


软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2020春福大软工实践W班 |
|---|---|
| 这个作业要求在哪里 | 寒假作业 2/2 |
| 这个作业的目标 | 掌握Git和GitHub的使用、学习构建之法 |
| 作业正文 | 软工实践寒假作业(2/2) |
| 其他参考文献 | CSDN、知乎、各技术微信文章 |
一、GitHub仓库地址
Github仓库地址:https://github.com/LinJie1119/InfectStatistic-main
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 1140 | 1380 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 120 |
| Design Spec | 生成设计文档 | 60 | 60 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| Design | 具体设计 | 120 | 120 |
| Coding | 具体编码 | 600 | 900 |
| Code Review | 代码复审 | 60 | 120 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | 120 | 120 |
| Test Report | 测试报告 | 100 | 100 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | 1270 | 1510 |
三、解题思路描述
-
题目首先给出的是处理对象是日志文本,即每天的感染情况。所以我首先对文本进行简单的输入输出操作,便于后面编程。
-
题目首先给出的是处理对象是日志文本,即每天的感染情况。文本每行包含四种信息:省份、操作(增减)、患者类型、人数,所以我想首先对文本中的四种信息进行提取,你便于接下来的操作。
-
提取出文本的四种信息后,接着对文本经行操作。
-
做好文本信息的处理后就是,对list输入命令的读取。对命令行经行识别,然后将识别后的信息对输出进行处理操作。
四、实现过程
1.先对文本输入输出进行处理
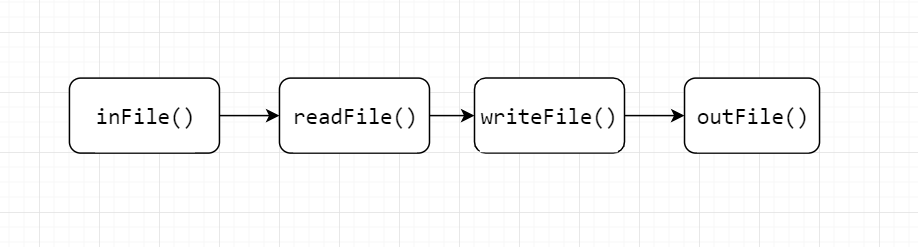
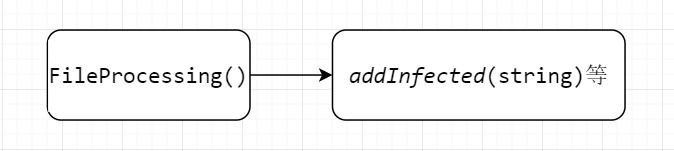
2.在对日志里不同行进行处理

3.最后对命令行进行解析处理
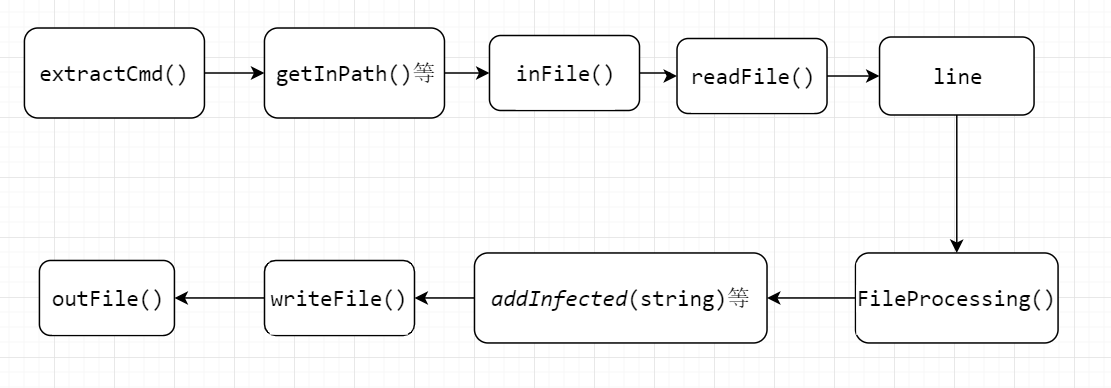
4.最后将三个处理过程连接
五、代码说明
1.将给各省份名称存储在数组中,便于比较和输出。
/**
* 各省份状态
* 默认0:没有状况
* 1:有状况
*/
private static int[] province_status = new int[32];
/**
* 省份排序(包括“全国”)
*/
private static String[] province_str = {"全国", "安徽", "北京", "重庆", "福建", "甘肃",
"广东", "广西", "贵州", "海南", "河北", "河南", "黑龙江", "湖北", "湖南",
"吉林", "江苏", "江西", "辽宁", "内蒙古", "宁夏", "青海", "山东", "山西",
"陕西", "上海", "四川", "天津", "西藏", "新疆", "云南", "浙江"};
2.将文本行中存在的集中情况用正则表达式存储在数组中,用于文本输入是的比较。
/**
* 文本中存在的所有情况
*/
private static String[] situation_str = {"(\\S+) 新增 感染患者 (\\d+)人", "(\\S+) 新增 疑似患者 (\\d+)人",
"(\\S+) 感染患者 流入 (\\S+) (\\d+)人", "(\\S+) 疑似患者 流入 (\\S+) (\\d+)人",
"(\\S+) 死亡 (\\d+)人", "(\\S+) 治愈 (\\d+)人",
"(\\S+) 疑似患者 确诊感染 (\\d+)人", "(\\S+) 排除 疑似患者 (\\d+)人"};
3.读文件根据文件地址打开文件,并逐行读入。
/**
* 读文件
*/
void readFile(String filePath) throws Throwable {
try {
Throwable var1;
try {
try (BufferedReader in = new BufferedReader(new InputStreamReader(new FileInputStream(new File(filePath)), StandardCharsets.UTF_8))) {
String line;
while ((line = in.readLine()) != null) {
if(line.equals("// 该文档并非真实数据,仅供测试使用"))
break;
LogLine.FileProcessing(line);
}
}
} catch (Throwable var11) {
var1 = var11;
throw var1;
}
} catch (Exception var12) {
var12.printStackTrace();
}
}
4.文本行与上面数组比较好,分别通过以下函数获取文本行中的信息。
/**
* 文本内容处理
*/
private static void FileProcessing(String string) {
int num = -1;
for (int i = 0; i < situation_str.length; i++) {
boolean isMatch = Pattern.matches(situation_str[i], string);
if (isMatch)
num = i;
}
switch (num) {
case 0:
addInfected(string);
break;
case 1:
addSuspected(string);
break;
case 2:
flowInfected(string);
break;
case 3:
flowSuspected(string);
break;
case 4:
addDead(string);
break;
case 5:
addCure(string);
break;
case 6:
diagnosisSuspected(string);
break;
case 7:
removeSuspected(string);
break;
default:
System.out.println("日志内容错误!");
}
}
六、单元测试截图和描述
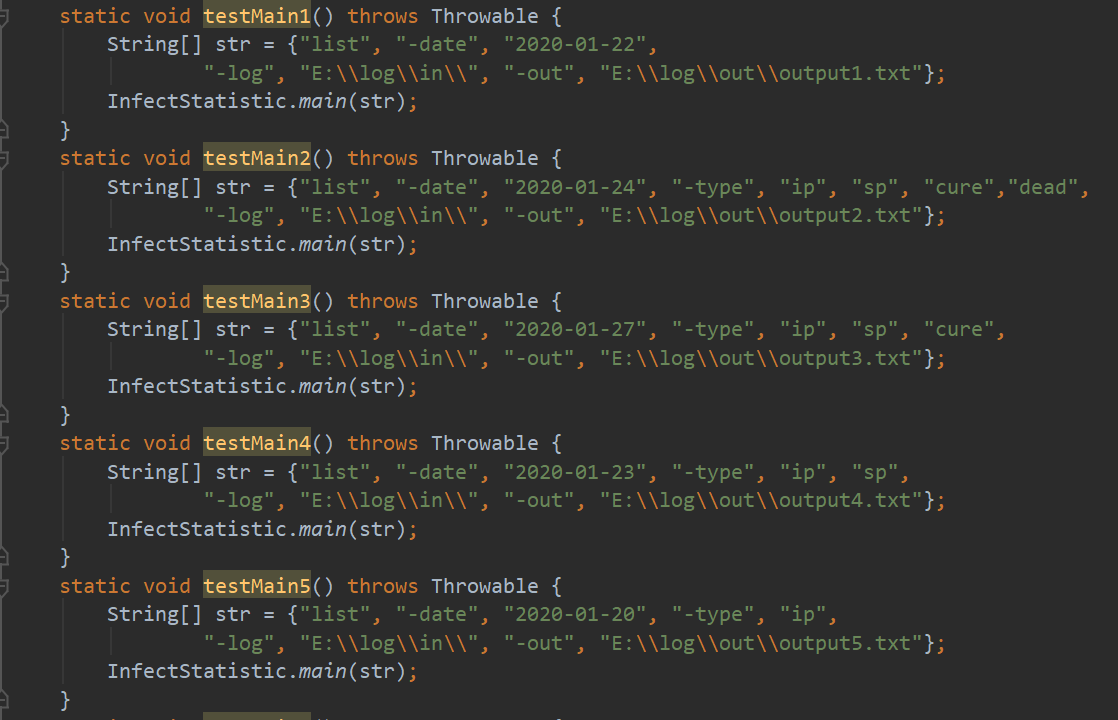
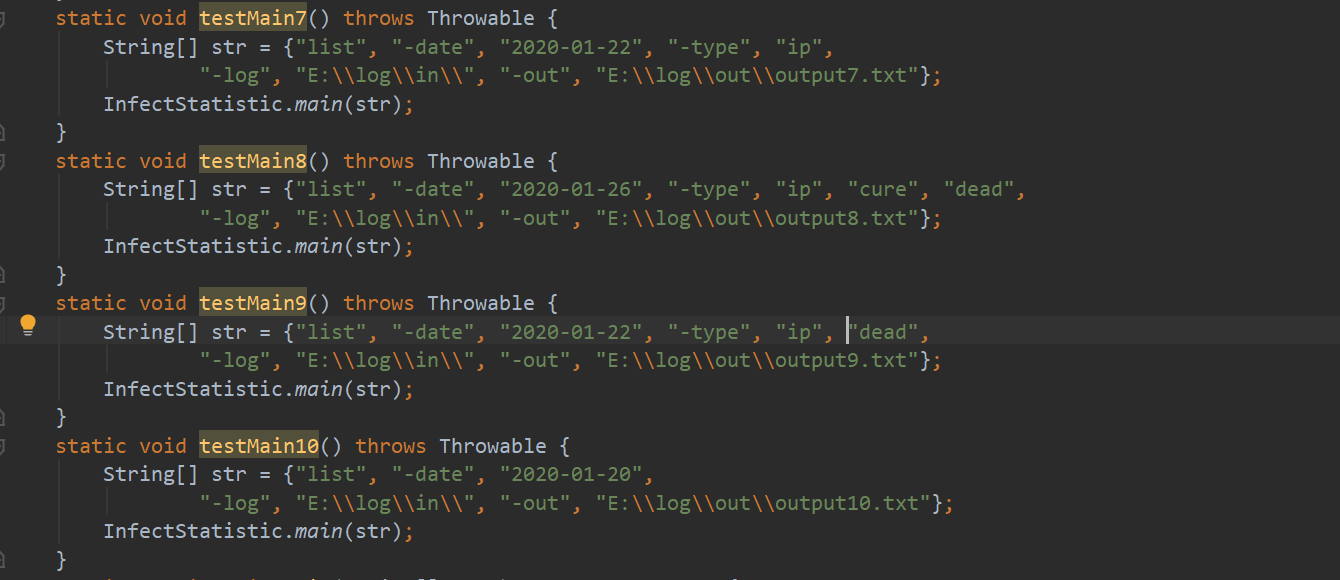
1.十个测试用例(未能实现-province的识别)
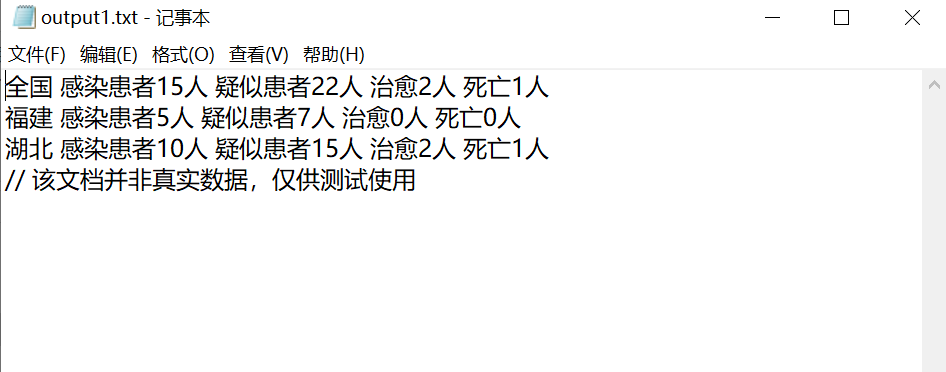
2.输出文件类似如图
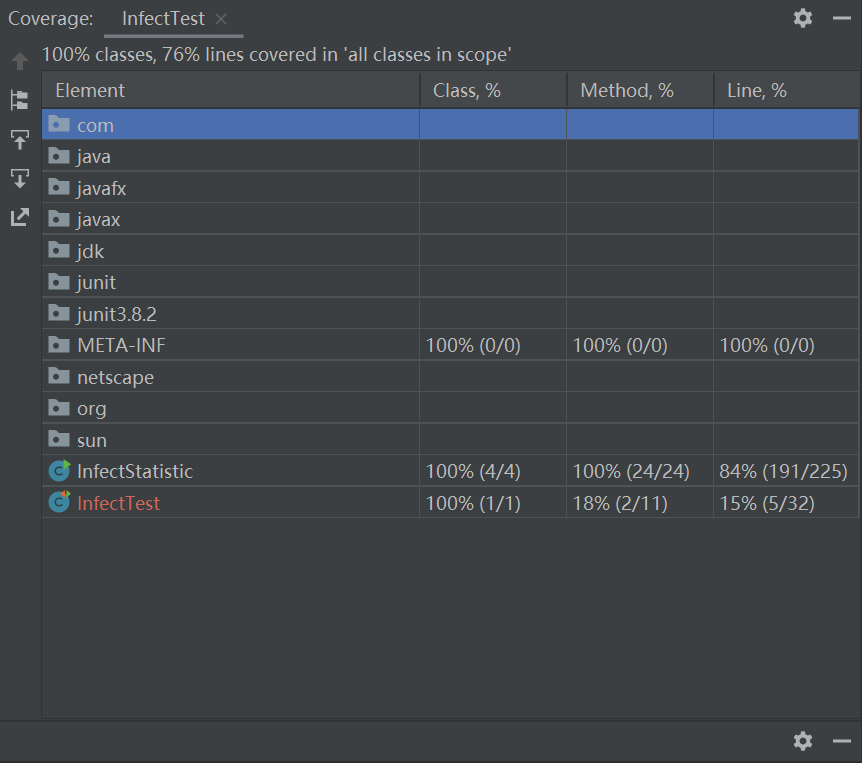
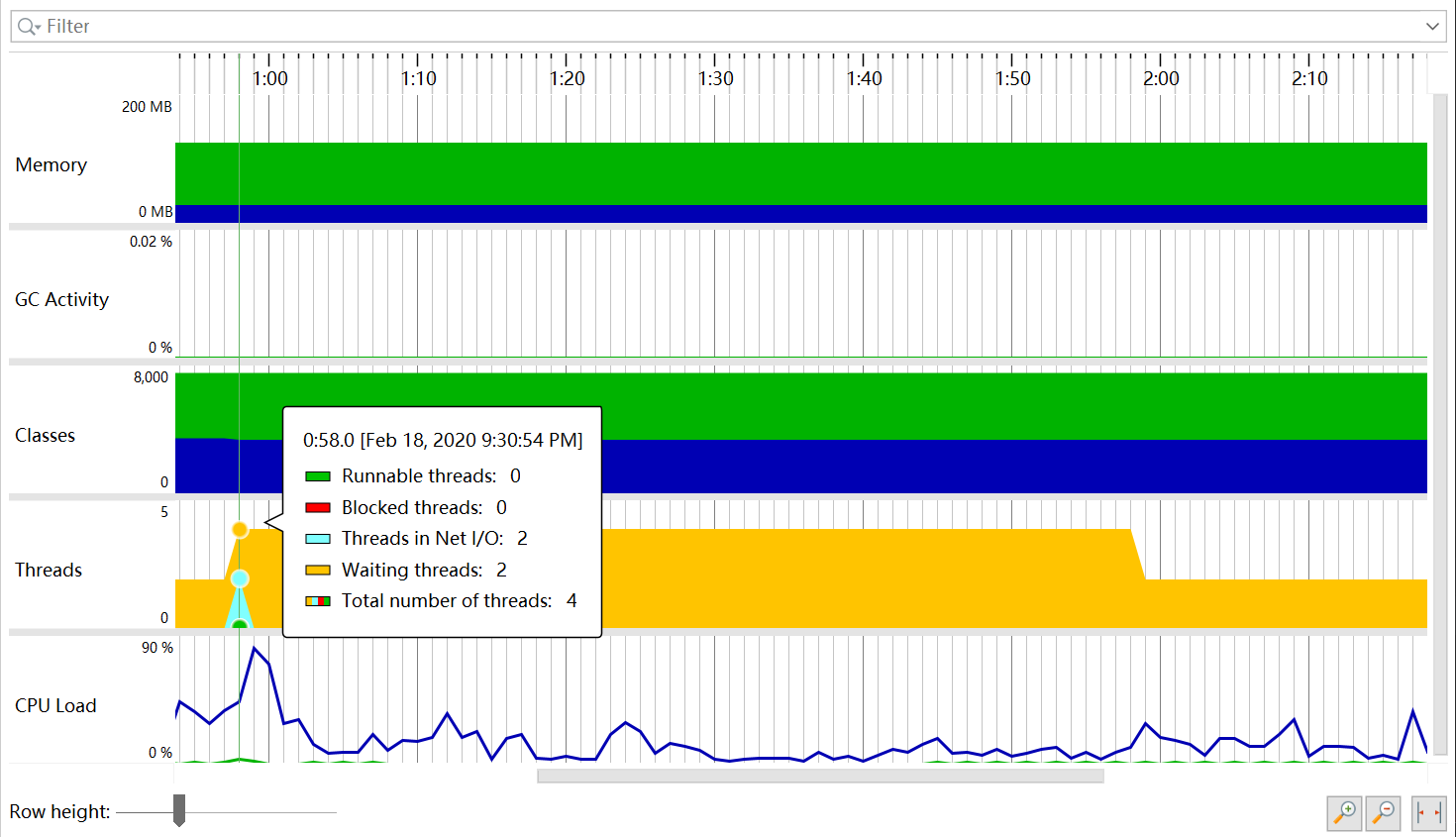
七、单元测试覆盖率优化和性能测试

八、代码规范的链接
代码规范的链接:https://github.com/LinJie1119/InfectStatistic-main/blob/master/081700316/codestyle.md
九、心路历程与收获
-
新的工具:IntelliJ IDEA,GitHub,Git都是我第一次使用,这些新的开发工具方便和规范了我的开发流程,提高了开发效率,希望在接下来的团队合作开发中进一步的熟练掌握这些工具的使用。
-
新的方法:单元测试,回归测试,效能分析,个人软件开发流程(PSP),都是我第一次听说并学习的开发方法,通过这些开发和测试方法的学习,更直观的知道了自己代码的效能,和了解到了自己在开发步骤的不规范和低效率。
-
新的态度:《构建之法》第三章提到“软件开发的目的是为了提高软件的开发运营维护的效率,以及提升用户的满意度,软件的可靠性和可维护性。”对于这次的作业,如果自己开发流程的不规范,可能导致合作开发的小伙伴、以后的运维、甚至未来的用户带来麻烦。所以我希望通过这学期的学习,规范软件开发流程,提高开发能力,在将来的某一天,通过自己的软件开发,为社会做出贡献。
十、技术路线图相关的5个仓库
1.biezhi/blade:一款轻量级、高性能、简洁优雅的MVC框架。
GitHub:https://github.com/lets-blade/blade
2..dyc87112/SpringCloud-Learning:SpringCloud的学习笔记和示例。
GitHub:https://github.com/dyc87112/SpringCloud-Learning
3.java-design-patterns :设计模式是形式化的最佳实践,程序员可以在设计应用程序或系统时使用它来解决常见问题。
GitHub:https://github.com/iluwatar/java-design-patterns
4.aaberg/sql2o:小而美的数据库操作框架,性能略屌。
GitHub:http://h5ip.cn/VtMw
5.ihaolin/diablo:分布式配置管理平台(看过代码,值得品读)。
github:http://h5ip.cn/sLXU

