Android知识大纲
Android知识大纲
Java垃圾回收机制
Java内存是如何划分的,Java语言为什么要使用垃圾回收机制?
垃圾判定
1. 标记引用算法
2. 根搜索法
垃圾清扫
1. 标记-清除法 概念以及特点
2. 复制算法
3. 标记-整理法
4. 分代回收算法
有了垃圾回收机制,Java还会出现内存泄露吗,如果说存在,Java有什么应对机制吗?
Java的四种引用方式
- 强引用
- 软引用
- 弱引用
- 虚引用
软引用、弱引用配合引用队列如何使用,使用的目的是什么?
可参考:http://blog.csdn.net/u012152619/article/details/46981643
以上这么多关于Java垃圾回收和内存的东西,你在编写代码的时候有需要注意的地方吗?
java数据结构
数据结构相关的类:Collection、List、Set、Map
List: ArraryList、LinkedList和Vector
Set: hashSet、LinkedSet和TreeSet
Map: HashTable、HashMap、LinkedMap和TreeMap
内存存放特性、数据增长特性和各自的适用场景
遍历Iterator、ListIterator和Foreach
线程安全问题,Tree一类的红黑树概念
了解Collections和Arrays两个辅助工具类的用法
HashMap/ArrayMap/SparseArray三个区别和使用场景
http://blog.csdn.net/u010687392/article/details/47809295
基础数据类型int和Integer的区别
Integer是对象,int的包装类,java是面向对象设计语言,为了使int类型进行对象编程,故设计了Integer包装类,提供其一系列的方法;如特定场景下,网络访问接口,如需要传int类型的身高值,有身高是就传值,没有时就不传,这个时候Integer就到了用武之地;
Integer底层做了缓存优化,缓存了-128到127之间的Integer对象,可以快速进行转换;所以-128和127之间地址是一样的,但是equals方法比较的是int值,而不是地址,这点要注意
SharedPreference
什么是SharedPreference?
适用场景?存储原理、读原理、写原理,线程、进程安全?写入大量数据时如何以及应对办法?
是否会造成ANR?
最后,替代它的产品?
反思|官方也无力回天?Android SharedPreferences的设计与实现
[Google] 再见 SharedPreferences 拥抱 Jetpack DataStore
SP设计针对轻量级的配置xml文件中,读操作会与文件IO操作,然后缓存到内存Map中,之后就会从这个缓存Map读取出来!
写操作,在SharedEditor中还会缓存一个Map,先写入这个Map;当调用commit时才会写入到文件系统中,写入之前会备份一份xml.bak,防止写入过程中崩溃,commit方法只会在主线程进行,为了防止写入量过大,开发了apply异步操作;这两个Map同步更新也是在apply和commit时会进行同步更新
线程问题:
使用了3把锁,读Map使用一把锁
editor写操作在使用一把锁;进行同步写入时会在用一把锁
进程之前访问需要自己使用文件锁来保证安全
SP引发的ANR问题?
虽然apply子线程去执行,但是仍然会有可能引发ANR现象,其原因在于apply任务最重会交给QueueWork或者HandlerThread去执行,其会先创建一把锁,执行完在释放锁;而Activity的onStop方法会等待所有的锁释放才会继续执行;所以当频繁调用Apply时会有可能导致ANR
MMKV
什么是protocolbuf、MMKV,以及他们背后的原理?
如何使用他们,以及他们的优势?
Protobuf的简单介绍、使用和分析
详解通信数据协议ProtoBuf
MMKV 组件现在开源了
android注解
辅助完成代码工作,优化代码;一个注解主要有两点构成:
注解运行时机: source、class、run;source在java文件有效,class在java和class有效,run在运行时和java、class有效
作用对象: Filed、Param、Method等
还有一个就是注解解释器,主要是通过发射获取类实例,反射获取类下的所有成员,依次查看每个成员的注解,拿到成员注解里面的值,然后把值设置到变量或者调用方法等
以下是个demo,为view设置id,仅仅有关键代码:
/**
定义注解
**/
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface ByID{
int id;
}
/**
注解解释器
**/
public void parse(Activity target){
Class<?> my = target.getClass();
Fileds[] filed = my.getDeclaredFields();
//便利所有成员
for(Fileds f : filed){
Annotation[] annotations = field.getAnnotations();
for(Annotation n : annotations){
if(n instanceof ByID){
ById b = f.getAnnotation(ById.class);
View view = target.findVIewById(b.id);
f.set(target, view);
}
}
}
}
/**
Activity使用
**/
public class Activity{
}
更多参考:https://www.jianshu.com/p/edfc0780a112
clone拷贝
- java中如何实现clone()拷贝,完成拷贝时他的内存是如何分配的?
- 什么是浅拷贝,什么是深拷贝,如何实现深拷贝?
参考:http://blog.csdn.net/zhangjg_blog/article/details/18369201
实现拷贝clone实现cloneable接口,并重写clone方法,为其配置public属性;这样只能进行浅拷贝,基础类型拷贝,引用对象直接拿的是引用;要想引用对象也拷贝,则引用对象也要实现cloneable接口才行
Parcel和Serializable序列化
什么是序列化?为了永久性的保存对象,或者进程中和网络中传输,实现序列化和反序列化,无需关注实现细节,从而保证对象的存储和传输
android中建议使用Parcel实现序列化,效率比Serializable高,因为Serializable会产生大量的临时变量,频繁GC;
OkHttp
多线程
线程用法
Thread、Runnable和Callable,以及各自的特点
线程的几个状态
创建、就绪、运行、阻塞、停止
线程池
为什么要使用线程池?
- 线程池常见的几个类的用法:
ThreadPoolExecutor、Executor,Executors,ExecutorService,CompletionService,Future,Callable 等 - 线程池四个分类
newCachedThreadPool、newFixedThreadPool、newScheduledThreadPool和SingleThreadExecutor - 自定义线程池 ThreadPoolExecutor
线程池工作原理
核心线程数、等待队列、处理策略等
线程同步
同步方式:synchronized和lock
同步相关方法:wait()/notify()/notifyAll() sleep()/join()/yield() await()/signal()/signalAll
如何使用,各自适用场景?
参考:http://wiki.jikexueyuan.com/project/java-concurrency/executor.html
线程锁问题
- 一般lock和unlock是配对使用,有些情况,在lock和unlock代码块之间有一个return,我们忘记在中间return前方unlock也会照成死锁,别的线程无法拿到锁
设计模式
面向对象设计六大原则
优化代码的第一步——单一职责原则
让程序更稳定、更灵活——开闭原则
构建扩展性更好的系统——里氏替换原则
让项目拥有变化的能力——依赖倒置原则
系统有更高的灵活性——接口隔离原则
更好的可扩展性——迪米特原则
参考:http://blog.csdn.net/bboyfeiyu/article/details/50103471
android适配问题
不同系统版本之前的适配 – API变化
比如9.0提供了新的API – Application下的getProcessName()
对于低于9.0的机型是没有这个API的,如果不适配
不同手机厂商之间的适配 – 对Android原生系统进行了改造
屏幕适配 – 尺寸单文(dp/sp/px)、布局layout和图片资源
dp设计出来是表示不同手机上相同长度的尺寸,但是像素密度dpi不同的手机,dp也不同
dp = (dpi/160)px
dpi为160时 1dp = 1px dpi为320时 1dp = 2px
适配1:
宽高限定符,创建不同尺寸的values文件,配置不同dimes的长度单位
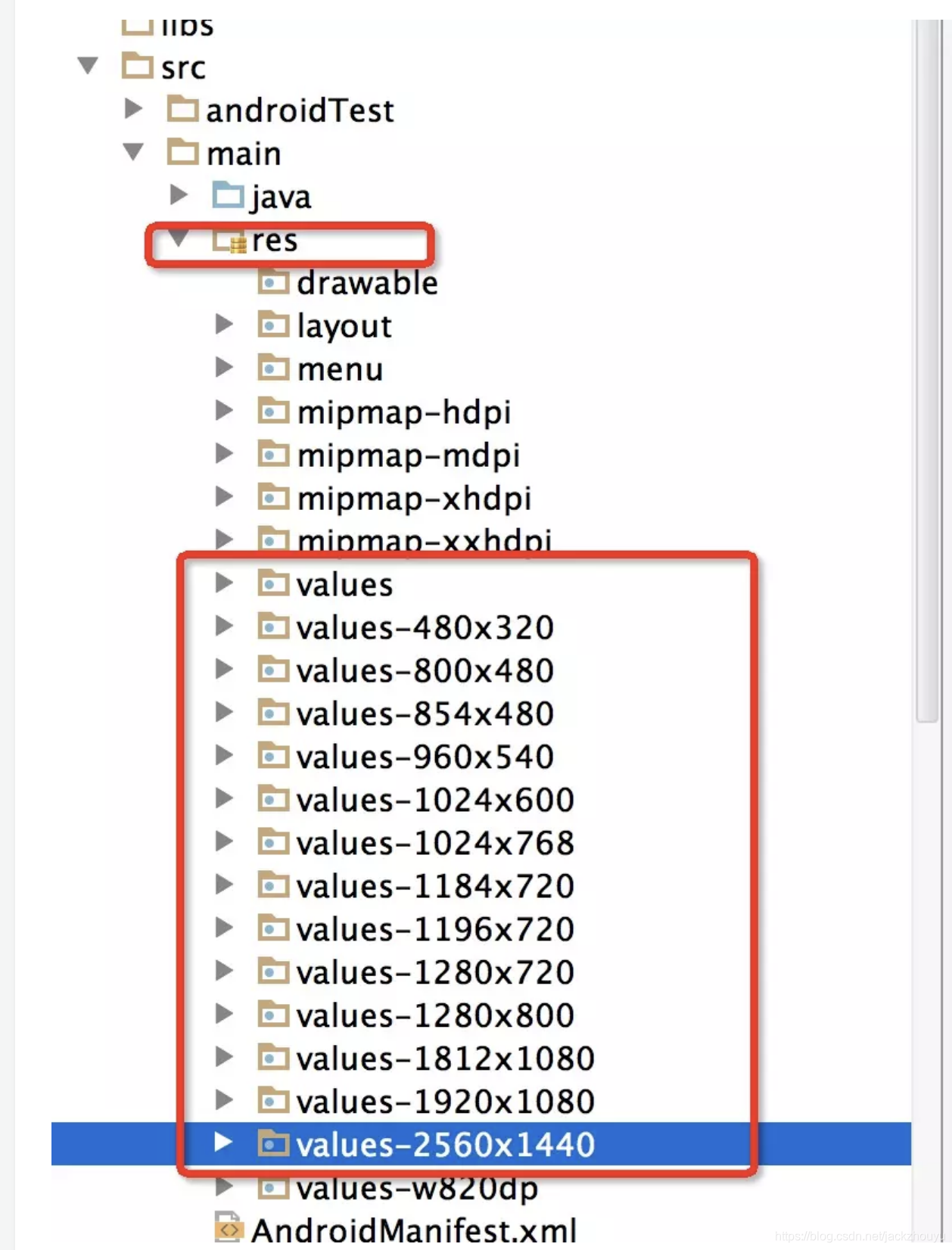
缺点:手机多 适配麻烦,如果找不到对应尺寸配置,使用默认的配置相差会极大
屏幕适配方案2:smallestWidth方案
假如一个手机dpi是480,宽度是1080px,那么1dp = 3px那么宽度就是360dp,于此同时我们在values创建不同尺寸的文件(如下图),App运行时,系统会自动去选择与之尺寸相近的一个文件夹value,我们在value中配置好基础的尺寸;假设UI设计稿为375个像素,就把360分为375,那么一个UI设计稿中一个px就等于0.96dp,我们只需要在value文件中配置不同尺寸即可
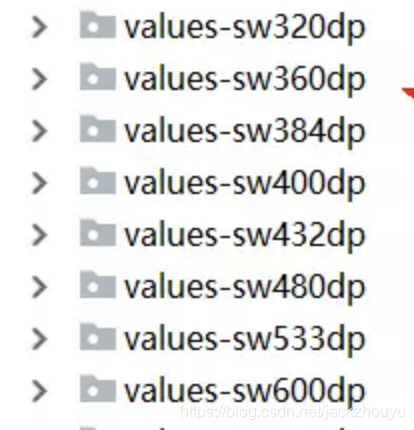
效果好,缺点就是会使apk体积变大,适配很多屏幕情况下
头条适配:
我们知px = dp(dpi/160),默认density = dpi/160,而头条将density改为以下,
denstiy = 手机宽度px / 设计稿dp;我们在view的宽高正常使用dp单位,在通过官方api重新设置density,这样就形成了等比例关系 手机宽度px/设计稿UI = view最终宽度px/view我们设置的dp;我们在xml中设置的是dp,但是系统最终都转到px,px = density * dp,这步是由系统做的
AndroidManifest中设置好设计稿尺寸,计算出density,
private static void adaptScreen(final Activity activity,
final int sizeInPx,
final boolean isVerticalSlide) {
final DisplayMetrics systemDm = Resources.getSystem().getDisplayMetrics();
final DisplayMetrics appDm = Utils.getApp().getResources().getDisplayMetrics();
final DisplayMetrics activityDm = activity.getResources().getDisplayMetrics();
if (isVerticalSlide) {
activityDm.density = activityDm.widthPixels / (float) sizeInPx;
} else {
activityDm.density = activityDm.heightPixels / (float) sizeInPx;
}
activityDm.scaledDensity = activityDm.density * (systemDm.scaledDensity / systemDm.dens
activityDm.densityDpi = (int) (160 * activityDm.density);
appDm.density = activityDm.density;
appDm.scaledDensity = activityDm.scaledDensity;
appDm.densityDpi = activityDm.densityDpi;
}
可参考:http://blog.csdn.net/qq_28758749/article/details/51297842
Handler机制
- 使用方法, send/post两种方式
- handler底层怎么从发送消息到接收消息的
- 理清楚Looper、Handler、MessageQueue和Message概念和关系
- HandlerThread是什么东东,如何使用,和Handler有什么区别呢?
参考:http://blog.csdn.net/jackzhouyu/article/details/49079699
Activity
-
正常执行时,生命周期是何变化?异常时和Activity重新展开时,注意方法的调用时机: onSaveInstance()、onRestoreInstance()、onWindowFocusChanged()和onConfigurationChanged()以及使用方法
-
onStart()和onResume()、 onPause()和onDestroy()这两方法用处都很类似,Android为什么要这么设计呢?
-
Activity的四种启动方式standard、singleTop、singTask和singleInstance是什么?他们onNewIntent()方法的关系,启动Intent的几个标志位FLAG_ACTIVITY_NEW_TASK/FLAG_ACTIVITY_SINGLE_TOP/FLAG_ACTIVITY_CLEAR_TOP
https://blog.csdn.net/vipzjyno1/article/details/25463457
特别注意singleInstance是栈中唯一,而且栈中TaskRecord只有一个就是它,不能存储其他Activity,即使你配置taskAffinity属性为相同的名字,taskRecord的名字相同,id不同,不是同一个
taskAffinity为任务栈亲和属性意向,startActivity时,会根据配置taskAffinity属性查找相近的任务栈TaskRecord,将Activity加入其中,并且启动模式或Flag为singleTask和singleInstance或者flag为NEW_TASK才生效,如果没有指定,会根据packageName创建一个新的TaskRecord来管理这个Activity;如果没有配置属性,默认会加入到启动他的Activity的那个TaskRecord

最后一个为何不同?在于如果Activity没有配置launchMode时,就会销毁包含自己在内以及到栈顶的Activity,在重新new一个,并且不会执行onNewIntent;但是如果配置了SingleTask则就不会销毁自己,直销会他之上的Activity,并且也会调用onNewIntent
参考:
(1) http://blog.csdn.net/woshimalingyi/article/details/50961380
(2) http://blog.csdn.net/jiangwei0910410003/article/details/16968881
(3) http://www.cnblogs.com/lijunamneg/archive/2013/03/26/2982461.html
(4)http://blog.csdn.net/mynameishuangshuai/article/details/51491074
(5)https://developer.android.com/reference/android/content/Intent?hl=zh-cn#FLAG_ACTIVITY_CLEAR_TOP
onNewIntent
当配置启动模式为SingleTask和singleTop时,Activity重新启动时,如果Activity刚好在栈顶,则会依次调用onNewIntent -> onResume;如果不在栈顶,则会onNewIntent -> onRestart -> onStart -> onResume;注意的是,如果Activity异常退出时,记得要在OnNewIntent方法中调用setIntent(intent),这样重建后的Activity通过getIntent才是最新的Intent
onConfigchanged
onConfigChanged用于Activity横竖屏切换时调用,但是要在Activity配置android:configChanges=“orientation|screenSize|keyboardHidden”,这样activity切换后生命周期不用所有方法都重走一次,而只是调用onConfigChanged方法;不配置时切屏会重新调用各个生命周期,切横屏时会执行一次,切竖屏时会执行两次
Fragment
1. 什么是fragment?为什么要使用fragment?
需要对比Activity才能更好的作出解答
2. fragment的生命周期,并且和Activity的联系?
3. fragmentManger和FragmentTransaction两者用法,它的replace/add/remove/hide/show方法,以及添加到回退站和回退的用法
4. fragment和Activity的通信,以及何种方案保证降低他们的耦合性
以及fragment上踩过的一些坑
a. 嵌套fragment时Duplicated id或者Tag
b. replace之痛
c. Fragment的public默认无参数构造方法
原因:Fragment会被重新销毁(Activity销毁的时候它里面的Fragment就被销毁了,可能因为内存不足,手机配置发生变化,横竖屏切换)。在重新创建的时候系统调用的是无参构造函数。
d. getActivity()为空指针
讲解:http://blog.csdn.net/goodlixueyong/article/details/48715661
f. frgament和viewpager配合使用,生命周期影响几何,fragment如何感知自己已经处于显示状态,并且与Activity通信
http://blog.csdn.net/tongcpp/article/details/41978751
参考:
(1)http://toughcoder.net/blog/2015/04/30/android-fragment-the-bad-parts/
(2)http://blog.csdn.net/lmj623565791/article/details/37970961
Service
1. 生命周期及两种启动方式
2. Service的线程关系和Thread,它属于哪个线程和进程
3. Service和IntentService的区别
参考:
http://blog.csdn.net/xiao__gui/article/details/11579087
http://blog.csdn.net/huutu/article/details/40357481
HandlerThread、ServiceThread以及IntentService
HandlerThread继承Thread,你可以理解为子线程的Handler,需要自己prepare、loop等操作
ServiceThread继承于HandlerThread,可以从写其run方法
IntentService继承于Service,其内部还是利用了HandlerThread的原理,在子线程执行onHandleIntent方法,可以多次调用startService(Intent)来执行任务,并且执行完成后自动调用stopSelf来结束Service,主要原理就是这个Handler:
private final class ServiceHandler extends Handler {
looper参数来源于子线程的HandlerThread,所以可以在子线程执行
public ServiceHandler(Looper looper) {
super(looper);
}
@Override
public void handleMessage(Message msg) {
onHandleIntent((Intent)msg.obj);
执行完成后,自动执行stopSelf结束Service
stopSelf(msg.arg1);
}
}
为什么onHandleIntent能执行多次?stopSelf明明每次onHandleIntent完后就执行了?
stopSelf大致是这样一个逻辑,传入的msg.arg1是从startCommand传入的startId,标记了每次事件的起始id,最后通过binder通信,调用到服务端ActivityManagerService.stopServiceToken — >> ActivityServicess.stopServiceTokenLocaked()方法如下:
boolean stopServiceTokenLocked(ComponentName className, IBinder token,
int startId) {
.....
ServiceRecord r = findServiceLocked(className, token, UserHandle.getCallingUserId());
if (r != null) {
if (startId >= 0) {
// Asked to only stop if done with all work. Note that
// to avoid leaks, we will take this as dropping all
// start items up to and including this one.
ServiceRecord.StartItem si = r.findDeliveredStart(startId, false);
记录的最后一个事件id不为传入进来的id,则说明事件还未处理完们不能停止
if (r.getLastStartId() != startId) {
return false;
}
.....
}
}
IntentService另一个要点
public int onStartCommand(@Nullable Intent intent, int flags, int startId) {
onStart(intent, startId);
START_REDELIVER_INTENT表示因异常而导致Service死掉的,重启后会发送最后一个Intent进行处理
START_NOT_STICKY则异常死掉又重启不处理任何Intent
return mRedelivery ? START_REDELIVER_INTENT : START_NOT_STICKY;
}
图片压缩
质量压缩
采样率压缩
尺寸压缩
jni第三方库来压缩
svg webpg
Glide图片缓存机制
弱引用(hashmap)、LRUCache、DiskCache和网络下载
存储的关键字key来识别存储对象,key由许多参数组成:图片的地址、宽高等因素;
当我们需要图片时,会根据其宽高和地址信息生成一个key
- 首先去弱引用hashMap里面找,找到了我们就拿出来使用,并且当前图片计数器要加1
- 找不到情况下,或者弱引用中图片被回收,我们就去LRUCache中找
- LRUCache是用linkedhashmap加双链表结构体存储,其存储的图片也是弱引用,根据key找到图片,同时会在LRU中删除这张图片,把图片加入到弱引用中,找到图片后使用也会对图片计数器加一;找不到就去Disk和网络中去找
- 使用完图片后会对图片计数器减一,当计数器为0时,会将弱应用的图片清楚掉放回到LRU里面去
GlideBitmapPool
对于一些使用图片交大的App,需要频繁的分配/释放图片资源,大量的操作会引起频繁GC,造成应用内存抖动应用不稳定等现象;使用GlideBitmapPool可以将不再使用的图片bitmap资源保存起来,需要时在拿出来使用,这样就不会造成频繁GC,申请资源了;
inBitmap属性
4.4之前的版本inBitmap只能够重用相同大小的Bitmap内存区域。简单而言,被重用的Bitmap需要与新的Bitmap规格完全一致,否则不能重用。
4.4之后的版本系统不再限制旧Bitmap与新Bitmap的大小,只要保证旧Bitmap的大小是大于等于新Bitmap大小即可。
此框架就应用了这一特效,当Bitmap图片使用完后,不会recycle释放,将它进行保存;当需要使用图片分配内存时,如果图片尺寸大小小于旧图片的大小,就可以拿出来复用,其内部使用了LRU算法来保存bitmap资源,hashmap+双链表,LRU算法
现在Glide内部也是用了这个特性
广播
有序广播、粘性广播、系统广播
https://www.jianshu.com/p/ca3d87a4cdf3
android组件化与插件化????
android事件分发机制
1. Activity里面的组件发生点击事件时,事件是如何传递的?
2. view和viewgroup事件分发区别,理解dispatchTouchEvent()、onInterceptTouchEvent、onTouchEvent、onTouch和onClick事件
public boolean dispatchTouchEvent(MotionEvent ev)
用来进行事件的分发。如果事件能够传递到当前View,此方法一定会被调用,返回结果受当前__View的onTouchEvent()和下级View的diapatchTouchEvent()方法__的影响,表示__是否消耗当前事件
__。
public boolean onInterceptTouchEvent(MotionEvent event)
用来判断是否拦截某个事件,如果当前View拦截了某个事件,那么在同一个事件序列当中,此方法不会被再次调用,返回结果表示是否拦截当前事件。
public boolean onTouchEvent(MotionEvent event)
在dispatchTouchEvent()中调用,用来处理点击事件,返回结果表示是否消耗当前事件,如果不消耗,则在同一个事件序列中,当前View无法再次接收事件
当子view的action_down事件不处理后,后续事件序列将不再传递给他
当子view除action_down外的事件不处理后,虽然后续事件也会收到,但是它的父组件却无法处理
requestDisallowInterceptTouchEvent,onInterceptTouchEvent两个方法
参考:
https://segmentfault.com/a/1190000005268399
ListView和RecycleView区别
从功能上:
ListView用于轻量级,简单布局的页面展示;adapter的notifyDataSetChanged需要把所有item都刷新
RecycleView可以支持复杂布局,横竖方向滑动,线性、表格、瀑布流布局,就是比ListView多设置一个LayoutManager布局管理器;而adapter可以只刷新需要更新的item
从缓存上:
ListView支持2级缓存,这2两级缓存用于快速显示屏幕上的item,离屏外的item产生的convertview还需要自己复用
recycleView支持4级缓存,并且支持缓存离屏外的2个item,自己已经处理convertView复用的问题
缓存对比:
ListView缓存的是View,RecycleView缓存的是VIewHolder,对缓存的使用原理大致都是,item离屏时将视图item缓存好,新的item入屏时,在从缓存中取出视图进行复用
| ListView | 缓存的View | |
|---|---|---|
| mActiveViews | 缓存屏幕内显示的item,快速复用 | 不需要createView和bindView |
| mScrapView | 缓存屏幕外的item视图 | 不需要createView,但是需要bindView,自己对convertView进行复用 |
private View[] mActiveViews = new View[0]; //数组
private int mViewTypeCount;
private ArrayList<View>[] mScrapViews; //数组,其内部是ArrayList
mActiveViews好理解,屏幕内部快速复用;当有新的item进入屏幕时,会从mScrapViews拿出缓存的view,调用bindView由开发人员自己复用处理
| RecyclerView | 缓存的是ViewHolder | |
|---|---|---|
| mScrapView | 主要包含mAttchScrap和changedScrap,缓存屏幕内的item,快速复用 | 不需要creatView和bindview |
| mCachedViews | 缓存屏幕外部item,默认缓存2个,可以根据position和type查找到 | 不需要creatView和bindview |
| mViewExtension | 用于自定义扩展的视图缓存 | |
| recyclePool | pool内部Map以type为key,存放ViewHolder的集合,每个holder上限是5个 | 不需要createView,但是需要bindview |
mScrapView和ListView的mActiveViews一样,当有item滑出屏幕时,会将离屏的第一个viewholder根据position缓存到mCachedViews,默认是2个,遵循先进先出规则,如果mCachedViews已经有两个了,则会把最先进入的缓存ViewHolder移动至recyclePool,这里recyclePool会重置viewHolder,所以再次复用时需要onBind,这个默认是每个type类型的存5个
使用
仅仅做一些数据展示,不需要复杂的交互建议使用ListView,数据显示量大且交互逻辑处理,频繁更新建议使用RecycleView,局部通知notify等,布局灵活
ViewStub懒加载
只需要在xml里面设置ViewStub标签,传入layout子布局,加载时ViewStub就不会暂时加载出来,而当viewstub调用了inflate或者setVisible后才加载出来的,inflate只能掉一次,而setVisible可以调用多次;那这个原理是什么呢?
因为ViewStub这个组建继承于View,在初始化时设置了自己visible为gone,并且也没有将子布局加载进来;当调用inflate后(setVisible内部也是掉inflate),才会把子layout通过inflate进入,她会先用父布局将自己移除掉,在把子布局用来顶替自己的位置,并且使用自己的layoutParam参数,见如下代码
public View inflate() {
final ViewParent viewParent = getParent();
final ViewGroup parent = (ViewGroup) viewParent;
final View view = inflateViewNoAdd(parent);
replaceSelfWithView(view, parent);
mInflatedViewRef = new WeakReference<>(view);
if (mInflateListener != null) {
mInflateListener.onInflate(this, view);
}
return view;
}
private View inflateViewNoAdd(ViewGroup parent) {
final LayoutInflater factory;
if (mInflater != null) {
factory = mInflater;
} else {
factory = LayoutInflater.from(mContext);
}
final View view = factory.inflate(mLayoutResource, parent, false);
if (mInflatedId != NO_ID) {
view.setId(mInflatedId);
}
return view;
}
private void replaceSelfWithView(View view, ViewGroup parent) {
final int index = parent.indexOfChild(this);
parent.removeViewInLayout(this);
final ViewGroup.LayoutParams layoutParams = getLayoutParams();
if (layoutParams != null) {
parent.addView(view, index, layoutParams);
} else {
parent.addView(view, index);
}
}
jni如何向java抛异常
在android的JNIHelp.h文件中声明四种可以向JVM抛异常的函数:
int jniThrowException(JNIEnv* env, const char* className,const char* msg)
int jniThrowNullPointerException(JNIEnv* env, char* msg)
int jniThrowIOException(JNIEnv* env, int errnum)
int jniThrowRuntimeException(JNIEnv* env, const char* msg)
jni调用java class
jclass jclass1 = env->FindClass(“com/test/myjnitest/Person”);
jmethodID jageMethodId = env->GetMethodID(jclass1, “getAge”, “()I”);
//jobj通过jni传递进来
jint jageM = env->CallIntMethod(jobj, jageMethodId)
requestLayout和invalidate区别
requestlayout:一般来说会触发onMeasure和onLayout重新调用,但是有时候也会触发onDraw,可能原因是在onLayout时发现参数l,t,r,b和以前不一样了,他就会自己触发invalidate
invalidate:只会触发onDraw方法;
所以根据需求,只需要重新onMeasure和onLayout是就调用Requestlayout;需要onDraw时则调用invalidate;如果需要重新绘制,则依次两个都调用
精通网络通信机制;
对TCP、HTTP协议有丰富实践经验;
熟悉HTML、CSS、JS等web基础知识,独立或主导完成过大中型移动app经验者优先;
深入研究过android系统机制和framework源码,精通android上的app开发、调试、编译、打包等流程;
有技术难题攻关经验,在移动端app内存优化、绘制效率优化、IO优化或数据库、电量等调优方面有丰富的经验。

蓝牙
Android蓝牙方面开发,包括经典蓝牙、BLE蓝牙以及蓝牙协议HFP、A2DP、 AVRCP等协议
点击参考
面试问题准备
- app之间通信有哪些方式
- 给你一个app设计项目,你应该怎么去搭建框架,如何去设计这个app
- Android加载大图问题解决办法1
- Android加载大图问题解决办法2
干货资源
浏览器输入地址干了哪些事情?
音视频
-
什么是SPS和PPS?
Squence Paramters Set序列参数集
Picture Paramters Set图像参数集
他们位于H264协议帧的NAL单元,每帧数据通常用3字节或者4字节的01作为分隔符,分隔符紧挨着后一个字节的低4bit为7时表明这是一个SPS数据帧,为8表示PPS数据帧
SPS数据帧:存放了图像编码的一些全局参数,图像解码时会用到
PPS数据帧:存放了一些描述图像的信息
通常以上两个位于H264的第一帧和第二帧数据,紧挨着就是一个I帧 -
什么是NAL?
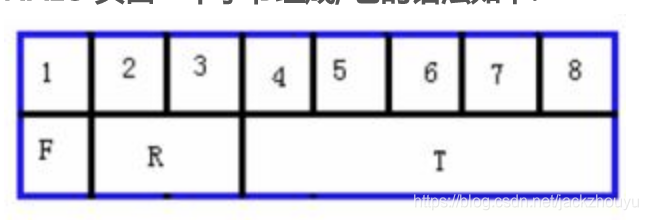
H264协议大致可以分为数据编码从VCL和网络抽象部分NAL,前者主要包含图像编码数据,后者主要是一些控制信息,NAL通常由一定的格式组成:
NALU由一个字节组成:
![在这里插入图片描述]()
NAL单元按RTP序列号按序传送。其中,T为负荷数据类型,占5bit;R为重要性指示位,占2个bit;最后的F为禁止位,占1bit。具体如下:
(1)NALU类型位
可以表示NALU的32种不同类型特征,类型1~12是H.264定义的,类型24~31是用于H.264以外的,RTP负荷规范使用这其中的一些值来定义包聚合和分裂,其他值为H.264保留。
(2)重要性指示位
用于在重构过程中标记一个NAL单元的重要性,值越大,越重要。值为0表示这个NAL单元没有用于预测,因此可被解码器抛弃而不会有错误扩散;值高于0表示此NAL单元要用于无漂移重构,且值越高,对此NAL单元丢失的影响越大。
(3)禁止位
编码中默认值为0,当网络识别此单元中存在比特错误时,可将其设为1,以便接收方丢掉该单元,主要 用于适应不同种类的网络环境(比如有线无线相结合的环境)。
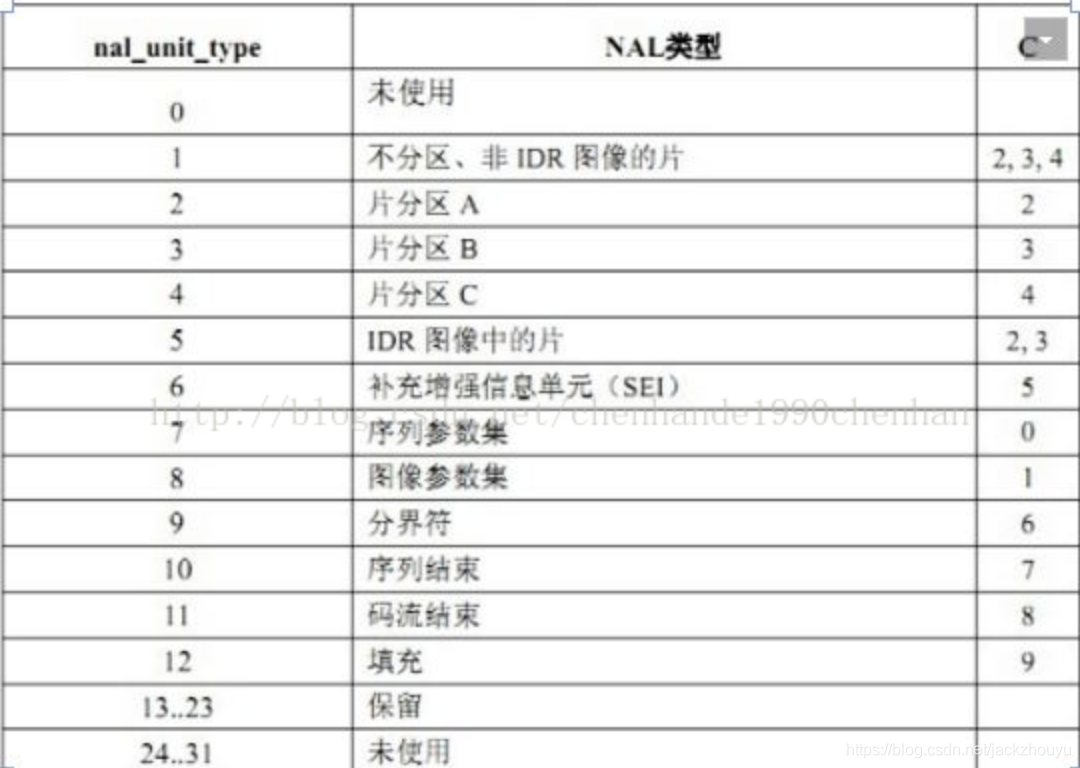
NALU类型是我们判断帧类型的利器,从官方文档中得出如下图:
![https://juejin.im/entry/578d938079bc44005ff26aec]()
音视频面试集合
3、H264内部是如何编码的?
4、有几种媒体封装格式?
TS、AVI、MKV、TP、MOV、M2T,mp4, flv, 等等吧。我看电影少,对音视频格式认识的少,但是该背还得背。
5、MP4的内部结构?
内容好多呀,自行搜索,然后去背诵吧。我是没有背诵下来,但是重点的结构还是要说出来的。
6、编解码流程?
采集到的流,需要进行解码,格式转换,再编码,再封装等,一系列流程。
MP4封装格式简单介绍:
首先MP4由许多box结构组成,box结构又可以嵌套子box,这样众多的box树就构成了MP4文件;
box结构由header头和box的数据组成;
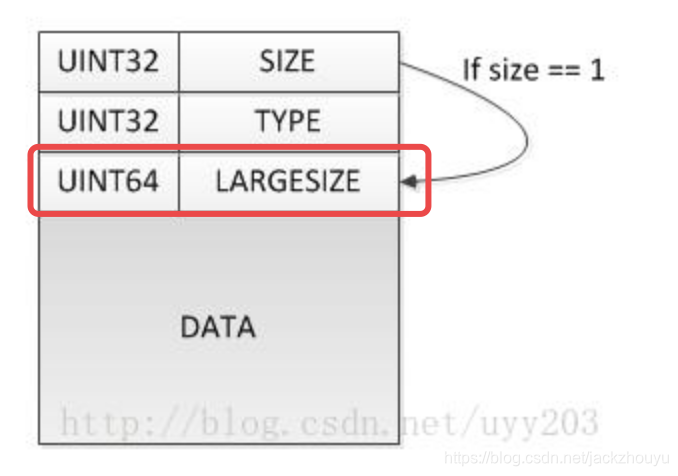
box基本数据格式
[4字节size][4字节type][可省略8字节largeSize][数据内容data]
4字节size包含了header加data的总大小,当总大小超过4字节显示时,size=1,添加8字节的largeSize来表示其总大小;
type标明此box名称,一般用ascll码表示;
以上会普通的box格式,另一种full box格式,在largeSize后data之前还有4字节的version和4字节的flag
MP4文件box顶层描述
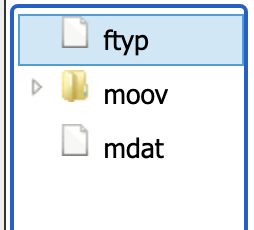
从顶层来看,只有三个box,ftyp、moov和mdat
-
ftyp
一个文件只有一个ftyp box,用于描述文件的信息、编码类型、兼容类型等信息;ftyp的data部分通常包含4字节major brand、4字节minor version和4字节的compatible brand;因为不同厂商mp4封装可能不同,以上可以标明此文件指出的主流MP4版本(v1或v2),兼容信息等 -
moov
该box包含音视频的基本信息,不包含音视频媒体本身数据;moov下面有很多子box,描述音视频的宽高、时间戳、解码器信息以及chunk在文件中的偏移,利用moov中的信息可以快速定位每帧在mdat中的位置 -
mdat
音视频媒体信息
moov box
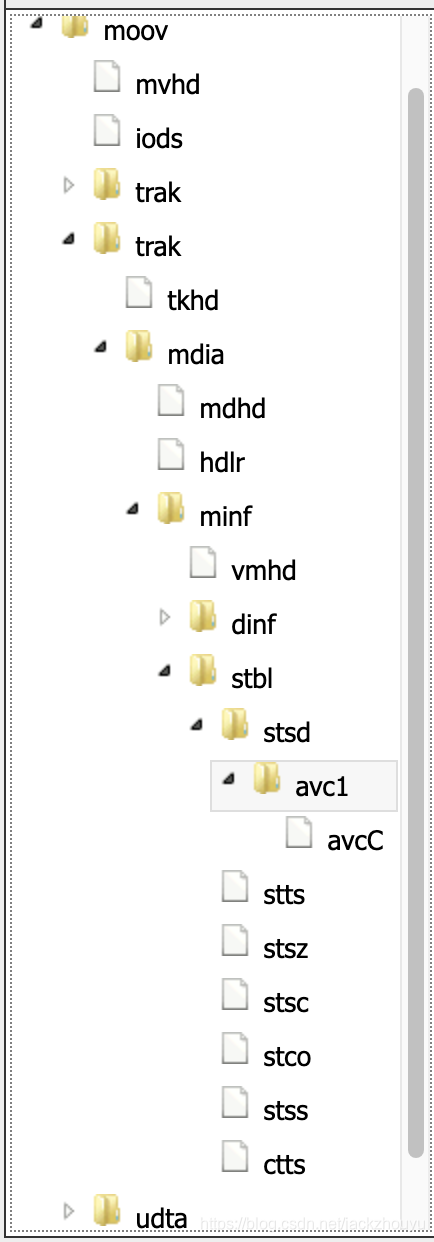
moov box下面大致是这样的结构模式;
-
一个固定的mvhd,也就是moov的header头
包含创建时间、时间粒度time_scale以及文件持续时间duration;此时间粒度1/ time_scale * trak中的tkhd的duration可以得到每个trak的真实时间 -
两个或者更多trak
对应音频或视频trak,包含音视频序列的媒体信息;trak下的tkhd是trak的header,包含创建时间、持续duration、宽高信息和音量等信息 -
mdia box
媒体box信息,其中mdhd为媒体头,包含媒体创建时间、时长、时基等信息,hdlr则可以用于区分这个trak是音频、视频还是其他trak,其中hdlr的handler可以取值vide、soun和hint等 -
stbl box
位于mdia box -> minf box -> stbl box很重要,它描述了每个chunk的sample信息、偏移信息,以及关键字信息等;![在这里插入图片描述]()
补充stsd描述信息包含解码器信息,它尤为重要;其他如上图;解释几个专有名词:
sample:采样,一帧或几帧图像采样数据,音视频采样数据
chunk:一个或多个sample
trak:包含多个chunk
因为mdat存放的媒体数据没有特定的格式,而st开头的这些数据就是描述具体的每个Sample以及每帧数据在mdat中的位置,所以理解stxx很重要
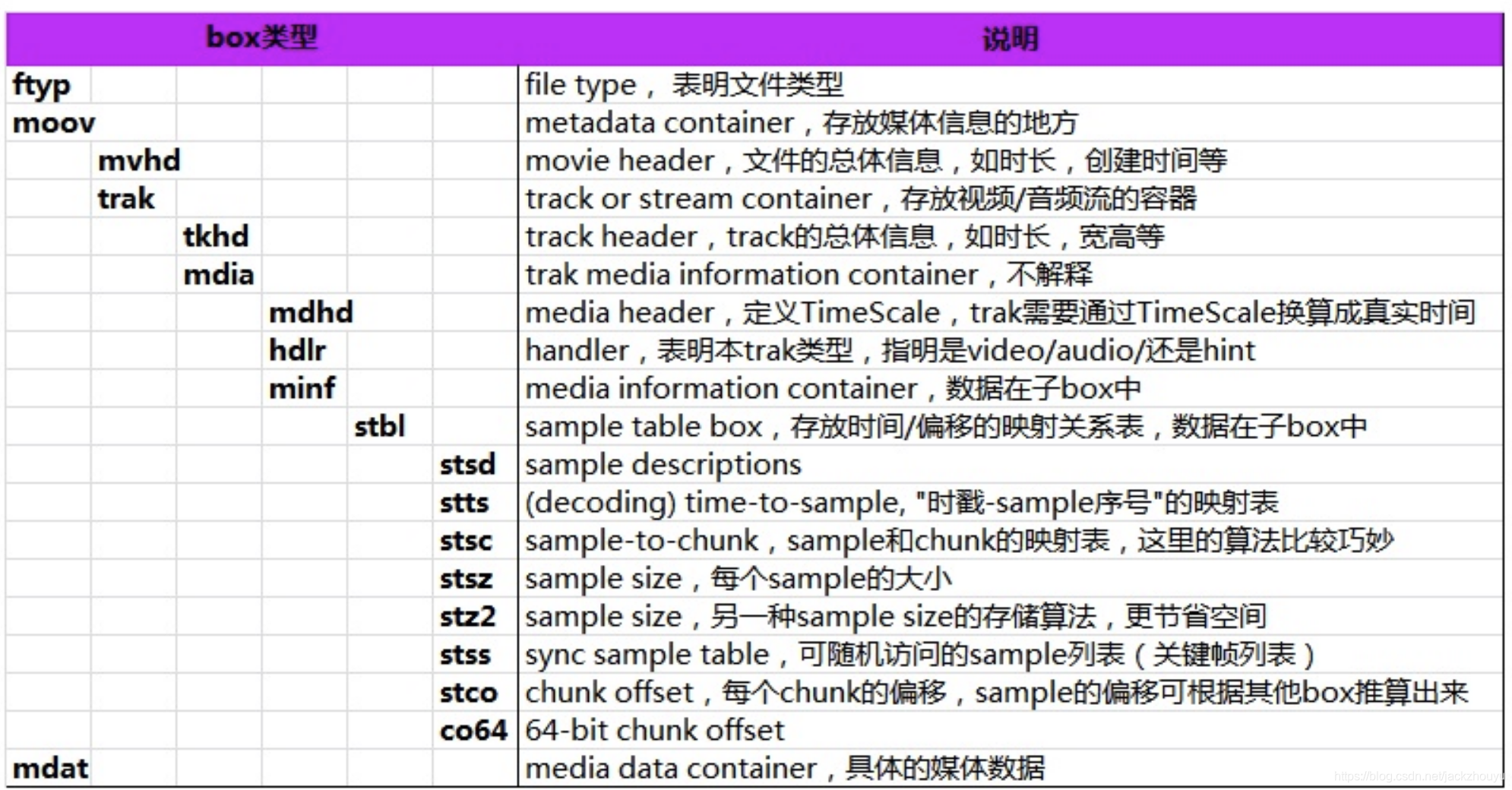
通过stxx获取每帧数据
通过stsc获取sample和chunk的映射关系;

first_chunk表示chunk的序号,sample_per_chunk表示每个chunk有多少个sample,最后一个sample_description_index对应stsd的描述信息;
寻找chunk和sample对应关系
上图表示:第1~12个chunk,每个chunk有29个sample采用,这些采样的描述信息位于stsd里面的index为1的描述;第13个chunk有4个sample,描述也是1的stsd
确定chunk在文件中的偏移
然后我们在stco或者co64去找,如下图:

stts确定每个sample时间戳和持续时长
从上面stsc中可以得到总的sample个数等于12*29 + 4=352个sample,并且其序号默认是递增的从0~351个;如何确定每个sample的时间戳以及时间持续,可以从stts来看,如下图:

sample_counts表示多少个sample,计算出来一共是352个,下面是时长
每个sample的大小?那就要看stsz

一共352个,就知道每个sample的大小了;1. 前面根据stsc得到每个chunk中包含的sample个数以及对应的描述;2. 然后根据stco得到每个chunk在文件中的偏移位置,3.又根据stsz得到每个sample的size,这样就知道每个采样的在文件中的具体位置和大小了,以及对应的时间戳
还有一个关键帧,怎么得到了?stss就是关键帧信息
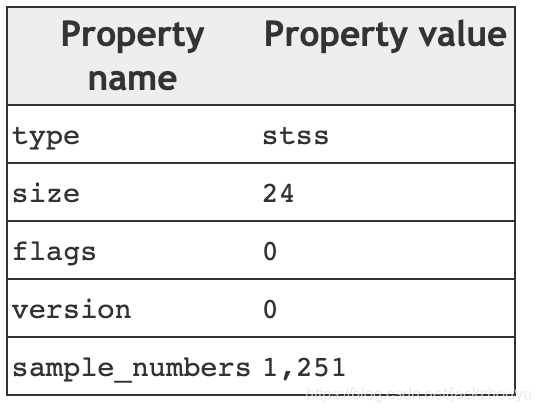
如上图,sample序号为1和251的就是关键帧了,遍历chunk中的sample序号就知道谁是关键帧了
上面截图使用的工具如下:
http://download.tsi.telecom-paristech.fr/gpac/mp4box.js/filereader.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号