
20199125 2019-2020-2 《网络攻防实践》综合实践
一、综述
本次所读论文为是2018年USENIX Security大会上的由德国科学家Cristian-Alexandru Staicu and Michael Pradel发表的《Freezing the Web: A Study of ReDoS Vulnerabilities in JavaScript-based Web Servers》,该文章主要是分析对于javascript中利用正则表达式进行攻击的可行性以及提出了一种检测Web网站是否易受到正则表达式拒绝服务攻击的方法。
二、关于该论文的创新点
ReDoS(正则表达式拒绝服务攻击)早已经被发现多年,并且被利用于python、java等开发语言环境中,但是对于在javascript中使用正则表达式攻击,却很少有人进行研究。恰恰相反的是,在Web中使用到正则表达式的频率更高,如何输入校验、查找替换等都需要使用到正则表达式。本文作者基于Node.js来研究javascript中关于ReDoS攻击,其主要原因是:JavaScript越来越流行,包括服务器端Node.js平台,它提倡使用异步I/O调用的单线程、基于事件的执行模型。在Node.js中,执行的主线程运行一个事件循环,称为主循环,用于处理由网络请求、I/O操作、计时器等触发的事件。缓慢的计算(例如,将字符串与正则表达式匹配)会减慢所有其他传入请求的速度。与多线程web服务器(如Apache)相比,单线程执行模型在JavaScript中解决了这个问题。例如,考虑一个需要一个多小时才能匹配的正则表达式,作者发现它存在于广泛使用的JavaScript软件中。要完全阻塞Apache web服务器,需要发送数百个这样的请求,每个请求阻塞一个线程。根据可用并行处理单元的数量、操作系统和线程池的大小,即使有上百个繁忙的线程在运行,也可以处理新的请求。相反,在Node.js中一个这样的请求就足以完全阻塞服务器一小时。更糟糕的是,即使不太严重的ReDoS有效负载也会显著降低Node.js服务器。
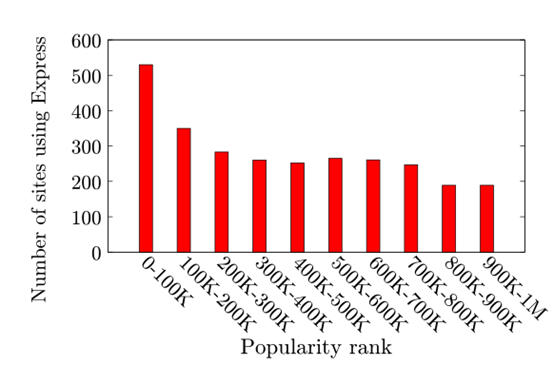
为此,作者调查了有多少受欢迎的网站使用了javascript技术,通过Alexa汇总的100万个受欢迎的网站,统计其中使用了最为流行的基于javascript的web服务器框架Express的站点,所采用的方法是“向100万个网站中的每一个发出请求,并检查标题X-Powered-By是否为“Express”。框架在新安装时默认设置此值”,若为Express,即说明使用了javascript。通过分析可知,受欢迎程度靠前的网站有大量都使用了javascript,这为回答受欢迎的网站是否易受ReDoS攻击提供了数据支撑。
三、如何衡量一个网站可以被攻击利用的程度
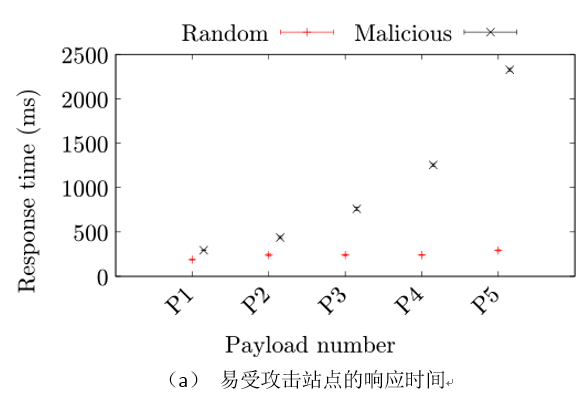
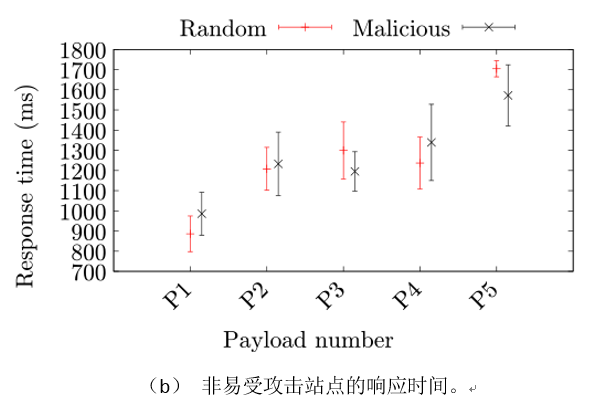
给定一组可能被利用的正则表达式,手动检查使用正则表达式的上下文。其目标是找到可以通过HTTP请求传递到web服务器的数据上的匹配操作。为此,重点关注(i)Express框架中包含的模块,(ii)扩展该框架的中间件模块,以及(iii)操作HTTP请求组件(如主体或特定头)的模块。对于这些模块中的正则表达式,只保留那些有可能从包接口或从HTTP头到正则表达式的数据流的正则表达式。基于npm模块中的ReDoS漏洞,作者创建了针对使用这些模块的web服务器的攻击。主要思想是假设服务器端web应用程序如何使用模块。为此,设置了一个新的Express安装,并实现了一个使用该模块的示例web应用程序。例如,对于解析用户代理的包,构建一个应用程序来解析主页面的每个HTTP请求的用户代理,这可能用于跟踪访问者。接下来,创建一个HTTP请求,其中用户控制的数据到达易受攻击的正则表达式,并编写触发异常长匹配时间的输入值。为了制作输入,作者试图通过强迫正则表达式引擎回溯来混淆正则表达式引擎,因为输入可以以多种方式进行匹配。在创建漏洞时,假设头的最大大小是81,750个字符,这是Express.js的默认值。如果成功地创造了一个正则表达式匹配时间超过5秒的输入,就认为这个漏洞是可利用的,并在接下来的研究中考虑它。
为了进一步评估攻击的影响,作者测量处理精心设计的输入与处理相同长度的随机字符串所花费的时间。我们用两种方法来测量时间。首先,我们测量正则表达式的匹配时间,例如检查字符串是否与正则表达式匹配所需的时间。其次,我们测量整个HTTP请求的时间,称为响应时间。响应时间可能包括各种其他组件,例如HTTP解析和序列化、DNS解析、包的路由时间,以及处理HTTP重传输或包碎片。
由于DNS解析、网络缓存、延迟、重传和其他影响因素,以可靠的方式度量响应时间并不简单。另一个问题是如何以统计可靠的方式确定响应时间是否大于另一个响应时间。作者通过调整技术来解决这些问题,最初用于比较运行在虚拟机上的软件的性能。其基本思想是反复测量响应时间,并得出结论:只有当作者观察到统计上显著的差异时,精心设计的输入才会比随机输入产生更高的响应时间。
更具体地说,为了度量给定输入的响应时间,作者首先重复请求n_w次来“预热”连接,例如,填充网络缓存,然后在记录响应时间的同时再重复请求n_m次。给定k对越来越大的随机和精心设计的输入(i_random, i_crafted),其中一对中的两个输入具有相同的大小,作者得到k对(T_random, T_crafted)的时间测量集(|T_random|=|T_crafted |=n_m)。对于每个输入大小,作者比较T_random, T_crafted中值的置信区间,并得出结论:只有当且仅当区间不重叠时,响应时间才不同。如果所有k个输入大小的响应时间不同,作者将输入大小的差异量化为T ̅_random, T ̅_crafted之间的差异,其中T ̅是T中时间的平均值。对于k个输入大小,此比较给出了一系列差异d1,…,dk。最后,当d1< d2< ..dk时,作者认为一个网站是可利用的。直观地说,这意味着随机输入和精心制作的输入的响应时间有一个统计上显著的差异,并且这个差异随着输入大小的增加而增加。
四、关于正则表达式
1.正则表达式基本介绍
正则表达式(Regular Expression, Regex)是由字符(可为英文字母、数字、符号等)与元字符(特殊符号)组成的一种有特定规则的特殊字符串。在模式匹配中,正则表达式通常被用于验证邮箱、URL、手机号码等。
JavaScript中的正则表达式用RegExp对象表示,有两种写法:一种是字面量写法;另一种是构造函数写法:
1.1 字面量写法
正则表达式字面量写法,又叫Perl写法,因为JavaScript的正则表达式特性借鉴自Perl。正则表达 式字面量定义为包含在一对斜杠/之间的字符,并且可以有3个模式修正符,let expression = /pattern/flags;这里的pattern就是指我们的字符串模式,而后面的flags则是指带的模式修正符。 JavaScript中的正则表达式支持下列3个模式修正符:
- g:表示全局(global)模式,即模式将被应用于所有字符串,而并非在发现第一个匹配项时立即停止;
- i:表示不区分大小写(case-insensitive)模式,即在确定匹配项时忽略模式与字符串的大小写;
- m:表示多行(multiline)模式,即在到达一行文本末尾时还会继续查找下一行中是否存在与模式匹配的项。
1.2 RegExp构造函数
和普通的内置对象一样,RegExp正则表达式对象也支持new RegExp。构造函数的形式来创建正 则。RegExp构造函数接收两个参数:要匹配的字符串模式(pattern)和可选的模式修正符(flags)。let reg1 = /at/i;等同于let reg2 = new RegExp("at","i")。
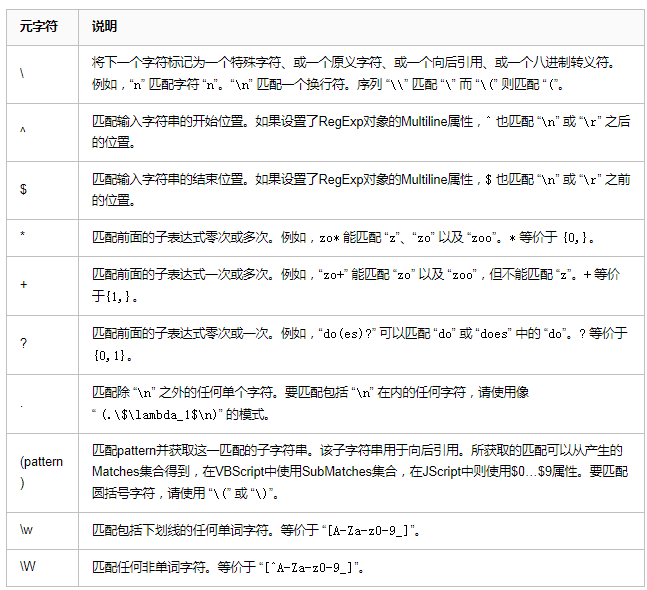
1.3 常用元字符表
2.自动机
有限状态自动机:(FSM “finite state machine” 或者FSA “finite state automaton” )是为研究有限内存的计算过程和某些语言类而抽象出的一种计算模型。有限状态自动机拥有有限数量的状态,每个状态可以迁移到零个或多个状态,输入字串决定执行哪个状态的迁移。
有限状态自动机还可以分成确定与非确定两种, 非确定有限状态自动机可以转化为确定有限状态自动机。
正则表达式引擎分成两类:一类称为DFA(确定性有限状态自动机),另一类称为NFA(非确定性有限状态自动机)。两类引擎要顺利工作,都必须有一个正则式和一个文本串,一个捏在手里,一个吃下去。DFA捏着文本串去比较正则式,看到一个子正则式,就把可能的匹配串全标注出来,然后再看正则式的下一个部分,根据新的匹配结果更新标注。而NFA是捏着正则式去比文本,吃掉一个字符,就把它跟正则式比较,匹配就记下来:“某年某月某日在某处匹配上了!”,然后接着往下干。一旦不匹配,就把刚吃的这个字符吐出来,一个个的吐,直到回到上一次匹配的地方(回溯)。
部分程序及其所使用的正则引擎:

3.ReDoS原理
3.1 概述
DFA对于文本串里的每一个字符只需扫描一次,比较快,但特性较少;NFA要翻来覆去吃字符、吐字符,速度慢,但是特性(如:分组、替换、分割)丰富。NFA支持 惰性(lazy)、回溯(backtracking)、反向引用(backreference),NFA缺省应用greedy模式,NFA可能会陷入递归险境导致性能极差。
3.2 贪婪匹配和非贪婪匹配
如果我想匹配X和y之间所有的字符,我可以简单地用x.y进行处理,注意,.代表任意字符。因此,该表达式将成功匹配x)dw2rfy字符串。但是,默认情况下,重复运算符是很贪婪的。他们会尝试尽可能多的匹配。让我们再考虑上面的例子,x.y表达式如果对字符串axaayaaya进行处理,就会返回xaayaay。但是使用者可能并不期待这种结果,他们也许只想要字符串xaay,这种x
3.3 回溯计算
计算机在处理正则表达式的时候必须经过自动机进行复杂的匹配,虽然看上去它们有很强的计算能力。当你需要用x*y表达式对字符串xxxxxxxxxxxxxxY进行匹配时,任何人都可以迅速告诉你无匹配结果,因为这个字符串不包含字符y。但是计算机的正则表达式引擎并不知道!它将执行以下操作

注意:这并不是全部的匹配步骤,而只是对第一个x的匹配,正则表达式引擎将从第二个x开始匹配,然后是第三个,然后是第四个,依此类推到第14个x,最终总步骤数为214。为了匹配这么一个并不是很长的字符串,需要执行214步,虽然这对于计算机的运算速度来说并不算什么,可是在论文中作者也提到了在Node.js中执行正则表达式匹配操作往往是单线程的,且作者实验所生成的字符串长达数万个字符(最大可达81,750个字符,这是由Express.js头部最大大小决定的),若同时发起多个恶意的HTTP请求(头部构造使用超长字符串),则必然会导致服务器耗费系统资源和大量的时间去进行正则表达式匹配,从而无法响应正常用户的请求,实现DoS攻击,即将此类攻击称之为ReDoS(正则表达式拒绝服务攻击)。
3.4 小结
每个恶意的正则表达式模式应该包含:使用重复分组构造、在重复组内会出现、重复、交替重叠。有缺陷的正则表达式会包含如下部分。
- (a+)+
- ([a-zA-Z]+)*
- (a|aa)+
- (a|a?)+
- (.*a){x} | for x > 10
注意: 这里的a是泛指。
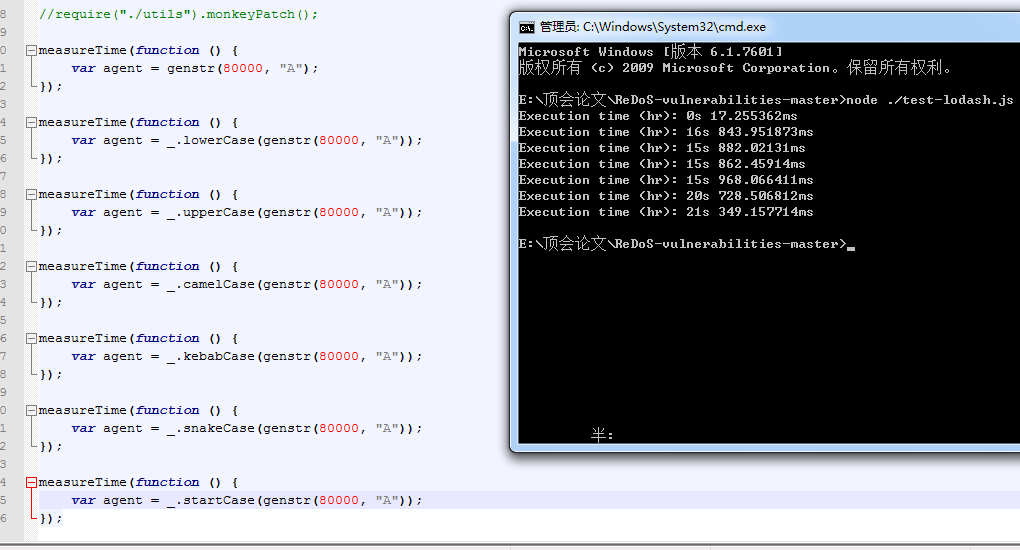
如何构造特殊字符串,根据论文作者提供的JS源码,选取其中一例,运行结果如下所示:
五、总结
在读该论文之前对于正则表达式攻击闻所未闻,对于正则表达式也并不是十分理解,但是通过查阅资料之后,发现正则表达式虽然之前不理解,但其实我们早已经在使用,如记事本、word中的查找替换“\s\r”就是一种正则表达式的使用。查阅了大量的资料,总算知道了正则表达式的表示含义;但是对于该论文,我还有不懂得地方,在论文中作者对于Node.js中的模块中的正则表达式,使用了AST(抽象语法树)进行获取,但是我查询了关于AST的资料,仍不明白是如何通过抽象语法树来提取Node.js模块中的正则表达式的。

