
ElasticSearch
ElasticSearch概述
ElasticSearch(基于Lucene的搜索引擎)分布式的搜索功能适用于大数据。
Lucene是一位名叫Doug Cutting的美国工程师基于java做的关于文本搜索的函数库。
它是一套信息检索工具包,jar包,不包含搜索引擎系统。
包含的是:索引结构,读写索引的工具,排序,搜索规则,工具类。
Lucene和ElasticSearch的关系:
ElasticSearch是基于Lucene做的封装和增强。
ElasticSearch是restful风格。
ELK技术 ElasticSearch+logstash+kibana。
ES和Solr的差别
ES:全文搜索,结构化搜索(结合分词器进行搜索),分析,关键字高亮,基于Lucene的搜索引擎。
ES是restful风格的api。
Solr是基于Lucene的搜索引擎。
Solr是web-service风格的api。
ES和Solr的比较
1、单纯对已有的数据进行搜索 时,Solr更快。
2、一旦建立索引,Solr就会产生io阻塞,查询性能较差,ES会有更好的优势。
3、随着数据量的增加,Solr的搜索引擎效率会变的更低,而ES没有明显的变化。
4、Solr利用Zookeeper进行分布式管路,ES自带分布式管理功能。
5、ES支持json,Solr支持json、xml、CSV。
ES安装
jdk1.8,ES客户端,界面工具。
1、ES的版本和Java对应的jar包要版本对应。
解压就可以使用了
2、熟悉目录
1 2 3 4 5 6 7 8 9 | bin 启动文件config 配置文件 log4j 日志配置文件 jvm.option java虚拟机相关的配置 elasticsearch.yml es的配置文件 默认9200端口(集群、端口、网关等)lib 相关jar包logs 日志mudules 功能模块plugins 插件 ik分词器 |
双击bin目录下的elasticsearch.bat

访问后返回:
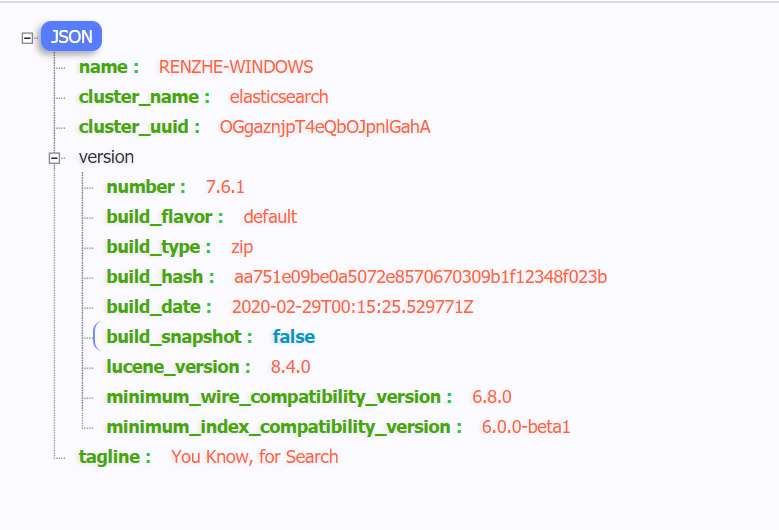
默认ES自成集群,没有配置也是集群,集群名字为:elasticsearch
安装可视化界面es head
1、下载地址:https://github.com/mobz/elasticsearch-head/
2、解决跨域问题:
在elasticsearch的配置文件中添加 http.cors.enabled: true http.cors.allow-origin: "*"
3、启动 需要有nodejs环境
1 2 | npm installnpm run start |
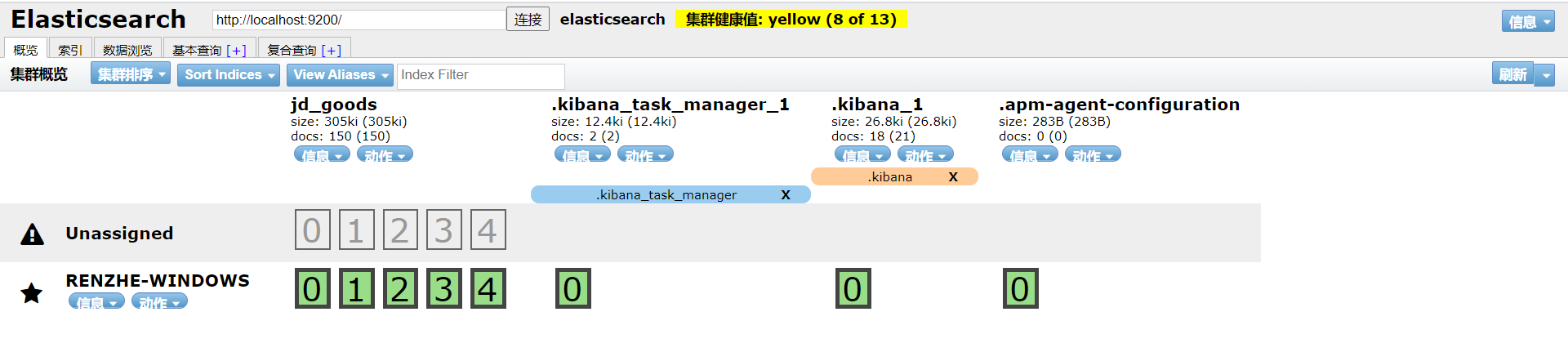
可以把索引当作一个数据库,文档就是库中的数据。
这个head就是一个数据展示工具,后面所有的查询可以在kibana上做
安装kibana
kibana版本要和es版本一致
1、下载地址:https://www.elastic.co/cn/kibana
2、解压:
3、启动:
4、修改配置,使其汉化
config-->kibana.yml
i18n.locale: "zh-CN"
5、启动后找到工具箱
es是面向文档的,一切都是json
{
}
关系型数据库和es的对比
| 关系型数据库 | ES |
| 数据库(databases) | indexs |
| 表(tables) | types |
| 行(rows) | documents |
| 列(columns) | fields |
一一对应。
文档
es是面向文档的,所以说索引和搜索数据的最小单位就是文档,es中文档有几个重要属性:
1.自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:value。
2.可以是层次型的,一个文档中包含文档,基本的逻辑实体就是这么来的(就是一个json对象,fastjson中自动转化)。
3.灵活的结构,文档不依赖预先定义的模式,关系型数据库中只有定义了字段才可以使用,在es中是非常灵活的,有时候我们可以忽略该字段,也可以动态添加一个字段。
类型
就是数据库。
索引会自动将数据存储到各个分片上。
创建索引时默认分片是5个。
倒排索引
es中使用一种称为倒排索引的结构,采用Lucene倒排索引为底层,这种结构用于快速的全文搜索。
1 2 | Study every day , good good up to forever #文档1包含的内容To forever , study every day , good good up #文档2包含的内容 |
为了创建倒排索引,我们首先要将每个文档拆分成独立的词(称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档:
| doc_1 | doc_2 | |
|---|---|---|
| Study | √ | × |
| To | × | √ |
| every | √ | √ |
| forever | √ | √ |
| day | √ | √ |
| study | × | √ |
| good | √ | √ |
| every | √ | √ |
| to | √ | × |
| up | √ |
现在,我们试图去搜索to forever,只需要查看包含每个词条的文档
| doc_1 | doc_2 | |
|---|---|---|
| to | √ | × |
| forever | √ | √ |
| total | 2 |
doc_1中的权重大,权重在es中会自动计算
IK分词器
默认的中文分词是将每个字看成一个词,比如说“我爱中国”,会被分为“我”,“爱”,“中“,”国“,这显然不符合要求,所以要使用IK分词器解决。
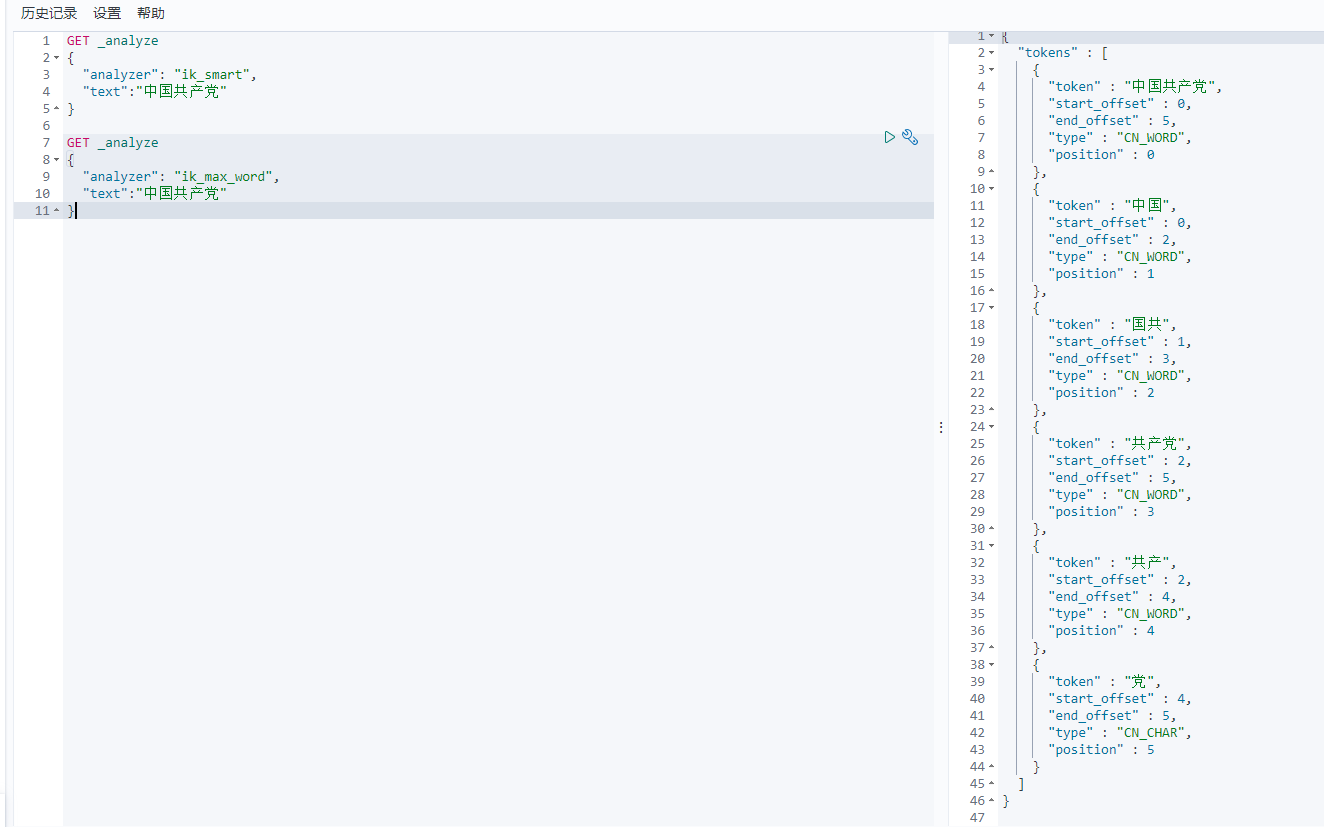
IK分词器提供两个算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分。
安装ik分词器
1、下载:https://github.com/medcl/elasticsearch-analysis-ik
2、下载完后解压放到elasticsearch的plugins的ik中(ik为创建的文件夹)
3、重启es
4、可以通过elasticsearch-plugin list查看加载的插件
5、使用kibana测试
ik_smart:最少切分

ik_max_word:最细粒度
restful风格的命令
GET :请求方式
analysis:分词器
{
}:分词要求
analyzer:选择分词器
text:操作的文本
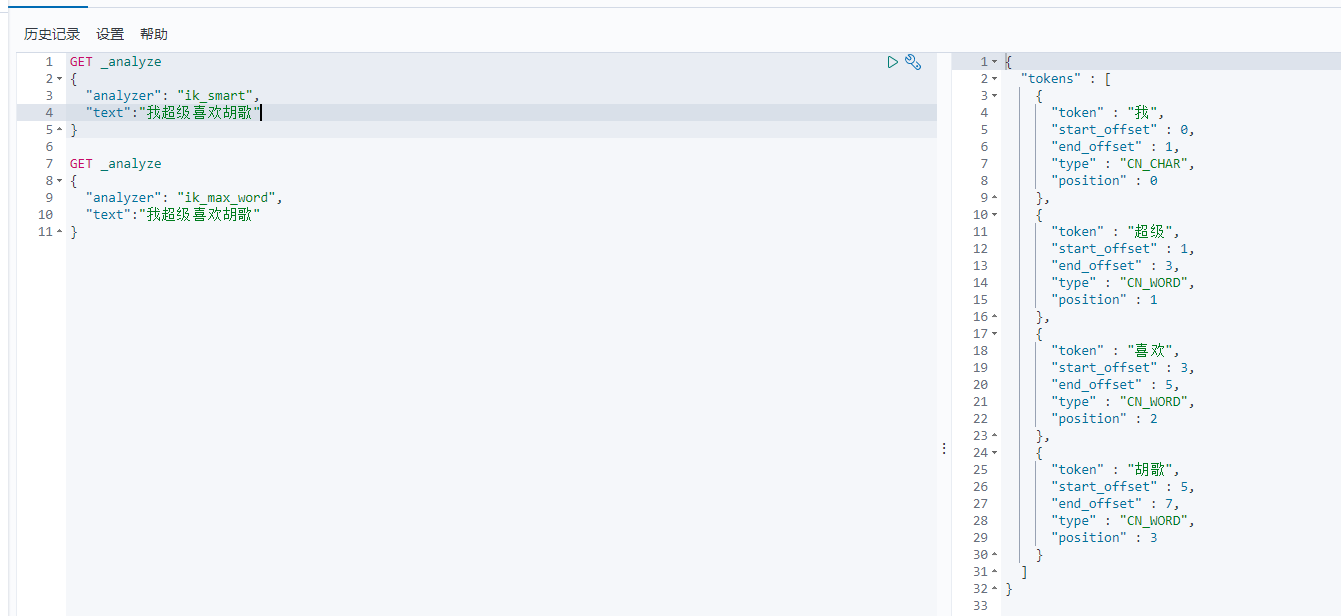
测试:文本为我超级喜欢胡歌
出现问题:它将胡歌两个字拆开了

所以这种自己需要的词需要我们自己加到分词器的字典中。
ik分词器的配置
在es中插件文件夹plugins下找ik再找config文件夹中添加自己需要的词
建立xxx.dic文件,在里面输入自己需要的词
然后将xxx.dic在IKAnalyzer.cfg.xml中引入

然后重启es

加载了huge.dic
重启kibana,重新测试文本我超级喜欢胡歌
restful风格
通过不同的命令实现不同的操作
| url地址 | 描述 | |
|---|---|---|
| PUT | localhost:9200/索引名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档id |
| POST | localhost:9200/索引名称/类型名称/_search |
基础测试
1、创建索引 PUT命令,库名为test1 类型为type1,1代表第一条数据
PUT /索引名/类型名/文档id
1 2 3 4 5 6 7 8 9 | PUT /test1/type1/1{"name":"renzhe","age":18} |
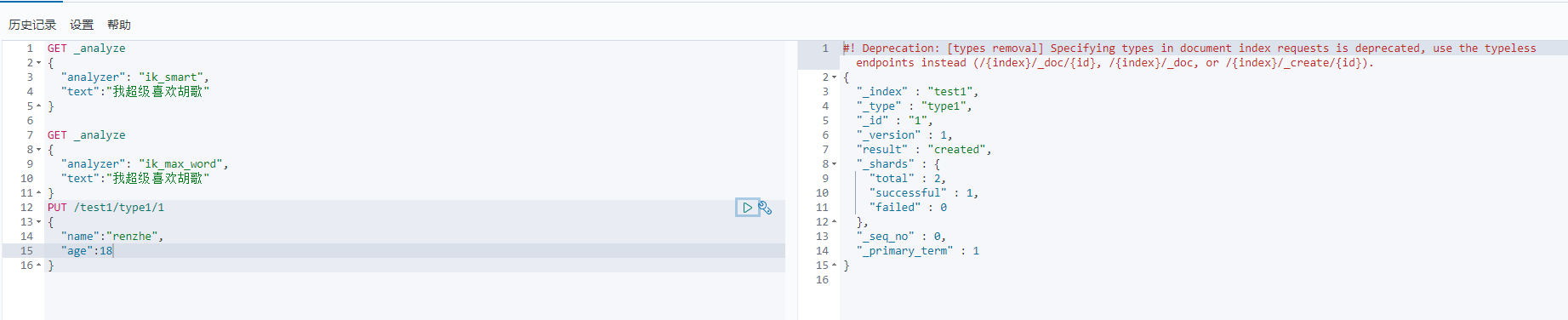
创建成功,
在es-head中查看:

插入的数据:
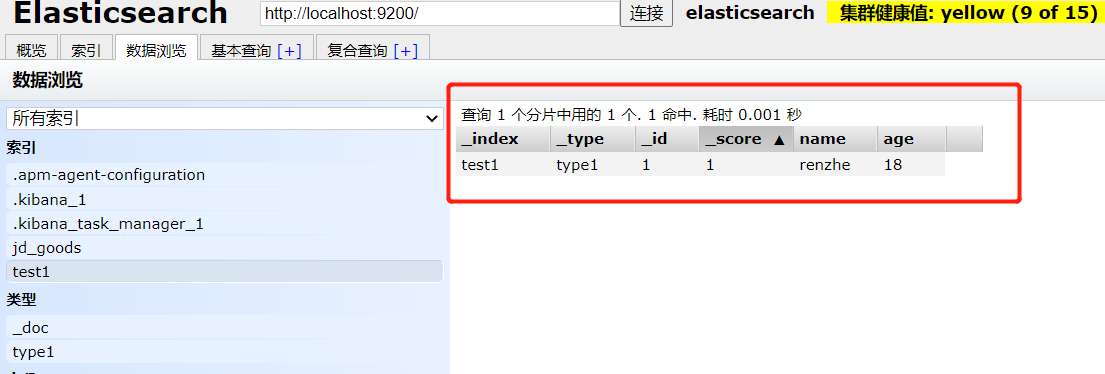
完成了自动添加了索引,数据页成功的添加了。
数据类型:
字符串类型:text 、keyword
数值类型:long、integer、short、byte、double、float、scaled float
日期类型:date
布尔类型:boolean
二进制类型:binary
等等.....
2、指定字段的类型
test2代表一个规则,在mapping中写规则
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | PUT /test2{ "mappings": { "properties": { "name":{ "type": "text" }, "age":{ "type": "long" }, "birthday":{ "type": "date" } } }} |
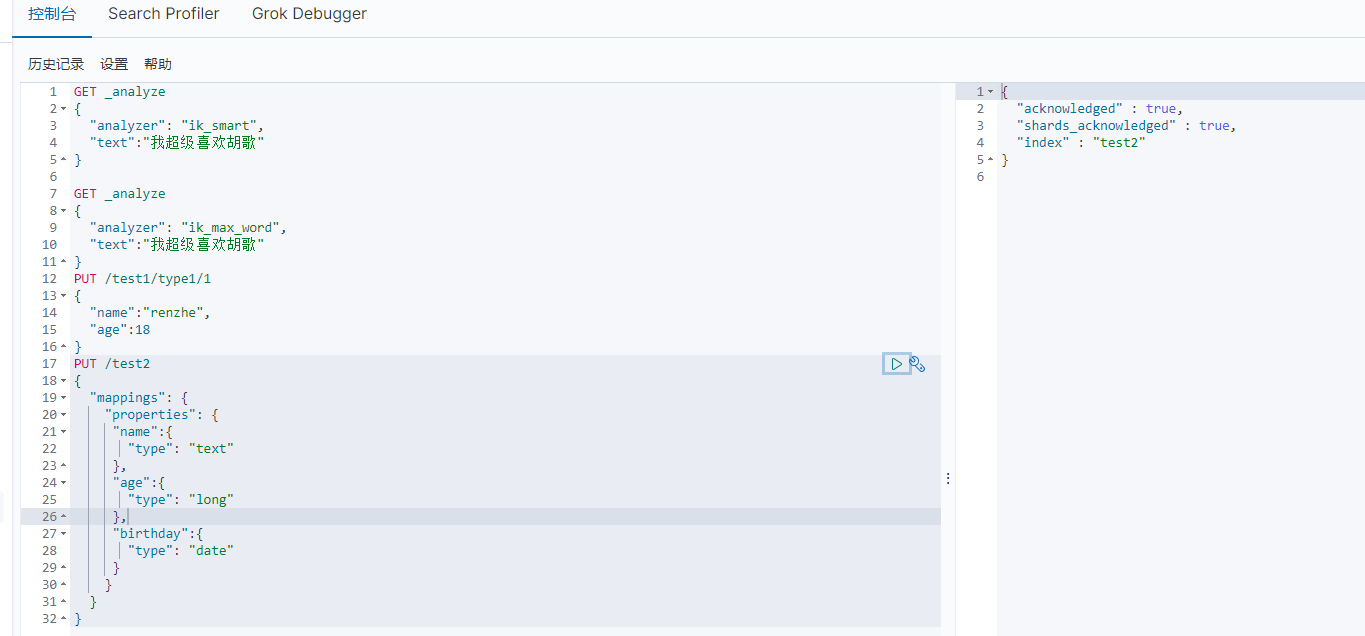
3、GET命令
GET /test2
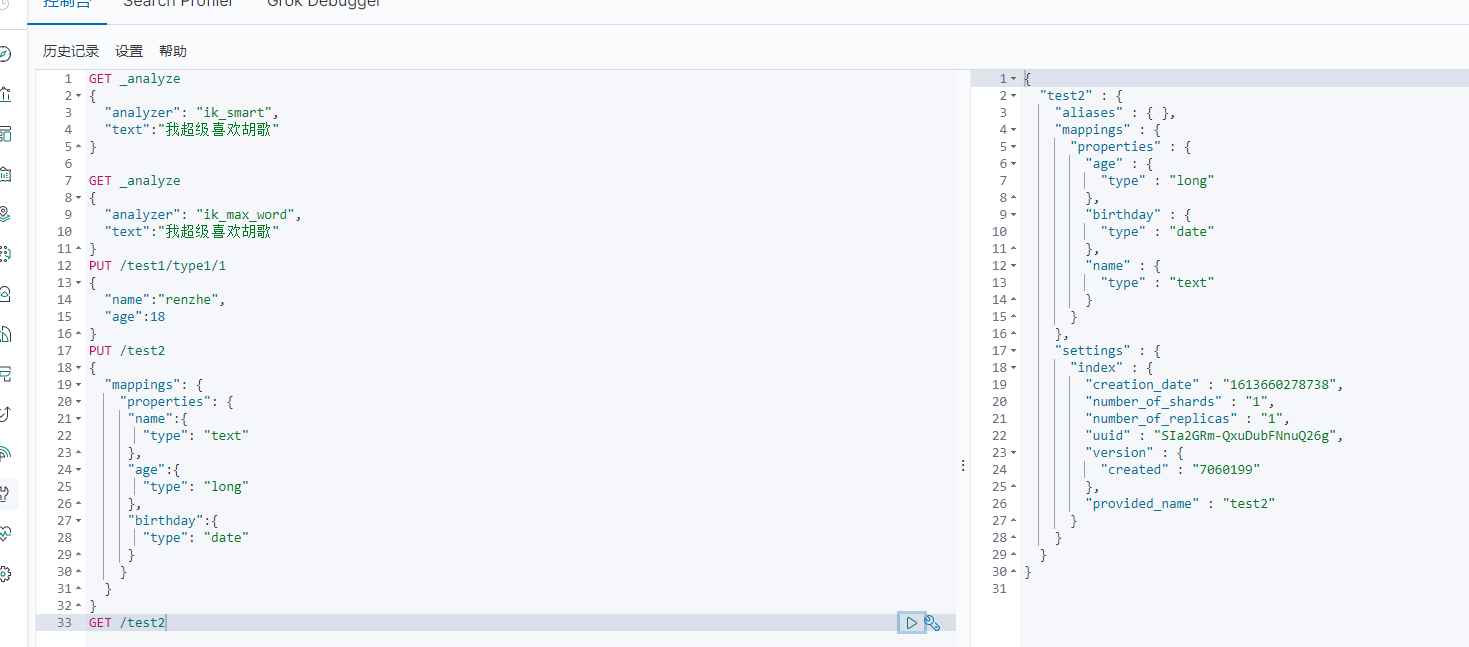
4、查看默认的信息
1 2 3 4 5 6 | PUT /test3/_doc/1{ "name":"任喆", "age":15, "birth":"1997 0924"} |
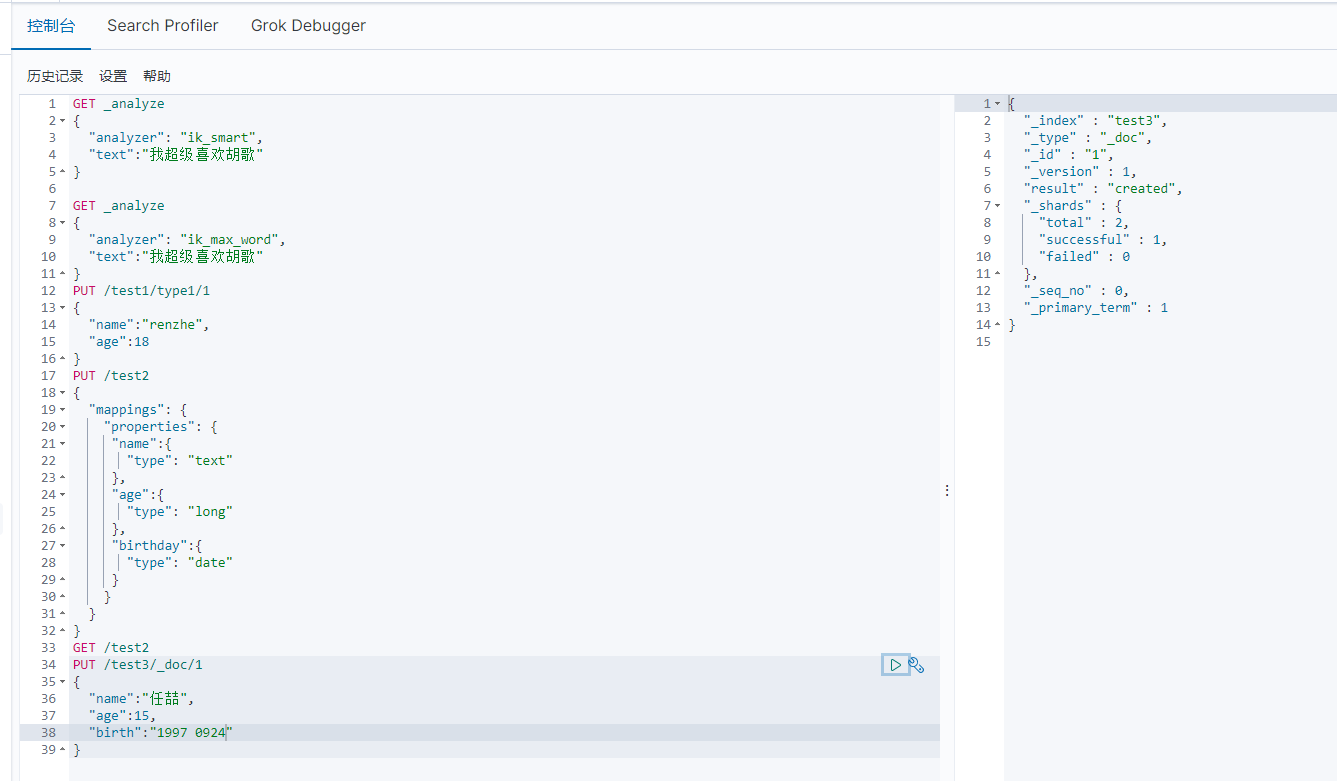
GET /test3
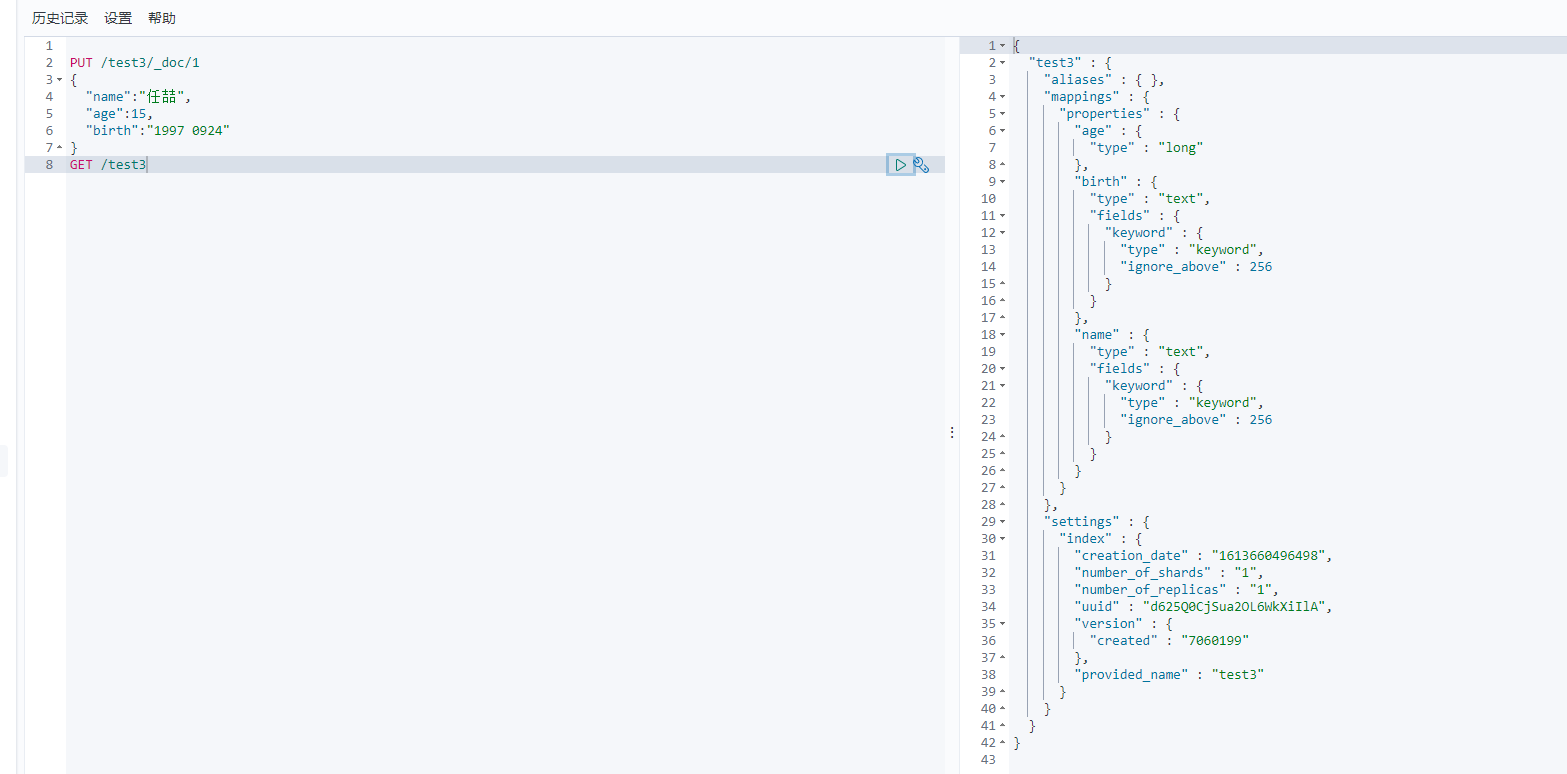
如果文档没有指定,那么es会给我们默认配置字段类型
拓展:通过命令 _cat 可以查看一些es默认信息
GET _cat/health 查看健康值
GET _cat/indices?v 查看版本信息
5、修改索引
(1)
1 2 3 4 5 6 7 8 | PUT命令 直接覆盖 version会增加PUT /test3/_doc/1{"name":"任喆a","age":15,"birth":"1997 0924"} |
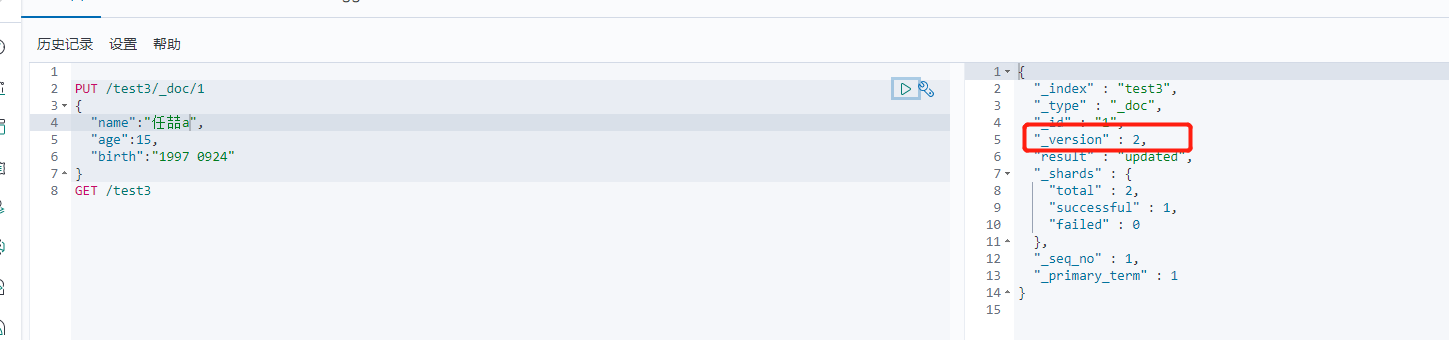
(2)
1 2 3 4 5 6 7 8 | POST命令POST /test3/_doc/1/_update{"doc":{ "name":"法外狂徒"}} |
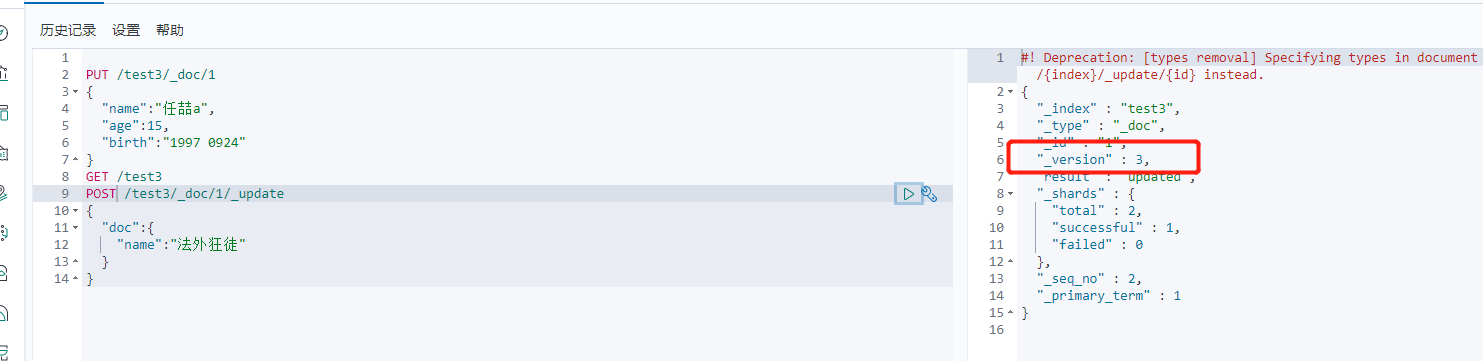
6、删除索引
通过DELETE命令实现删除,根据你的请求来判断是删除索引还是删除文档记录。

关于文档的基本操作
1、添加数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | PUT /renzhe/uer/1{ "name":"任喆", "age":15, "desc":"11111111", "tags":["阳光","正直"]}PUT /renzhe/uer/2{ "name":"任喆厉害", "age":6, "desc":"11111111", "tags":["阳光","正直"]}PUT /renzhe/uer/3{ "name":"任喆丫丫", "age":3, "desc":"11111111", "tags":["阳光","正直"]} |
2、获取数据
GET renzhe/uer/1
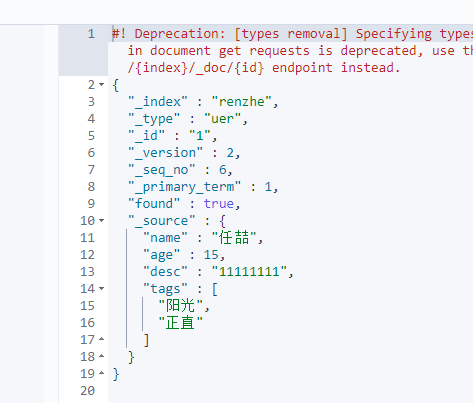
3、更新数据
1 2 3 4 5 6 7 | PUT /renzhe/uer/3{ "name":"任喆3555", "age":15, "desc":"11111111", "tags":["阳光","正直"]} |
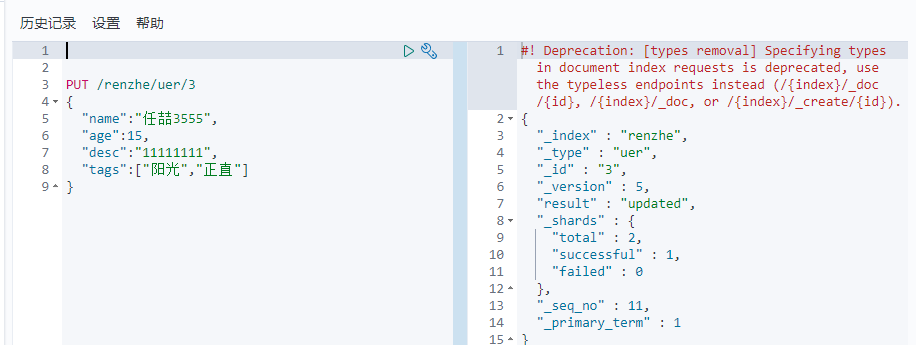
4、POTS _update 推荐使用 灵活性高 可以改任意一个值
简单的条件查询
GET renzhe/uer/_search?q=name:任喆
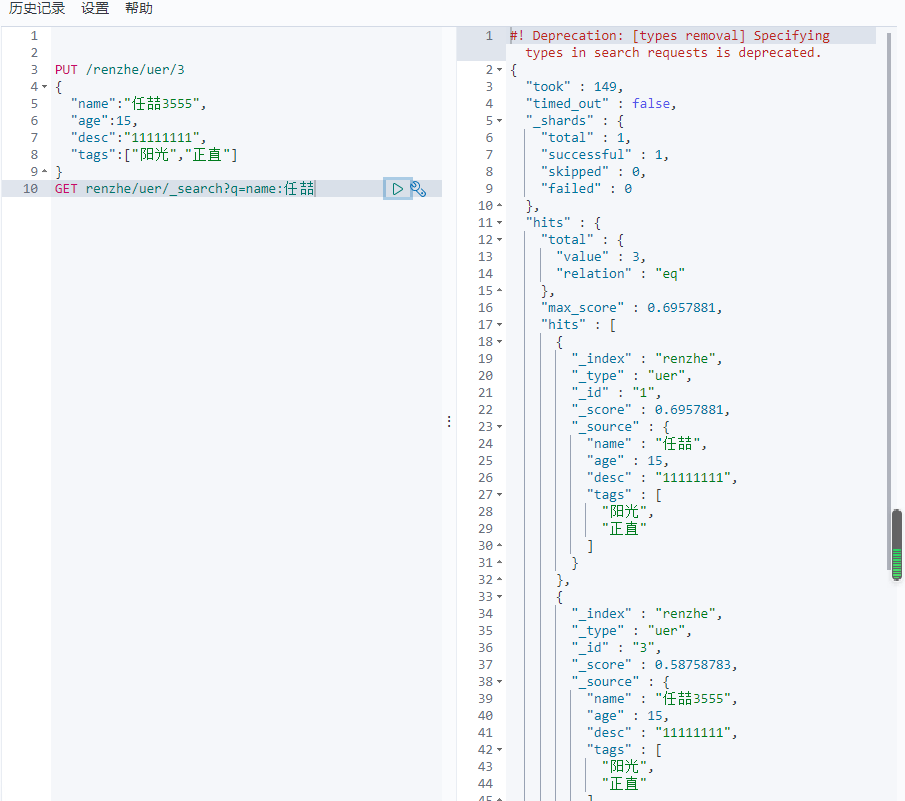
score代表匹配度,匹配度越高则分值越高。
复杂操作搜索 select(排序,分页,高亮,模糊,精准查询)
1 2 3 4 5 6 7 8 | GET renzhe/uer/_search{ "query": { "match": { "name": "任喆" } }} |
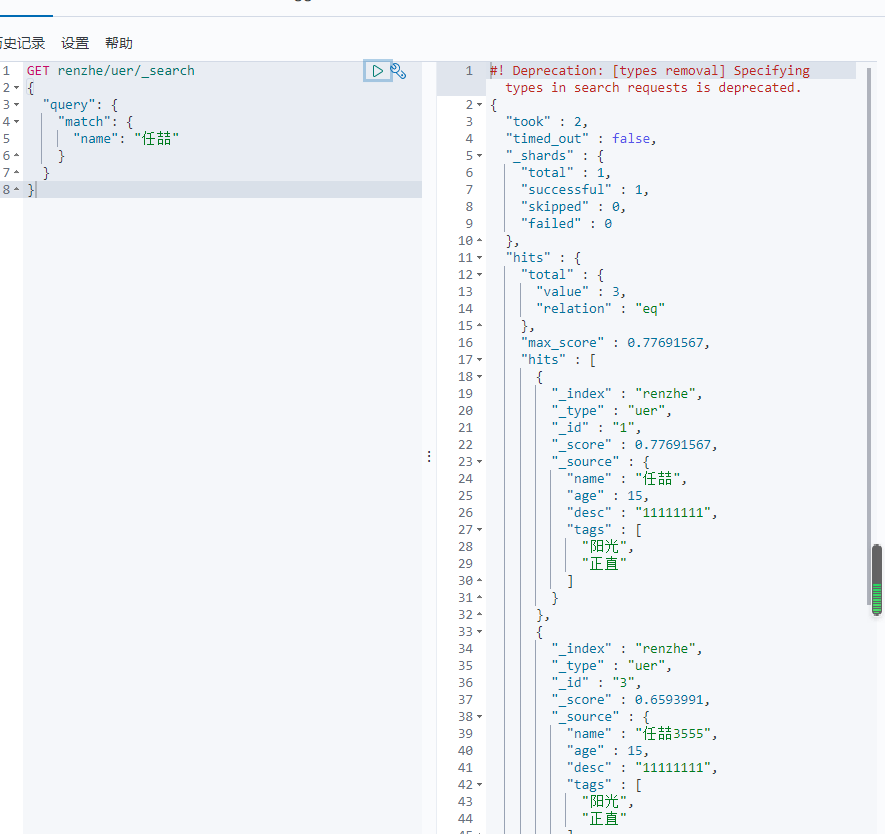
过滤属性 只查name和desc
1 2 3 4 5 6 7 8 9 | GET renzhe/uer/_search{ "query": { "match": { "name": "任喆" } }, "_source": ["name","desc"]} |

排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | GET renzhe/uer/_search{ "query": { "match": { "name": "任喆" } }, "sort": [ { "age": { "order": "desc" } } ]} |
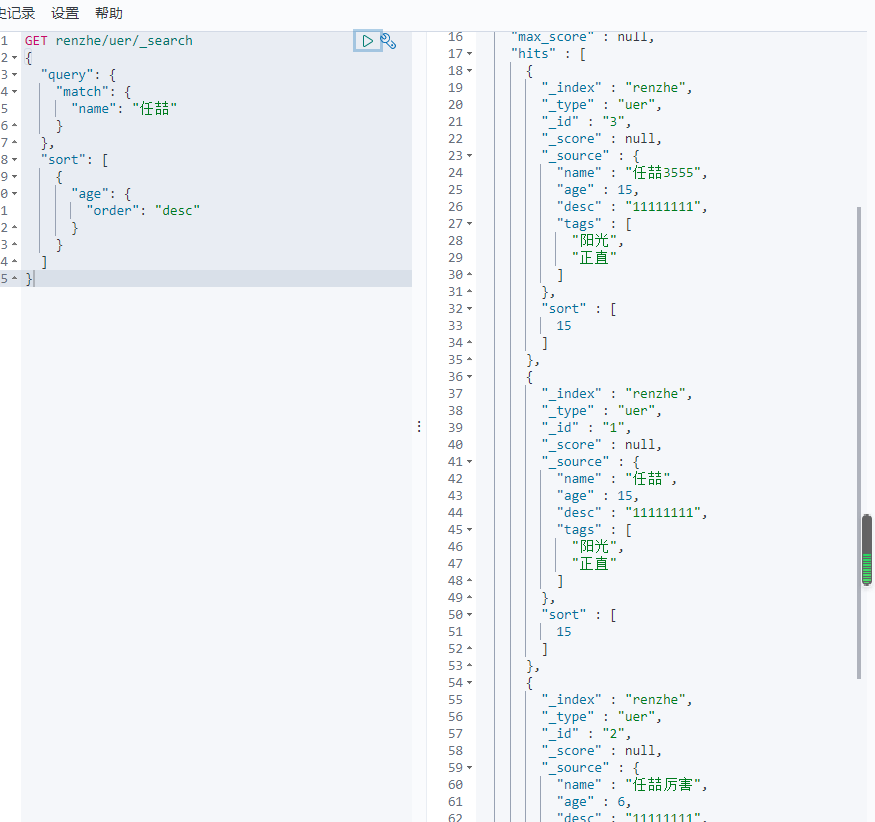
分页
from 从第几个开始 size每页多少个
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | GET renzhe/uer/_search{ "query": { "match": { "name": "任喆" } }, "sort": [ { "age": { "order": "desc" } } ], "from": 0, "size": 2} |
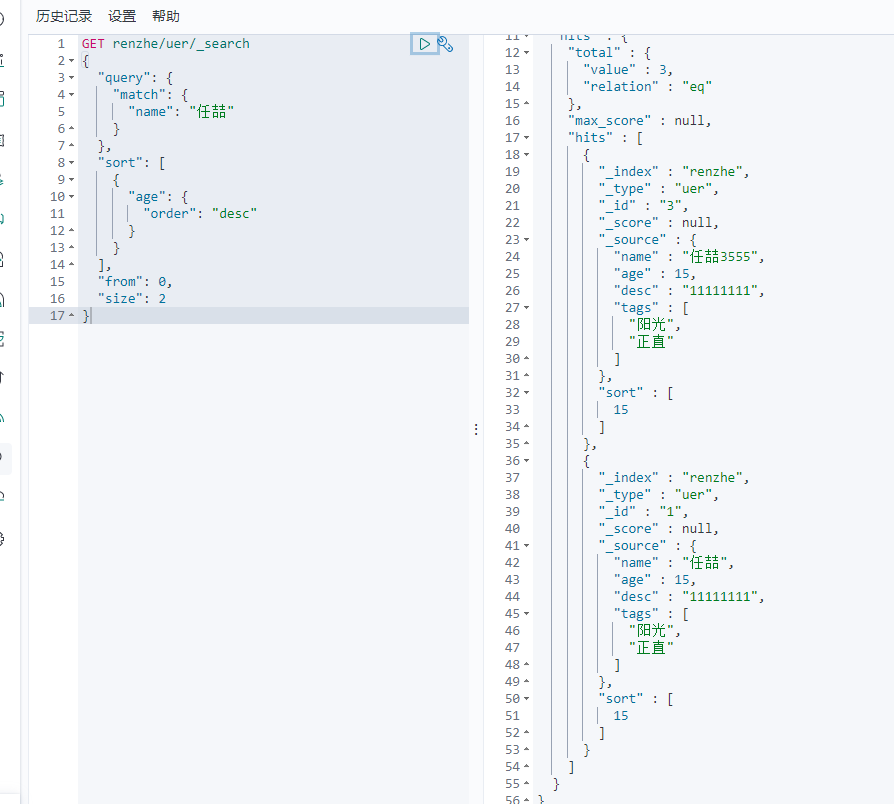
布尔值查询
must命令 所有条件都要符合
must_not命令 不符合这个条件
should命令 只要有一条数据符合既可
匹配规则 多条件匹配

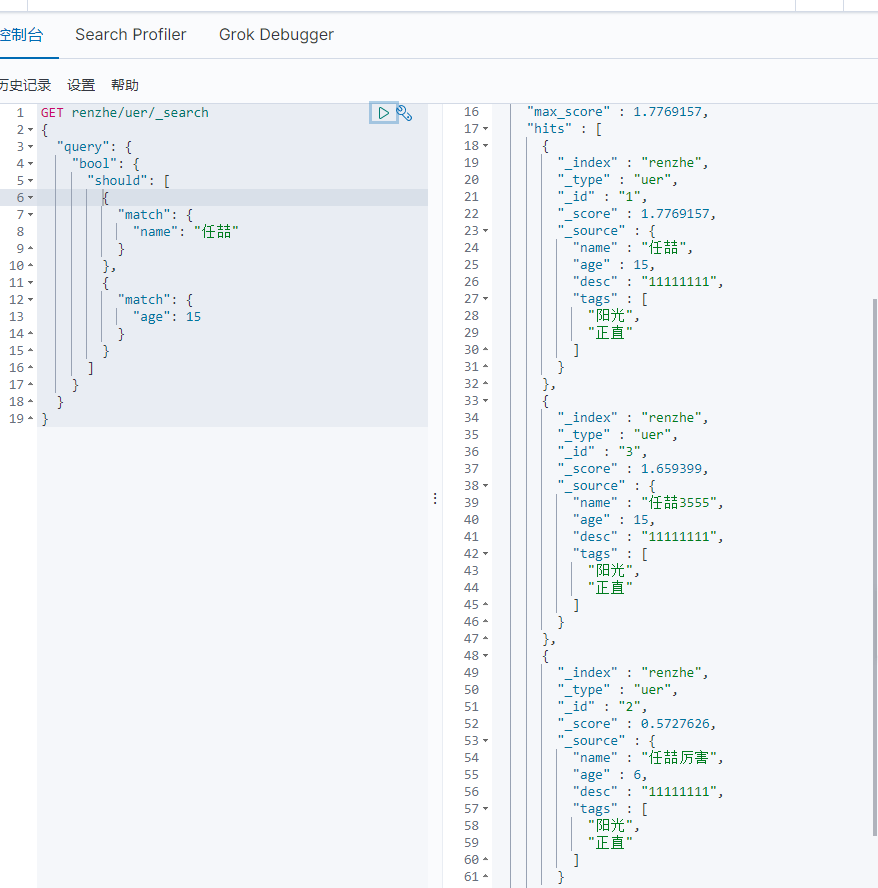
过滤器 filter 小于10岁的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | GET renzhe/uer/_search{ "query": { "bool": { "must": [ { "match": { "name": "任喆" } } ], "filter": { "range": { "age": { "lte": 10 } } } } }} |

大于 gt
大于等于 gte
小于 lt
小于等于 lte
匹配多个条件 tags 中直接用空格隔开即可 可直接根据权重判断优先级
1 2 3 4 5 6 7 8 | GET renzhe/uer/_search{ "query": { "match": { "tags": "阳 正直" } }} |
精确查询
term,直接查询精确的 效率高
match,会使用分词器解析(先分析文档,然后在通过分析的文档进行查询)
两个类型:text,keyword text会被分词器解析,而keyword不会被分词器解析
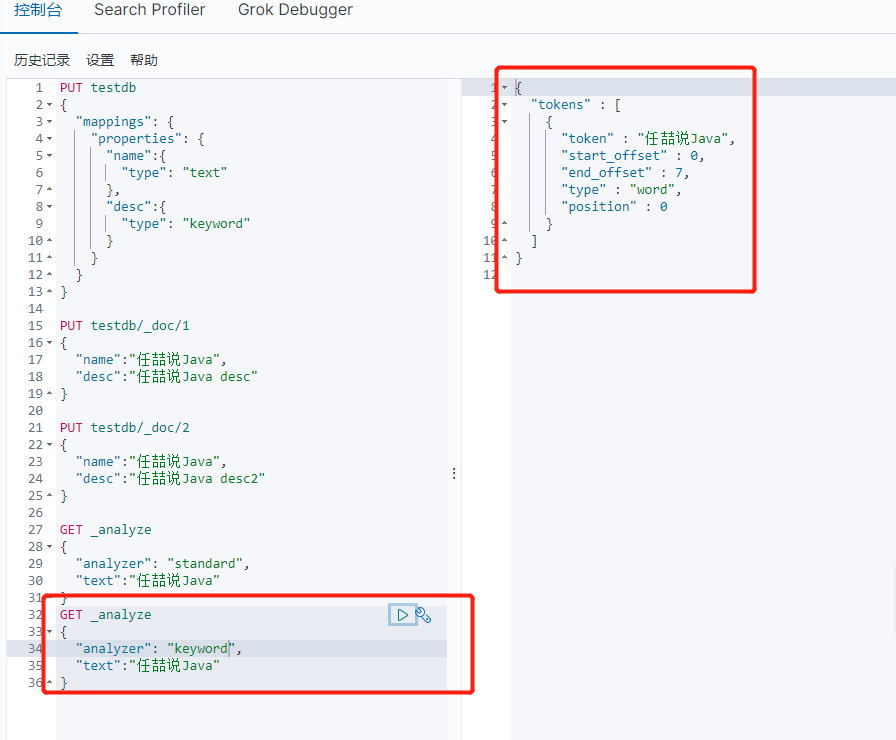
没有被分析
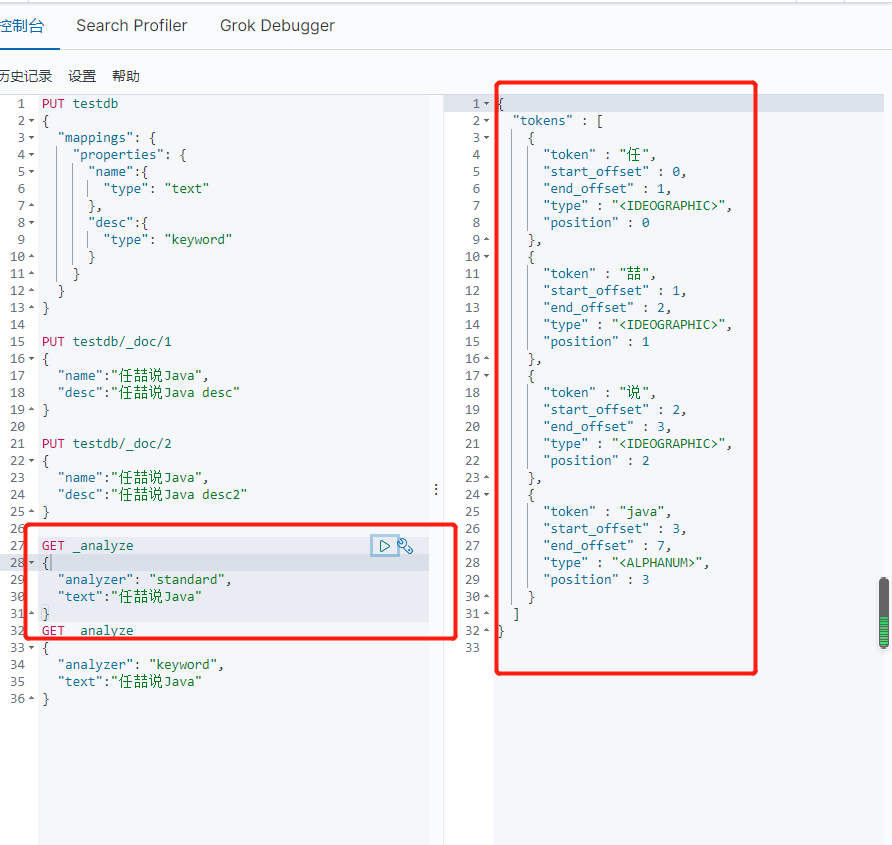
可以看到被拆分了
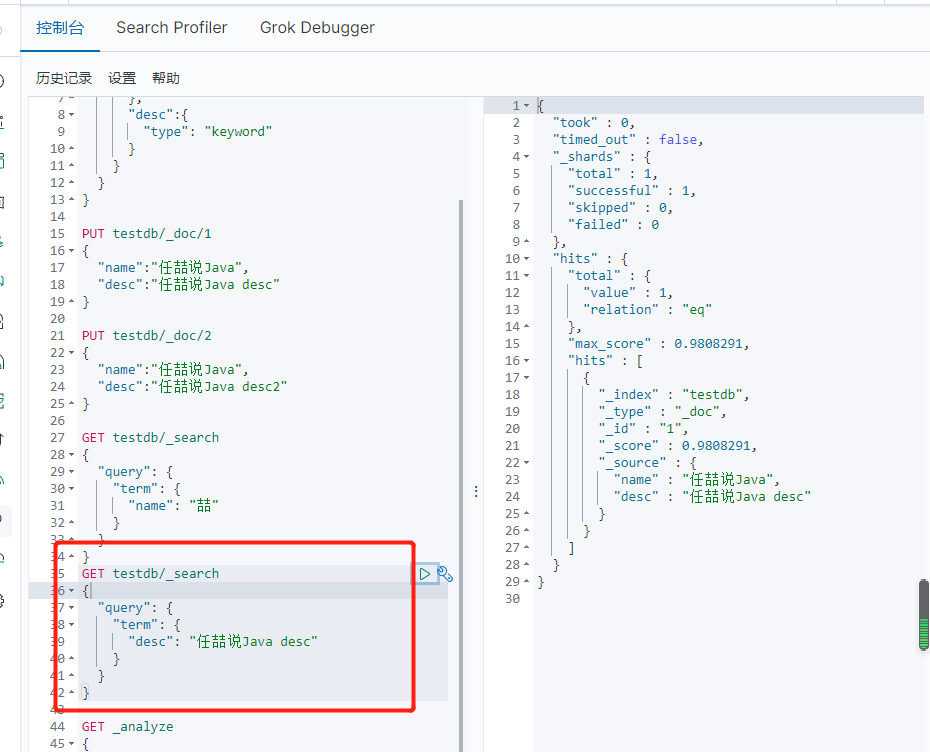
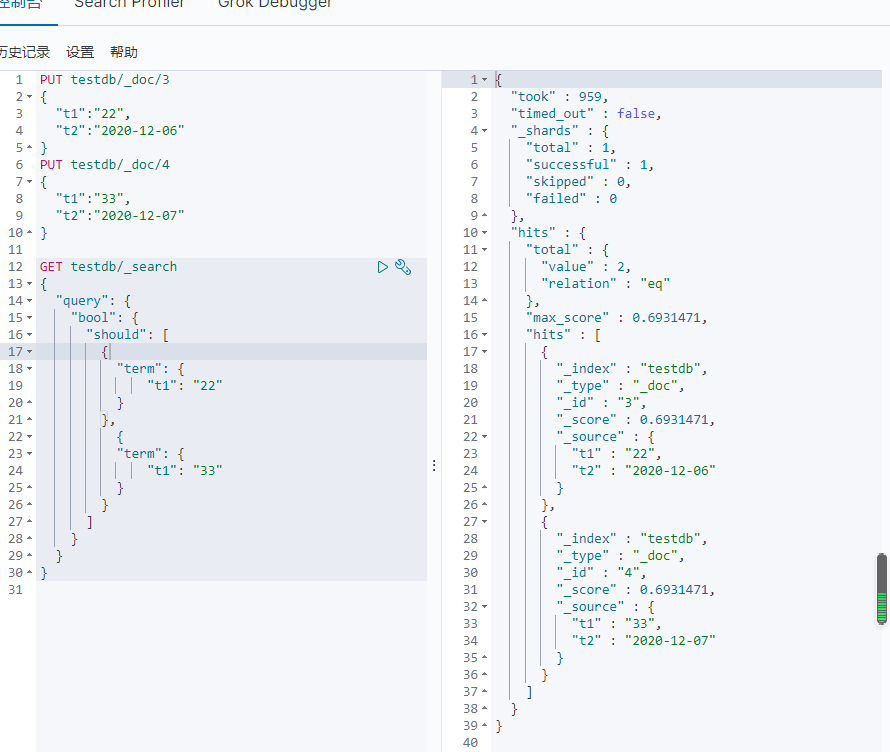
多个值匹配的精确查询
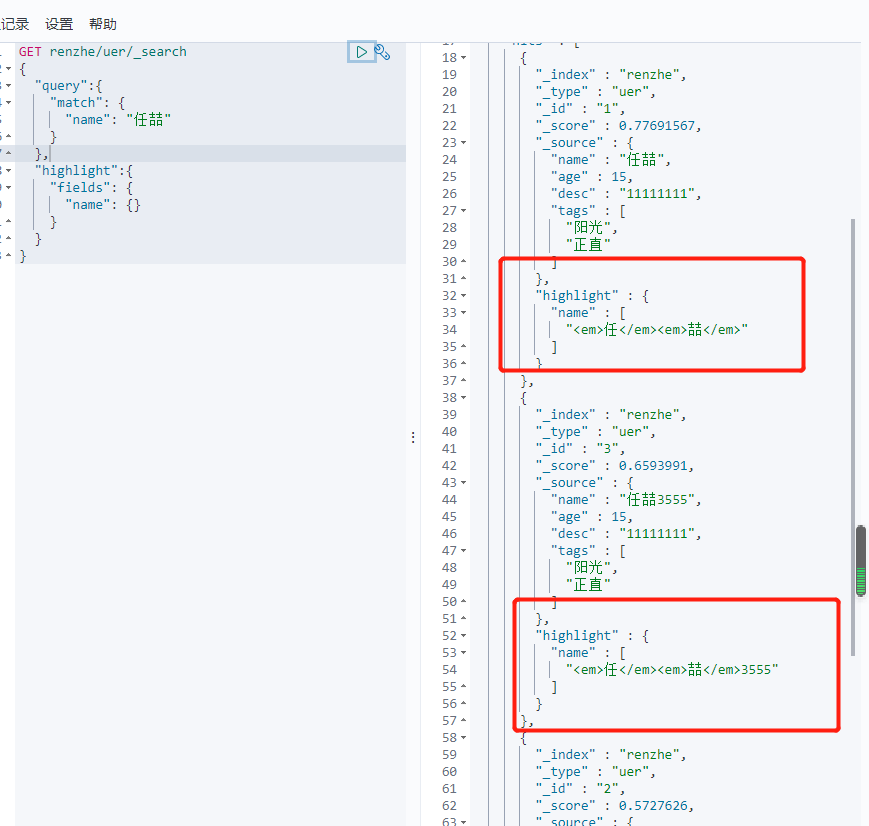
高亮查询
1 2 3 4 5 6 7 8 9 10 11 12 13 | GET renzhe/uer/_search{"query":{ "match": { "name": "任喆" }},"highlight":{ "fields": { "name": {} }}} |
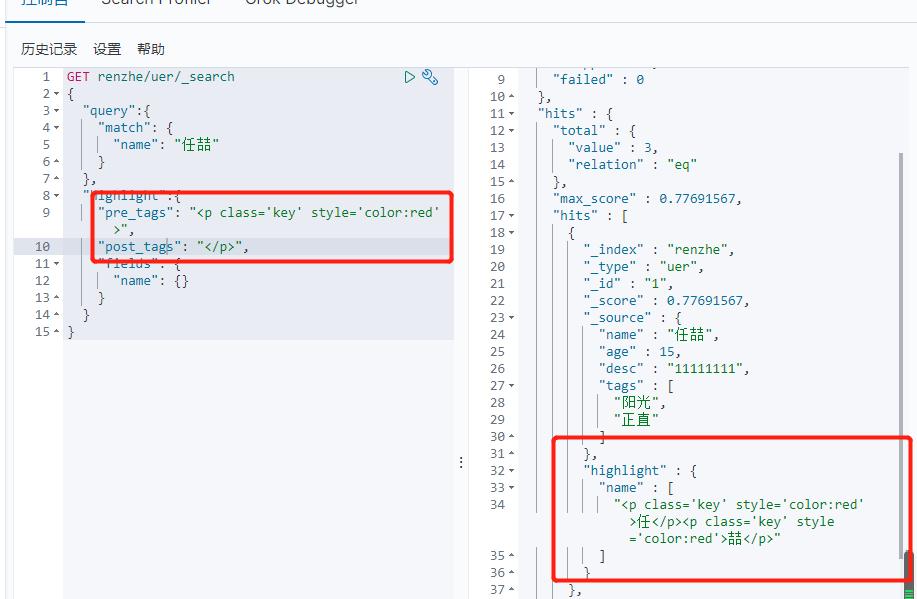
自定义搜索高亮条件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | GET renzhe/uer/_search{ "query":{ "match": { "name": "任喆" } }, "highlight":{ "pre_tags": "<p class='key' style='color:red'>", "post_tags": "</p>", "fields": { "name": {} } }} |
匹配
按条件匹配
精准匹配
区间范围匹配
匹配字段过滤
多条件查询
高亮查询


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义