什么是全文检索
Logstash我们每个人解除互联网都是从互联网搜索开始的,虽然大家常用的搜索引擎可能不同,搜索的关键词也可能不同,但是我们习惯经常在网上搜索的方式来快速学习技术并解决日常工作中所遇到的各种技术问题,如果没有互联网搜索引擎,那么恐怕我们将会有很多的人要失业了。如何在海量的网页信息中准确且快速的找到包含我们所搜索关键字的所有网页并合理的排序展示,这的确是一个很有挑战的问题。
除了我们生活中搜索引擎,大量的互联网应用离不开关键字搜索功能。不能提供关键字搜索功能的互联网应用基本没有生存的可能性。但奇怪的是,很多人从业多年。可能从来没有研究,学习过关键字搜索功能背后的实现技术,却天天将分布式事物这种古老又神秘的术语挂在嘴边。要理解关键字搜索的价值,我们需要先了解关系型数据库索引的极限性。我们在SQL查询语句中使用like "%keyword%" 这种查询条件时,数据库索引是不起作用的。此时,搜索过程就变成了类似于一页一页翻书的遍历过程了,几乎全部是I/O操作,因此对性能的危害是极大的。如果需要对多个关键字进行模糊匹配。比如like ‘%keyword1%’ and like ‘%keyword2%’,此时查询效率也就可想而知了。关键字检索也称为全文检索,本质上是将一系列文本文件内容以“词组(关键字)”为单位进行分析并生成对应的索引记录,索引存储了关键字到文章的映射关系,映射关系中记录了关键字所在的文章编号、出现次数等关键信息,甚至包括了关键词在文章中出现的起始位置,于是我们有机会看到关键字“高亮显示”的查询结果页面。
关键字检索的第一步对整个文档进行分词,得到文本中的每一个词。这对于英文来说毫无困难,因为英文词中的单词之间是通过空格天然分开的,但是中文语句中的字与词是两个概念,所以中文分词就成了一个很大的问题,比如对“北京天安门”如何分词呢?是“北京、天安门”还是“北、京、天安、门”?解决这个问题的最好办法是采用中文词库配合中文分词法,配合开源Lucene使用的比较知名的中文分词有IK(IKAnalyzer)或庖丁(PaodingAnalyzer),直接配置就可以使用了。
2、Lucene
java生态圈里面最有名的全文检索开源项目是Apache Lucene,他已经超过17岁了(2001年成为Apache开源项目),目前Apache官方维护的Lucene相关的开源项目有如下几个。
1.Lucene Core:用java编写的核心类,提供了全文检索功能的API与SDK。
2.solr:基于Lucene Core开发的高性能搜索服务,提供了REST API的高层封装接口。还提供了一个web管理界面。
3.PyLucene:一个Python版的Lucene Core 的高仿实现。
为了对一个文档进行索引,Lucene提供了5个基础类,分别是Document,Field,Index Writer,Analyzer和Directory。
首先,Document用来描述任何待搜索的文档,列如Html页面,电子邮件或者文本文件。我们知道一个文档可能有多个属性。比如一封电子邮件有接收日期。发件人,收件人,主题。内容等属性,每个属性可以用一个Field对象来描述,此外我们也可以把一个Document对象想象成数据库中的一条记录,而每个Field对象就是这条记录的一个字段。
其次,在一个Document能被查询之前,我们需要对文档内容进行分词以找到文档包含的关键字。这部分工作由Analyzer对象来实现的。Analyzer把分词后的内容交给IndexWriter建立索引。IndexWriter是Lucene用来创建索引的(Index)的核心类之一,它的作用是把每个Document对象加入到索引中来。并且把索引对象持久化保存到Directory中,Directory代表Lucene索引的存储位置。目前有两个实现:第一个FSDirectory,表示在文件系统中存储,第二个RAMDirectory,表示在内存系统中存储。
Lucene编程的整个流程如下图所示:
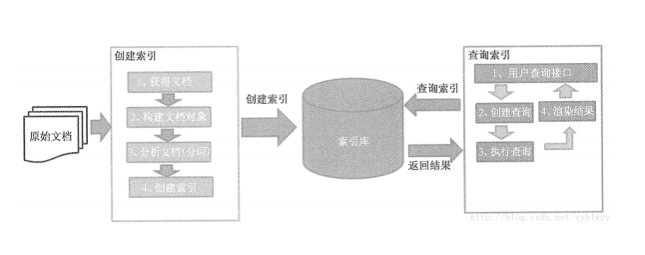
整个流程可以总结为三个独立步骤:
1.建模:根据被索引文档(原始文档)的结构与信息。建模对应的Document对象与相关的Lucene的索引字段(可以有多个索引),这一步类似于数据库建模。关键点之一是确定原始文档中有哪些信息需要作为Field存储到Document对象中。通常文档中的ID或全路径文件名是要保留的(Filed.Store.YES)。以便检索出结果后能让用户查看或下载原始文档。
2.收录:编写一段程序扫描每个待检索的目标文档。将其转换成对应的目标Document对象。并且创建相关的索引。最后存储到Lucene的索引仓库(Directory)中。这一步可以类比为初始化数据步骤(批量数据导入)。
3.检索:使用类似于SQL查询的Lucene API来编写我们的全文检索条件,从Lucene的索引仓库中查询符合条件的Document并且输出给用户。这一步瓦全类似于SQL查询。
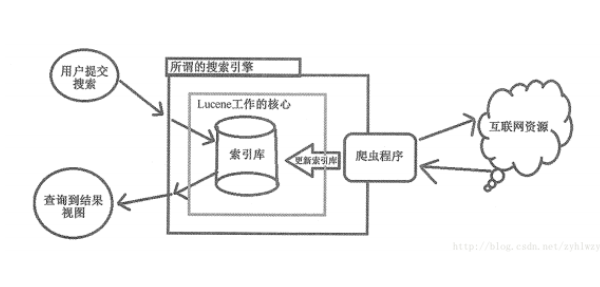
Lucene还普遍与网络爬虫技术相结合,提供基于互联网资源的全文检索的功能,比如不少提供商品比较和最优购物的信息网站通过爬虫去抓起各个电商平台上的商品信息并录入到Lucene库里。然后提供用户检索服务。如下图所示为此类型系统的一个典型的架构图。
3、Solr
如果我们把Lucene与Mysql做对比,你会发现Lucene像MySql的某个存储引擎。比如InnoDB或者MyISAM。Lucene只提供了最基本的全文检索相关的API,这不是一个独立中间件。功能也不够丰富。Api比较复杂。不大方便使用。除此之外。Lucene还缺乏一个更为关键性分布式。当我们需要检索的文档数量特别大的时候。必然会遭受到宕机的瓶颈。所以有了后来的solr和ElasticSearch。他们都基于Lucene的功能丰富的分布式全文检索中间件。
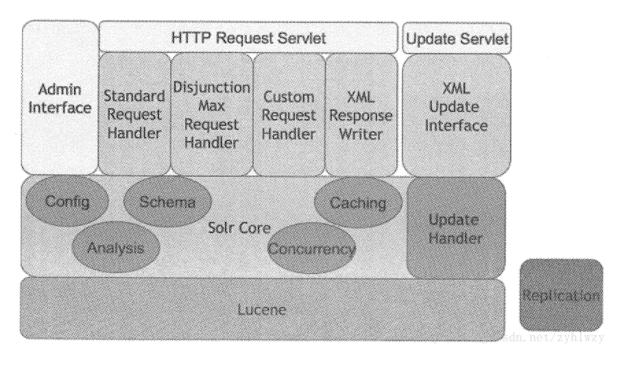
如下图所示为Solr的架构示意图,我们可以看到Solr在Lucene的基础上开发了很多企业级增强功能。
1.提供了一套强大的Data Schema来方便用户定义Document的结构;
2.增加了高效灵活的缓存功能;
3.增加了基于web的管理界面以提供集中的配置管理功能。
4.此外solr索引数据还可以分片存储到多个节点上。并且通过多副本复制的方式来提高系统的可靠性。
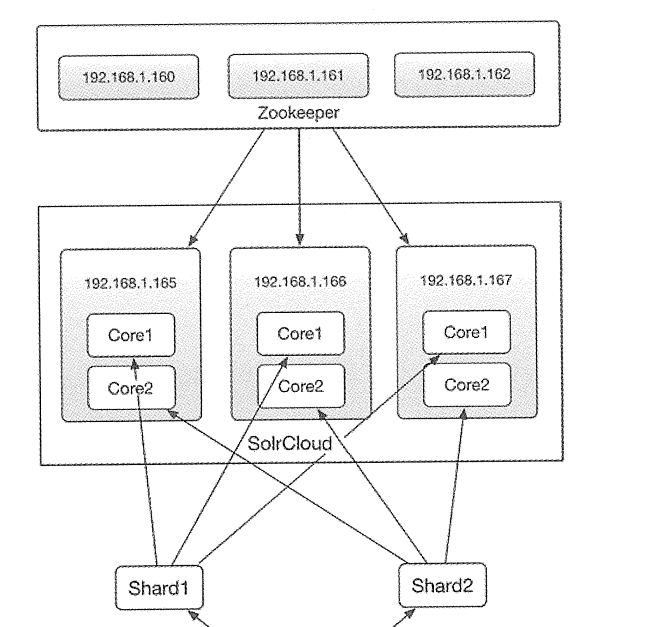
solr的分布式集群模式也被称为SolrCloud,这是一个灵活的分布式索引和检索系统。SolrCloud也是一种去中心化思想的分布式集群,集群中没有特殊的Master节点。而是依靠ZooKeeper来协调集群。SolrCloud中一个索引的数据(Collection)可以被划分成为多个分片(Shard)并存储在不同的节点上(Solr Core或者Core)。在索引数据分片的同时,SolrCloud也可以实现分片的复制。(Replication)功能以提升集群的可用性。SolrCloud集群的所有状态信息都放在ZooKeeper中统一维护,客户端访问SolrCloud集群时,首先要向ZooKeeper查询索引数据(Collection)所在的Core节点的地址列表。然后就可以连接到任意Core节点上来完成索引的所有操作的(CRUD)了。
如下图所示给出了一个SolrCloud参考部署方案。本方案的索引数据(Collection)被分为两个分片,同时每个Shard分片的数据有3份。其中一份所在Core节点被称为Leader,其它两个Core,节点被称为Replica。所有的索引数据分布在8个Core中,他们位于3台独立的服务器上。所以其中一台机器宕机。都不会影响系统的可用性。如果某个服务器在运行中宕机。那么SolrCloud会自动触发Leader的重新选举行为。具体通过ZooKeeper提供的分布式锁功能来实现的。
之前我们说到SolrCloud中的每个Shard分片都是由一个Leader和N个Replica所组成的,而却客户端可以连接到任意一个Core节点上进行索引的数据操作,那么,此时索引数据是如何实现多副本同步的内?下面给出了背后的答案。
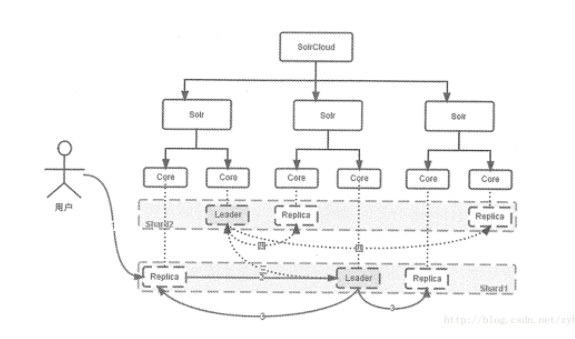
1.如果客户端连接的Core不是Leader,此时节点会把请求转发给所在的Shard分片的Leader节点。
2.Leader会把数据(Document),路由到所在Shard分片的每个Replica节点上。
3.如果文档分片路由规则计算出目标Shard分片是另外一个分片。则leader会把数据转发给该分片对应的leader 节点去处理。
SolrCloud采用了什么算法进行索引数据分片Shard呢?为了选择何时的分片的算法。SolrCloud提供了一个两个关键要求。
1.分片算法的计算速度就必须快,因为建立索引及访问索引的过程中都频繁用到分片算法。
2.分片算法必须保证索引数据能均匀的分布到每个分片上。SolrCloud的查询同时先后汇总了的过程。如果某个分片中的索引文档。(Document的数量远远大于其他分片。那么查询此分片同时花的时间就会明显多于其他分片。片大于其他分片。也就是说慢分片的查询速度决定了整体的查询的速度。
基于两点考虑。SolrCloud选择了一致性hash算法来实现索引分片。
Solr为了提供更实时的检索能力,提供了Soft Commit的新模式,在这种模式中不仅把数据提交到内存中。此时没有写入到磁盘索引文件中,但是索引index可见。solr会打开新的Searcher从而使得新的Document可见。同时,Solr会进行预热缓存以及查询以使得缓存的数据也是可见的。为了保证数据最终会持久化到磁盘上。可以每1-10分钟自动触发Hard Commit而每秒钟自动触发Soft Commit。Soft Commit也是一把双刃剑,一方面Commit越频繁,查询实时性越高。但同时增加solr的负荷。因为Commity越频繁越会生成小或者多的索引段。于是Solr Mange的行为会更加频繁。在实际项目中建议根据业务的需求和忍受。来确定Soft Commit的频率。
4、ElasticSearch
ElasticSearch简称ES,它并不是Apache出品的。和Solr类似,也是基于Lucene的一个分布式索引的中间件。在日志分析领域,以ElasticSearch为核心的ELK三件套(ELK Stack)成为事实上的标准。ELK其实并不是一款软件。而是一套解决方案。是三款软件ElasticSearch,Logstash和Kibana首字母的缩写,这三款软件都是开源软件。通常是配合使用的。又先后归于Elastic.co公司名下,故称为ELK Stack。在当前流行的日志管理平台,而在流行的基于Docker与Kubernetes的Pass平台中,ELK也是标配之一。非Apache出品的ES之所以能后来居上,与ELK的流行和影响力有着千丝万缕的联系。
如下图所示是ELK Stack的一个架构组成图。
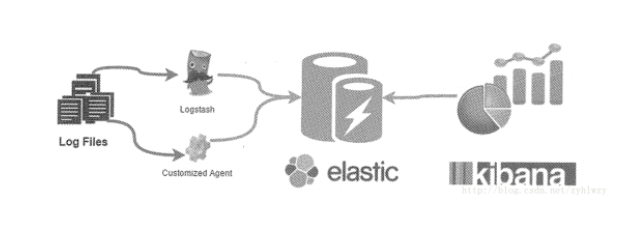
Logstash是一个有实时管道能力的数据收集引擎。用来收集日志并且作为索引数据写入到集群中。我们可以开发自定义的日志采集探头。并按照ELK的日志索引格式写入到ES集群找那个。
Kibana则为ES提供了数据分析以及数据可视化的web平台。它可以在ES的索引中查找数据并生成各种维度的标图。
ES通过简单的RESTful API来隐藏Lucene的复杂性。从而让全文检索变得简单。它提供了近时的索引,搜索,分析等功能。我们可以这样理解和描述ES。
1.分布式实时文档存储,文档中的每个字段都可被索引并搜索。
2.分布式实时分析搜索索引。
3.可以扩展到上百台服务器,处理器PB级结构化或非结构化数据。
ES中增加了Type这个概念,如果我们把index这个类比为Database ,那么Type就相当于Table。但是这个比喻又不是很恰当。因为我们知道不同的Table的表结构不同。而一个index中所有的Document的结构的高度一致的。ES中的Type其实就是Document中的一段特殊的字段。用来查询时过滤不同的Document.,比如我们在一个B2C的电商平台时,需要对每个店铺进行索引。而可以用Type区分不同的商铺,实际上。Type的使用场景非常少。这是我们需要注意的地方。
与SolrCloud一样。ES也是分布式系统,但是ES并没有采用ZooKeeper作为集群的协调者,而是自己实现了一套被称为Zen Directory的模块,该模块主要负责集群中节点自动发现和Master节点的选举,Master节点维护集群的全局状态,比如节点加入和离开时进行Shard的重新分配。而集群的节点之间则使用P2P的方式进行直接通信。不存在单点故障问题。我们需要重视一个参数是discovery.zen.minimum_master_nodes,他决定了在选举Master的过程中需要有多少个节点通信,一个基本原则是要设置成N/2+1,N是集群中节点的数量。
ES集群与SolrCloud还有一个重大区别,即ES集群中的节点类型不止一种,有以下几种类型。
1.Master节点:它有资格被选举为主节点,控制整个集群。
2.Data节点:该节点保存索引数据并执行相关操作,列如,增,删,改,查,搜索以及聚合。
3.Load balance节点:该节点只能处理路由信息,处理搜索及分发索引操作等,从本质上来说该节点的表现等同于智能负载平衡器。Load balance节点在较大的集群中是非常有用的,Load balance节点加入集群后可以得到集群的状态,并可以根据集群的状态直接路由请求。
4.Tribe节点:这是一个特殊的Load balance节点,他可以链接多个集群,在所有链接的集群上执行搜索和其他操作。
5.Ingest节点:是ES5.0新增的节点类型,该节点大大简化了以往ES集群中添加数据的复杂度。
如下所示是Tribe节点链接多个ES集群展示日志的ELK部署方案。据说魅族就采用了这种方案来解决各个IDC机房日志的集中展示问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号