
hadoop学习之hdfs文件系统
一、hdfs的概念
Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。 Hadoop是Apache Lucene创始人Doug Cutting开发的使用广泛的文本搜索库。它起源于Apache Nutch,后者是一个开源的网络搜索引擎,本身也是Luene项目的一部分。Aapche Hadoop架构是MapReduce算法的一种开源应用,是Google开创其帝国的重要基石。
什么是文件系统呢,其实我们最熟悉的windows用的是NTFS文件系统,linux用的是EXT3等等的,那归根结底不管什么存储方式,不同的文件系统里面存储文件是什么形式,它都是用来存储文件的,那么HDFS也是一样的,那我们就可以把它理解为类似于Win的HDFS的一种存储文件的方式。
二、hdfs实现思想和概念
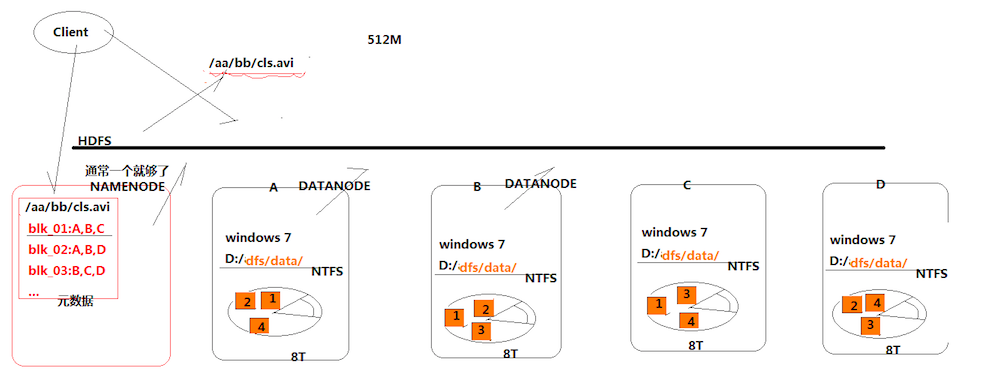
首先有一个概念叫分布式存储,它与普通的存储方式最大的区别在于,它将文件数据切分存放在多台服务器上面,从而减轻了一台服务器的存储压力。那么hdfs也是一种分布式存储的系统,具体怎么存储的如上图所示。
首先,我们又ABCD四个存储的服务器,有一个待存储的文件叫cls.avi,那么既然是分布式存储的,那么我们可以先将带存储文件切分为4块,在图中以1234个小方块表示,那么,我们可以将1234分别先存储到ABCD四个服务器里面,然后ABCD分别用NTFS将其保存起来。
那么这样初步实现了将数据分块存储,然后需要取数据的时候,从四台服务器将数据取出来然后拼接起来,这样就初步实现了数据分布化。但是这样存储面临一种问题,也就是说,如果我其中的一台服务器,比如说A坏掉了,那么最终我取出来的文件便会不全,那么为了解决这种问题,hdfs将文件的块存储在多台服务器里面,如上图中,块1存储在ABC,块2存储在ABD等等,那么如果说,我想取出块1,那么即便A坏了,我也可以从BC里面取,那么最终我取出来的数据还是完整的。
接着,还有一个问题,我是如何知道哪些块存储在哪些服务器上面的呢?那么hdfs提供了一个类似于路由服务器的功能,也就是所谓的namenode,前面所说的存储的服务器叫做datanode。那么namenode主要的功能便是,在数据块被存储的时候,将数据存储信息记录下来,比如说块1:ABC,块2:ABD等等,那么到客户端需要取出数据的时候,可以根据这些存储信息去对应的服务器上面获取数据即可,而且我们不太需要关心namenode的并发压力问题,因为这些存储信息的大小都会很小,不像datanode那样需要存储数据块。
三、总结
1.hdfs是通过分布式集群来存储文件的,文件被存储的时候分块多个block块
2.某一个block块存储在多台数据服务器datanode里面的
3.block块于datanode的存储关系是映射的,信息存储在namenode里面
4.这样存储的好处是其中一台机器发生故障,不会影响到数据的存储与读取
hdfs主要是负责存储,那么如何快速的将这些存储的大量数据读取并且返回给客户端,那么便是MapReduce需要去做的了。博主也是刚刚接触hadoop不久,上面的只是博主个人所学的见解,如果有不对的地方,还请大家多多指教。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~