
# 全网最细 | 21张图带你领略集合的线程不安全
全网最细 | 21张图带你领略集合的线程不安全
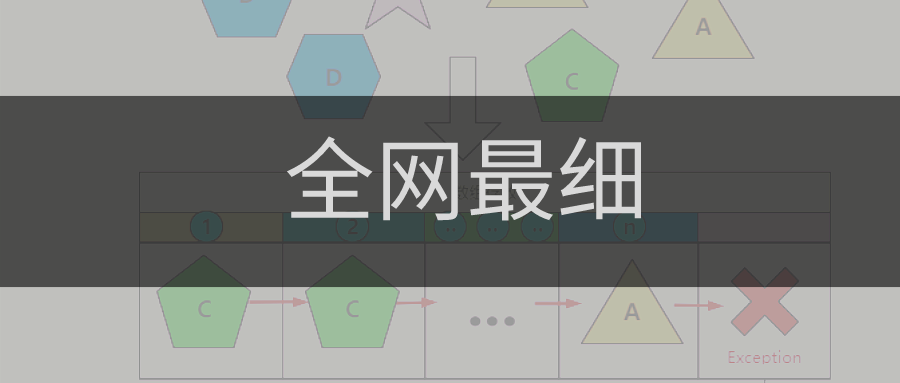
本篇主要内容如下:
本篇所有示例代码已更新到 我的Github
本篇文章已收纳到我的Java在线文档
《Java并发必知必会》系列:
1.反制面试官 | 14张原理图 | 再也不怕被问 volatile!

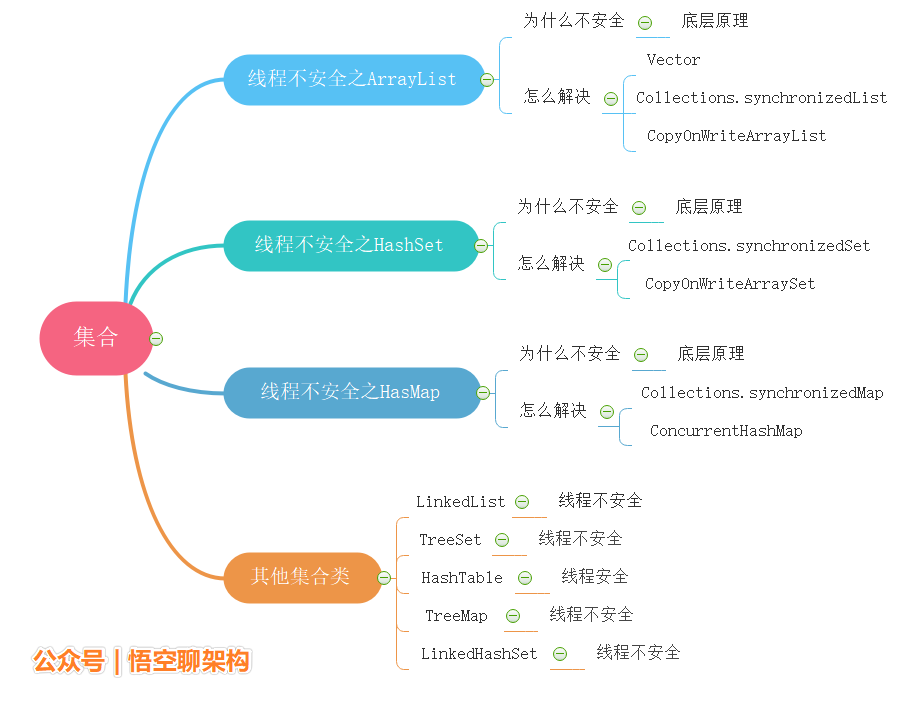
一、线程不安全之ArrayList
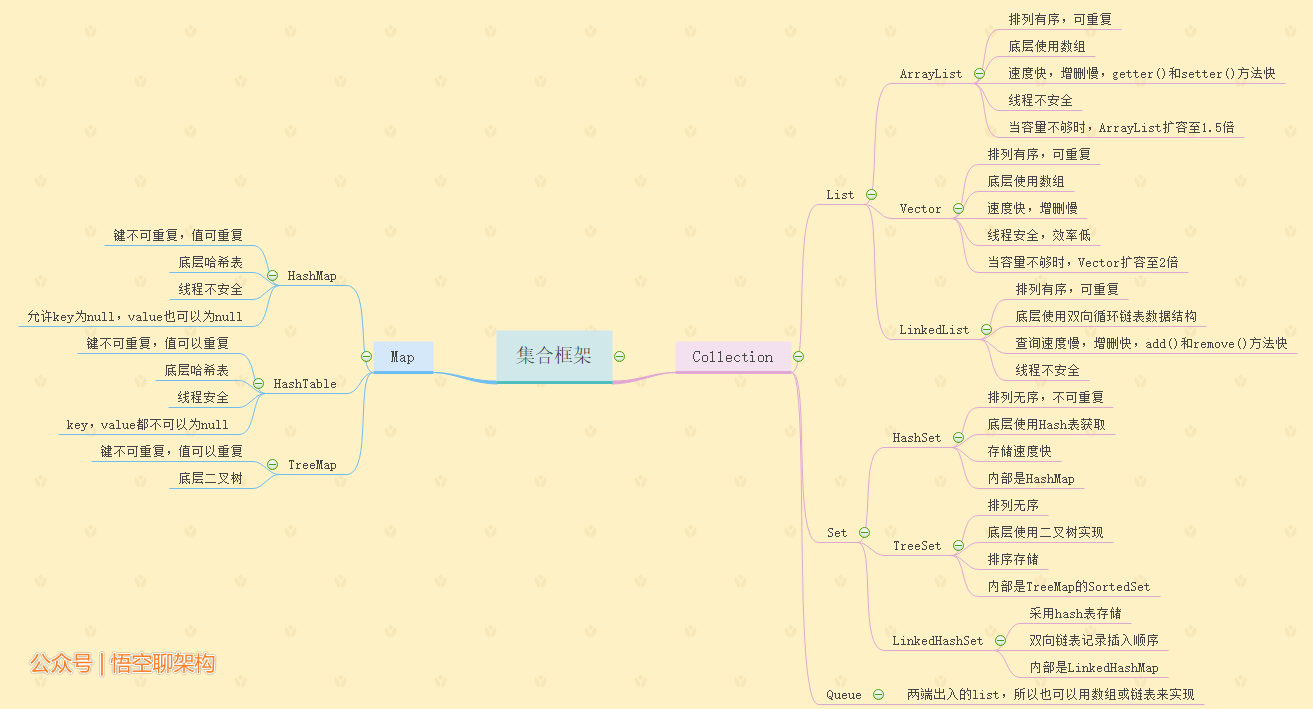
集合框架有Map和Collection两大类,Collection下面有List、Set、Queue。List下面有ArrayList、Vector、LinkedList。如下图所示:
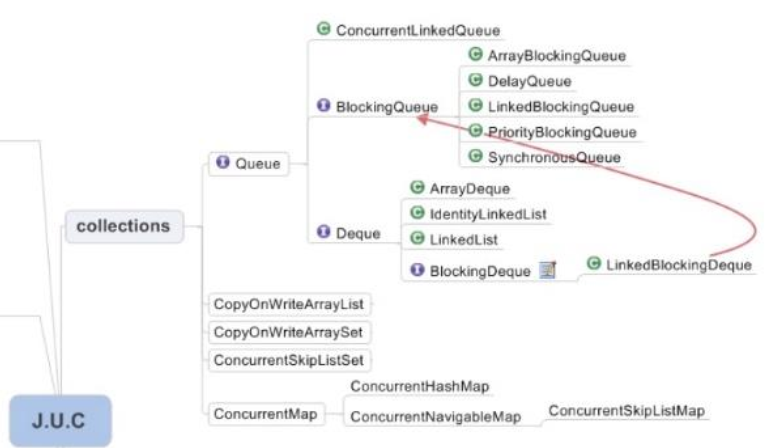
JUC并发包下的集合类Collections有Queue、CopyOnWriteArrayList、CopyOnWriteArraySet、ConcurrentMap
我们先来看看ArrayList。
1.1、ArrayList的底层初始化操作
首先我们来复习下ArrayList的使用,下面是初始化一个ArrayList,数组存放的是Integer类型的值。
new ArrayList<Integer>();
那么底层做了什么操作呢?
1.2、ArrayList的底层原理
1.2.1 初始化数组
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
创建了一个空数组,容量为0,根据官方的英文注释,这里容量应该为10,但其实是0,后续会讲到为什么不是10。
1.2.1 ArrayList的add操作
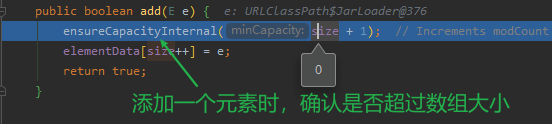
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
重点是这一步:elementData[size++] = e; size++和elementData[xx]=e,这两个操作都不是原子操作(不可分割的一个或一系列操作,要么都成功执行,要么都不执行)。
1.2.2 ArrayList扩容源码解析
(1)执行add操作时,会先确认是否超过数组大小
ensureCapacityInternal(size + 1);
(2)计算数组的当前容量calculateCapacity
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
minCapacity : 值为1
elementData:代表当前数组
我们先看ensureCapacityInternal调用的ensureCapacityInternal方法
calculateCapacity(elementData, minCapacity)
calculateCapacity方法如下:
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
elementData:代表当前数组,添加第一个元素时,elementData等于DEFAULTCAPACITY_EMPTY_ELEMENTDATA(空数组)
minCapacity:等于1
DEFAULT_CAPACITY: 等于10
返回 Math.max(DEFAULT_CAPACITY, minCapacity) = 10
小结:所以第一次添加元素时,计算数组的大小为10
(3)确定当前容量ensureExplicitCapacity
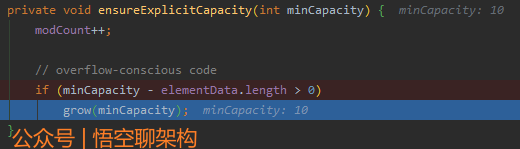
minCapacity = 10
elementData.length=0
小结:因minCapacity > elementData.length,所以进行第一次扩容,调用grow()方法从0扩大到10。
(4)调用grow方法
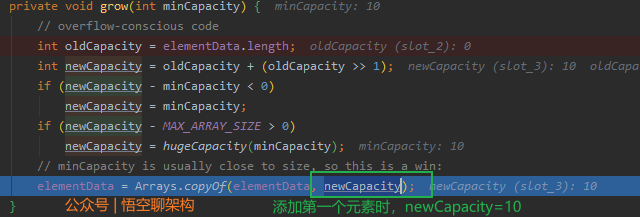
oldCapacity=0,newCapacity=10。
然后执行 elementData = Arrays.copyOf(elementData, newCapacity);
将当前数组和容量大小进行数组拷贝操作,赋值给elementData。数组的容量设置为10
elementData的值和DEFAULTCAPACITY_EMPTY_ELEMENTDATA的值将会不一样。
(5)然后将元素赋值给数组第一个元素,且size自增1
elementData[size++] = e;
(6)添加第二个元素时,传给ensureCapacityInternal的是2
ensureCapacityInternal(size + 1)
size=1,size+1=2
(7)第二次添加元素时,执行calculateCapacity
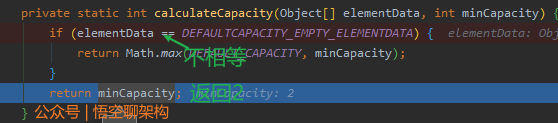
elementData的值和DEFAULTCAPACITY_EMPTY_ELEMENTDATA的值不相等,所以直接返回2
(8)第二次添加元素时,执行ensureExplicitCapacity
因minCapacity等于2,小于当前数组的长度10,所以不进行扩容,不执行grow方法。
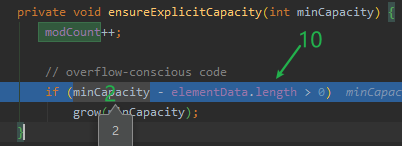
(9)将第二个元素添加到数组中,size自增1
elementData[size++] = e
(10)当添加第11个元素时调用grow方法进行扩容
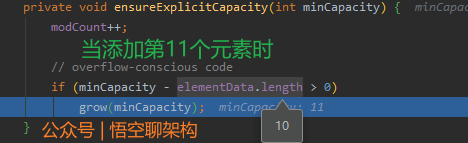
minCapacity=11, elementData.length=10,调用grow方法。
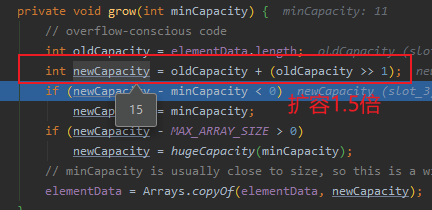
(11)扩容1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
oldCapacity=10,先换算成二级制1010,然后右移一位,变成0101,对应十进制5,所以newCapacity=10+5=15,扩容1.5倍后是15。
(12)小结
- 1.ArrayList初始化为一个
空数组 - 2.ArrayList的Add操作不是线程安全的
- 3.ArrayList添加第一个元素时,数组的容量设置为
10 - 4.当ArrayList数组超过当前容量时,扩容至
1.5倍(遇到计算结果为小数的,向下取整),第一次扩容后,容量为15,第二次扩容至22... - 5.ArrayList在第一次和扩容后都会对数组进行拷贝,调用
Arrays.copyOf方法。

1.3、ArrayList单线程环境是否安全?
场景:
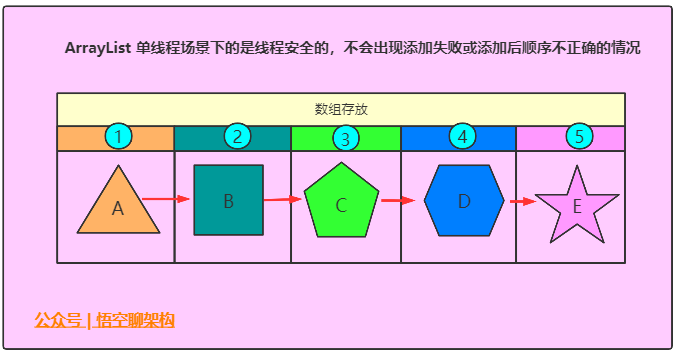
我们通过一个添加积木的例子来说明单线程下ArrayList是线程安全的。
将 积木 三角形A、四边形B、五边形C、六边形D、五角星E依次添加到一个盒子中,盒子中共有5个方格,每一个方格可以放一个积木。
代码实现:
(1)这次我们用新的积木类BuildingBlockWithName
这个积木类可以传形状shape和名字name
/**
* 积木类
* @author: 悟空聊架构
* @create: 2020-08-27
*/
class BuildingBlockWithName {
String shape;
String name;
public BuildingBlockWithName(String shape, String name) {
this.shape = shape;
this.name = name;
}
@Override
public String toString() {
return "BuildingBlockWithName{" + "shape='" + shape + ",name=" + name +'}';
}
}
(2)初始化一个ArrayList
ArrayList<BuildingBlock> arrayList = new ArrayList<>();
(3)依次添加三角形A、四边形B、五边形C、六边形D、五角星E
arrayList.add(new BuildingBlockWithName("三角形", "A"));
arrayList.add(new BuildingBlockWithName("四边形", "B"));
arrayList.add(new BuildingBlockWithName("五边形", "C"));
arrayList.add(new BuildingBlockWithName("六边形", "D"));
arrayList.add(new BuildingBlockWithName("五角星", "E"));
(4)验证arrayList中元素的内容和顺序是否和添加的一致
BuildingBlockWithName{shape='三角形,name=A}
BuildingBlockWithName{shape='四边形,name=B}
BuildingBlockWithName{shape='五边形,name=C}
BuildingBlockWithName{shape='六边形,name=D}
BuildingBlockWithName{shape='五角星,name=E}
我们看到结果确实是一致的。
小结: 单线程环境中,ArrayList是线程安全的。
1.4、多线程下ArrayList是不安全的
场景如下: 20个线程随机往ArrayList添加一个任意形状的积木。
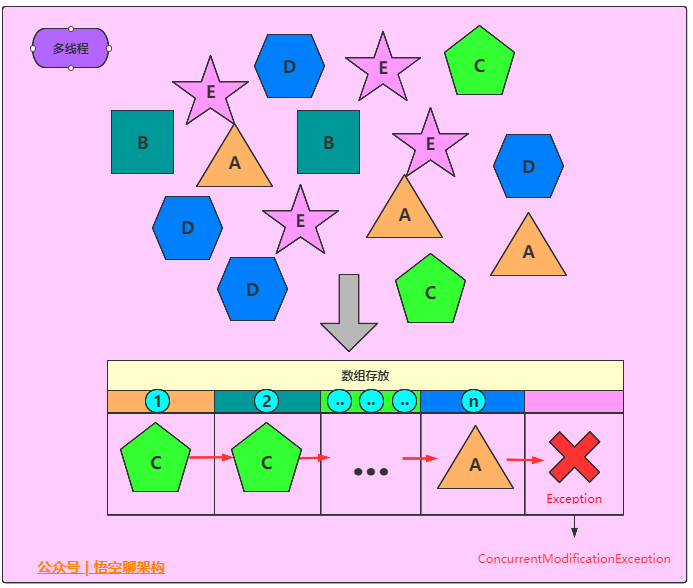
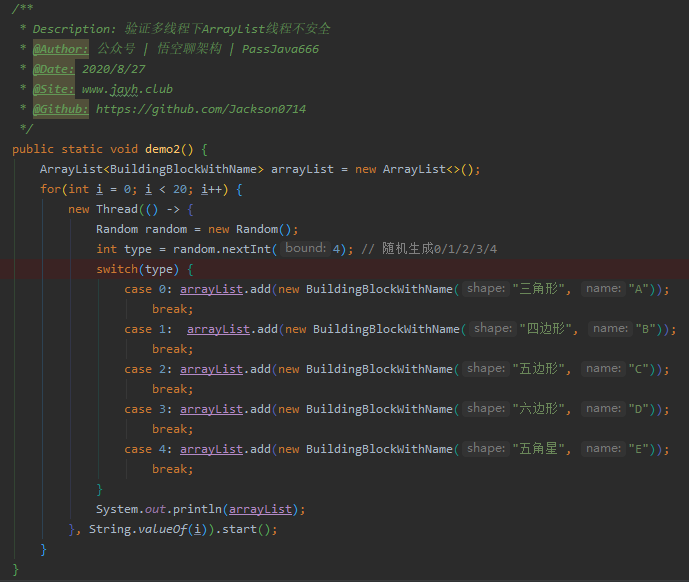
(1)代码实现:20个线程往数组中随机存放一个积木。
(2)打印结果:程序开始运行后,每个线程只存放一个随机的积木。
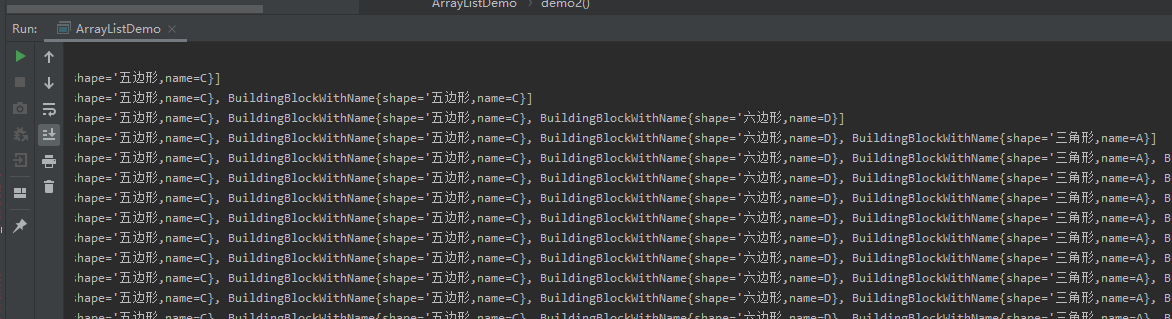
数组中会不断存放积木,多个线程会争抢数组的存放资格,在存放过程中,会抛出一个异常: ConcurrentModificationException(并行修改异常)
Exception in thread "10" Exception in thread "13" java.util.ConcurrentModificationException
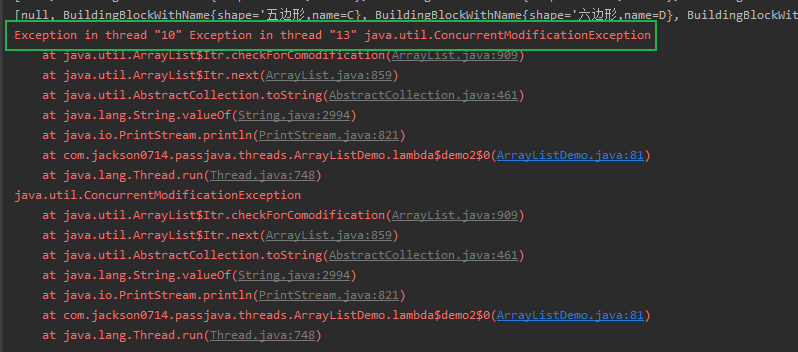
这个就是常见的并发异常:java.util.ConcurrentModificationException
1.5 那如何解决ArrayList线程不安全问题呢?
有如下方案:
- 1.用Vector代替ArrayList
- 2.用Collections.synchronized(new ArrayList<>())
- 3.CopyOnWriteArrayList
1.6 Vector是保证线程安全的?
下面就来分析vector的源码。
1.6.1 初始化Vector
初始化容量为10
public Vector() {
this(10);
}
1.6.2 Add操作是线程安全的
Add方法加了synchronized,来保证add操作是线程安全的(保证可见性、原子性、有序性),对这几个概念有不懂的可以看下之前的写的文章-》 反制面试官 | 14张原理图 | 再也不怕被问 volatile!
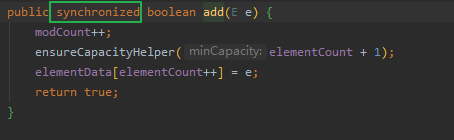
1.6.3 Vector扩容至2倍
int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity);
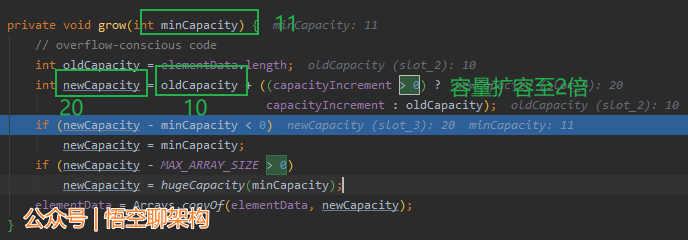
注意: capacityIncrement 在初始化的时候可以传值,不传则默认为0。如果传了,则第一次扩容时为设置的oldCapacity+capacityIncrement,第二次扩容时扩大1倍。
缺点: 虽然保证了线程安全,但因为加了排斥锁synchronized,会造成阻塞,所以性能降低。

1.6.4 用积木模拟Vector的add操作
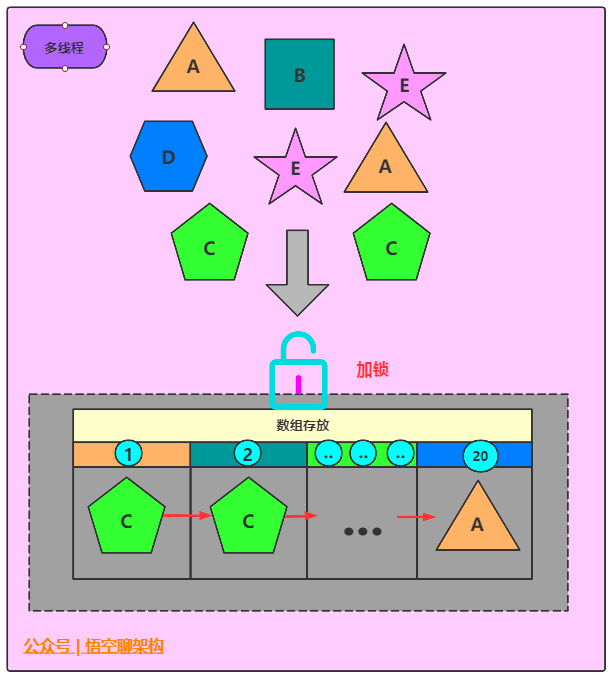
当往vector存放元素时,给盒子加了一个锁,只有一个人可以存放积木,放完后,释放锁,放第二元素时,再进行加锁,依次往复进行。
1.7 使用Collections.synchronizedList保证线程安全
我们可以使用Collections.synchronizedList方法来封装一个ArrayList。
List<Object> arrayList = Collections.synchronizedList(new ArrayList<>());
为什么这样封装后,就是线程安全的?
源码解析: 因为Collections.synchronizedList封装后的list,list的所有操作方法都是带synchronized关键字的(除iterator()之外),相当于所有操作都会进行加锁,所以使用它是线程安全的(除迭代数组之外)。


注意: 当迭代数组时,需要手动做同步。官方示例如下:
synchronized (list) {
Iterator i = list.iterator(); // Must be in synchronized block
while (i.hasNext())
foo(i.next());
}
1.8 使用CopyOnWriteArrayList保证线程安全

1.8.1 CopyOnWriteArrayList思想
- Copy on write:写时复制,一种读写分离的思想。
- 写操作:添加元素时,不直接往当前容器添加,而是先拷贝一份数组,在新的数组中添加元素后,在将原容器的引用指向新的容器。因为数组时用volatile关键字修饰的,所以当array重新赋值后,其他线程可以立即知道(volatile的可见性)
- 读操作:读取数组时,读老的数组,不需要加锁。
- 读写分离:写操作是copy了一份新的数组进行写,读操作是读老的数组,所以是读写分离。
1.8.2 使用方式
CopyOnWriteArrayList<BuildingBlockWithName> arrayList = new CopyOnWriteArrayList<>();
1.8.3 底层源码分析
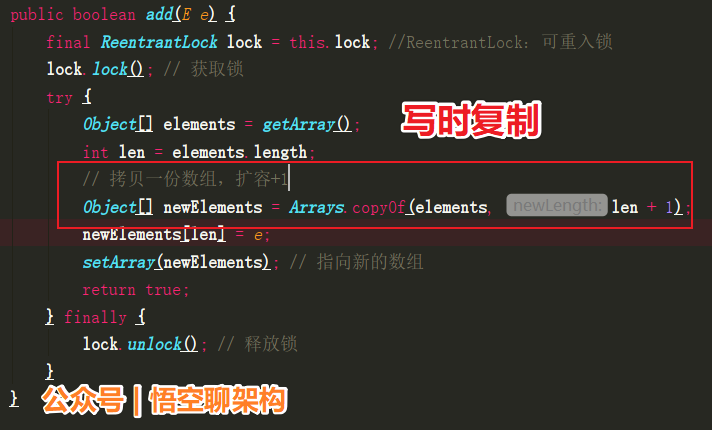
add的流程:
- 先定义了一个可重入锁
ReentrantLock - 添加元素前,先获取锁
lock.lock() - 添加元素时,先拷贝当前数组
Arrays.copyOf - 添加元素时,扩容+1(
len + 1) - 添加元素后,将数组引用指向新加了元素后的数组
setArray(newElements)
为什么数组重新赋值后,其他线程可以立即知道?
因为这里的数组是用volatile修饰的,哇,又是volatile,这个关键字真妙_
private transient volatile Object[] array;

1.8.4 ReentrantLock 和synchronized的区别
划重点
相同点:
- 1.都是用来协调多线程对共享对象、变量的访问
- 2.都是可重入锁,同一线程可以多次获得同一个锁
- 3.都保证了可见性和互斥性
不同点:

- 1.ReentrantLock 显示的获得、释放锁, synchronized 隐式获得释放锁
- 2.ReentrantLock 可响应中断, synchronized 是不可以响应中断的,为处理锁的不可用性提供了更高的灵活性
- 3.ReentrantLock 是 API 级别的, synchronized 是 JVM 级别的
- 4.ReentrantLock 可以实现公平锁、非公平锁
- 5.ReentrantLock 通过 Condition 可以绑定多个条件
- 6.底层实现不一样, synchronized 是同步阻塞,使用的是悲观并发策略, lock 是同步非阻塞,采用的是乐观并发策略
1.8.5 Lock和synchronized的区别

- 1.Lock需要手动获取锁和释放锁。就好比自动挡和手动挡的区别
- 1.Lock 是一个接口,而 synchronized 是 Java 中的关键字, synchronized 是内置的语言实现。
- 2.synchronized 在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而 Lock 在发生异常时,如果没有主动通过 unLock()去释放锁,则很可能造成死锁现象,因此使用 Lock 时需要在 finally 块中释放锁。
- 3.Lock 可以让等待锁的线程响应中断,而 synchronized 却不行,使用 synchronized 时,等待的线程会一直等待下去,不能够响应中断。
- 4.通过 Lock 可以知道有没有成功获取锁,而 synchronized 却无法办到。
- 5.Lock 可以通过实现读写锁提高多个线程进行读操作的效率。
二、线程不安全之HashSet
有了前面大篇幅的讲解ArrayList的线程不安全,以及如何使用其他方式来保证线程安全,现在讲HashSet应该更容易理解一些。
2.1 HashSet的用法
用法如下:
Set<BuildingBlockWithName> Set = new HashSet<>();
set.add("a");
初始容量=10,负载因子=0.75(当元素个数达到容量的75%,启动扩容)
2.2 HashSet的底层原理
public HashSet() {
map = new HashMap<>();
}
底层用的还是HashMap()。
考点: 为什么HashSet的add操作只用传一个参数(value),而HashMap需要传两个参数(key和value)
2.3 HashSet的add操作
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
考点回答: 因为HashSet的add操作中,key等于传的value值,而value是PRESENT,PRESENT是new Object();,所以传给map的是 key=e, value=new Object。Hash只关心key,不考虑value。
为什么HashSet不安全: 底层add操作不保证可见性、原子性。所以不是线程安全的。
2.4 如何保证线程安全
-
1.使用Collections.synchronizedSet
Set<BuildingBlockWithName> set = Collections.synchronizedSet(new HashSet<>()); -
2.使用CopyOnWriteArraySet
CopyOnWriteArraySet<BuildingBlockWithName> set = new CopyOnWriteArraySet<>();
2.5 CopyOnWriteArraySet的底层还是使用的是CopyOnWriteArrayList
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
三、线程不安全之HashMap
3.1 HashMap的使用
同理,HashMap和HashSet一样,在多线程环境下也是线程不安全的。
Map<String, BuildingBlockWithName> map = new HashMap<>();
map.put("A", new BuildingBlockWithName("三角形", "A"));
3.2 HashMap线程不安全解决方案:
- 1.Collections.synchronizedMap
Map<String, BuildingBlockWithName> map2 = Collections.synchronizedMap(new HashMap<>());
- 2.ConcurrentHashMap
ConcurrentHashMap<String, BuildingBlockWithName> set3 = new ConcurrentHashMap<>();
3.3 ConcurrentHashMap原理
ConcurrentHashMap,它内部细分了若干个小的 HashMap,称之为段(Segment)。 默认情况下一个 ConcurrentHashMap 被进一步细分为 16 个段,既就是锁的并发度。如果需要在 ConcurrentHashMap 中添加一个新的表项,并不是将整个 HashMap 加锁,而是首先根据 hashcode 得到该表项应该存放在哪个段中,然后对该段加锁,并完成 put 操作。在多线程环境中,如果多个线程同时进行put操作,只要被加入的表项不存放在同一个段中,则线程间可以做到真正的并行。
四、其他的集合类
LinkedList: 线程不安全,同ArrayList
TreeSet: 线程不安全,同HashSet
LinkedHashSet: 线程不安全,同HashSet
TreeMap: 同HashMap,线程不安全
HashTable: 线程安全
总结
本篇第一个部分详细讲述了ArrayList集合的底层扩容原理,演示了ArrayList的线程不安全会导致抛出并发修改异常。然后通过源码解析的方式讲解了三种方式来保证线程安全:
Vector是通过在add等方法前加synchronized来保证线程安全Collections.synchronized()是通过包装数组,在数组的操作方法前加synchronized来保证线程安全CopyOnWriteArrayList通过写时复制来保证线程安全的。
第二部分讲解了HashSet的线程不安全性,通过两种方式保证线程安全:
- Collections.synchronizedSet
- CopyOnWriteArraySet
第三部分讲解了HashMap的线程不安全性,通过两种方式保证线程安全:
- Collections.synchronizedMap
- ConcurrentHashMap
另外在讲解的过程中,也详细对比了ReentrantLock和synchronized及Lock和synchronized的区别。
彩蛋: 聪明的你,一定发现集合里面还漏掉了一个重要的东西:那就是Queue。期待后续么?
白嫖么?转发->在看->点赞-收藏!!!
我是悟空,一只努力变强的码农!我要变身超级赛亚人啦!

另外可以搜索「悟空聊架构」或者PassJava666,一起进步!
我的GitHub主页,关注我的Spring Cloud实战项目《佳必过》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号