

(转)OO设计初次见面
我使用OO技术第一次设计软件的时候,犯了一个设计者所能犯的所有错误。那是一个来自国外的外包项目,外方负责功能设计,我们公司负责程序设计、编码和测试。
第一个重要的错误是,我没有认真的把设计说明书看明白。功能点设计确实有一些问题,按照他们的设计,一个重要的流程是无法实现的。于是我在没有与投资方沟通的情况下,擅自改动了设计,把一个原本在Linux系统上开发的模块改到了Windows系统上。结果流程确实是实现了,但是很不幸,根本不符合他们的需要,比起原先的设计差的更多。在询问了这个流程的设计意图之后,我也清楚了这一点。对方的工程师承认了错误,但是问题是:“为什么不早说啊,我们都跟领导讲过了产品的构架,也保证了交货时间了,现在怎么去说啊?”。他们设计的是一个苹果,而我造了一个桔子出来。最后和工程师商议的结果是:先把桔子改成设计书上的苹果,按时交货,然后再悄悄的改成他们真正需要的香蕉。的这时候距离交货的时间已经不足三天了,于是我每天加班工作到天明,把代码逐行抽出来,用gcc编译调试。好在大部分都是体力活,没有什么技术含量,即使在深夜大脑半休眠的情况下仍然可以接着干。
项目中出现的另外一个错误是:我对工作量的估计非常的不准确。在第一个阶段的时候,按照功能设计说明书中的一个流程,我做了一个示例,用上了投资方规定的所有的技术。当我打开浏览器,看到页面上出现了数据库里的“Tom,Jerry,王小帅”,就愉快的跑到走廊上去呼吸了一口新鲜空气,然后乐观的认为:设计书都已经写好了,示例也做出来了,剩下的事情肯定就象砍瓜切菜一样了。不就是把大家召集起来讲讲设计书,看看示例,然后扑上去开工,然后大功告成。我为每个画面分配的编码工作量是三个工作日。结果却是,他们的设计并不完美,我的理解也并不正确,大家的思想也并不一致。于是我天天召集开会,朝令夕改,不断返工。最后算了一下,实际上写完一个画面用的时间在十个工作日以上。编码占用了太多的时间,测试在匆忙中草草了事,质量……能掩盖的问题也就只好掩盖一下了,性能更是无暇顾及了。
还有一个方面的问题是出在技术上的,这方面是我本文要说的重点。按照投资方的方案,系统的主体部分需要使用J2EE框架,选择的中间件是免费的JBoss。再加上Tomcat作为Web服务器,Struts作为表示层的框架。他们对于这些东西的使用都是有明确目的,但是我并不了解这些技术。新手第一次进行OO设计,加上过多的新式技术,于是出现了一大堆的问题。公司原本安排了一个牛人对我进行指导,他熟悉OO设计,并且熟悉这些开源框架,曾熟读Tomcat和Struts源代码。可是他确实太忙,能指导我的时间非常有限。
投资方发来设计书以后,很快就派来了两个工程师对这个说明书进行讲解。这是一个功能设计说明书,包括一个数据库设计说明书,和一个功能点设计说明。功能点说明里面叙述了每一个工作流程,画面设计和数据流程。两位工程师向我们简单的说明了产品的构想,然后花了一个多星期的时间十分详细的说明了他们的设计,包括数据表里每一个字段的含义,画面上每一个控件的业务意义。除了这些功能性的需求以外,他们还有一些技术上的要求。
为了减少客户的拥有成本,他们不想将产品绑定在特定的数据库和操作系统上,并且希望使用免费的平台。于是他们选择了Java作为开发语言,并且使用了一系列免费的平台。选用的中间件是JBoss,使用Entity Bean作为数据库访问的方式。我们对Entity Bean的效率不放心,因为猜测他运用了大量的反射技术。在经过一段时间的技术调查之后,我决定不采用Entity Bean,而是自己写出一大堆的Value Object,每个Value Object对应一个数据库表,Value Object里面只有一些setter和getter方法,只保存数据,不做任何事情。Value Object的属性与数据库里面的字段一一对应。与每个Value Object对应,做一个数据表的Gateway,负责把数据从数据库里面查出来塞到这些Value Object里面,也负责把Value Object里面的数据塞回数据库。
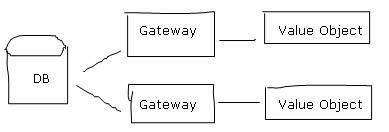
按照这样的设计,需要为每一个数据表写一个Gateway和一个Value Object,这个数量是比较庞大的。因此我们做了一个自动生成代码的工具,到数据库里面遍历每一个数据表,然后遍历表里面的每一个字段,把这些代码自动生成出来。
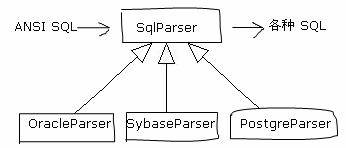
这等于自己实现了一个ORM的机制。当时我们做这些事情的时候,ORM还是一个很陌生的名词,Hibernate这样的ORM框架还没听说过。接着我们还是需要解决系统在多种数据库上运行的问题。Gateway是使用JDBC连接数据库的,用SQL查询和修改数据的。于是问题就是:要解决不同数据库之间SQL的微小差别。我是这样干的:我做了一个SqlParser接口,这个接口的作用是把ANSI SQL格式的查询语句转化成各种数据库的查询语句。当然我没必要做的很全面,只要支持我在项目中用到的查询方式和数据类型就够了。然后再开发几个具体的Parser来转换不同的数据库SQL格式。
到这个时候,数据库里面的数据成功转化成了程序里面的对象。非常好!按道理说,剩下的OO之路就该顺理成章了。但是,很不幸,我不知道该怎样用这些Value Object,接下来我就怀着困惑的心情把过程式的代码嫁接在这个OO的基础上了。
我为每一个画面设计出了一个Session Bean,在这个Session Bean里面封装了画面所关联的一切业务流程,让这个Session Bean调用一大堆Value Object开始干活。在Session Bean和页面之间,我没有让他们直接调用,因为据公司的牛人说:“页面直接调用业务代码不好,耦合性太强。”这句话没错,但是我对“业务代码”的理解实在有问题,于是就硬生生的造出一个Helper来,阻挡在页面和Session Bean中间,充当了一个传声筒的角色。
于是在开发中就出现了下面这副景象:每当设计发生变更,我就要修改数据库的设计,用代码生成工具重新生成Value Object,然后重新修改Session Bean里面的业务流程,按照新的参数和返回值修改Helper的代码,最后修改页面的调用代码,修改页面样式。
实际情况比我现在说起来复杂的多。比如Value Object的修改,程序规模越来越大以后,我为了避免出现内存的大量占用和效率的下降,不得不把一些数据库查询的逻辑写到了Gateway和Value Object里面,于是在发生变更的时候,我还要手工修改代码生成工具生成的Gateway和Value Object。这样的维护十分麻烦,这使我困惑OO到底有什么好处。我在这个项目中用OO方式解决了很多问题,而这些问题都是由OO本身造成的。
另一个比较大的问题出在Struts上。投资方为系统设计了很灵活的界面,界面上的所有元素都是可以配置出来,包括位置、数据来源、读写属性。并且操作员的权限可以精确到每一个查看、修改的动作,可以控制每一个控件的读写操作。于是他们希望使用Struts。Struts框架的每一个Action恰好对应一个操作,只需要自己定义Action和权限角色的关系,就可以实现行为的权限控制。但是我错误的理解了Struts的用法,我为每一个页面设计了一个Action,而不是为每一个行为设计一个Action,这样根本就无法做到他们想要的权限控制方式。他们很快发现了我的问题,于是发来了一个说明书,向我介绍Struts的正确使用方式。说明书打印出来厚厚的一本,我翻了一天,终于知道了错在什么地方。但是一大半画面已经生米煮成熟饭,再加上我的Session Bean里面的流程又是按画面来封装的,于是只能改造小部分能改造的画面,权限问题另找办法解决了。
下面就是这个系统的全貌,场面看上去还是蔚为壮观的:
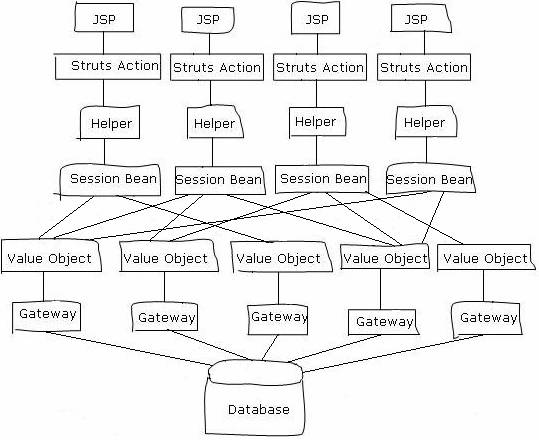
系统经历过数次较大的修改,这个框架不但没有减轻变更的压力,反而使得变更困难加大了。到后来,因为业务流程的变更的越来越复杂,现有流程无法修改,只得用一些十分曲折的方式来实现,运行效率越来越低。由于结构过于复杂,根本没有办法进行性能上的优化。为了平衡效率的延缓,不得不把越来越多的Value Object放在了内存中缓存起来,这又造成了内存占用的急剧增加。到后期调试程序的时候,服务器经常出现“Out of memory”异常,各类对象庞大繁多,系统编译部署一次需要10多分钟。投资方原先是希望我们使用JUnit来进行单元测试,但是这样的流程代码测试起来困难重重,要花费太多的时间和人手,也只得作罢。此外他们设计的很多功能其实都没有实现,并且似乎以后也很难再实现了。设计中预想的很多优秀特点在这样框架中一一消失,大家无奈的接受一个失望的局面。
在我离开公司两年以后,这个系统仍然在持续开发中。新的模块不断的添加,框架上不断添加新的功能点。有一次遇到仍然在公司工作的同事,他们说:“还是原来那个框架,前台加上一个个的JSP,然后后台加上一个个的Value Object,中间的Session Bean封装越来越多的业务流程。”
我的第一个OO系统的设计,表面上使用了OO技术,实际上分析设计还是过程主导的方式。设计的时候过多、过早、过深入的考虑了需要做哪些画面,画面上应该有哪些功能点,功能点的数据流程。再加上一个复杂的OO框架,名目繁多的对象,不仅无法做到快速的开发,灵活的适应需求的变化,反而使系统变得更加复杂,功能修改更加的麻烦了。
在面条式代码的时代,很多人用汇编代码写出了一个个优秀的程序。他们利用一些工具,或者共同遵守一些特别的规约,采用一致的变量命名方式,规范的代码注释,可以使一个庞大的开发团队运行的井井有条。人如果有了先进的思想,工具在这些人的手中就可以发挥出超越时代的能量。而我设计的第一个OO系统,恰好是一个相反的例子。
实际上,面向对象的最独特之处,在于他分析需求的方式。按照这样的方式,不要过分的纠缠于程序的画面、操作的过程,数据的流程,而是要更加深入的探索需求中的一些重要概念。下面,我们就通过一个实例看一看,怎样去抓住需求中的这些重要概念,并且运用OO方法把他融合到程序设计中。也看看OO技术是如何帮助开发人员控制程序的复杂度,让大家工作的更加简单、高效。
我们来看看一个通信公司的账务系统的开发情况。最开始,开发人员找到电信公司的职员询问需求的情况。电信公司的职员是这样说的:
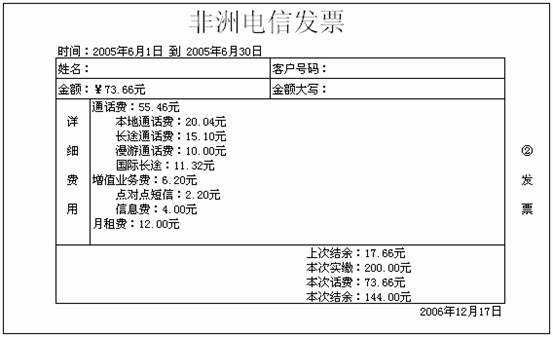
“账务系统主要做这样几件事情:每个月1日凌晨按照用户使用情况生成账单,然后用预存冲销这个账单。还要受理用户的缴费,缴费后可以自动冲销欠费的账单,欠费用户缴清费用之后要发指令到交换上,开启他的服务。费用缴清以后可以打印发票,发票就是下面这个样子。”
经过一番调查,开发人员设计了下面几个主要的流程:
1、 出账:根据一个月内用户的消费情况生成账单;
2、 销账:冲销用户账户上的余额和账单;
3、 缴费:用户向自己的账户上缴费,缴清欠费后打印发票。
弄清了流程,接着就设计用户界面来实现这样的流程。下面是其中一个数据查询界面,分为两个部分:上半部分是缴费信息,记录了用户的缴费历史;下半部分是账单信息,显示账单的费用和销账情况。
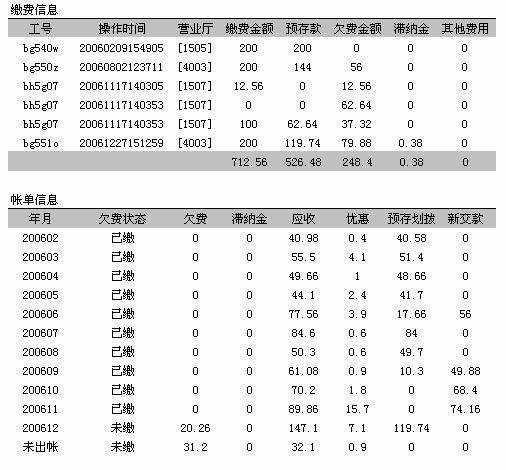
界面上的数据一眼看起来很复杂,其实结合出账、缴费、销账的流程讲解一下,是比较容易理解的。下面简单说明一下。
缴费的时候,在缴费信息上添加一条记录,记录下缴费金额。然后查找有没有欠费的账单,如果有就做销账。冲抵欠费的金额记录在“欠费金额”的位置。如果欠费时间较长,就计算滞纳金,记录在“滞纳金”的位置上。冲销欠费以后,剩余的金额记录在“预存款”的位置上。“其他费用”这个位置是预留的,目前没有作用。
每个月出账的时候,在账单信息里面加上一条记录,记录下账单的应收和优惠,这两部分相减就是账单的总金额。然后检查一下账户上有没有余额,如果有就做销账。销账的时候,预存款冲销的部分记录在“预存划拨”的位置,如果不足以冲抵欠费,账单就暂时处于“未缴”状态。等到下次缴费的时候,冲销的金额再记录到“新交款”的位置。等到所有费用缴清了,账单状态变成“已缴”。
销账的流程就这样融合在缴费和出账的过程中。
看起来一切成功搞定了,最重要的几个流程很明确了,剩下的事情无疑就像砍瓜切菜一样。无非是绕着这几个流程,设计出其他更多的流程。现在有个小问题:打印发票的时候,发票的右侧需要有上次结余、本次实缴、本次话费、本次结余这几个金额。
上次结余:上个月账单销账后剩下来的金额,这个容易理解;
本次结余:当前的账单销账后剩下的金额,这个也不难;
本次话费:这是账单的费用,还是最后一次完全销账时的缴费,应该用哪一个呢?
本次缴费:这个和本次话费有什么区别,他在哪里算出来?
带着问题,开发者去问电信公司的职员。开发者把他们设计的界面指点给用户看,向他说明了自己的设计的这几个流程,同时也说出了自己的疑问。用户没有直接回答这个疑问,却提出了另一个问题:
“缴费打发票这个流程并不总是这样的,缴费以后不一定立刻要打印发票的。我们的用户可以在银行、超市这样的地方缴话费,几个月以后才来到我们这里打印发票。并且缴费的时间和销账的时间可以相距很长的,可以先缴纳一笔话费,后面几个月的账单都用这笔钱销账;也可以几个月都不缴费,然后缴纳一笔费用冲销这几个账单。你们设计的这个界面不能很好的体现用户的缴费和消费情况,很难看出来某一次缴费是在什么时候用完的。必须从第一次、或者最后一次缴费余额推算这个历史,太麻烦了。还有,‘预存划拨’、‘新交款’这两个概念我们以前从来没有见过,对用户解释起来肯定是很麻烦的。”
开发人员平静了一下自己沮丧(或愤怒)的心情,仔细想一想,这样的设计确实很不合理。如果一个会计记出这样的账本来,他肯定会被老板开除的。
看起来流程要改,比先前设计的更加灵活,界面也要改。就好像原先盖好的一栋房子忽然被捅了几个窟窿,变得四处透风了。还有,那四个数值到底应该怎样计算出来呢?我们先到走廊上去呼吸两口新鲜空气,然后再回来想想吧。
现在,让我们先忘记这几个变化多端的流程,花一点时间想一想最基本的几个概念吧。系统里面最显而易见的一个概念是什么呢?没错,是账户(Account)。账户可以缴费和消费。每个月消费的情况是记录在一个账单(Bill)里面的。账户和账单之间是一对多的关系。此外,账户还有另一个重要的相关的概念:缴费(Deposit)。账户和缴费之间也是一对多的关系。在我们刚才的设计中,这些对象是这样的:
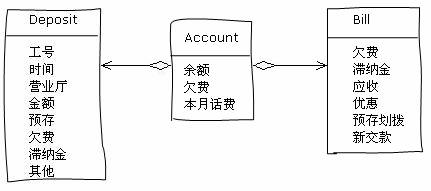
这个设计看来有些问题,使用了一些用户闻所未闻的概念(预存划拨,新交款)。并且他分离了缴费和消费,表面上很清楚,实际上使账单的查询变得困难了。在实现一些功能的时候确实比较简单(比如缴费和销账),但是另一些功能变得很困难(比如打印发票)。问题到底在什么地方呢?
涉及到账务的行业有很多,最容易想到的也许就是银行了。从银行身上,我们是不是可以学到什么呢?下面是一个银行的存折,这是一个委托收款的账号。用户在账户上定期存钱,然后他的消费会自动从这里扣除。这个情景和我们需要实现的需求很相似。可以观察一下这个存折,存入和支取都是记录在同一列上的,在支出或者存入的右侧记录当时的结余。

有两次账户上的金额被扣除到0,这时候金额已经被全部扣除了,但是消费还没有完全冲销。等到再次存入以后,会继续支取。这种记账的方式就是最基本的流水账,每一条存入和支出都要记录为一条账目(Entry)。程序的设计应该是这样:
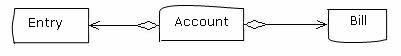
这个结构看上去和刚才那个似乎没有什么不同,其实差别是很大的。上面的那个Deposit只是缴费记录,这里的Entry是账目,包括缴费、扣费、滞纳金……所有的费用。销账扣费的过程不应该记录在账单中,而是应该以账目的形式记录下来。Account的代码片段如下:
{
public Bill[] GetBills()
{
//按时间顺序返回所有的账单
}
public Bill GetBill(DateTime month)
{
//按照月份返回某个账单
}
public Entry[] GetEntrees()
{
//按时间顺序返回所有账目
}
public void Pay(float money)
{
//缴费
//先添加一个账目,然后冲销欠费的账单
}
public Bill GenerateBill(DateTime month)
{
//出账
//先添加一个账单,然后用余额冲销这个账单
}
public float GetBalance()
{
//返回账户的结余
//每一条账目的金额总和,就是账户的结余
}
public float GetDebt()
{
//返回账户的欠费
//每一个账单的欠费金额综合,就是账户的欠费
}
}
Entry有很多种类型(存入、支取、滞纳金、赠送费),可以考虑可以为每一种类型创建一个子类,就像这样:
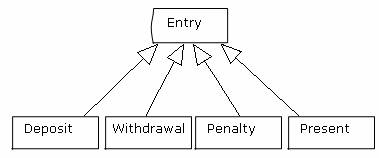
搞成父子关系看起来很复杂、麻烦,并且目前也看不出将这些类型作为Entry的子类有哪些好处。所以我们决定不这样做,只是简单的把这几种类型作为Entry的一个属性。Entry的代码片段如下:
{
public DateTime GetTime()
{
//返回账目发生的时间
}
public float GetValue()
{
//返回账目的金额
}
public EntryType GetType()
{
//返回账目的类型(存入、扣除、赠送、滞纳金)
}
public string GetLocation()
{
//返回账目发生的营业厅
}
public Bill GetBill()
{
//如果这是一次扣除,这里要返回相关的账单
}
}
Entry是一个枚举类型,代码如下:
{
Deposit = 1,
Withdrawal = 2,
Penalty = 3,
Present = 4
}
下面的界面显示的就是刚才那个账户的账目。要显示这个界面只需要调用Account的GetEntrees方法,得到所有的账目,然后按时间顺序显示出来。这个界面上的消费情况就明确多了,用户很容易弄明白某个缴费是在哪几个月份被消费掉的。
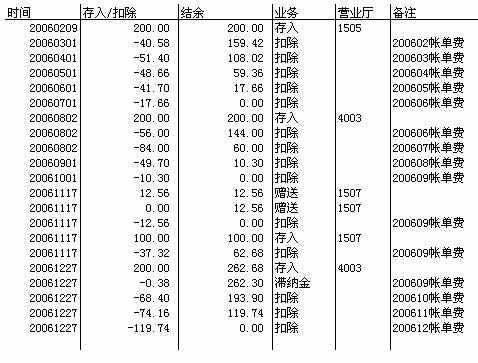
并且,发票上的那几个一直搞不明白的数值也有了答案。比如2005年6月份的发票,我们先看看2005年6月份销账的所有账目(第六行、第八行),这两次一共扣除73.66元,这个金额就是本次消费;两次扣除之间存入200元,这个就是本次实缴;第五行的结余是17.66元,这就是上次结余;第八行上的结余是144元,这个就是本次结余。
用户检查了这个设计,觉得这样的费用显示明确多了。尽管一些措辞不符合习惯的业务词汇,但是他们的概念都是符合的。并且上次还有一个需求没有说:有时候需要把多个月份的发票合在一起打印。按照这样的账目表达方式,合并的发票数值也比较容易搞清楚了。明确了这样的对象关系,实现这个需求其实很容易。
面向对象的设计就是要这样,不要急于确定系统需要做哪些功能点和哪些界面,而是首先要深入的探索需求中出现的概念。在具体的流程不甚清楚的情况下,先把这些概念搞清楚,一个一个的开发出来。然后只要把这些做好的零件拿过来,千变万化的流程其实就变得很简单了,一番搭积木式的装配就可以比较轻松的实现。
另一个重要的类型也渐渐清晰的浮现在我们的眼前:账单(Bill)。他的代码片段如下:
{
public DateTime GetBeginTime()
{
//返回账单周期的起始时间
}
public DateTime GetEndTime()
{
//返回账单周期的终止时间
}
public Fee GetFee()
{
//返回账单的费用
}
public float GetPenalty()
{
//返回账单的滞纳金
}
public void CaculatePenalty()
{
//计算账单的滞纳金
}
public float GetPaid()
{
//返回已支付金额
}
public float GetDebt()
{
//返回欠费
//账单费用加上滞纳金,再减去支付金额,就是欠费
return GetFee().GetValue() + GetPanalty() - GetPaid();
}
public Entry GetEntrees()
{
//返回相关的存入和支取的账目
}
public Bill Merge(Bill bill)
{
//合并两个账单,返回合并后的账单
//合并后的账单可以打印在一张发票上
}
}
Bill类有两个与滞纳金有关的方法,这使开发者想到了原先忽略的一个流程:计算滞纳金。经过与电信公司的确认,决定每个月进行一次计算滞纳金的工作。开发人员写了一个脚本,先得到系统中所有的欠费账单,然后一一调用他们的CaculatePenalty方法。每个月将这个脚本执行一次,就可以完成滞纳金的计算工作。
Bill对象中有账户的基本属性和各级账目的金额和销账的情况,要打印发票,只有这些数值是不够的。还要涉及到上次结余、本次结余和本次实缴,这三个数值是需要从账目中查到的。并且发票有严格的格式要求,也不需要显示费用的细节,只要显示一级和二级的费用类就可以了。应该把这些东西另外封装成一个类:发票(Invoice):
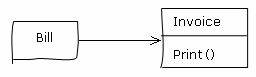
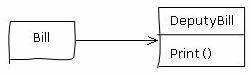
通信公司后来又提出了新的需求:有些账号和银行签订了托收协议,每个月通信公司打印出这些账户的托收单交给银行,银行从个人结算账户上扣除这笔钱,再把一个扣费单交给通信公司。通信公司根据这个扣费单冲销用户的欠费。于是开发人员可以再做一个托收单(DeputyBill):
账单中的GetFee方法的返回值类型是Fee,Fee类型包含了费用的名称、金额和他包含的其他费用。例如下面的情况:
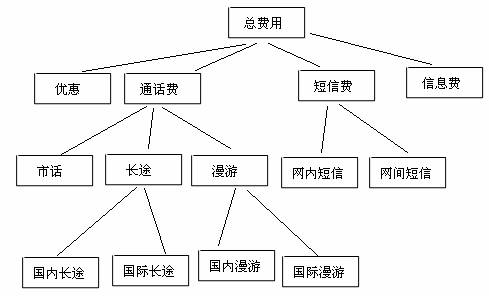
我们可以用这样的一个类来表示费用(Fee),一个费用可以包含其他的费用,他的金额是子费用的金额和。代码片段如下:
{
private float valuee = 0;
public string GetName()
{
//返回费用的名称
}
public bool HasChildren()
{
//该费用类型是否有子类型
}
public Fee[] GetChildren()
{
//返回该费用类型的子类型
}
public float GetValue()
{
//返回费用的金额
if (HasChildren())
{
float f = 0;
Fee[] children = GetChildren();
for (int i = 0; i < children.Length; i ++)
{
f += children[i].GetValue();
}
return f;
}
else
{
return valuee;
}
}
}
现在开发者设计出了这么一堆类,构成软件系统的主要零件就这么制造出来了。下面要做的就是把这些零件串在一起,去实现需要的功能。OO设计的重点就是要找到这些零件。就像是设计一辆汽车,仅仅知道油路、电路、传动的各项流程是不够的,重要的是知道造一辆汽车需要先制造哪些零件。要想正确的把这些零件设计出来不是一件容易的事情,很少有开发者一开始就了解系统的需求,设计出合理的对象关系。根本的原因在于领域知识的贫乏,开发者和用户之间也缺乏必要的交流。很多人在软件开发的过程中才渐渐意识到原来的设计中存在一些难受的地方,然后探索下去,才知道了正确的方式,这就是业务知识的一个突破。不幸的是,当这个突破到来的时候,程序员经常是已经忙得热火朝天,快把代码写完了。要把一切恢复到正常的轨道上,需要勇气,时间,有远见的领导者,也需要有运气。

