

python - 文件操作
目录
文件的基本概念
什么是文件
文件是存放在外部介质(如硬盘,u盘)上面的一组完整信息的集合,这些信息可以为各种文字,图形,图像,电影,音乐,甚至包括病毒程序
两种重要的文件类型
文本文件(Text file)
文本文件是可以直接阅读的,使用记事本打开即可以看到文件的内容
二进制文件(Binary file)
这类文件将数据按照它的进制编码形式存储,由于这类文件内容是二进制编码,所以使用记事本打开是乱码
文本文件与二进制文件的优缺点:
文本文件:
优点:输出内容友好,不需要手动转换
缺点:一个字符占一个字节,文件占用存储空间较多,读写是需要转换(内存 ->显示),访问时的效率不高
###############################################
二进制文件:
优点:二进制文件中的数据与数据的内存中的表现形式一直,二进制文件在存储数据时非常紧凑,占用存储空间较少,在读写时不需要进行转换,具有较高的时间效率
缺点:二进制无法直接以字符形式输出,必须要经过一个转换的过程
python3中的数据类型
bytes
转换:bytes->str :
decode('utf8') 解码
str
转换:
str->bytes:
encode('utf8')
注意:encode编码时可指定任何合适的编码方式,但decode解码时,一定需要对应的编码方式
###############################################
例:
文件编码 ---》 就是人类语言与计算机语言的转化表
比如 ascll码 --》常见英文字符
unicode 万国码
encode编码时可指定任何合适的编码方式,
但decode解码时,一定需要对应的编码方式
>>> ord("中")
20013
>>> ord("国")
22269
utf-8 gbk 是unicode编码的具体实现方式,决定它在内存中怎么去存储
utf-8 一个中文字符占3个字节
gbk 一个中文字符占2个字符
以什么方式加码就要以什么方式解码,不然会出现乱码
>>> "中".encode("utf8")
b'\xe4\xb8\xad'
>>> "中".encode("gbk")
b'\xd6\xd0'
>>> "中".encode("gbk").decode("gbk")
'中'
>>> "中".encode("utf8").decode("utf8")
'中'
>>> "中".encode("utf8").decode("gbk")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 2: incomplete multibyte sequence
python2 的编码是ascll码
python3 的默认编码是utf8
文件的缓冲机制:
·读操作:不会直接对磁盘进行读取,而是先打开数据流,将磁盘上的文件信息拷贝到缓冲区内,然后程序再从缓冲区中读取所需数据·
写操作:不会马上写入磁盘中,而是先写入缓冲区,只有在缓冲区已满或“关闭文件”时,才会将数据写入磁盘
文件缓冲区:
·计算机系统为要处理的文件在内存中单独开辟出来的一个存储区间,在读写该文件时,做为数据交换的 临时“存储中转站”。
###############################################
文件的基本操作:
打开文件使用 open()函数
读取文件使用read
在读的过程中奖信息读到内存中去
但不会立刻写到磁盘里面去,
只有读/写文件的进程结束以后才会保存文件并释放内存空间
什么时候真正会写入磁盘?
1.缓冲区满了
2.读或写进程关闭
3.强制刷新 --》flush()
4.文件关闭的时候 --》 close()
open()函数:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
###############################################
open函数的参数
·file : 要打开的文件名( str )
·mode: 打开文件的方式( str ) => text, bytes
·encoding: 文件编码方式(str)
·errors: 当发生编码错误时的处理方式(str)
‘ignore’或’strict’(默认)
·buffering: 缓存方式 ( int)
几种常见的参数
flie : 要打开的文件
默认从哪个目录进入的python3,就从哪个目录查找要打开的文件
但也可以接文件所在的绝对路径

·mode: 打开文件的方式( str ) => text, byte
文件打开默认是文本类型
可以在mode参数里面加 b 来提示打开文本类型为二进制文件
例:
fp = open(text1.txt, rb)
读操作:r --》mode默认是读操作
覆盖写操作:w
追加写操作:a
新建写操作:x
###############################################
文件读取
fp.read() --> 从光标读到文件末尾
fp.readline() --> 从光标位置读到行末
rp.readlines() --> 从光标位置读到文件末尾,每一行作为一个元素放到列表里面
r是进行读操作,默认mode是r
>>>fp = open(text1.txt) >>>fp.read() 'aaa\nbbb\nccc\n'
open的读操作只会从光标所在地方开始往后读 所以在进行写操作以后,光标后面就没有内容了 所以不会有输出
>>> fp = open("text2.txt")
>>> fp.read()
'111111\n4524\n中文字符\n'
>>> fp.read()
''
>>> fp.seek(0)
0
>>> fp.read(6)
'111111'
>>> fp.read(6)
'\n4524\n'
>>> fp.read(4)
'中文字符'
>>> fp.read()
'\n'
>>> fp.seek(0)
0
>>> fp.readline()
'111111\n'
>>> fp.readline()
'4524\n'
>>> fp.readline()
'中文字符\n'
>>> fp.read()
''
>>> fp.seek(0)
0
>>> fp.readlines()
['111111\n', '4524\n', '中文字符\n']
大文件推荐使用readlines
readlines()的参数
输出 多少字节所在的行内容
>>> fp = open("text2.txt")
>>> fp.readlines(8)
['11111\n', '452422\n']
>>> fp.seek(0)
0
>>> fp.readlines(9)
['11111\n', '452422\n']
>>> fp.seek(0)
0
>>> fp.readlines(10)
['11111\n', '452422\n']
>>> fp.seek(0)
0
>>> fp.readlines(11)
['11111\n', '452422\n']
>>> fp.seek(0)
0
>>> fp.readlines(12)
['11111\n', '452422\n']
>>> fp.seek(0)
0
>>> fp.readlines(13)
['11111\n', '452422\n', '中文字符\n']###############################################
w覆盖写操作
原来的内容会被清空

1个英文字符等于一个字节,一个中文等于三个字节

a追加写入


###############################################
x 新建写入,



###############################################
mode的几种合法组合方式
r、rb、r+、rb+、w、wb、w+、wb+、a、ab、a+、ab+
###############################################
fp.seek(cookie,whence=0)
移动光标位置
cookie=> 偏移量
cookie为正表示向后面偏移
cookie为负表示向前面偏移
whence=> 相对位置
(0-> 开始, 1->当前, 2->末尾)
注意:1、2只能用b模式打开才可以
buffering 设置缓冲区
buffering=0 不缓存,实时写入
buffering=1 设置缓冲区为 1*4096个字节
buffering=2 设置缓冲区为2*4096个字节

###############################################
with 语句管理
with语句里面的内容执行完了,会自动关闭fp的连接
with open("E:\\text1.txt", "r") as fp:
for i in fp:
print("*"*20)
print(i)
fp.seek(0)
print(fp.read())###############################################
练习:
1.统计ip地址出现频率(京东二面题)
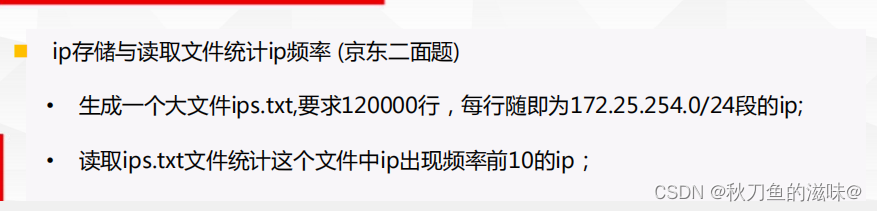
"""
@name : 统计频率前十的ip地址.py
@author : wangshenghu
@projectname: tlbb
@Date : 2022/3/6
"""
import random
with open("ips.txt", "w+") as fp:
# 生成120000行ip地址
for i in range(120000):
num1 = random.randint(1, 255)
num2 = "172.25.254." + str(num1) + "\n"
fp.write(num2)
# 将光标移到文本开头处
fp.seek(0)
dict1 = {}
for ip in fp:
# 去除首尾的\n符号
ip = ip.strip()
# 将ip地址写进字典dict1
if ip in dict1:
dict1[ip] += 1
else:
dict1[ip] = 1
top = 10
print("出现频率前十的ip地址:")
# 取字典值最大的前10个键值
print(sorted(dict1.items(), key=lambda x: x[1], reverse=True)[:top])
2.瓦尔登湖词频统计

"""
@name : 瓦尔登湖词频统计.py
@author : wangshenghu
@projectname: tlbb
@Date : 2022/3/6
"""
fp = open("Walden(1).txt", "r", encoding="utf-8").read()
fp = fp.lower()
for ch in fp:
if ch in '!"#$%&()*+,-./;:<=>?@[\\]^‘_{|}~':
fp = fp.replace(ch, " ")
# 指定分隔符为 " "
fp = fp.split(" ")
dict1 = {}
for i in fp:
if i.isalpha():
if i in dict1:
dict1[i] += 1
else:
dict1[i] = 1
else:
continue
print(dict1)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通