb.save(save_path)
if __name__=='__main__':
#book_tag_lists = ['心理','判断与决策','算法','数据结构','经济','历史']
#book_tag_lists = ['传记','哲学','编程','创业','理财','社会学','佛教']
#book_tag_lists = ['思想','科技','科学','web','股票','爱情','两性']
#book_tag_lists = ['计算机','机器学习','linux','android','数据库','互联网']
#book_tag_lists = ['数学']
#book_tag_lists = ['摄影','设计','音乐','旅行','教育','成长','情感','育儿','健康','养生']
#book_tag_lists = ['商业','理财','管理']
#book_tag_lists = ['名著']
#book_tag_lists = ['科普','经典','生活','心灵','文学']
#book_tag_lists = ['科幻','思维','金融']
book_tag_lists = ['个人管理','时间管理','投资','文化','宗教']
book_lists=do_spider(book_tag_lists)
print_book_lists_excel(book_lists,book_tag_lists)

