爬虫.之登陆及动态网页的抓取
分布式爬虫
Xpath
正则表达式
动态网页
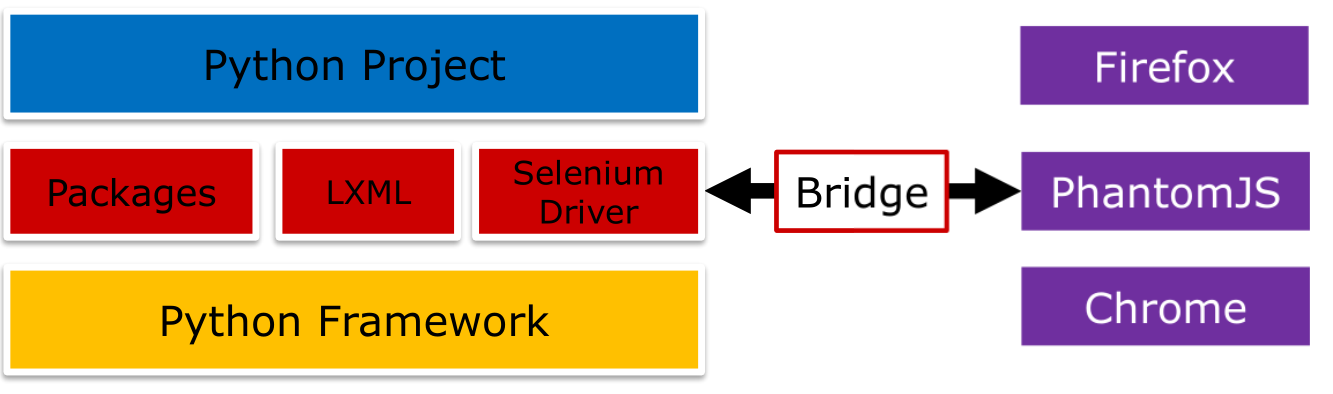
Headless的浏览器:phantomJS
浏览器的驱动:Selenium
1.Xpath
基本语法:
表达式:nodename(节点名) 选取此节点的所有子节点,tag或*选择任意的tag
/ 从根节点选取,选择直接子节点,不包含更小的后代(例如孙、从孙)
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置,包含所有后代
. 选取当前节点
.. 选取当前节点的父节点
@ 选取属性
@属性
在DOM树,以路径的方式查询节点通过@符号选取属性
rel class href (超文本引用)都是属性,可以通过“//*[@class=‘external text’]”来选取对应元素
=符号要求属性完全匹配,可以用contains方法来部分匹配,例如“//*[contains(@class,'external')]”可以匹配,而“//*[@class='external']”则不能
运算符
and和or运算符
选择p或者span或者h1标签的元素
soup=tree.xpath(‘//td[@class=“editor bbsDetailContainer”]//*[self::p or self::span or self::h1]’)
选择class为editor或者tag的元素
soup=tree.xpath(‘//td[@class=“editor”or @class=“tag”]’)
2.正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑
在爬虫解析中,经常会将正则表达式与Dom选择器结合使用。正则表达式适用于字符串特征比较明显的情况,但同样的正则表达可能在HTML源码里多次出现:而Dom选择器可以通过class
以及id来精确找到DOM块,从而缩小查找的范围。
爬虫常用的正则规则
获取标签下的文本 ‘<th[^>]*>(.*?)</th>’
查找特定类型的链接,例如/wiki/不包含Category目录:‘<a href="/wiki/(?!Category:)[^/>]*>(.*?)<’
查找商品外链,例如jd的商品外链为7位数字的a标签节点: ‘^d{7}.html’
查找淘宝的商品信息,‘或者’开始及结尾 ‘href=[\"\’]{1}(//detail.taobao.com/item.htm[^>\"\'\s]+?)"'
3.贪婪模式与非贪婪模式
?该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串
4.动态网页
1.动态网页的使用场景
单页模式
单页模式指的是不需要外部跳转的网页,例如个人设置中心经常就是单页
页面交互多的场景
一部分网页上,有很多的用户交互接口,例如去哪儿的机票选择网页,用户可以反复修改查询的参数
内容及模块丰富的网页
有些网页内容很丰富,一次加载完对服务器压力很大,而且这种方式延时也会很差;用户一般也不会查看所有的内容
2.动态网页带来的挑战
对于爬虫:简单下载HTML已经不行了,必须得有一个web容器来运行HTML的脚本
增加了爬取的时间
增加了计算机的CPU、内存资源的消耗
增加了爬取的不确定性
对于网站:为了配合搜索引擎的爬取,与搜索相关的信息会采用静态方式
与搜索无关的信息,例如商品的价格、评论,仍然会使用动态加载
3.抓取动态网页—分析
打开目标网页后,直接右键点击,只保存HTML
把网页滑动到页面的最下面,然后再次保存,这次选择保存完整网页。
4.分析动态网页—对比
使用BeyondCompare或者SVN等工具,来对比网页,大致找出动态加载部分
针对要提取的部分,分别查看html only与full webpage,找出动态数据的部分
记录下他们的 class或id,
5.Python web引擎
pyQt pyside :基于QT的Python web引擎,需要图形界面的支持,需要安装大量的以来。安装和配置复杂,尤其是安装图形系统,对于服务器来说代价很大
Selenium:一个自动化的web测试工具,可以支持包括Firefox、Chrome、phatomJS、IE等多种浏览器的连接与测试
phantonJS:一个基于webkit的Headless的web引擎,支持JavaScript。相比pyQt等方法,phamtoms可以部署在没有UI服务器上
5.安装
selenium
pip install selenium
phantomJS
phantomJS需要先安装nodejs
#yum install nodejs
为了加速,将NPM的源改为国内的淘宝
$npm install-g cnpm--registry=https://registry.npm.taobao.org
利用NPM的package Manager安装phantomjs
$npm-g istall phantomjs-prebuilt
6.使用phantomJS来加载动态页面
set_window_size
对于动态网页,有可能存在大量数据是根据视图来动态加载的。
phantomJS允许客户端设置来模拟渲染页面的窗口的尺寸,这个尺寸如果设置比较小,我们就不得用JavaScript的scroll命令来模拟页面往下滑动的效果以显示更多
内容,所以我们可以设置一个相对大的窗口高度来渲染。 driver.set_window_size(1280,2400) #optional
7.Built-in DOM selector
Selenium实现了一系列的类似于xpath选择器的方法,使得我们可以直接调用driver.find_element()来进行元素的选择,但是这些都是基于Python的实现,执行效率非常
低,大约是基于C的正则表达式或lxml的10倍时间,因此不建议使用built_in的选择器,而是采用lxml或者re对driver.page_source(html文本)进行操作。
find_element(self,by=‘id’,value=None)
find_element_by_class_name(self,name)
find_element_by_id(self,id_)
find_element_by_css_selector(self,css_selector)
8.Useful Methods & Properties
selenium通过浏览器的驱动,支持大量的HTML及JavaScript的操作,常用的可以包括:
page_source:获取当前的HTML文本
title:HTML的title
current_url:当前网页的url
get_cookie()&get_cookies():获取当前的cookie
delete_cookie()&delete_all_cookie():删除所有的cookie
add_cookie():添加一段cookie
set_page_load_timeout():设置网页超时
execute_script():同步执行一段JavaScript命令
execute_async_script():异步执行JavaScript命令
9.Close and Clear
Selenium通过内嵌的浏览器driver与浏览器进程通信,因此在退出时候必须调用driver.close()及driver.quit()来退出phantomJS,否则phantomJS会一直运行在后台
并占用系统资源。
1.send_signal is recommended
driver.service.process.send_signal(signal.SIGTERM)
2.driver.close()this is not guaranteed to close phantonJS
3.to assure it's closed,run below command in terminal pgrep phantomjs \ xargs kill
10.提取动态数据
1.加载过程中,根据网络环境的优劣,会存在一些延迟时,因此要尝试多次提取,提取不到不意味着数据不存在或者网络出错
2.动态网页的元素,所使用的id或class经常会不止一个,例如:京东一件商品的“好评率”,class包括了rate和percent-con两种,因此,需要对两种情况都进行尝试,更通用的情况,如果一个元素
不能找到而selenium并没有报网络错误,那么有可能这个元素的class或id有了新的定义,我们需要将找不到的页面及元素信息记录在日志里,使得后续可以分析,找出新的定义并对这一类页面
重新提取信息
11.\and\\
网页内,href后面的链接可以有这样三种:
href=“http//career.taobao.com”
http://是完整URL,直接跳转(经常外链会是绝对路径,比如引用到了wiki、百科的一篇文章)
href=“\\detail.taobao.com\iuslkjsd”
//是协议相关的绝对路径,如果现在是http://xxx则需要在//etail.taobao.com前面加上https:前面的协议也可以是file://ftp://所以这样会比较灵活
herf=“\i\8277375.html”
/是网站的相对路径,需要在前面指明当前url的协议及domain
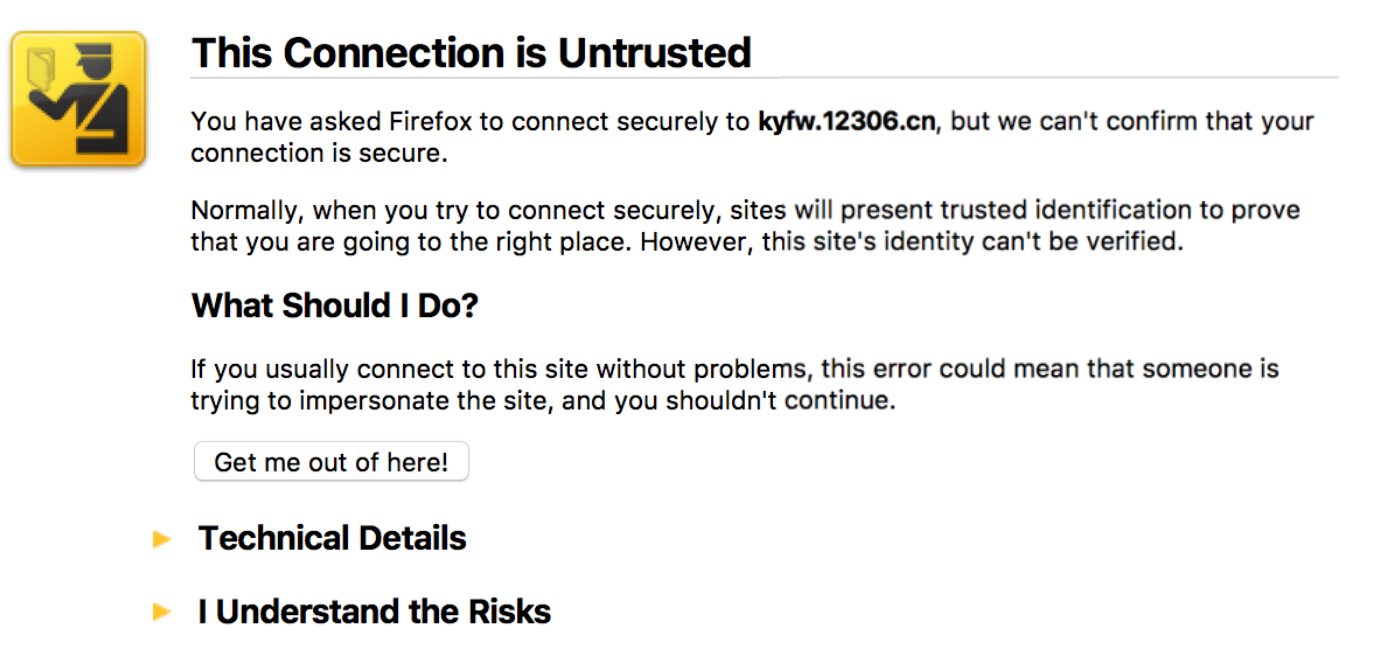
phantomJS配置
重要的配置-ignore-ssl-errors=[true / false]
一些证书没有获得CA授权(多是自己制作的证书),浏览器会报出证书不受信任,这种情况需要用户交互操作(点击继承或者新人),使用这个命令后,能自动忽略此类错误。
重要的配置-load-images=[true / false]
网页上一般都存在大量的图片,这些图片对我们第一次执行抓取是没有用的,在这种情况下,选择-load-images=false可以不下载这些图片,加快下载速度

重要的配置-config=/ path / to /config.json

其它配置:
-disk-cache=[ture/false]
-cookies-file=/ path / to / cookies.txt
-debug-=[ture/false]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号