Mongodb学习笔记
1.Mongodb:
文档数据库,存储的是文档(bson->json的二进制化)
特点:内部引擎用JS解释器,把文档存储成bson结构,在查询时转换为js对象,并可以通过熟悉的js语法操作。
2.Mongo和mysql(传统型数据库)比最大的不同:
传统型数据库:结构化数据,定好了表结构后,每一行的内容必是符合表结构的,就是说列的个数类型都一样
Mongo文档型数据库:表下的每篇文档都可以有自己独特的结构(json对象都可以有自己独特的属性和值)
思路:如果有电影,影评,影评的回复,回复的打分,在传统型数据库中,至少要4张表,关联度非常复杂
在文档数据库中,通过1篇文档即可完成。体现出文档型数据库的反范式化。
3.安装过程:
Linux操作系统下
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.2.5.tgz
2. 解压:tar zxf mongodb-linux-x86_64-rhel70-4.2.5.tgz
3 .不用编译,本身就是二进制可执行文件文件
mv mongodb-linux-x86_64-rhel70-4.2.5 /usr/local/mongodb
cd /usr/local/mongod
4.启动mongod服务
./bin mongod --dbpath /path/to/database --logpath /path/to/xx.log --fork --port 27017
--dbpath:数据库存放目录
--logpath:日志存放目录(注意要写上log名)
--port:运行端口(默认27017)
--fork:后台进程运行
(mongodb非常的占磁盘空间,可以用--smailfiles选项来启动,将会占用较小的空间)
5.查看是否启动成功:ps aux | grep mongo

6.连接:./bin/mongo
4.Mongodb基本命令:
- show dbs :查看当前数据库
- use databaseName:选库
- show tables/collections:查看当前库下的表
- 如何创建库
Mongodb的库是隐式创建的,你可以use一个不存在的库
然后在该库下创建collection,即可创建库
use shop
db.createCollection('user')
插入一条数据:
db.user.insert({name:'zhangsan',age:24})
db.user.find()
指定id,不使用系统生成的id:
db.user.insert({_id:3,name:'lisi',age:27})
db.user.insert({_id:4,name:'hmm',hobby:['basketball','footerball'],intro:{'title':'my intro','content':'from china'}})
collection允许隐式创建:
db.goods.insert({_id:1,name:'NOKIA98',price:29.9})
删除表:
db.use.drop()
删除库:
db.dropDatabase()
CURD操作:
批量插入数据:
db.stu.insert([{_id:3,sn:003,name:'xiaoli'},{_id:4,sn:004,name:'xiaozhang'},{_id:5,sn:005,name:'xiaocai'}])
删除:
db.stu.remove({sn:'002'})
删除stu表中sn属性值为001的文档
删除全部:db.stu.remove()
注意:
查询表达式依然是个json对象
查询表达式匹配的行将被删掉
如果不写查询表达式,collections中的所有文档将被删掉
只删除一行:
db.stu.remove({name:'xiaoming'},true)
改:update操作 ({}代表整篇文档)
改谁:查询表达式
改成什么样:新值或赋值表达式
操作细则:可选参数
整篇文档修改:db.stu.update({name:'xiaoli'},{name:'wudalang'})
部分字段修改:db.stu.update({name:'xiaocai'},{$set:{name:'caicai'}})
db.stu.update({name:'wukong'},{$set:{name:'douzhanshengfo'},$unset:{jingu:1},$rename:{sex:'gender'},$inc:{age:10}})
修改的赋值表达式:
$set:修改某列的值(默认只修改一样行)
$unset:删除某个列
$rename:重命名某个列
$inc:增长某个列的值
$setOnInsert:当upsert为true时,并且insert成功,你可以补充该字段
Option的作用:
(upsert:true/false,multi:true/false)
Upsert:指没有匹配的行,则直接插入该行。如果有,则修改(和mysql的replace一样)
db.stu.update({_id:99},{x:123,y:456},{upsert:true})
db.stu.update({name:'wusong'},{$set:{name:'zingzhewusong'},$setOnInsert:{general:'male'}},{upsert:true})
Multi:指修改多行(即使查询表达式命中多行默认也只改1,可以用此项修改多行)
db.stu.update({jingu:true},{$set:{sex:'m'}},{multi:true})
查询:
语法:db.collection.find(查询表达式,查询的列)
查询所有:db.stu.find()
查询所有文档某列:db.stu.find({},{general:1})
不查询id属性:db.stu.find({},{general:1,_id:0})
查询条件:db.stu.find({name:'wukong'},{sex:1,_id:0})
查询表达式:
查出满足以下条件的商品
1.1:主键为32的商品
db.goods.find({goods_id:32});
1.2:不属第3栏目的所有商品($ne)
db.goods.find({cat_id:{$ne:3}},{goods_id:1,cat_id:1,goods_name:1});
1.3:本店价格高于3000元的商品{$gt}
db.goods.find({shop_price:{$gt:3000}},{goods_name:1,shop_price:1});
1.4:本店价格低于或等于100元的商品($lte)
db.goods.find({shop_price:{$lte:100}},{goods_name:1,shop_price:1});
1.5:取出第4栏目或第11栏目的商品($in)
db.goods.find({cat_id:{$in:[4,11]}},{goods_name:1,shop_price:1});
1.6:取出100<=价格<=500的商品($and)
db.goods.find({$and:[{price:{$gt:100},{$price:{$lt:500}}}]);
1.7:取出不属于第3栏目且不属于第11栏目的商品($and $nin和$nor分别实现)
db.goods.find({$and:[{cat_id:{$ne:3}},{cat_id:{$ne:11}}]},{goods_name:1,cat_id:1})
db.goods.find({cat_id:{$nin:[3,11]}},{goods_name:1,cat_id:1});
db.goods.find({$nor:[{cat_id:3},{cat_id:11}]},{goods_name:1,cat_id:1});
1.8:取出价格大于100且小于300,或者大于4000且小于5000的商品()
db.goods.find({$or:[{$and:[{shop_price:{$gt:100}},{shop_price:{$lt:300}}]},{$and:[{shop_price:{$gt:4000}},{shop_price:{$lt:5000}}]}]},{goods_name:1,shop_price:1});
1.9:取出goods_id%5 == 1, 即,1,6,11,..这样的商品
db.goods.find({goods_id:{$mod:[5,1]}});
1.10:取出有age属性的文档
db.stu.find({age:{$exists:1}});
含有age属性的文档将会被查出
1.11:取出字段类型是字符串的文档:$type
db.stu.find({age:{$type:2}})
1.12:判断数组中满足所有条件的文档:
db.stu.find({hobby:{$all:['v','a']}})
1.13:直接用where语句
db.goods.find({$where:'this.shop_price>100'})



游标操作:
插入一万条数据:for (var i=0;i <10000;i++){db.bar.insert({_id:i+1,title:'hello word',content:'xuhao'+i})}
游标是什么?
通俗的说,游标不是查询结果,而是查询的返回资源或者接口
通过这个接口,你可以逐条读取。
声明游标:
var mycusor=db.bar.find()
var mycusor=db.bar.find({_id:{$lte:5}})
printjson(mycusor.next())
While循环游标:
while(mycusor.hasNext()){printjson(mycusor.next())}
For循环:
for(var mycusor=db.bar.find({_id:{$lte:5}});mycusor.hasNext();){printjson(mycusor.next())}
forEach:
mycusor.forEach(function(obj){printjson(obj)})
游标在分页中的应用:
var mycusor=db.bar.find().skip(9995)
skip():在查询结果中,跳过多少行
查询第901页,每页10条
db.bar.find().skip(9000).limit(10)
索引:
- 索引提高查询速度,降低写入速度,权衡常用的查询字段,不必在太多的列上建立索引
- 在mongodb中索引可以按字段升序/降序来创建,便于排序
- 默认是用btree来组织索引文件
查看查询计划:
db.bar.find({_id:1001}).explain()
添加索引:
db.bar.ensureIndex({content:1})
删除索引:
db.bar.dropIndex({content:1})
删除所有索引:
db.bar.dropIndexes()
多列创建索引:
db.bar.ensureIndex({_id:1,content:1})
查看索引:
db.bar.getIndexes()
子文档查询:
db.shop.find({‘spc.area’:’taiwan’}) 用.(点)不断指向子文档
子文档添加索引:
db.shop.ensureIndex({‘spc.area’:1})
索引性质:
普通索引
唯一索引:db.stu.ensureIndex({email:1},{unique:true})
稀疏索引:如果针对field做索引,针对不含field列的文档,将不建立索引(忽略不存在的列)。与之相对,普通索引会把该文档的field列的值认为NULL,并建立索引。适用于:小部分文档含有某列时。在查询时,普通索引可以根据field:null查到,而稀疏索引查询不到
稀疏索引创建:db.stu.ensureIndex({email:1},{sparse:true})
哈希索引:db.stu.ensureIndex({email:’hashed’})
重建索引
一张表经过多次修改后,导致表的文件产生空洞,索引文件也如此
可以通过索引的重建,减少索引文件碎片,来提高索引的效率
db.bar.reIndex()
用户管理:
在mongodb中,有一个admin数据库,牵涉到服务器配置层面的操作,需要先切换到admin数据库,即:use admin
Mongo的用户是以数据库为单位创建的,每个数据库有自己的管理员
我们在设置用户时,需要先在admin数据库下建立管理员----这个管理员登陆后,相当于超级管理员
添加用户:
db.createUser({user: 'admin', pwd: 'admin', roles: [{role:'readWrite', db: 'stu'}]})
注意:添加用户后,我们再次退出并登陆,发现依然可以直接读取数据库。原因是mongodb服务器启动时,默认不是需要认证的。要让用户生效,需要启动服务器时,指定 --auth选项。
认证登陆:db.auth('admin','admin')
修改用户:db.changeUserPassword('admin','admin123')
删除用户:db.dropUser('admin')
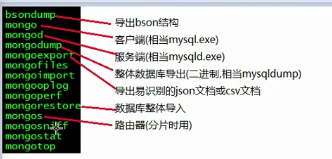
数据备份和恢复:

./bin/mongoexport -d test -c stu -f sn,name -o ./test.stu.json

./bin/mongoimport -d test -c animal --type json --file ./test.stu.json
./bin/mongoimport -d test -c bird --type csv -f sn,name --file ./test.stu
二进制导出:

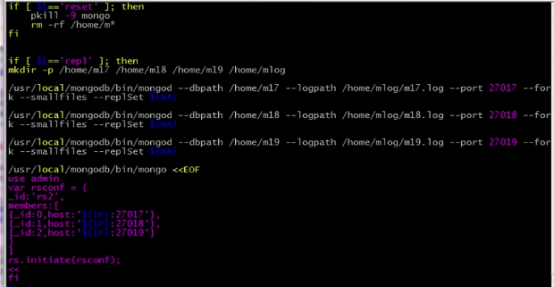
Replication set 复制集:




初始化:
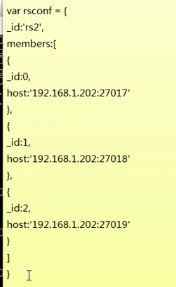
根据配置做初始化:



连接不同的mongodb:

自动化脚本:

实战:生成短网址
Php-mongodb扩展编译:
wget http://pecl.php.net/get/mongodb-1.9.0.tgz
tar zxf mongodb-1.9.0.tgz
find / -name phpize
编译安装:
/www/server/php/73/bin/phpize
find / -name php-config
./configure --with-php-config=/www/server/php/73/bin/php-config
make && make install
find / -name php.ini
vim /www/server/php/73/etc/php.ini
添加:
extension = /www/server/php/73/lib/php/extensions/no-debug-non-zts-20180731/mongodb.so
重启php:service php-fpm restart
使用php -m 查看是否添加成功
Mongodb中如何生成一个不断递增的数字:
db.cnt.insert({_id:1,sn:0})
db.cnt.findAndModify({query:{_id:1},update:{$inc:{sn:1}}})
Php写法:
$manager = new MongoDB\Driver\Manager("mongodb://localhost:27017");
//自增长
$cmd = new \MongoDB\Driver\Command([
'findAndModify' => 'cnt',
'query' => ['_id' => 1],
'update' => ['$inc' => ['sn' => 1]]
]);
$rows = $manager->executeCommand('test', $cmd);
foreach ($rows as $r) {
print_r($r);
}
Aggregate聚集框架
分组:
db.goods.aggregate({$group:{_id:"$cat_id",total:{$sum:1}}})
查询每个栏目下 价格大于50的商品个数
db.goods.aggregate([{$match:{shop_price:{$gt:50}}},{$group:{_id:"$cat_id",total:{$sum:1}}}])
并筛选出商品满足条件的商品个数 >=3 的栏目:
db.goods.aggregate([{$match:{shop_price:{$gt:50}}},{$group:{_id:"$cat_id",total:{$sum:1}}},{$match:{total:{$gt:3}}}])
查询每个栏目下的库存量
db.goods.aggregate([{$group:{_id:"$cat_id",total:{$sum:"$goods_number"}}}])
查询每个栏目下的库存量,并按库存量排序
db.goods.aggregate([{$group:{_id:"$cat_id",total:{$sum:"$goods_number"}}},{$sort:{total:1}}])
取3条
db.goods.aggregate([{$group:{_id:"$cat_id",total:{$sum:"$goods_number"}}},{$sort:{total:-1}},{$limit:3}])
查询每个栏目下的商品平均价格,并按平均价格由高到低排序:
db.goods.aggregate([{$group:{_id:"$cat_id",avg:{$avg:"$shop_price"}}},{$sort:{avg:-1}}])
Mapreduce:
Map-->映射
Reduce->归约
用mapRudece计算每个栏目的库存总量
Map函数:
var map=function (){
emit(this.cat_id,this.good_number);
}
var reduce=function (cat_id,numbers){
return Array.sum(numbers);
}
db.goods.mapReduce(map,reduce,{out:’res’})
PHP使用mongodb类操作mongodb例子:
<?php //连接MongoDB $manager = new MongoDB\Driver\Manager("mongodb://localhost:27017"); //自增长 $cmd = new \MongoDB\Driver\Command([ 'findAndModify' => 'cnt', 'query' => ['_id' => 1], 'update' => ['$inc' => ['sn' => 1]] ]); $rows = $manager->executeCommand('test', $cmd); foreach ($rows as $r) { print_r($r); } #插入数据 //创建一个BulkWrite对象 $bulk = new \MongoDB\Driver\BulkWrite(); $bulk->insert(['name'=>'tea li','age'=>25,'email'=>'zhuoshaouu@qq.com']); $bulk->insert(['name'=>'tea wang','age'=>30,'email'=>'wangli@qq.com']); //执行插入 $res=$manager->executeBulkWrite('test.tea', $bulk);
♥ 作者:离岸少年
♠ 出处:https://www.cnblogs.com/jackzhuo/
♣ 本博客大多为学习笔记或读书笔记,本文如对您有帮助,还请多推荐下此文,如有错误欢迎指正,相互学习,共同进步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号