互联网面试必杀:如何保证消息中间件全链路数据100%不丢失:第一篇
背景引入
这篇文章,我们来聊聊在线上生产环境使用消息中间件技术的时候,从前到后的全链路到底如何保证数据不能丢失。
这个问题,在互联网公司面试的时候高频出现,而且也是非常现实的生产环境问题。
如果你的简历中写了自己熟悉MQ技术(RabbitMQ、RocketMQ、Kafka),而且在项目里有使用的经验,那么非常实际的一个生产环境问题就是:投递消息到MQ,然后从MQ消费消息来处理的这个过程,数据到底会不会丢失。
面试官此时会问:如果数据会丢失的话,你们项目生产部署的时候,是通过什么手段保证基于MQ传输的数据100%不会丢失的?麻烦结合你们线上使用的消息中间件来具体说说你们的技术方案。
这个其实就是非常区分面试候选人技术水平的一个问题。
实际上相当大比例的普通工程师,哪怕是在一些中小型互联网公司里工作过的,也就是基于公司部署的MQ集群简单的使用一下罢了,可能代码层面就是基本的发送消息和消费消息,基本没考虑太多的技术方案。
但是实际上,对于MQ、缓存、分库分表、NoSQL等各式各类的技术以及中间件在使用的时候,都会有对应技术相关的一堆生产环境问题。
那么针对这些问题,就必须要有相对应的一整套技术方案来保证系统的健壮性、稳定性以及高可用性。
所以其实中大型互联网公司的面试官在面试候选人的时候,如果考察对MQ相关技术的经验和掌握程度,十有八九都会抛出这个使用MQ时一定会涉及的数据丢失问题。因为这个问题,能够非常好的区分候选人的技术水平。
所以这篇文章,我们就来具体聊聊基于RabbitMQ这种消息中间件的背景下,从投递消息到MQ,到从MQ消费消息出来,这个过程中有哪些数据丢失的风险和可能。
然后我们再一起来看看,应该如何结合MQ自身提供的一些技术特性来保证数据不丢失?
前情回顾
首先给大伙一点提醒,有些新同学可能还对MQ相关技术不太了解,建议看一下之前的MQ系列文章,看看MQ的基本使用和原理:
另外,其实之前我们有过2篇文章是讨论消息中间件的数据不丢失问题的。
我们分别从消费者突然宕机可能导致数据丢失,以及集群突然崩溃可能导致的数据丢失两个角度讨论了一下数据如何不丢失。
只不过仅仅那两个方案还无法保证全链路数据不丢失,但是大家如果没看过的建议也先回过头看看:
总之,希望对MQ不太熟悉的同学,先把前面那些系列文章熟悉一下,然后再来一起系统性的研究一下MQ数据如何做到100%不丢失。
目前已有的技术方案
经过之前几篇文章的讨论,目前我们已经初步知道,第一个会导致数据丢失的地方,就是消费者获取到消息之后,没有来得及处理完毕,自己直接宕机了。
此时RabbitMQ的自动ack机制会通知MQ集群这条消息已经处理好了,MQ集群就会删除这条消息。
那么这条消息不就丢失了么?不会有任何一个消费者处理到这条消息了。
所以之前我们详细讨论过,通过在消费者服务中调整为手动ack机制,来确保消息一定是已经成功处理完了,才会发送ack通知给MQ集群。
否则没发送ack之前消费者服务宕机,此时MQ集群会自动感知到,然后重发消息给其他的消费者服务实例。
《扎心!线上服务宕机时,如何保证数据100%不丢失?》这篇文章,详细讨论了这个问题,手动ack机制之下的架构图如下所示:
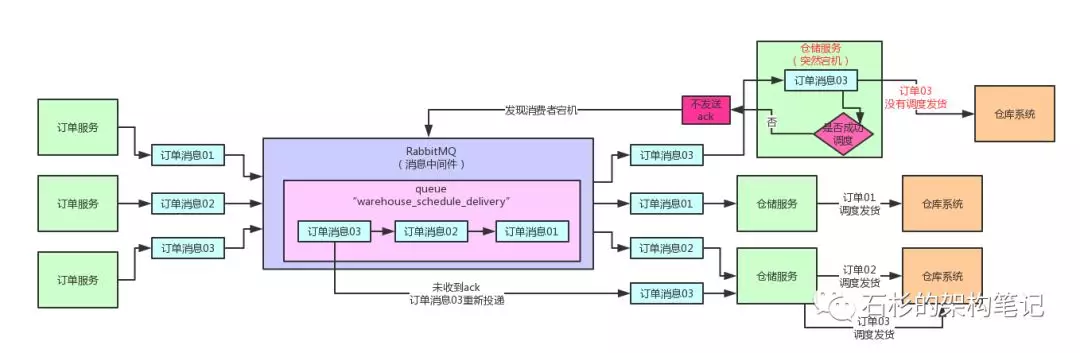
当时除了这个数据丢失问题之外,还有另外一个问题,就是MQ集群自身如果突然宕机,是不是会导致数据丢失?
默认情况下是肯定会的,因为queue和message都没采用持久化的方式来投递,所以MQ集群重启会导致部分数据丢失。
所以《消息中间件集群崩溃,如何保证百万生产数据不丢失?》这篇文章,我们分析了如何采用持久化的方式来创建queue,同时采用持久化的方式来投递消息到MQ集群,这样MQ集群会将消息持久化到磁盘上去。
此时如果消息还没来得及投递给消费者服务,然后MQ集群突然宕机了,数据是不会丢失的,因为MQ集群重启之后会自动从磁盘文件里加载出来没投递出去的消息,然后继续投递给消费者服务。
同样,该方案沉淀下来的系统架构图,如下所示:

数据100%不丢失了吗?
大家想一想,到目前为止,咱们的架构一定可以保证数据不丢失了吗?
其实,现在的架构,还是有一个数据可能会丢失的问题。
那就是上面作为生产者的订单服务把消息投递到MQ集群之后,暂时还驻留在MQ的内存里,还没来得及持久化到磁盘上,同时也还没来得及投递到作为消费者的仓储服务。
此时要是MQ集群自身突然宕机,咋办呢?
尴尬了吧,驻留在内存里的数据是一定会丢失的,我们来看看下面的图示。

按需制定技术方案
现在,我们需要考虑的技术方案是:订单服务如何保证消息一定已经持久化到磁盘?
实际上,作为生产者的订单服务把消息投递到MQ集群的过程是很容易丢数据的。
比如说网络出了点什么故障,数据压根儿没传输过去,或者就是上面说的消息刚刚被MQ接收但是还驻留在内存里,没落地到磁盘上,此时MQ集群宕机就会丢数据。
所以首先,我们得考虑一下作为生产者的订单服务要如何利用RabbitMQ提供的相关功能来实现一个技术方案。
这个技术方案需要保证:只要订单服务发送出去的消息确认成功了,此时MQ集群就一定已经将消息持久化到磁盘了。
我们必须实现这样的一个效果,才能保证投递到MQ集群的数据是不会丢失的。
需要研究的技术细节
这里我们需要研究的技术细节是:仓储服务手动ack保证数据不丢失的实现原理。
之前,笔者就收到很多同学提问:
- 仓储服务那块到底是如何基于手动ack就可以实现数据不丢失的?
- RabbitMQ底层实现的细节和原理到底是什么?
- 为什么仓储服务没发送ack就宕机了,RabbitMQ可以自动感知到他宕机了,然后自动重发消息给其他的仓储服务实例呢?
这些东西背后的实现原理和底层细节,到底是什么?
大伙儿稍安勿躁,接下来,咱们会通过一系列文章,仔细探究一下这背后的原理。
互联网面试必杀:如何保证消息中间件全链路数据100%不丢失:第二篇
互联网面试必杀:如何保证消息中间件全链路数据100%不丢失:第三篇
互联网面试必杀:如何保证消息中间件全链路数据100%不丢失:第四篇
来源:【微信公众号 - 石杉的架构笔记】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号