TCP三次握手原理,你真的了解吗?
最近碰到一个问题,Client 端连接服务器总是抛异常。在反复定位分析、并查阅各种资料搞懂后,我发现并没有文章能把这两个队列以及怎么观察他们的指标说清楚。
问题描述
场景:Java 的 Client 和 Server,使用 Socket 通信。Server 使用 NIO。
问题:
- 间歇性出现 Client 向 Server 建立连接三次握手已经完成,但 Server 的 Selector 没有响应到该连接。
- 出问题的时间点,会同时有很多连接出现这个问题。
- Selector 没有销毁重建,一直用的都是一个。
- 程序刚启动的时候必会出现一些,之后会间歇性出现。
分析问题

正常 TCP 建连接三次握手过程,分为如下三个步骤:
- Client 发送 Syn 到 Server 发起握手。
- Server 收到 Syn 后回复 Syn + Ack 给 Client。
- Client 收到 Syn + Ack后,回复 Server 一个 Ack 表示收到了 Server 的 Syn + Ack(此时 Client 的 56911 端口的连接已经是 Established)。
从问题的描述来看,有点像 TCP 建连接的时候全连接队列(Accept 队列,后面具体讲)满了。
尤其是症状 2、4 为了证明是这个原因,马上通过 netstat -s | egrep "listen" 去看队列的溢出统计数据:
667399 times the listen queue of a socket overflowed
反复看了几次之后发现这个overflowed 一直在增加,那么可以明确的是server上全连接队列一定溢出了。
接着查看溢出后,OS怎么处理:
# cat /proc/sys/net/ipv4/tcp_abort_on_overflow
0
tcp_abort_on_overflow 为0表示:如果三次握手第三步的时候全连接队列满了那么server扔掉client 发过来的ack(在server端认为连接还没建立起来)
为了证明客户端应用代码的异常跟全连接队列满有关系,我先把tcp_abort_on_overflow修改成 1,1表示第三步的时候如果全连接队列满了,server发送一个reset包给client,表示废掉这个握手过程和这个连接(本来在server端这个连接就还没建立起来)。
接着测试,这时在客户端异常中可以看到很多connection reset by peer的错误,到此证明客户端错误是这个原因导致的(逻辑严谨、快速证明问题的关键点所在)。
于是开发同学翻看java 源代码发现socket 默认的backlog(这个值控制全连接队列的大小,后面再详述)是50,于是改大重新跑,经过12个小时以上的压测,这个错误一次都没出现了,同时观察到 overflowed 也不再增加了。
到此问题解决,简单来说TCP三次握手后有个accept队列,进到这个队列才能从Listen变成accept,默认backlog 值是50,很容易就满了。满了之后握手第三步的时候server就忽略了client发过来的ack包(隔一段时间server重发握手第二步的syn+ack包给client),如果这个连接一直排不上队就异常了。
但是不能只是满足问题的解决,而是要去复盘解决过程,中间涉及到了哪些知识点是我所缺失或者理解不到位的。
这个问题除了上面的异常信息表现出来之外,还有没有更明确地指征来查看和确认这个问题。
深入理解TCP握手过程中建连接的流程和队列
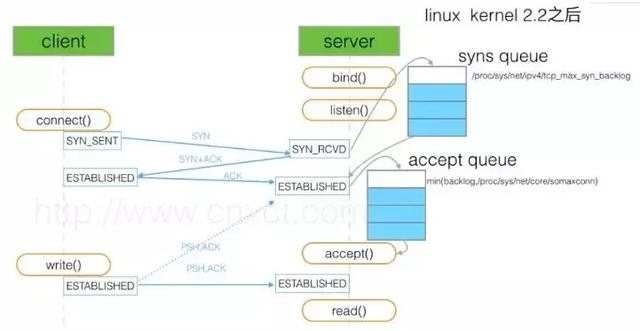
如上图所示,这里有两个队列:syns queue(半连接队列);accept queue(全连接队列)。
三次握手中,在第一步server收到client的syn后,把这个连接信息放到半连接队列中,同时回复syn+ack给client(第二步);
题外话,比如
syn floods攻击就是针对半连接队列的,攻击方不停地建连接,但是建连接的时候只做第一步,第二步中攻击方收到server的syn+ack后故意扔掉什么也不做,导致server上这个队列满其他正常请求无法进来。
第三步的时候server收到client的ack,如果这时全连接队列没满,那么从半连接队列拿出这个连接的信息放入到全连接队列中,否则按tcp_abort_on_overflow指示的执行。
这时如果全连接队列满了并且tcp_abort_on_overflow是0的话,server过一段时间再次发送syn+ack给client(也就是重新走握手的第二步),如果client超时等待比较短,client就很容易异常了。
在我们的os中retry 第二步的默认次数是2(centos默认是5次):
net.ipv4.tcp_synack_retries =2
如果TCP连接队列溢出,有哪些指标可以看呢?
上述解决过程有点绕,听起来懵,那么下次再出现类似问题有什么更快更明确的手段来确认这个问题呢?(通过具体的、感性的东西来强化我们对知识点的理解和吸收。)
netstat -s
[root@server ~] # netstat -s | egrep "listen|LISTEN"
667399 times the listen queue of a socket overflowed
667399 SYNs to LISTEN sockets ignored
比如上面看到的 667399 times ,表示全连接队列溢出的次数,隔几秒钟执行下,如果这个数字一直在增加的话肯定全连接队列偶尔满了。
ss 命令
[root@server ~]#ss -lnt
Recv -Q Send -Q Loacl Address:Port Peer Address:Port
0 50 *:3306 *:*
上面看到的第二列Send-Q 值是50,表示第三列的listen端口上的全连接队列最大为50,第一列Recv-Q为全连接队列当前使用了多少。
全连接队列的大小取决于:min(backlog, somaxconn) 。backlog是在socket创建的时候传入的,somaxconn是一个os级别的系统参数。
这个时候可以跟我们的代码建立联系了,比如Java创建ServerSocket的时候会让你传入backlog的值:
ServerSocket()
Creates an unbound server socket.
ServerSocket(int port)
Creates a server socket,bound to the specified port.
ServerSocket(int port, int backlog)
Creates a server socket and binds it to the specified local port number, with the specified backlog.
ServerSocket(int port, int backlog, InetAddress bindAddr)
Creates a server with the specified port, listen backlog, and local IP address to bind to.
半连接队列的大小取决于:max(64, /proc/sys/net/ipv4/tcp_max_syn_backlog),不同版本的os会有些差异。
我们写代码的时候从来没有想过这个backlog或者说大多时候就没给他值(那么默认就是50),直接忽视了他。
首先这是一个知识点的盲点;其次也许哪天你在哪篇文章中看到了这个参数,当时有点印象,但是过一阵子就忘了,这是知识之间没有建立连接,不是体系化的。
但是如果你跟我一样首先经历了这个问题的痛苦,然后在压力和痛苦的驱动自己去找为什么,同时能够把为什么从代码层推理理解到OS层,那么这个知识点你才算是比较好地掌握了,也会成为你的知识体系在TCP或者性能方面成长自我生长的一个有力抓手。
netstat 命令
netstat 跟 ss 命令一样也能看到 Send-Q、Recv-Q 这些状态信息,不过如果这个连接不是 Listen 状态的话,Recv-Q 就是指收到的数据还在缓存中,还没被进程读取,这个值就是还没被进程读取的 bytes。
$netstat -tn
Active Internet connections(w/o servers)
Proto Recv -Q Send -Q Local Address Foreign Address State
tcp0 0 server:8182 client-1:15260 SYN_RECV
tcp0 28 server:22 client-1:51708 ESTABLISHED
tcp0 0 server:2376 client-1:60269 ESTABLISHED
netstat -tn 看到的 Recv-Q 跟全连接半连接没有关系,这里特意拿出来说一下是因为容易跟 ss -lnt 的 Recv-Q 搞混淆,顺便建立知识体系,巩固相关知识点 。
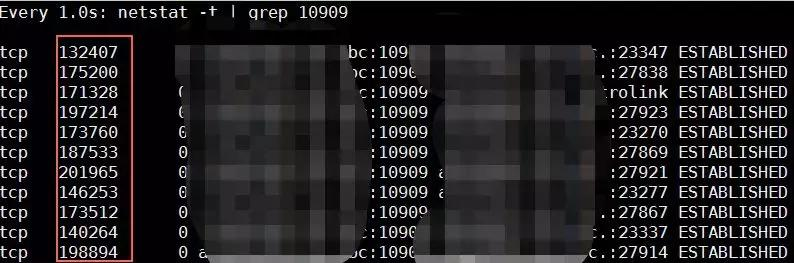
比如如下netstat -t 看到的Recv-Q有大量数据堆积,那么一般是CPU处理不过来导致的:
上面是通过一些具体的工具、指标来认识全连接队列(工程效率的手段)。
实践验证一下上面的理解
把java中backlog改成10(越小越容易溢出),继续跑压力,这个时候client又开始报异常了,然后在server上通过 ss 命令观察到:
Fri May 5 13:50:23 CST 2017
Recv -Q Send -Q Local Address:port Peer Address:Port
11 10 *:3306 *:*
按照前面的理解,这个时候我们能看到3306这个端口上的服务全连接队列最大是10,但是现在有11个在队列中和等待进队列的,肯定有一个连接进不去队列要overflow掉,同时也确实能看到overflow的值在不断地增大。
Tomcat和Nginx中的Accept队列参数
Tomcat默认短连接,backlog(Tomcat里面的术语是Accept count)Ali-tomcat默认是200, Apache Tomcat默认100。
#ss -lnt
Recv -Q Send -Q Local Address:port Peer Address:Port
0 100 *: 8080 *:*
Nginx默认是511。
#sudo ss -lnt
State Recv -Q Send -Q Local Address:Port Peer Address:Port
LISTEN 0 511 *: 8085 *:*
LISTEN 0 511 *: 8085 *:*
因为Nginx是多进程模式,所以看到了多个8085,也就是多个进程都监听同一个端口以尽量避免上下文切换来提升性能。
总结
全连接队列、半连接队列溢出这种问题很容易被忽视,但是又很关键,特别是对于一些短连接应用(比如Nginx、PHP,当然他们也是支持长连接的)更容易爆发。 一旦溢出,从cpu、线程状态看起来都比较正常,但是压力上不去,在client看来rt也比较高(rt=网络+排队+真正服务时间),但是从server日志记录的真正服务时间来看rt又很短。jdk、netty等一些框架默认backlog比较小,可能有些情况下导致性能上不去。
希望通过本文能够帮大家理解TCP连接过程中的半连接队列和全连接队列的概念、原理和作用,更关键的是有哪些指标可以明确看到这些问题(工程效率帮助强化对理论的理解)。
另外每个具体问题都是最好学习的机会,光看书理解肯定是不够深刻的,请珍惜每个具体问题,碰到后能够把来龙去脉弄清楚,每个问题都是你对具体知识点通关的好机会。
最后提出相关问题给大家思考
- 全连接队列满了会影响半连接队列吗?
- netstat -s看到的overflowed和ignored的数值有什么联系吗?
- 如果client走完了TCP握手的第三步,在client看来连接已经建立好了,但是server上的对应连接实际没有准备好,这个时候如果client发数据给server,server会怎么处理呢?(有同学说会reset,你觉得呢?)
来源:阿里技术微信公众号


 浙公网安备 33010602011771号
浙公网安备 33010602011771号