互联网面试必杀:如何保证消息中间件全链路数据100%不丢失:第三篇
前情提示
上一篇文章:<<互联网面试必杀:如何保证消息中间件全链路数据100%不丢失:第二篇>>,我们分析了 ack 机制的底层实现原理(delivery tag机制),还有消除处理失败时的nack机制如何触发消息重发。
通过这个,已经让大家进一步对消费端保证数据不丢失的方案的理解更进一层了。
这篇文章,我们将会对 ack 底层的delivery tag机制进行更加深入的分析,让大家理解的更加透彻一些。
面试时,如果被问到消息中间件数据不丢失问题的时候,可以更深入到底层,给面试官进行分析。
unack消息的积压问题
首先,我们要给大家介绍一下RabbitMQ的prefetch count这个概念。
大家看过上篇文章之后应该都知道了,对每个 channel(其实对应了一个消费者服务实例,你大体可以这么来认为),RabbitMQ 投递消息的时候,都是会带上本次消息投递的一个delivery tag的,唯一标识一次消息投递。
然后,我们进行 ack 时,也会带上这个 delivery tag,基于同一个 channel 进行 ack,ack 消息里会带上 delivery tag 让RabbitMQ知道是对哪一次消息投递进行了 ack,此时就可以对那条消息进行删除了。
大家先来看一张图,帮助大家回忆一下这个delivery tag的概念。

所以大家可以考虑一下,对于每个channel而言(你就认为是针对每个消费者服务实例吧,比如一个仓储服务实例),其实都有一些处于unack状态的消息。
比如RabbitMQ正在投递一条消息到channel,此时消息肯定是unack状态吧?
然后仓储服务接收到一条消息以后,要处理这条消息需要耗费时间,此时消息肯定是unack状态吧?
同时,即使你执行了ack之后,你要知道这个ack他默认是异步执行的,尤其如果你开启了批量ack的话,更是有一个延迟时间才会ack的,此时消息也是unack吧?
那么大家考虑一下,RabbitMQ 他能够无限制的不停给你的消费者服务实例推送消息吗?
明显是不能的,如果 RabbitMQ 给你的消费者服务实例推送的消息过多过快,比如都有几千条消息积压在某个消费者服务实例的内存中。
那么此时这几千条消息都是unack的状态,一直积压着,是不是有可能会导致消费者服务实例的内存溢出?内存消耗过大?甚至内存泄露之类的问题产生?
所以说,RabbitMQ 是必须要考虑一下消费者服务的处理能力的。
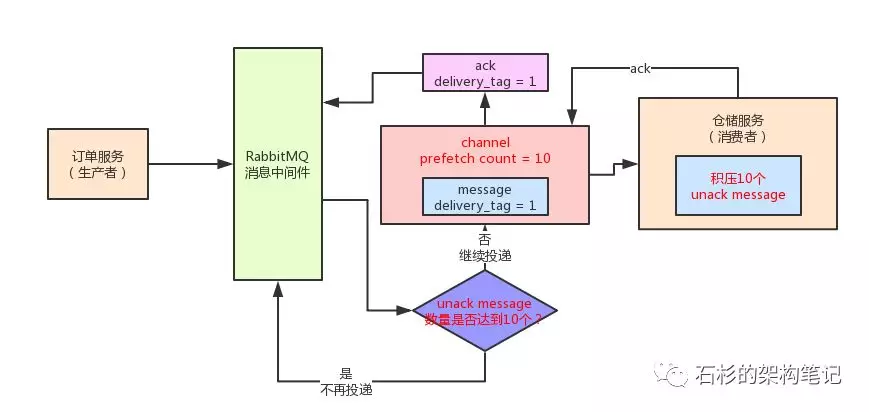
大家看看下面的图,感受一下如果消费者服务实例的内存中积压消息过多,都是unack的状态,此时会怎么样。

如何解决unack消息的积压问题
正是因为这个原因,RabbitMQ基于一个prefetch count来控制这个unack message的数量。
你可以通过“channel.basicQos(10)”这个方法来设置当前channel的prefetch count。
举个例子,比如你要是设置为10的话,那么意味着当前这个channel里,unack message的数量不能超过10个,以此来避免消费者服务实例积压unack message过多。
这样的话,就意味着RabbitMQ正在投递到channel过程中的unack message,以及消费者服务在处理中的unack message,以及异步ack之后还没完成 ack 的unack message,所有这些message 加起来,一个 channel 也不能超过10个。
如果你要简单粗浅的理解的话,也大致可以理解为这个prefetch count就代表了一个消费者服务同时最多可以获取多少个 message 来处理。所以这里也点出了 prefetch 这个单词的意思。
prefetch 就是预抓取的意思,就意味着你的消费者服务实例预抓取多少条 message 过来处理,但是最多只能同时处理这么多消息。
如果一个 channel 里的unack message超过了prefetch count指定的数量,此时RabbitMQ就会停止给这个 channel 投递消息了,必须要等待已经投递过去的消息被 ack 了,此时才能继续投递下一个消息。
老规矩,给大家上一张图,我们一起来看看这个东西是啥意思。
高并发场景下的内存溢出问题
好!现在大家对 ack 机制底层的另外一个核心机制:prefetch 机制也有了一个深刻的理解了。
此时,咱们就应该来考虑一个问题了。就是如何来设置这个prefetch count呢?这个东西设置的过大或者过小有什么影响呢?
其实大家理解了上面的图就很好理解这个问题了。
假如说我们把 prefetch count 设置的很大,比如说3000,5000,甚至100000,就这样特别大的值,那么此时会如何呢?
这个时候,在高并发大流量的场景下,可能就会导致消费者服务的内存被快速的消耗掉。
因为假如说现在MQ接收到的流量特别的大,每秒都上千条消息,而且此时你的消费者服务的prefetch count还设置的特别大,就会导致可能一瞬间你的消费者服务接收到了达到prefetch count指定数量的消息。
打个比方,比如一下子你的消费者服务内存里积压了10万条消息,都是unack的状态,反正你的prefetch count设置的是10万。
那么对一个channel,RabbitMQ就会最多容忍10万个unack状态的消息,在高并发下也就最多可能积压10万条消息在消费者服务的内存里。
那么此时导致的结果,就是消费者服务直接被击垮了,内存溢出,OOM,服务宕机,然后大量unack的消息会被重新投递给其他的消费者服务,此时其他消费者服务一样的情况,直接宕机,最后造成雪崩效应。
所有的消费者服务因为扛不住这么大的数据量,全部宕机。
大家来看看下面的图,自己感受一下现场的氛围。

低吞吐量问题
那么如果反过来呢,我们要是把prefetch count设置的很小会如何呢?
比如说我们把 prefetch count 设置为1?此时就必然会导致消费者服务的吞吐量极低。因为你即使处理完一条消息,执行ack了也是异步的。
给你举个例子,假如说你的 prefetch count = 1,RabbitMQ最多投递给你1条消息处于 unack 状态。
此时比如你刚处理完这条消息,然后执行了 ack 的那行代码,结果不幸的是,ack需要异步执行,也就是需要100ms之后才会让RabbitMQ感知到。
那么100ms之后RabbitMQ感知到消息被ack了,此时才会投递给你下一条消息!
这就尴尬了,在这100ms期间,你的消费者服务是不是啥都没干啊?
这不就直接导致了你的消费者服务处理消息的吞吐量可能下降10倍,甚至百倍,千倍,都有这种可能!
大家看看下面的图,感受一下低吞吐量的现场。

合理的设置prefetch count
所以鉴于上面两种极端情况,RabbitMQ官方给出的建议是prefetch count一般设置在100~300之间。
也就是一个消费者服务最多接收到100~300个message来处理,允许处于unack状态。
这个状态下可以兼顾吞吐量也很高,同时也不容易造成内存溢出的问题。
但是其实在我们的实践中,这个prefetch count大家完全是可以自己去压测一下的。
比如说慢慢调节这个值,不断加大,观察高并发大流量之下,吞吐量是否越来越大,而且观察消费者服务的内存消耗,会不会OOM、频繁FullGC等问题。
阶段性总结
其实通过最近几篇文章,基本上已经把消息中间件的消费端如何保证数据不丢失这个问题剖析的较为深入和透彻了。
如果你是基于RabbitMQ来做消息中间件的话,消费端的代码里,必须考虑三个问题:手动ack、处理失败的nack、prefetch count的合理设置
这三个问题背后涉及到了各种机制:
- 自动ack机制
- delivery tag机制
- ack批量与异步提交机制
- 消息重发机制
- 手动nack触发消息重发机制
- prefetch count过大导致内存溢出问题
- prefetch count过小导致吞吐量过低
这些底层机制和问题,咱们都一步步分析清楚了。
所以到现在,单论消费端这块的数据不丢失技术方案,相信大家在面试的时候就可以有一整套自己的理解和方案可以阐述了。
接下来下篇文章开始,我们就来具体聊一聊:消息中间件的生产端如何保证数据不丢失。
互联网面试必杀:如何保证消息中间件全链路数据100%不丢失:第一篇
互联网面试必杀:如何保证消息中间件全链路数据100%不丢失:第二篇
互联网面试必杀:如何保证消息中间件全链路数据100%不丢失:第四篇
来源:【微信公众号 - 石杉的架构笔记】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号