【Unity】Shader优化总结
分为三个部分:Unity官方文档,GDC,个人经验。
Unity Manual
1.计算量优化。着色器进行的计算和处理越多,对性能的影响越大。针对不影响最终效果但依然进行计算的无效代码,进行移除操作。计算的频率也会影响游戏的性能。通常,像素着色器比顶点着色器的执行次数要多。在可能的情况下,将计算从像素着色器移动到顶点着色器,或将它们完全在着色器移除,在脚本中计算并传递给着色器。
2.表面着色器优化。Unity提供的表面着色器非常适合编写与光照交互的着色器。针对特定情况设置关键字以使着色器效率更高或减小体积:
approxview使用逐顶点而不是逐像素的规范化观察向量。虽然是近似值,通常足够使用。镜面反射着色器类型使用halfasview更快。计算半角向量并逐顶点进行规范化,并且光照函数使用半角向量而不是观察向量作为参数。noforwardadd着色器仅完全支持前向渲染中的一个定向光源。其余的光源仍然可以有逐顶点光照或球谐的效果。减少了着色器大小,即使存在多个灯光始终只渲染一次。noambient禁用着色器的环境光和球谐光照。
3.计算精度优化。当使用CG / HLSL编写着色器时,存在三种基本的数字类型:float(32bits),half(16bits)和fixed(11bits)
- 对于世界空间位置和纹理坐标,使用
float精度。 - 对于其他一切(矢量,HDR颜色等),首先使用
half精度,必要时增加精度。 - 对于纹理数据的非常简单的操作,使用
fixed精度。
实际上,应该使用哪种数据精度取决于平台和GPU。一般来说:
- 所有现代桌面级GPU总是以完全
float精度进行计算,float/half/fixed在底层是完全相同的。因此在Unity编辑器中(即使切换为移动平台),难以确定半/固定精度是否足够,因此请始终在目标设备上测试着色器以获得准确的结果。 - 移动GPU具有实际
half精度支持。通常更快,并且使用更少的功率来进行计算。 Fixed精度通常仅对较旧的移动GPU有效。大多数现代GPU(支持OpenGL ES 3.0或Metal)内部处理fixed和half精度完全相同。
4.Alpha Testing优化。固定函数AlphaTest - 或其可编程等价函数clip()- 在不同平台上具有不同的性能表现:
- 通常,在大多数平台上使用它来移除的完全透明像素时,有些许性能优势。
- 但是,在iOS和某些使用PowerVR GPU的Android设备上,alpha testing是资源密集型的。不要试图在这些平台上使用它进行性能优化,会导致游戏运行速度比平常慢。
5.Color Mask优化。在某些平台上(主要是iOS和Android设备中的移动GPU),使用ColorMask忽略某些通道(例如ColorMask RGB)可能是资源密集型的,因此请在必要时才使用。
GDC
GDC2013和GDC2014上介绍了DX10和DX11上PC和Console上的底层着色语言优化,将优化放在减少着色器指令数量上面。
GDC2013:http://www.humus.name/Articles/Persson_LowLevelThinking.pdf
GDC2014:http://www.humus.name/Articles/Persson_LowlevelShaderOptimization.pdf
个人认为,在PC和Console平台上对于指令数量的优化意义并不大。但是在移动平台,指令数量的优化还是有必要。虽然SM3.0指令数量已经基本不会对着色器编写复杂度进行限制,但是如果要求支持SM2.0,96条指令数量要求十分严苛。
由于着色器指令的优化与硬件(HW)关系密切,因此我们需要根据硬件厂商提供的相关文档进行优化。移动平台的三大GPU品牌,分别是PowerVR,Mali,Adreno。PowerVR有专门的GLSL优化文档,Mali和Adreno也有相关文档提到这部分内容。
但这样做,必然会增加着色器变体数量,因为我们要使用关键字来选择执行不同的代码,这会生成不同的着色器变体。
根据PowerVR Low Level GLSL Optimisation,我这里列举一些优化的方式。至于Mali和Adreno的优化,需要参考其开发文档进行。
通常来讲,在PowerVR上的Shader性能取决于执行Shader的周期次数。PowerVR Rogue架构提供了多种选择用于在USC ALU管线中的单一周期执行多个指令。
从下图可以看到,在一个周期内,可以执行最多三个Phase。为了高效的利用ALU,按照下面的规则,重新排列我们的GLSL代码是明智的。
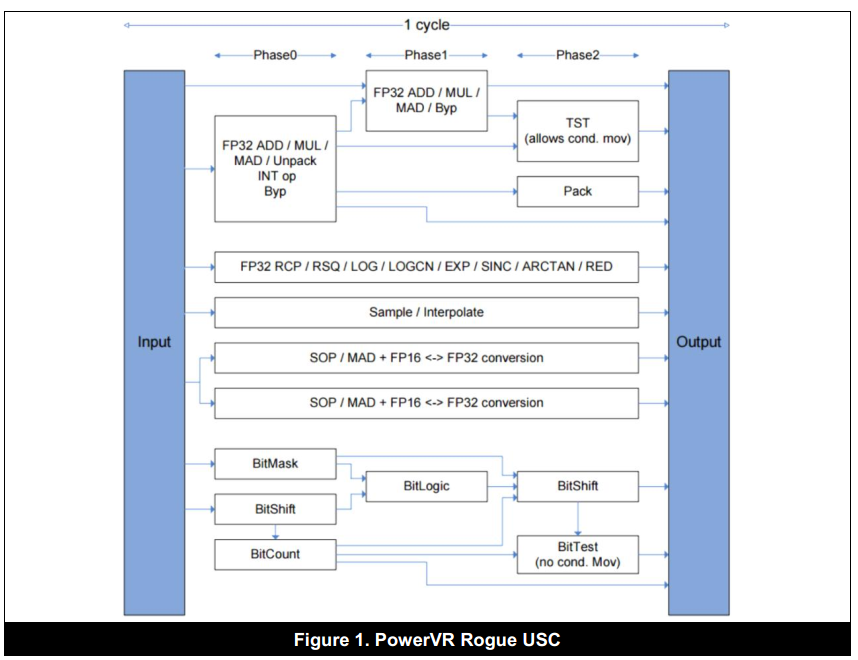
指令优化
1.MAD
上图可以知道,MAD和MUL/ADD均占用一个Phase,但是MAD却执行了a*b+c的计算,这想当于一个Phase执行了一次乘法和加法。将表达式是改为MAD形式,会减少50%的周期消耗。

2.Division
将除法写为乘以除数的倒数(rcp)的形式,对优化有帮助。同样的,简化表达式也会获得额外的性能增加。

3.Sign
sign(x)的计算是这样的:返回 -1 if x<0; 0 if x =0;1 if x >0.
如果不需要x=0的情况,那么最好的方式是自己实现。

4.Rcp/Rsqrt/Sqrt
在PowerVR Rogue架构中,倒数操作是直接一条指令支持的。

rsqrt()也同样是硬件支持的。

sqrt()在另一方面是以1/(1/sqrt(x))的方式实现的,因此它占用两个循环。

一般来说用替代的实现x*1/sqrt(x)实现sqrt的功能。

同样是两个周期,使用替代实现更好的唯一情形是结果会被测试。在这种情况下,测试指令刚好放入第二条指令中。
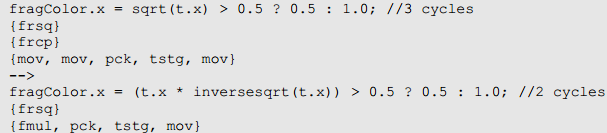
5.Abs/Neg/Saturate
在PowerVR架构中,修饰符如abs(),neg()和clamp(…,0.0,1.0)(相当于saturate())的优势是很重要的,因为在特定的情况下,他们没有消耗。abs()和neg()如果用于操作的输入,是无消耗的。在这种情况下,他们被编译器转换成无消耗的修饰。saturate()相反,当用于操作的输出的时候,被转换为无消耗的修饰。
但是对于复杂的或者采样/插值指令却不符合这个规则。换句话说,对于纹理采样输出,或者复杂的指令输出,saturate()并不是无消耗的。当这些函数没有使用时,它们可能会引入额外的mov指令,这些指令可能会影响着色器的循环计数。
使用clamp(…,0.0,1.0)而不是min(…,1.0)和max(…,0.0)也有利于优化。这令原有的测试指令变为saturate修饰符。




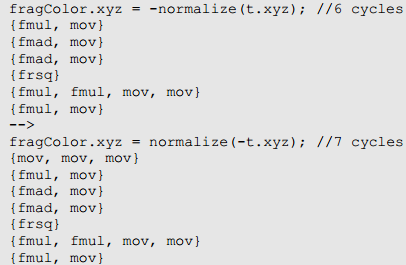
之后,对于复杂函数,他们被译为多个操作并且因此在这个情形下,修饰符的位置就十分重要。比如,规范化函数normalize(),它的实现。

正如所看到的,在这种情况下,最好是对最终乘法的一个输入取负,而不是所有情况下的都对输入取负,或者创建一个临时的负值输入:
6.Exp/Log
在PowerVR Rogue架构,2^n操作是一条指令支持的操作。
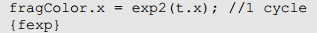
Log2()同样。

Exp()与Exp2()的实现不同,占用两个循环。
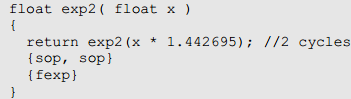
Pow(x,y)的实现如下,需要三个周期。

7.Sin/Cos/Sinh/Cosh
Sin,Cos,Sinh,Cosh在PowerVR架构上有适度的四个周期的低消耗。它们被分解为fred*2+fsinc+一个条件。




8.Asin/Acos/Atan/Degrees/Radians
如果实现了数学表达式的简化,之后的这些函数通常不会被用到。因此,它们并不会精确的映射到硬件。这意味着这些函数有者非常高的消耗,并且在任何时候都应该避免使用。
Asin()耗费多达67个周期。

Acos()耗费多达79个周期。

Atan()依然比较耗,但是如果需要的话还是可以使用的。

虽然degrees和radians只有一个周期,但如果只使用弧度进行计算,通常是可以避免的。


9.Vector*Matrix
Vector*Matrix有一个相对比较合理的开销,不管需要发生的计算数量。优化例如会知道w=1的优势,但并不会降低开销。

10.Mixed Scalar/Vector math
Normalize()/length()/distance()/reflect()等函数内部通常会包含许多的函数调用例如dot()。知道这些函数是如何实现的是一个优势。
例如,如果我们知道两个操作有共享的子表达式,我们可以减少周期数量。然而,这只在如果输入顺序允许的情况下发生。

手动的展开这些复杂的函数有时可以帮助编译器优化代码。
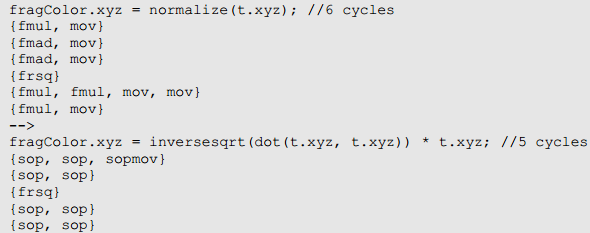
同样的,在展开形式组合向量和标量指令也可能得到优化。
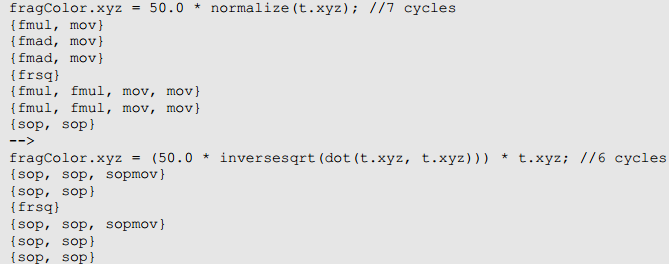
下面列举一些复杂指令的展开形式。
cross()可以扩展为:

distance()可以扩展为:

dot()可以扩展为:

faceforward()可以扩展为:

length()可以扩展为:

normalize()可以扩展为:

reflect()可以扩展为:
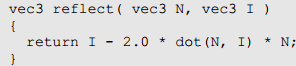
refract()可以扩展为:

11.Operation grouping
将标量和向量操作分别组合是有利于优化的。这样编译器可以将更多的操作打包到单一的周期中。

FP16概述
1.FP16精度和转化
当简化的精度满足的时候,FP16的管线工作的不错。然而,依然建议经常检查优化后的结果会不会出现精度瑕疵。当16位的浮点精度硬件可用,并且着色器使用中精度的时候,16位与32位的转化使用修饰符是无开销的,因为被USC ALU管线包含了它。
然而,当着色器不使用16位指令或者例如早期的Rogue硬件硬件不包含16位浮点管线,指令只会在常规的32位管线执行并且因此也不会有转化发生。
2.FP6 SOP/MAD operation
FP16 SOP/MAD管线是PowerVR ALU管线最强大的地方之一。如果使用得当。它允许开发者打包更多到操作到单一周期中。这可以提高性能并降低功率消耗。
单一周期的FP16 SOP/MAD操作可以被以下的伪代码描述:
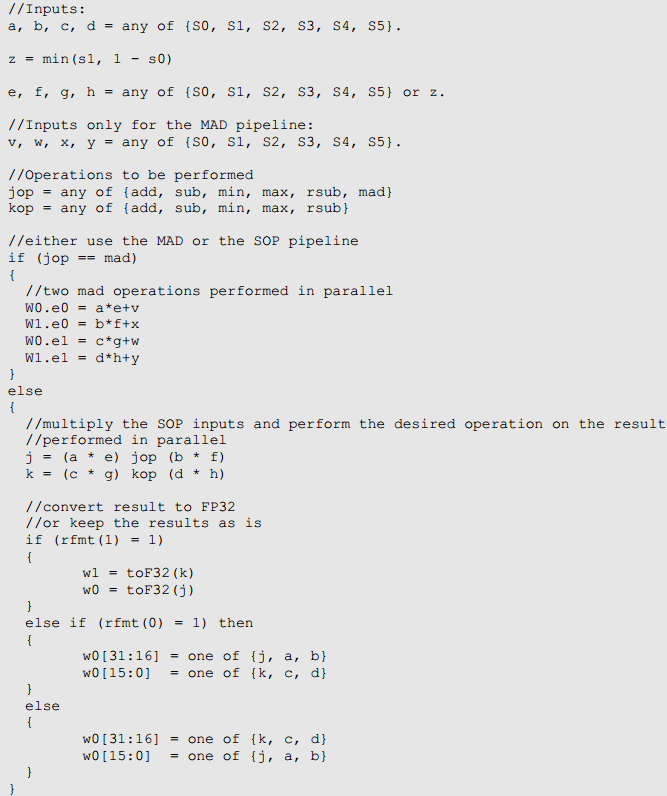
输入应用各种修饰符(abs(),negete(),oneminus())和输出应用clamp()也是合适的。下一小节介绍如何完全的利用FP16 SOP/MAD管线。
3.利用FP16 SOP/MAD管线
PowerVR Rogue架构有一个强大的为常规图形操作优化的FP16管线。这节描述了如何利用FP16管线。注意转换输入到FP16之后转换输出到FP32是零开销很重要。
对SOP/MAD你有许多的选择。在一个周期中,你可以执行2个SOP操作或2个MAD操作或1个MAD+1个SOP操作。二选一的,你可以在单一周期执行4个FP16 MAD操作。
在单一周期执行4个MAD:

SOP表示乘法的结果之间选择一个操作的点积之和:

这里OP可以是一个加法,减法,min()或者max():

你也可以对输入应用取负,abs()或者clamp()(saturate)中的任一:

最后,你也可以对最终结果应用clamp()(saturate):

在应用完所有的知识之后,我们可以通过使用单一周期的任何事情来炫耀我们的管线功率:

经验
1.将一些计算烘焙到纹理
具体来讲,就是使用纹理读取的方式减轻运算量。在一般硬件,采样操作占用一个周期。如果将BRDF的D/F/G等计算烘焙到一张RGBA的四个通道中,我们只需要计算输入的几个点积结果以及粗糙度等参数,通过采样纹理得到计算结果(或者是中间结果)。这部分的操作比较灵活。在不追求计算精确的情况下,以空间换时间。
2.计算转移的思考
由Unity的官方手册优化建议第一条,我们可以知道,在Shader编写中,我们可以知道有些计算,在不影响表现的情况下,是可以放到三个部分中的,顶点着色器,片段着色器以及脚本中。顶点着色器和片段着色器,分别是逐顶点和逐像素来进行计算的。而脚本中,是每一帧计算的(Update函数)。
那把计算放到哪里更能优化性能?Unity的官方文档给出的建议的脚本优于顶点着色器优于像素着色器。
在不考虑剔除的情况下:
顶点着色器:逐顶点计算,计算次数等于顶点数。
片段着色器:逐像素计算,计算次数等于像素数。
脚本:逐帧计算,每帧计算一次。
从计算次数上来看效率,脚本>顶点着色器>片段着色器。
然而区别是,顶点着色器和片段着色器是Shader内部的计算,运行在GPU上。计算从片段着色器移动至顶点着色器使得性能得到优化是没有疑问的。而脚本的计算则是运行在CPU上,计算得到的结果传递给GPU也会有性能的开销。
举两个极端的例子:
模型1:超高精度模型,模型顶点数1000W。(Nvidia的技术展示Demo)
模型2:Quad,模型顶点数4。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号