Kafka基础笔记
消息队列
- 消息队列是存放消息的组件。
- 程序A将消息放入消息队列,程序B从消息队列中获取消息。
- 大多数情况下,消息队列都不是永久性的存储消息,只是作为一种临时缓冲存储存在。
消息的处理方式可分为同步处理、异步处理,如下图所示: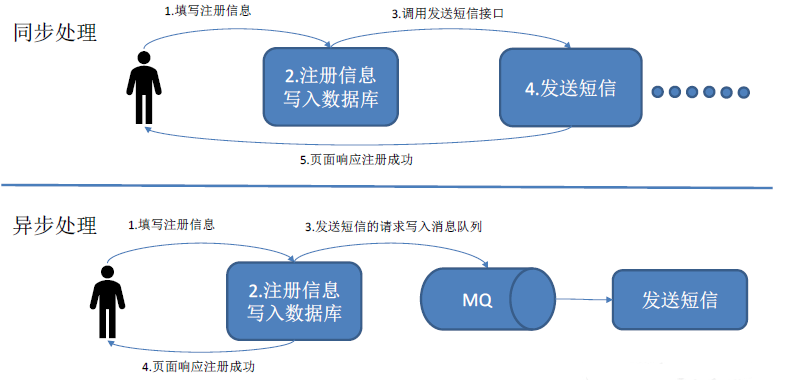
消息队列的优势
- 系统解耦:允许相关联的两个服务(系统)独立扩展,只需遵守一定规范。
- 缓冲:控制、优化数据经过系统的速度,解决消息生产和消费速度不一致的问题。
- 可恢复性:系统中消息处理的某一组件异常,系统恢复后消息仍能被处理。
- 异步处理:提供异步处理方式。
- 峰值处理能力:在消息量剧增的情况下,突发流量不会使系统直接崩溃。
消息队列工作模式
点对点模式(生产者-消费者模式)
- 消息生产者向队列发送消息,消息消费者从队列中取出消息并消费。
- 一条消息只能被一个消费者消费。
发布/订阅模式
- 消息生产者将消息发布到Topic中,多个消费者订阅该Topic。
- 一条消息可以被多个消费者消费。
Kafka
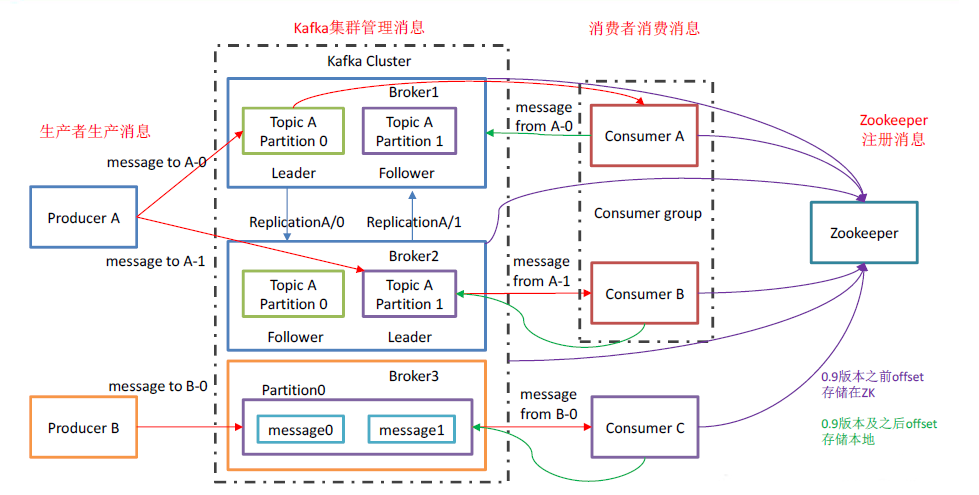
Kafka基础架构
-
Producer:消息生产者。
-
Consumer:消息消费者。
-
Consumer Group:消费者组,由一个或多个消费者组成。
1)一个消费者组中的不同消费者可以消费一个Topic中的不同分区数据,一个分区只能由组内一个消费者消费。
2)每一个消费者组都一个唯一的名字,配置 group.id 一样的消费者是属于同一个组中。
3)消费者组是逻辑上的订阅者,消费者组之间互不影响。
-
Broker:Kafka的服务进程,一个服务进程就是一个Broker。一个Broker可容纳多个Topic。
-
Topic:主题,可理解为逻辑上的消息队列。消息的生产和消费都须指定Topic。一个Topic可包括多个Partition。
-
Partition:分区,每个Partition是一个有序的队列。Kafka集群的分布式特性由Partition实现,一个Topic的消息可分布在该Topic的不同Partition中。
-
Replica:副本,实现Kafka集群的容错,实现Partition的容错。一个Topic的每个Partition都有若干个副本,包括一个leader和若干个follower。
leader:Partition的主副本,消息的生产、消费的对象都是leader。
follower:Partition的从副本,实时同步leader的数据,leader发生故障时,从follower中选择一个成为新的leader。
-
offset:偏移量。相对Consumer和Partition来说,可以通过offset,从该位置拉取数据。
Kafka存储机制
Kafka中消息根据Topic进行分类,消息的生产和消费都是面向Topic。Topic是逻辑上的消息队列。一个Topic分为多个Partition,Partition负责实际的消息存取,每个Partition有对应的log文件,每条消息记录都有自己的offset。Kafka的分区采取分段+索引的机制。
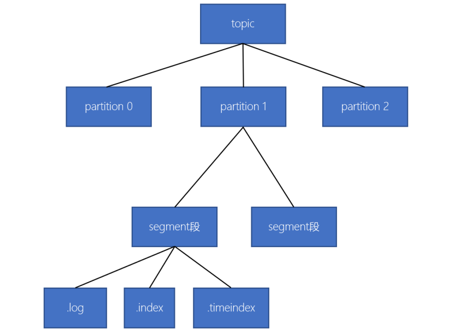
.log 数据文件、 .index 稀疏索引文件、.timeindex时间索引文件的名称对应着该文件存储的第一条记录的分区全局offset偏移量。
00000000000000000000.index 稀疏索引文件
00000000000000000000.log 日志数据文件
00000000000000000000.timeindex 时间索引
数据消费流程如下:
- 消费者的offset是一个针对partition的「全局offset」。
- 可以根据这个offset找到「segment段」。
- 接着需要将全局的offset转换成segment的「局部offset」。
- 根据局部的offset,就可以从(.index稀疏索引)找到对应的「数据位置」。
- 开始顺序读取。
Producer分区写入策略
-
轮询策略
消息以轮询的方式,均衡地写入Topic的不同分区。如果在生产消息时,key为null,则使用轮询算法均衡地分配分区。
-
按key分配策略
消息是 <key, value>格式。key.hash() % Partition数量。
可能因为某个key包含大量数据,数据都被分配到一个分区中,导致数据倾斜。
Consumer分区分配策略
消费者分区分配——尽可能地确保每个消费者消费的分区数量是均衡的。
Range范围分配策略
Kafka的默认分配策略。Range策略针每个Topic。对若图所示: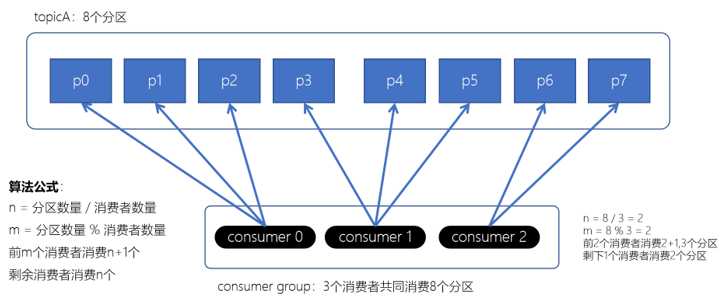
算法公式
n = 分区数量 / 消费者数量
m = 分区数量 % 消费者数量
前m个消费者消费n+1个
剩余消费者消费n个
RoundRobin轮询策略
RoundRobin策略是将消费组内所有消费者以及消费者所订阅的所有Topic的Partition按照字典序排序(topic和分区的hashcode进行排序),然后通过轮询方式逐个将分区以此分配给每个消费者。如下图: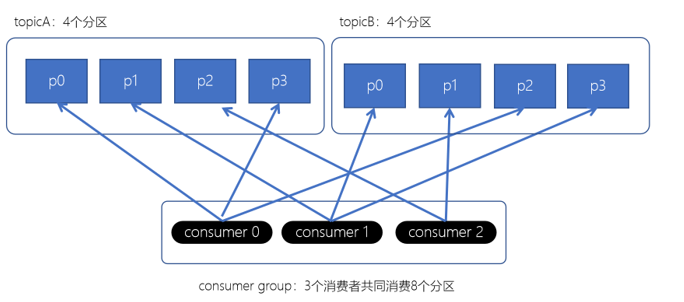
Stricky粘性分配策略
Stricky粘性分配策略设计的目标包括以下两点:
- 分区分配尽可能均匀。
- 在发生Rebalance的时候,分区的分配尽可能与上一次分配保持相同。
在没有发生Rebalance的情况下,Stricky粘性分配策略和RoundRobin分配策略相同。发生Rebalance后,减少对系统资源的浪费,保留Rebalance之前的分配结果,再将需要重新分配的分区均匀分配给当前的消费者。如下图所示: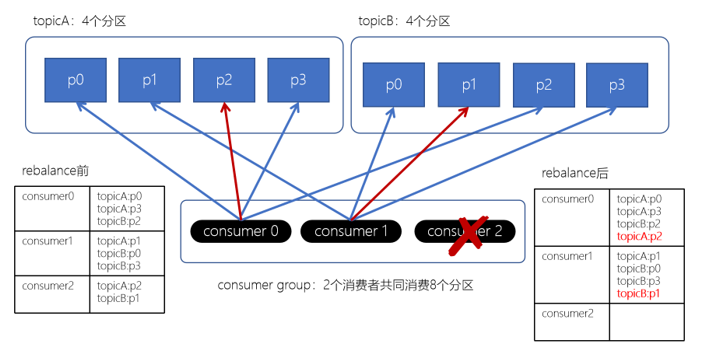
消费者组Rebalance机制
Kafka高性能表现得益于均衡负载,Kafka消费者组中,Kafka提供了分区的均衡分配机制,同时,当发生变化时,进行再平衡(Rebalance)。Rebalance过程中l 所有的消费者都将停止工作,直到Rebalance完成。
Rebalance触发因素:
- 消费者组中Consumer个数发生变化。新的Consumer加入或某个Consumer停止。
- 消费者组订阅的Topic个数发生变化。
- 订阅的Topic分区数量发生变化。
副本与ACK机制
Kafka中Partition又分为leader和follower。follower即是消息数据的备份。创建Topic时,Kafka会尽可能的将各分区的leader分配到不同的Broker中。
- 分区leader:读、写数据。
- 分区follower:同步leader的数据;参与选举成为新leader。
Producer不断地往Kafka中写入消息,整个过程不是原子性的,由此Kafka提供了ACK机制来确保消息的写入。对应的ACKs有一下:
- acks = 0:生产者只管写入,不管是否写入成功,可能会数据丢失。性能最好。
- acks = 1:生产者会等到leader分区写入成功后,返回成功,接着写下一条消息。
- acks = -1/all:确保消息写入到leader分区、还确保消息同步follower都成功后,接着写下一条,性能最差。
AR\ISR\OSR
- AR(Assigned Replicas)表示一个Topic下的所有副本。
- ISR(In Sync Replicas)所有与leader副本保持一定程度同步的副本(包括leader副本在内)。
- OSR(Out of Sync Replicas)与leader副本同步滞后过多的副本(不包括leader副本)。
- AR = ISR + OSR

 浙公网安备 33010602011771号
浙公网安备 33010602011771号