
This is my template for Algorithm Contest
// c11 编译器选项 -std=c++11
// 注意: 当设置为 false 时,cin 就不能和scanf,sscanf, getchar, fgets等同时使用。
// 取消cin和cout对于C语言的流同步 (这时尽量不要将两种输入输出混合)
ios::sync_with_stdio(false);
// 解除 cin 和 cout 运行库层面的对数据传输的默认绑定。由于存在数据传输的默认绑定, cin 和 cout 在每次操作的时候(也就是调用”<<”或者”>>”)都要刷新(调用flush),这样增加了IO的负担。通过解除绑定,可提高输入输出效率。
// cin构造出来就会调用cin.tie() 与cout绑定每次格式化输入都会调用cout.flush();导致效率低,可以使用该语句解绑
cin.tie(NULL);
cout.tie(NULL);
// 求最大值
auto it = max_element(std::begin(cloud), std::end(cloud)); // C++11
min_element同理
表示圆周率:#define PI acos(-1.0)
getline(cin, t) // 用C++读取一行
string b = "chi1 huo1 guo1", a = "1chi1 huo1 guo1";
a.find(b); // 若找到字串返回位置(0开始的索引), 否则返回-1
priority_queue<int> s2; // 默认大顶堆
priority_queue<int, vector<int>, greater<int>> s1; // 这里可以设置成小顶堆
// 底层哈希表(键有限制,只能int,string,double等,不能是自己定义的结构体
// 查询O(1) 修改O(logn)
unordered_map<string, int> ump;
// 底层红黑树(键无限制)
// 查询O(logn) 修改O(logn)
map<node, int> mp;
// cout 输出较大小数或特别大的数可能会输出科学计数法,这时前面需要加一个fixed
cout << fixed << setprecision(6) << n;
// lower表示等于 >=
int r = lower_bound(v.begin(), v.end(), x) - v.end();
// upper表示大于 >
int l = upper_bound(v.begin(), v.end(), y) - v.end();
// multiset 可以插入重复的数字,并且保证集合有序 插入和删除为O(logn), <set>库
multiset
/* 字符串处理 */
注意C++的字符串末尾也会加\0,但是他会放在a.size()这个位置上,所以原则上可以越界到这个位置
string a;
a = string("1234") // 字符串构造函数
a = string(cnt, '1') //赋值cnt个1构成的字符串给a
// i为起始坐标(从0开始),len为长度,获取字串
a.substr(i, len);
// 找子串,存在返回下标(0开始),不存在返回-1
a.find("haha");
// cctype中的东西
isalpha('a') // 判断是否为字母包括大小写
islower('a') // 判断是否为小写字母
isuppper('a') // 判断是否为大写字母
isalnum('a') // 判断是否为大小写字母或数字
isblank('a') // 判断是否为空格或制表符\t
isspace('a') // 判断是否为 space, \t, \r, \n
char t = tolower('A') // 转换小写
char t = toupper('a') // 转换为大写
string n = to_string(123) // 转换为字符串 可以是int float double 等
string str = "123";
int a = stoi(str); // 将字符串转变为数(注意若str是非法的,那么stoi将会读取到非数字为止)
string str2 = "123.4"
double b = stod(str); // 将字符串转变为double型,若非法,自动截取前面的浮点数,非法为止,若前面不是数字或小数点发生运行错误,若前面是小数点会转化后在前面自动补0
// 类似的还有
stof (string to float)
stold (string to long double)
stol (string to long)
stoll (string to long long)
stoul (string to unsigned long)
stoull (string to unsigned long long)
Basic algorithm
前缀异或
由异或性质(结合律)$a \oplus (b \oplus c) = (a \oplus b) \oplus c$, $a \oplus a = 0$, 因此对于给定的区间异或假设我们有一个前缀异或函数$f(i)$, 那么对于区间$[l, r]$的异或,我们可以得到$Xor(i, j) =f(j) \oplus f(i - 1)$
前缀和
O(1) 对矩阵求和
#include <iostream>
#include <cstring>
using namespace std;
const int N = 1e3 + 5;
int main() {
int n, m, q, a[N][N], sum[N][N]; cin >> n >> m >> q;
for (int i = 1; i <= n; i ++) for (int j = 1; j <= m; j ++) {
cin >> a[i][j];
sum[i][j] = sum[i - 1][j] + sum[i][j - 1] - sum[i - 1][j - 1] + a[i][j];
}
while(q --) {
int x1, y1, x2, y2; cin >> x1 >> y1 >> x2 >> y2;
cout << sum[x2][y2] - sum[x1 - 1][y2] - sum[x2][y1 - 1] + sum[x1 - 1][y1 - 1] << endl;
}
}
差分
O(1) 对矩阵操作 + - * /
#include <iostream>
#include <cstring>
#include <iostream>
using namespace std;
const int N = 1e3 + 5;
int diff[N][N];
// 差分矩阵主要记住insert就行了,相当于输入打标记,区间打标记
void insert(int x1, int y1, int x2, int y2, int c) {
diff[x1][y1] += c, diff[x1][y2 + 1] -= c, diff[x2 + 1][y1] -= c, diff[x2 + 1][y2 + 1] += c;
}
int main() {
int n, m, q, a[N][N]; cin >> n >> m >> q;
for (int i = 1; i <= n; i ++) for (int j = 1; j <= m; j ++) {
cin >> a[i][j], insert(i, j, i, j, a[i][j]);
}
while(q --) {
int x1, y1, x2, y2, c; cin >> x1 >> y1 >> x2 >> y2 >> c;
insert(x1, y1, x2, y2, c);
}
for (int i = 1; i <= n; i ++) for (int j = 1; j <= m; j ++)
cout << (diff[i][j] += diff[i - 1][j] + diff[i][j - 1] - diff[i - 1][j - 1]) << "\0 \n "[2 * (i != n) + (j != m)];
}
位运算
异或
\(a \oplus a = 0\)
\(0 \oplus a = a\)
\(a \oplus b = b \oplus a\)
\(a \oplus (b \oplus c) = (a \oplus b) \oplus c\)
\(a \oplus b = c\) , then \(a \oplus c = b\)
变量交换
\(a = a \oplus b\), \(b = a \oplus b\), \(a = a \oplus b\)
排除重复里面的不重复(唯一一个不重复的)
对于任意的\(arr[i]\), 进行异或,最终得到的结果便是唯一不重复的数字
二分
// 区间[l, r]被划分成 [l, mid] 和 [mid + 1, r] 时
int bsearch(int x) {
while (l < r) {
int mid = l + r >> 1;
if (check(mid)) r = mid;
else l = mid + 1;
}
}
// l = mid时,补上 + 1 (l + r + 1 >> 1)
// 补上加以等同于四舍五入,保证了mid不会等于l,从而导致l被重复赋值为l造成死循环
// 区间[l, r]被划分成 [l, mid - 1] 和 [mid, r] 时
int bsearch(int x) {
while (l < r) [
int mid = l + r + 1 >> 1;
if (check(mid)) l = mid;
else r = mid - 1;
]
}
// 浮点数二分
const double EPS = 1e-8;
dobule b_search(double n) {
double l = -1000, r = 1000;
while (r - l >= EPS) {
double mid = (l + r) / 2;
if (mid * mid * mid >= n) r = mid;
else l = mid;
}
}
// 也可以直接迭代指定次数
for (int i = 1; i <= 100; i ++) {
double mid = (l + r) / 2;
if (check(mid)) r = mid;
else l = mid;
}
Some suffixes
1. Qucikly read for const numbers
#include <bits/stdc++.h>
#define rep(i, j, k) for(int i = j; i <= k; i ++)
#define per(i, j, k) for(int i = j; i >= k; i --)
#define lc p<<1
#define rc p<<1|1
#define f first
#define s second
#define pb(x) push_back(x)
#define ll long long
using namespace std;
const int N = 1e7 + 10;
char buf[1 << 21], *p1 = buf, *p2 = buf;
// p1 means start point and p2 means end point
inline char gc(){
if (p1 == p2){
// fread return real count
p2 = (p1 = buf) + fread(buf, 1, 1 << 21, stdin);
}
return *p1 ++;
}
// gc can be replaced by function getchar.
inline int read(){
int s = 0, w = 1;
char ch = gc();
while (ch < '0' || ch > '9'){
if (ch == '-') w *= - 1;
ch = gc();
}
while ('0' <= ch && ch <= '9'){
s = (s << 1) + (s << 3) + (ch ^ 48);
ch = gc();
return s * w;
}
}
int main()
{
int n, t;
ll sum = 0;
cin >> n;
rep (i, 1, n){
t = read();
if (i > 1){
sum ^= t;
}else{
sum = t;
}
}
cout << sum;
}
2. Header
#include <iostream>
#include <cstring>
#include <cmath>
#include <stack>
#include <queue>
#include <map>
#include <set>
#include <bitset>
#include <algorithm>
#include <functional>
#include <utility>
#include <unordered_set>
#include <unordered_map>
#define INF 0x3f3f3f3f
#define siz(x) (int)x.size()
#define IOS ios::sync_with_stdio(false);
#define rep(i, j, k) for(int i = j; i <= k; ++ i)
#define per(i, j, k) for(int i = j; i >= k; -- i)
#define dbg1(a) cout << a << endl;
#define dbg2(a, b) cout << a << " " << b << endl;
#define dbg3(a, b, c) cout << a << " " << b << " " << c << endl;
#define pb(x) push_back(x)
#define eb(x) emplace_back(x)
#define all(x) x.begin(), x.end()
#define f first
#define s second
#define FASTIO \
std::ios ::sync_with_stdio(0); \
std::cin.tie(0); \
std::cout.tie(0);
#define lc p<<1
#define rc p<<1|1
using namespace std;
typedef long long LL;
typedef priority_queue<int, vector<int>, greater<int>> S_HEAP;
typedef priority_queue<int> B_HEAP;
typedef pair<string, int> PSI;
typedef pair<int, int> PII;
const int N = 1e5 + 10;
First : Tree
1. Heap
## Insert Establish
void PushUp(int i){
if (i == 1) return;
while (i != 1){
if (heap[i] < heap[i / 2]) swap(heap[i], heap[i / 2]), i /= 2;
else break;
}
}
int n;
for (int i = 1; i <= n; i ++){
PushUp(i);
}
## Establish via binary tree
void AdjustHeap(int a[], int i, int n){
for (i = i * 2; i <=n; i *= 2){
if (i < n && a[i + 1] < a[i]) i ++;
if (a[i] < a[i / 2]) swap(a[i], a[i / 2]);
else break;
}
}
void build(int a[], int p, int n){
for (int i = n / 2; i >= p; i --){
AdjustHeap(a, i, n);
}
}
## Delete root Elements
sawp(a[1], a[len + 1]);
AdjustHeap(a, 1, n - 1)
2. Segment Tree
#include <bits/stdc++.h>
#define rep(i, j, k) for (int i = j; i <= k; i ++)
#define per(i, j, k) for (int i = j; i >= k; i --)
#define ll long long
#define lc p<<1
#define rc p<<1|1
using namespace std;
const int N = 1e5 + 10;
ll w[N];
struct node{
ll l, r, sum, add;
}tr[4 * N];
void pushup(int p){
tr[p].sum = tr[rc].sum + tr[lc].sum;
}
void pushdown(int p){
if (tr[p].add){
tr[rc].sum += (tr[rc].r - tr[rc].l + 1) * tr[p].add;
tr[lc].sum += (tr[lc].r - tr[lc].l + 1) * tr[p].add;
tr[lc].add += tr[p].add;
tr[rc].add += tr[p].add;
tr[p].add = 0;
}
}
void build(int p, int l, int r){
tr[p] = {l, r, w[l], 0};
if (l == r) return;
int m = l + r >> 1;
build(lc, l, m);
build(rc, m + 1, r);
pushup(p);
}
void update(int p, int l, int r, int k){
if (tr[p].l >= l && tr[p].r <= r){
tr[p].sum += (tr[p].r - tr[p].l + 1) * k;
tr[p].add += k;
return;
}
int m = tr[p].l + tr[p].r >> 1;
pushdown(p);
if (l <= m) update(lc, l, r, k);
if (r > m) update(rc, l, r, k);
pushup(p);
}
ll query(int p, int l, int r){
if (tr[p].l >= l && tr[p].r <= r)
return tr[p].sum;
int m = tr[p].l + tr[p].r >> 1;
ll sum = 0;
pushdown(p);
if (l <= m) sum += query(lc, l, r);
if (r > m) sum += query(rc, l, r);
return sum;
}
int main()
{
int n, m;
cin >> n >> m;
rep (i, 1, n){
cin >> w[i];
}
build(1, 1, n);
rep (i, 1, m){
int c, x, y, z;
cin >> c;
if (c == 1){
cin >> x >> y >> z;
update(1, x, y, z);
}
else{
cin >> x >> y;
cout << query(1, x, y) << endl;
}
}
}
## lazytag
3. Cartesian Tree
For the best description about Cartesian Tree. The first time I read about it was sophisticated to understand.
Cartesian Tree is a tree defined by the BST and the Heap(min), so if the tree is BST and Heap(min), that is a Cartesian Tree.
What about the algorithm?
Look it at OIWIKI.
#include <bits/stdc++.h>
#include <cmath>
#define f first
#define s second
#define pb(x) push_back(x)
#define ll long long
#define pii pair<int, int>
#define psi pair<string, int>
#define rep(i, j, k) for (int i = j; i <= k; ++ i)
#define per(i, j, k) for (int i = j; i >= k; -- i)
#define lc p<<1
#define rc p<<1|1
using namespace std;
const int N = 100;
int st[N], ls[N], rs[N], q[N], tt, n, a[N];
bool has_fa[N];
void bfs(int root){
int hh, tt;
hh = tt = 0;
q[0] = root;
while (hh <= tt){
int t = q[hh ++];
if (ls[t]) q[ ++ tt] = ls[t];
if (rs[t]) q[ ++ tt] = rs[t];
cout << a[t] << " ";
}
}
int main()
{
int n;
cin >> n;
rep (i, 1, n) cin >> a[i];
rep (i, 1, n){
int k = tt;
while (k > 0 && a[st[k]] > a[i]) k --;
if (k) rs[st[k]] = i, has_fa[i] = true;
if (k < tt) ls[i] = st[k + 1], has_fa[st[k + 1]] = true;
st[++k] = i;
tt = k;
}
int root = 1;
while (has_fa[root]) root ++;
bfs(root);
}
Graph
1. Topological sort (Kath)
bool toposort(){
queue<int> q;
rep (i, 1, n)
if (!din[i]) q.push(i);
while (q.size()){
int x = q.front(), cnt = 0, tmp[N]; q.pop();
tp.push_back(x);
for (auto y : v[x]){
if (-- din[y] == 0) q.push(y);
}
}
if (tp.size() == n) return 1;
else return 0;
}
2. Topological sort (DFS)
bool dfs(int x){
c[x] = -1;
for (int y : e[x]){
if (c[y] < 0) return 0;
else if (!c[y])
if (!dfs[y]) return 0;
}
c[x] = 1;
tp.push_back(x);
return 1;
}
bool toposort(){
memset(c, 0, sizeof(c));
rep (x, 1, n){
if (!c[x])
if (!dfs(x)) return 0;
}
reverse(tp.begin(), tp.end());
return 1;
}
3. Dijkstra (normal)
#include <iostream>
#include <cstring>
#include <vector>
#define f first
#define s second
#define pb(x) push_back(x)
#define rep(i, j, k) for (int i = j; i <= k; ++ i)
#define Inf 0x3f3f3f3f
using namespace std;
const int N = 1e4 + 10;
struct edge{int v, w;};
bool st[N];
int dist[N], pre[N], n, m, s;
vector<edge> g[N];
void dijkstra(int s){
memset(dist, 0x3f, sizeof(dist));
dist[s] = 0;
rep (i, 1, n - 1){
int u = -1;
rep (j, 1, n)
if (!st[j] && (u == -1 || dist[j] < dist[u])) u = j;
st[u] = 1;
for (auto x : g[u]){
int v = x.v, w = x.w;
if (dist[v] > dist[u] + w)
pre[v] = u;
dist[v] = dist[u] + w;
}
}
}
void dfs_path(int u){
if (u == 1){
printf("%d", u);
}
dfs_path(pre[u]);
printf("->%d", u);
}
int main()
{
cin >> n >> m >> s;
rep(i, 1, m){
int u, v, w;
cin >> u >> v >> w;
g[u].push_back({v, w});
}
dijkstra(s);
rep (i, 1, n){
if (dist[i] == Inf) cout << (1<<31) - 1 << " ";
else cout << dist[i] << " ";
}
}
4. Dijkstra (Heap)
#include <bits/stdc++.h>
#define pii pair<int, int>
#define f first
#define s second
#define pb(x) push_back(x)
#define rep(i, j, k) for (int i = j; i <= k; ++ i)
#define Inf 0x3f3f3f3f
using namespace std;
const int N = 1e5 + 10;
struct edge{int v, w;};
bool st[N];
int dist[N], pre[N], n, m, s;
vector<edge> g[N];
priority_queue<pii> q;
void dijkstra(int s){
memset(dist, 0x3f, sizeof(dist));
dist[s] = 0, q.push({0, s});
while (q.size()){
auto t = q.top(); q.pop();
int u = t.s;
if (st[u]) continue;
st[u] = 1;
for (auto x : g[u]){
int v = x.v, w= x.w;
if (dist[v] > dist[u] + w){
pre[v] = u;
dist[v] = dist[u] + w;
q.push({-dist[v], v});
}
}
}
}
void dfs_path(int u){
if (u == 1){
printf("%d", u);
return;
}
dfs_path(pre[u]);
printf("->%d", u);
}
int main()
{
cin >> n >> m >> s;
rep(i, 1, m){
int u, v, w;
cin >> u >> v >> w;
g[u].push_back({v, w});
}
dijkstra(s);
rep (i, 1, n){
if (dist[i] == Inf) cout << (1<<31) - 1 << " ";
else cout << dist[i] << " ";
}
}
5. Bellman-ford
int bellman_ford(){
memset(dist, 0x3f, sizeof(dist)); // init data
dist[1] = 0;
bool flag;
rep (i, 1, n){ // n times loop
flag = false;
rep (j, 0, m - 1){ // then travese all the vertex in the graph
int a = edges[j].a, b = edges[j].b, w = edges[j].w;
if (dist[b] < dist[a] + w) // realex the edge by the other edge
dist[b] = dist[a] + w, flag = true;
}
}
if (flag) cout << "The graph has negative circle!"; // judge the negative circle
if (dist[n] > 0x3f3f3f3 / 2) return -1; // if the vertex can't be reach from source point
return dist[n];
}
6. SPFA
dfs_path(int u){
if (u == 1) {
printf("%d", u);
return;
}
dfs_path(pre[u]);
printf("->%d", u);
}
bool spfa(int s){
queue<int> q;
d[s] = 0, q.push(s), st[s] = 1;
while (q.size()){
int x = q.front();
q.pop(), st[x] = 0;
for (auto y : e[x]){
int v = y.v, w = y.w;
if (d[v] > d[x] + w){
d[v] = d[x] + w;
pre[v] = x;
cnt[v] = cnt[x] + 1;
if (cnt[v] >= n) return true; // if the graph has negative circle the func will return true value
if (!st[v]) q.push(v), st[v] = 1;
}
}
}
return false;
}
// if you the source vertex can't reach the negative circle, you should put all the vertex to queue
bool spfa(){
memset(d, 0x3f, sizeof(d));
rep(i, 1, n) q.push(i), st[i] = 1;
while (q.size()){
int x = q.front();
q.pop(), st[x] = 0;
for (auto y : e[x]){
int v = y.v, w = y.w;
if (d[v] > d[x] + w){
d[v] = d[x] + w;
cnt[v] = cnt[x] + 1;
if (cnt[v] >= n) return true; // the negative circle is true
if (!st[v]) q.push(v), st[v] = 1;
}
}
}
return false; // not have any negative circle
}
7. Floyd
#include <bits/stdc++.h>
#define rep(i, j, k) for (int i = j; i <= k; ++ i)
#define pii pair<int, int>
#define Inf 0x3f3f3f3f
using namespace std;
const int N = 201, M = 1e4 + 10;
int d[N][N], p[N][N], n, m, k;
void floyd(){
rep (k, 1, n)
rep (i, 1, n)
rep (j, 1, n)
if (d[i][j] < d[i][k] + d[k][j])
d[i][h] = d[i][k] + d[k][j], path[i][j] = k;
}
void path(int i, int j){
if (p[i][j] == 0) return;
int k = p[i][j];
path(i, k);
printf("%d->", k);
path(k, j);
}
int main(){
cin >> n >> m >> k;
rep (i, 1, n)
rep (j, 1, n)
if (i == j) d[i][j] = 0;
else d[i][j] = Inf;
rep (i, 1, m){
int a, b, c;
cin >> a >> b >> c;
d[a][b] = min(d[a][b], c);
}
floyd();
while (k --){
int a, b;
cin >> a >> b;
if (d[a][b] > Inf / 2) cout << "impossible" << endl;
else cout << d[a][b] << endl;
}
// print the most shortest path
int a, b;
cin >> a >> b;
cout << a << "->";
path(a, b);
cout << b << endl;
}
8. Kruskal
#include <bits/stdc++.h>
#define rep(i, j, k) for (int i = j; i <= k; ++ i)
#define pii pair<int, int>
#define Inf 0x3f3f3f3f
using namespace std;
const int N = 5010, M = 1e5 + 10;
int p[N], cnt, n, m, ans;
struct edge{
int u, v, w;
bool operator<(const edge &t) const{
return w < t.w;
}
}e[4 * M];
int find(int x){
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
bool kruskal(){
sort(e, e + m);
rep(i, 1, n) p[i] = i;
rep (i, 0, m - 1){
int fa = find(e[i].u), fb = find(e[i].v);
if (fa != fb){
p[fa] = fb;
ans += e[i].w;
cnt ++;
}
}
return cnt == n - 1;
}
int main(){
cin >> n >> m;
int num = 0;
rep (i, 0, m - 1){
int a, b, c;
cin >> a >> b >> c;
e[num ++] = {a, b, c};
e[num ++] = {b, a, c};
}
m = num;
if (kruskal()) cout << ans;
else cout << "orz";
}
9. Prim (normal)
#include <bits/stdc++.h>
#define rep(i, j, k) for (int i = j; i <= k; ++ i)
#define pii pair<int, int>
#define Inf 0x3f3f3f3f
using namespace std;
const int N = 5010, M = 1e5 + 10;
int d[N], st[N], ans, cnt, n, m;
struct edge{int v, w;};
vector<edge> e[N];
bool prim(int s){
memset(d, 0x3f, sizeof(d));
d[s] = 0;
rep (i, 1, n){
int u = 0;
rep (j, 1, n)
if (!st[j] && d[j] < d[u]) u = j;
st[u] = 1;
ans += d[u];
if (d[u] != Inf) cnt ++;
for (auto y : e[u]){
int v = y.v, w = y.w;
if (d[v] > w) d[v] = w;
}
}
return cnt == n;
}
int main(){
int num = 0;
cin >> n >> m;
rep (i, 1, m){
int a, b, c;
cin >> a >> b >> c;
e[a].push_back({b, c});
e[b].push_back({a, c});
}
if (prim(1)) cout << ans;
else cout << "impossible";
}
10. Prim(Heap)
#include <bits/stdc++.h>
#define s second
#define f first
#define rep(i, j, k) for (int i = j; i <= k; ++ i)
#define pii pair<int, int>
#define Inf 0x3f3f3f3f
using namespace std;
const int N = 5010, M = 1e5 + 10;
int d[N], st[N], ans, cnt, n, m;
struct edge{int v, w;};
vector<edge> e[N];
priority_queue<pii> q;
bool prim(int s){
memset(d, 0x3f, sizeof(d));
d[s] = 0, q.push({0, s});
while (q.size()){
int u = q.top().s; q.pop();
if (st[u]) continue;
st[u] = 1, ans += d[u], cnt ++;
for (auto y : e[u]){
int v = y.v, w = y.w;
if (d[v] > w){
d[v] = w;
q.push({-d[v], v});
}
}
}
return cnt == n;
}
int main(){
int num = 0;
cin >> n >> m;
rep (i, 1, m){
int a, b, c;
cin >> a >> b >> c;
e[a].push_back({b, c});
e[b].push_back({a, c});
}
if (prim(1)) cout << ans;
else cout << "impossible";
}
11. Dyeing about Bipartite Graph
#include <bits/stdc++.h>
#define s second
#define f first
#define rep(i, j, k) for (int i = j; i <= k; ++ i)
#define pii pair<int, int>
#define Inf 0x3f3f3f3f
using namespace std;
const int N = 1e5 + 10, M = 2 * (1e5 + 10);
int h[N], e[M], ne[M], idx, n, color[N], m;
void add(int a, int b){
e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}
inline bool dfs(int u, int c){
color[u] = c;
for (int i = h[u]; i != -1; i = ne[i]){
int j = e[i];
if (color[j] == -1){
if (!dfs(j, !c)) return false;
}
else if (color[j] == c) return false;
}
return true;
}
inline bool check(){
memset(color, -1, sizeof(color));
bool flag = true;
rep (i, 1, n){
if (color[i] == -1){
if (!dfs(i, 0)){
flag = false;
break;
}
}
}
return flag;
}
int main(){
memset(h, -1, sizeof(h));
cin >> n >> m;
rep (i, 1, m){
int a, b;
cin >> a >> b;
add(a, b);
add(b, a);
}
if (check()) puts("Yes");
else puts("No");
}
12. Hungarian algorithm
#include <bits/stdc++.h>
#define s second
#define f first
#define rep(i, j, k) for (int i = j; i <= k; ++ i)
#define pii pair<int, int>
#define Inf 0x3f3f3f3f
using namespace std;
const int N = 1e5 + 10, M = 1e5 + 10;
int h[N], e[M], ne[M], match[N], idx, n, m, k, ans;
bool st[N];
void add(int a, int b){
e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}
bool dfs(int u){
for (int i = h[u]; i != -1; i = ne[i]){
int j = e[i];
if (!st[j]){
st[j] = true;
if (!match[j] || dfs(match[j])){
match[j] = u;
return true;
}
}
}
return false;
}
int main(){
memset(h, -1, sizeof(h));
cin >> n >> m >> k;
rep (i, 0, k - 1){
int a, b;
cin >> a >> b;
add(a, b);
}
rep (i, 1, n){
memset(st, 0, sizeof(st));
if (dfs(i)) ans ++;
}
cout << ans;
}
13.DSU
/* DSU + 维护size + 权值 */
// init
for(int i = 1; i <= n; i ++) p[i] = i, siz[i] = 1;
// find fuc
int find(int x) {
if(x != p[x]) {
int t = find(p[x]);
d[x] += d[p[x]];
p[x] = t;
}
}
// add fuc
void add(int x, int y, int k) {
if(find(x) != find(y))
siz[find(y)] += siz[find(x)];
p[find(x)] = find(y);
val[find(x)] += -val[x] + val[y] + s;
}
String
1. KMP
#include <bits/stdc++.h>
#include <cstring>
#include <cmath>
#define ll long long
#define f first
#define s second
#define Inf 0x3f3f3f3f
#define NInf -0x3f3f3f3f
#define pii pair<int, int>
#define rep(i, j, k) for(int i = j; i <= k; ++ i)
#define per(i, j, k) for(int i = j; i >= k; -- i)
using namespace std;
const int N = 1e6 + 10;
int ne[N];
void init_kmp(char p[], int m){
ne[1] = 0;
for (int i = 2, j = 0; i <= m; ++ i){
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[j + 1] == p[i]) j ++;
ne[i] = j;
}
}
void kmp(char a[], char p[], int n, int m){
for (int i = 1, j = 0; i <= n; ++ i){
while (j && p[j + 1] != a[i]) j = ne[j];
if (a[i] == p[j + 1]) j ++;
if (j == m) cout << i - j + 1 << endl;
}
}
int getlen(char a[]){
int i = 1;
while (a[i]) i ++;
return i - 1;
}
int main(){
char a[N], p[N];
cin >> a + 1 >> p + 1;
int n = getlen(a), m = getlen(p);
init_kmp(p, m);
kmp(a, p, n, m);
cout << ne[1];
rep (i, 2, m) cout << " " << ne[i];
}
Math
基本定理
可看,唯一分解定理(算数基本定理)
\(x = p^{a_1} \times p ^{a_2} \times ... \times p^{a_n}\) (p为x的素因子), 该分解式对于任意的正整数(\(x\ge2\))唯一
约数个数:\(\prod \limits_{i = 1}^n (a_i + 1)\)
约数之和:\(\prod \limits_{i=1}^n \sum \limits_{j=0}^{a_j} p_i^{j}\)
完全平方数的约数个数为奇数个, 因为约数成对存在, 证毕
\([1, n]\)的完全平方数为\(\sqrt{n}\)个, 显然 这不用证明 因为每个数都是完全平方数的约数
Basic operator
\(a\mid b\) : a能够整除b, b能够被a整除
\(a \nmid b\) : a不能够整除b, b不能够被a整除
带余数除法: 若a,b时两个整数,其中b>0,则存在两个整数q及r,使得
\(a=bq + r\) 且 \(0 \leq r \textless b\) , 且q和r唯一, 此处b时商,r是余数
(0除以任何不为0的数都等于0, 0不能作为除数)
模运算
$(a + b) \bmod m = (a \bmod m + b \bmod m) \bmod m $
\((a-b) \bmod m = (a \bmod m - b \bmod m) \bmod m\)
\((a*b)\bmod m = ((a \bmod m) * (b \bmod m)) \bmod m\)
通常为了规避减法异号的情况,我们通常这样操作
\((a-b) \bmod m = ((a \bmod m) - (b \bmod m) + m) \bmod m\)
除法的取模需要使用 逆元
上取整与下取整
int x = 9, y = 3;
// 上取整
int res = (x - 1) / y ;
// 下取整
int res = x / y;
// 四舍五入
int res = (x + y / 2) / y;
也可以用cmath的库函数, 但是必须保证传入为double即 小数
// 上取整
int res = ceil((x * 1.0) / y);
// 下取整
int res = floor((x * 1.0) / y);
// 四舍五入
int res = round((x * 1.0) / y);
向上取整证明

预处理MAXN之前的数的约数
void init() {
for(int i = 1; i <= MAXN; i ++) {
for(int j = i; j <= MAXN; j += i) {
factors[j].push_back(i);
}
}
}
快速幂
\(O(\sqrt{n})\) n为指数
分治
double fast_pow(double a, int n) {
if (n == 1) return a;
double t = fast_pow(a, n / 2);
if (n % 2 == 1) return t * t * a;
else return t * t;
}
Bit
\(O(logn)\)
int fast_pow(double a, int b) {
double ans = 1;
while (b) {
if (b & 1) ans *= a;
a *= a;
b>>=1;
}
return ans;
}
康托展开
GCD-最大公因数
GCD and LCM properties
更相损减术:\(\gcd(a,b) = \gcd(b, a-b)\)
辗转相除法:\(\gcd(a,b) = \gcd(b,a \bmod b)\)
证明:\(d\mid a, d \mid b\)等价于\(d\mid(a-b)\), \(d|b\)(充要条件)
LCM最小公倍数: \(lcm(a,b) = \frac{a*b}{\gcd(a,b)}\) 常记为 \([a,b]\)
-
可重复贡献
\(\gcd(a, b, c) = \gcd(\gcd(a, b), c) = \gcd(a, \gcd(b, c))\) (可以推广到n个数的情况)
-
\(\gcd(a, 0) = a\)
-
\(\gcd(a, b) = \gcd(a, -b)\)
-
\(\gcd(x, x-1) = 1\)
LCM的一些性质:
- \(lcm(a,b)\), 若a或b为质数,则\(lcm(a, b) = a * b\);
- \(lcm(a,b)\), 若\(b \mid a\), 则\(lcm(a,b) = a\)
- \(lcm(x, x - 1) = x * (x - 1)\)
常用构造题:
对于给定的a, b在某个区间, 这里假设
\(l \le a, b\le r\)
- \(lcm(a,ka)\) 使lcm最小
- \(lcm(a,b)\), \(gcd(a,b) = 1\), 使\(lcm\)最大
证明:
假定\(a \le b\),
- \(b \bmod a = 0\),\(lcm(a,b) = b\), \(l \le b \le r\)
- \(b \bmod a \ne 0\), \(lcm(a,b) \ge 2 * b\) \(ie. 2 * l \le lcm \le 2 * r\)
辗转相除法
辗转相除法:\(\gcd(a,b) = \gcd(b,a \bmod b)\)
证明: 描述a与b的带余数除法关系,\(a = kb + r\)
设d为a和b的因数, 有\(d \mid a\), \(d \mid b\), 因为\(r = a - kb\) , 所以 \(d|r\),
因此d是\(b, r\)的公约数(为什么不写成\(a, r\), 因为\(r = a - kb\) 的因子有可能超出b的因子范围,如\(6 * 5\) 此时6也可以作为因子,所以为了限制该条件我们用b来作为另一个数)
因此\(gcd(a,b) = gcd(b, a \bmod b)\)
int gcd(int a, int b) {return b == 0?a:gcd(b, a % b);}
裴蜀定理
设a,b是不全为零的整数,则存在整数x,y使得 \(ax + by = \gcd(a, b)\)
(可以理解为,该方程有解,且为最小正元)
#include <iostream>
#include <vector>
using namespace std;
int gcd(int a, int b) {
return b == 0?a:gcd(b, a % b);
}
int main() {
int n, last; cin >> n;
vector<int> a(n);
last = 0;
for (int i = 0; i < a.size(); i ++) {
cin >> a[i];
if (a[i]<0) a[i]*=-1;
last = gcd(last, a[i]);
}
cout << last;
}
类欧几里得算法
类似于欧几里得形式的算法, 需要求出f(a,b), 通过变换形式,使问题规模越来越小,最终求得解。
扩展欧几里得算法
考虑一个二元一次不定方程: \(ax + by = c\) (a, b, c为整数且a, b都不为0)
定理1: 设它有整数解\(x = x_0, y = y_0,\)则一切整数解可以写成\(x = x_0 - b_1t, y = y_0 + a_1t,\space(t = 0, 1, -1, 2, -2, ...)\) 其中\(b_1 = \frac{a}{\gcd(a, b)}\), $a_1 = $$\frac{b}{\gcd(a,b)}$
证明:
充分性: 已知\(ax_0 + by_0 = c,\) 可得\(a(x_0 - b_1t) + b(y_0 + a_1t) = ax_0 + by_0 + t(ba_1-ab_1) = ax_0 + by_0 = c\)
必要性: 设\(x', y'\)是\(ax+by=c\)的任意解, 则\(ax' + by' = c\)已知\(ax_0 + by_0 =c\)两式相减,得\(a(x' - x_0) + b(y' - y_0) = 0\), 除公因数,得\(a_1(x'-x0) = -b_1(y' - y_0)\), 观察式子, 既然\(a_1\)与\(b_1\)互质,那么$ a_1 \mid (y'-y_0) \(. 可得\)y'=y_0 + a_1t\(. 同理可得\)x'=x_0-b_1t$
定理2:一般式\(ax+by = c\) 有整数解的充要条件是\(\gcd(a, b) | c\)
证明:
必要性:若有整数解则\(\gcd(a,b)|(ax + by)\), 故\(\gcd(a,b)|c\)
充分性:若\(\gcd(a,b)|c\)则由裴蜀定理 \(ax+by=\gcd(a,b)\) 一定存在解,则对其解乘以\(\frac{c}{\gcd(a,b)}\) 便为\(ax+by=c\)的解
因此对于任给的\(ax+by=c\) 且 \(\gcd(a,b) \mid c\),则找到 了一组特解,便可以得到所有解.
求 \(ax_1 + by_1 = \gcd(a, b)\)
思路:
求\(ax_1+by_1=\gcd(a,b)\), 由于\(\gcd(a,b)==\gcd(b, a \bmod b)\),我们可以先求出\(bx_2 +(a \bmod b)y_2=\gcd(b, a \bmod b)\)的解,再通过找到这两条式子的解的关系而得出原式子的解。
关系:\(x_1 = y_2, y_1 = x_2 - \lfloor a/b \rfloor * y_2\)
证明:\(ax_1 + by_1 = \gcd(a,b) = \gcd(a, a \bmod b) = bx_2 + (a \bmod b)y_2 = bx_2 + (a - \lfloor a / b \rfloor * b)y_2=ay_2+b(x_2 - \lfloor a / b \rfloor y_2)\)
在通过类欧几里得算法得到该特解后,那么我们根据定理1 即可求得所有解。
扩展欧几里得也可以用来求线性同余式。
CODE:
int exgcd(int a, int b, int &x, int &y) {
if (b == 0) {
x = 1, y = 0; // 得到一组解返回,然后通过解的关系得到通解
return a;
}
int d = exgcd(b, a % b, x ,y);
int tmp = x;
x = y,y = tmp - a / b * y;
return d;
}
同余和逆元
同余
定义:给定一个正整数m,把他叫做模,如果用m对任意两个正整数a,b取模所得余数相同,我们就说a,b对模m同余,记作\(a \equiv b \pmod m\),取模所得余数不同记作\(a \not \equiv b \pmod m\)
$a \bmod m = b \bmod m 等价于 a \equiv b (\bmod m) $
第二定义:若\(m \mid a-b\), 则a,b叫做对模m同余
性质1:若 \(a \equiv b \pmod m\) , 则 \(\gcd(a,m) = \gcd(b, m)\)
性质2:若 \(a \equiv b \pmod m\), 则\(ka \equiv kb \pmod m\)
性质3:若\(a \equiv b \pmod m\), 则\(a = da_1, b = db_1, \gcd(d, m) = 1\) 则 \(a_1 \equiv b_1 \pmod m\)
同余式
定义:若用\(f(x)\)表示系数为整数的多项式;又设m是一个正整数,则\(f(x) \equiv 0 \pmod m\) 叫做模m的同余式。一次同余式:\(ax \equiv b \pmod m, a \not \equiv 0 \pmod m\)
使同余式成立的x叫做该式的一个解。
定理:一次同余式(又叫线性同余方程)由解的充要条件是\(\gcd(a, m) \mid b\)
证:一次同余式可以写成\(ax=my+b\). 移项,得\(ax-my=b\), 因\(y\)无关紧要, 令\(y = -y\),得\(ax+my=b\).一条二元一次不定方程。由定理2,证毕。
逆元
方程\(ax \equiv 1 \pmod m\)的一个解\(x\),称\(x\)为a模m的逆元。其中\(\gcd(a,m)=1\)
由同余性质,因为\(\gcd(a, m) = 1\) 上述等式可以写成 \(x \equiv \frac{1}{a} \pmod m\)
逆元的一个重要应用就是求除法的模 (k为b的逆元)
\(\because (kb \bmod m) = 1\)
\(\frac{a}{b} \bmod m = ((\frac{a}{b} \bmod m)(kb \bmod m)) \bmod m = ak \bmod m\)
逆元求法:
- 扩展欧几里得定理解方程
- 费马小定理
直接用快速幂求\(a^{p-2}\), 注意\(p\)是质数, 另外\(a \bmod p = 0\)时无解。
费马小定理
若p是素数,则\(a^p \equiv a \pmod p\)
因为 \(\gcd(a, p) = 1\), 由同余性质,上述式子也可以写成\(a^{p-1} \equiv 1 \pmod p\)
定理证明:
集合\(\left\{ 1,2,3...p-1 \right\}\)中的每一个数模p的值互不相同。有一个数a不是p的倍数,集合\(\left \{a,2a,3a,4a,...a(p-1) \right \}\)中每一个数模p的值也互不相同(1),是\(1,2,3,...,p-1\)的一种排列。
那么\((p-1)! \equiv a * 2 * a * 3 ... * (p-1)*a \pmod b\), 左右除以\((p-1)!\)(2)。
得到 \(1 \equiv a^{p-1} \bmod p\).左右同乘一个a,得证。
1) 证明 : 若\(x \not \equiv y \pmod p\), \(ax \equiv ay \bmod p\)
2) \(\gcd(p, (p-1)!) = 1\), (按照前所述性质)可以直接除。
应用: 求逆元,可以得到 \(\frac{1}{a} \equiv a^{p-2} \pmod p\) 所以a的一个逆元就是 \(a^{p-2} \bmod p\) (这里可以用快速幂来求)
fast_pow
#include <iostream>
typedef long long bl;
using namespace std;
const int N = 600;
int n, p;
bl fast_pow(bl a, bl n) {
bl ans = 1;
while(n) {
if (n & 1) ans *= a % p, ans %= p;
a *= a % p, a %= p;
n >>= 1;
}
return ans;
}
int main() {
cin >> n >> p;
for (int i = 1; i <= n; i ++) {
cout << fast_pow(i, p - 2) << "\n";
}
}
ex_gcd
#include <iostream>
typedef long long bl;
using namespace std;
const int N = 600;
int n, p;
int ex_gcd(bl a, bl b, bl &x, bl &y) {
if (!b) {
x = 1, y = 0;
return a;
}
int d = ex_gcd(b, a%b, x, y);
int tmp = x;
x = y, y = tmp - a / b * y;
return d;
}
int main() {
cin >> n >> p;
for (int i = 1; i <= n; i ++) {
bl x, y;
ex_gcd(i, p, x, y);
x = (x % p + p) % p;
cout << x << "\n";
}
}
唯一分解定理
任意一个大于1的整数都可以表示为质数的乘积,即任一大于1的整数
\(a=p_1p_2p_3...p_n , p_1 \leq p_2 \leq ... \leq p_n\)
我们也可以将相同质数写在一起: \(a=p_1^{a^1}p_2^{a^2}..p_n^{a^n}\), \(a_i \textgreater 0, i=1,2,3,...,k\) (标准分解式)
由唯一分解定理,也不难得到gcd和lcm的表达式:
\((a,b) = p_1^{min(a1,b1)}p_2^{min(a2,b2)}p_3^{min(a3,b3)}\)
\([a,b] = p_1^{max(a1,b1)}p_2^{max(a2,b2)}p_3^{max(a3,b3)}\)
有时候我们需要对gcd取模的时候,我们可以用上述方法来求.
试除法分解素因子 \(\Theta(\sqrt{n})\)
/*
关于试除法的证明,每轮循环i可以保证,n当中不包含2~i的质因子,因此第i轮循环一定不包含2~i-1的质因子,因此,如果n%i==0的i也一定不包含2~i-1的质因子(i整除n), 因此iy
*/
void divide(int x)
{
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0)
{
int s = 0;
while (x % i == 0) x /= i, s ++ ;
cout << i << ' ' << s << endl;
}
if (x > 1) cout << x << ' ' << 1 << endl;
cout << endl;
}
一般做题时有更优的方法, 即预处理求出1~n素数(筛法),然后直接枚举素数约掉素因子。
试除法求约数 \(O(\sqrt{n})\)
/*
对于每个数x, 在1~n的约数,可以记为 n / x;
所以求和 n + n/2 + n/3 + .. + 1 = nlogn
*/
vector<int> res;
void get_divisors(int n) {
for(int i = 1; i <= n / i; i ++) {
if(n % i == 0) {
res.push_back(i);
if(i != n / i) res.push_back(n / i);
}
sort(res.begin(), res.end());
}
}
素数筛
埃氏筛
埃氏筛中每个合数可能会被筛去多次,复杂度为\(O(n\log \log n)\)
/*
埃氏筛基本原理:用当前质数去筛掉(2~n)的合数
如果当前枚举的数是合数,因为其素因子p<n, 并且每次循环保证p的所有倍数(kp <= n)都被筛掉,所以一定能够筛掉当前的数
*/
int primes[N], cnt; // primes[]存储所有素数
bool st[N]; // st[x]存储x是否被筛掉
void get_primes(int n) {
for (int i = 2; i <= n; i ++ ) {
if (st[i]) continue;
primes[cnt ++ ] = i;
for (int j = i + i; j <= n; j += i)
st[j] = true;
}
}
线性筛(欧拉筛)
线性筛弥补了上述缺点,保证所有数只被筛去一次,复杂度为\(O(N)\)
/*
线性筛基本原理: (用i的最小质因子筛取i,保证了复杂度为O(N)
枚举2 ~ n / i的质数,如果我们枚举到质数且当前质数pj % i == 0, 对于(1~j)的质数一定满足p是p*i的最小的质因子
因为我们求的时1~n的素数所以保证上界pj <= n / i
*/
void get_primes(int n) {
for (int i = 2; i <= n; i ++ ) {
if (!st[i]) primes[cnt ++ ] = i;
for (int j = 0; primes[j] <= n / i; j ++ ) {
st[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
欧拉函数
定义:
\(\varphi(n)\)表示的是小于等于n并且和n互质的数的个数。 \(\varphi(1)=1\), \(\varphi(p) = p - 1\)(p为质数)
性质: 积性函数(如果\(\gcd(a,b)=1\),那么\(\varphi(a*b)=\varphi(a)*\varphi(b)\))
公式:
证明:
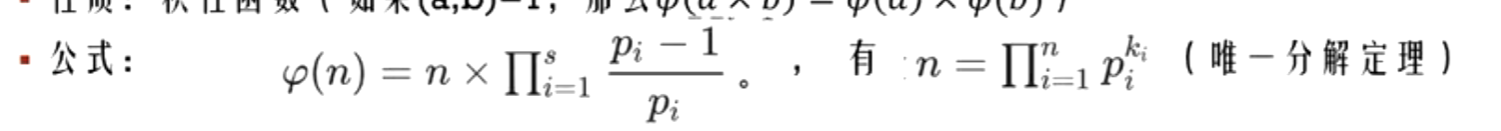
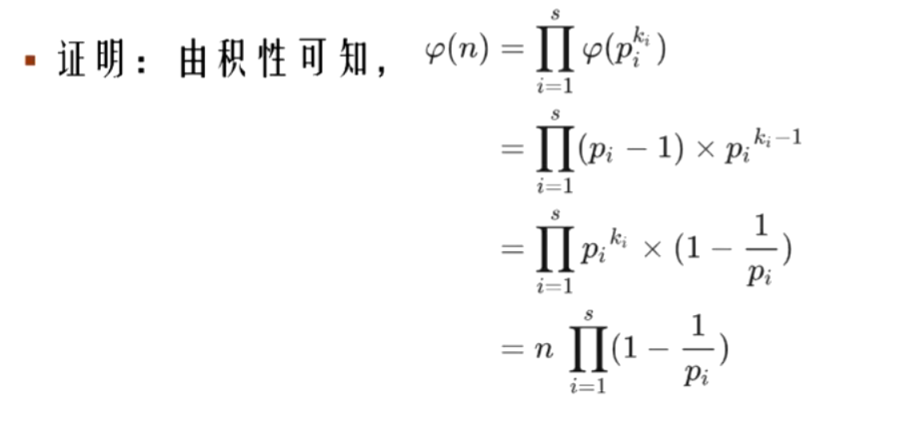
这里给出自己的理解, 欧拉函数就求1~n以内的与n互质的数的个数,我们用筛取n的质数的倍数的方法来求,即为筛取\(k \times p_i\), 由于同一个数被筛去多次, 那么问题转化为容斥原理,下面不求证了直接用公式
CODE(Acwing): \(O(\sqrt{n})\)
int phi(int x)
{
int res = x;
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0)
{
res = res / i * (i - 1); // 这里原公式时 1 - 1 / pi 由于浮点数问题,我们先整除后乘
while (x % i == 0) x /= i;
}
if (x > 1) res = res / x * (x - 1);
return res;
}
筛法 \(O(N)\) 求1~n的每个数的欧拉函数值
int primes[N], cnt; // primes[]存储所有素数
int euler[N]; // 存储每个数的欧拉函数
bool st[N]; // st[x]存储x是否被筛掉
void get_eulers(int n)
{
euler[1] = 1;
for (int i = 2; i <= n; i ++ )
{
if (!st[i])
{
primes[cnt ++ ] = i;
euler[i] = i - 1;
}
for (int j = 0; primes[j] <= n / i; j ++ )
{
int t = primes[j] * i;
st[t] = true;
if (i % primes[j] == 0)
{
euler[t] = euler[i] * primes[j]; // 互质包含了1-p_i 直接在n位置加一个相乘即可
break;
}
euler[t] = euler[i] * (primes[j] - 1); // 不包含 p_i* (1- 1 / p_i) = p_i - 1
}
}
}
欧拉定理
若\(a\) 与 \(m\) 互质, 则\(a^{\phi(m)} \equiv 1 (\bmod m)\). \(\phi(m)为欧拉函数\)
证明:
设\(x_1, x_2, ... , x_{\phi(n)}\) 为1~n中与n互质的数
设序列 \(p_1 = ax_1, p_2 = ax_2 ... p_{\phi(n)} = ax_{\phi(n)}\)
Lemma1: \(p \bmod m\) 两两不同余
Lemma2: \(p \bmod n\)的每个结果都与m互质
Lemma3: 若\((r_1 * r_2) \bmod m = r_2, 其中r_1,r_2均与m互质, 则 r_1 = 1\)
由两个引理1, 2得, \(p \bmod m\) 是对\(x_1, x_2, ... x_{\phi(m)}\)的映射
所以有
\((\prod \limits^{\phi(m)}_{i = 1} p_i) \bmod m = (\prod \limits^{\phi(m)}_{i = 1} x_i) \bmod m\)
=> \((a^{\phi(m)}\prod \limits^{\phi(m)}_{i = 1} x_i) \bmod m = (\prod \limits^{\phi(m)}_{i = 1} x_i) \bmod m\)
由引理3
=> \(a^{\phi(m)} \bmod m = 1\)
对于欧拉定理,显然费马小定理是欧拉定理的特例, 即\(m\)为质时, \(\phi(m) = m - 1\), 带入等式与费马小定理结果相同
关于引理的证明参考这个视频
中国剩余定理
\(m_1, m_2, ... m_n\)两两互质, 求
\(x \equiv a_1 (\bmod m), x \equiv a_2 (\bmod m), ... ,x\equiv a_n(\bmod m)\)的一组解。
\(M = m_1m_2...m_n\)
\(M_i = \frac{M}{m_i}\)
\(x = a_1 M_1 M_1^{-1} + a_2 M_2 M_2^{-1} + ... + a_n M_n M_n^{-1}\)
求逆元可以用扩欧
高斯消元
初等行列变换:
-
把某一行乘一个非零的数
-
交换某两行
-
把某行的若干倍加到第三行
通过初等行列变换将方程换成上三角的形式。
结果分为三种:
- 完美阶梯型 唯一解
- 出现无解式 如0 = 非零 无解
- 0 = 0 无穷多组解
算法过程
枚举每一列c
- 找到当前列绝对值最大的一行
- 把这一行换到最上面
- 将该行的第一个数变成1(系数同时除)
- 把下面所有行的第c列消为0
通过消去可以得到阶梯行列式
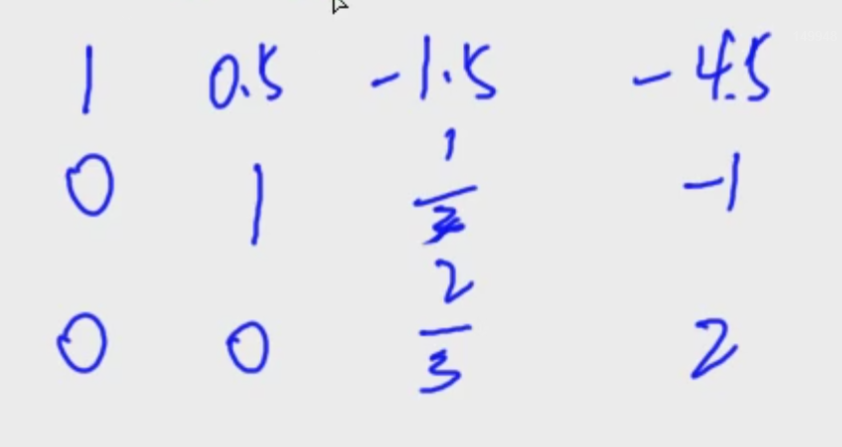
求组合数
递推 \(O(n^2)\)
\(C_a^b = C_{a-1}^b + C_{a-1}^{b-1}\)
#include <iostream>
using i64 = long long;
const int N = 2010, mod = 1e9 + 7;
int c[N + 10][N + 10];
void init() {
for(int i = 0; i < N; i ++) {
for(int j = 0; j <= i; j ++) {
if(!j) c[i][j] = 1;
else c[i][j] = (c[i - 1][j] + c[i - 1][j - 1]) % mod;
}
}
}
int main() {
init();
int n;
std::cin >> n;
while(n --) {
int a, b;
std::cin >> a >> b;
std::cout << c[a][b] << "\n";
}
}
逆元预处理 \(O(nlogn)\)
\(C_a^b = \frac{a!}{(b-a)!b!} \bmod p = a! \times ((b-a)!)^{-1} \times (b!)^{-1}\) , 这里\(-1\)指\(数论倒数\)即\(逆元\)
所以预处理好上面的数即可求解, 逆元数组部分 因为\(ax \equiv 1(\bmod p), by \equiv 1(\bmod p) 则ax \times by \equiv 1(\bmod p)\)
#include <iostream>
#include <algorithm>
using i64 = long long;
typedef long long LL;
const int N = 100010, mod = 1e9 + 7;
int fact[N], infact[N];
int fast_pow(int a, int b, int mod) {
int res = 1;
while(b) {
if(b & 1) res = (LL)res * a % mod;
a = (LL)a * a % mod;
b >>= 1;
}
return res;
}
int main() {
fact[0] = infact[0] = 1;
for(int i = 1; i < N; i ++) {
fact[i] = (LL)fact[i - 1] * i % mod;
infact[i] = (LL)infact[i - 1] * fast_pow(i, mod - 2, mod) % mod;
}
int n;
std::cin >> n;
while(n --) {
int a, b;
std::cin >> a >> b;
std::cout << (LL)fact[a] * infact[b] % mod * infact[a- b] % mod << "\n";
}
}
也有\(O(n)\)做法,需要线性预处理逆元
卢卡斯定理
\(C_a^b \equiv C_{a \bmod p}^{a \bmod p} \times C_{a/p}^{b/p}(\bmod p)\)
\(O(p + Tlogp)\)
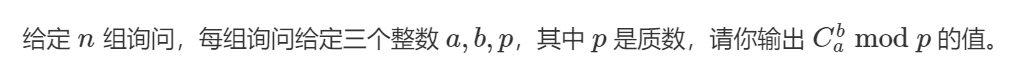
#include <bits/stdc++.h>
using i64 = long long;
i64 p;
int fast_pow(int a, int k) {
int res = 1;
while(k){
if(k & 1) res = (i64)res * a % p;
a = (i64)a * a % p;
k >>= 1;
}
return res;
}
int C(int a, int b) {
int res = 1;
for(int i = 1, j = a; i <= b; i ++, j --) {
res = (i64)res * j % p;
res = (i64)res * fast_pow(i, p - 2) % p;
}
return res;
}
int lucas(i64 a, i64 b) {
if(a < p && b < p) return C(a, b);
return (i64)C(a % p, b % p) * lucas(a / p, b / p) % p;
}
int main() {
int n;
std::cin >> n;
while(n --) {
i64 a, b;
std::cin >> a >> b >> p;
std::cout << lucas(a, b) << "\n";
}
}
高精度-组合数
- 分解质因数
- 写高精度乘法
#include <iostream>
#include <algorithm>
#include <vector>
using i64 = long long;
const int N = 5010;
int primes[N], cnt;
int sum[N];
bool st[N];
void get_primes(int n) {
for(int i = 2; i <= n; i ++) {
if(!st[i]) primes[cnt ++] = i;
for(int j = 0; primes[j] <= n / i; j ++) {
st[primes[j] * i] = true;
if(i % primes[j] == 0) break;
}
}
}
int get(int n, int p) {
int res = 0;
while(n) {
res += n / p;
n /= p;
}
return res;
}
std::vector<int> mul(std::vector<int> a, int b) {
std::vector<int> c;
int t = 0;
for(int i = 0; i < a.size(); i ++) {
t += a[i] * b;
c.push_back(t % 10);
t /= 10;
}
while(t) {
c.push_back(t % 10);
t /= 10;
}
return c;
}
int main() {
int a, b;
std::cin >> a >> b;
get_primes(a);
for(int i = 0; i < cnt; i ++) {
int p = primes[i];
sum[i] = get(a, p) - get(a - b, p) - get(b, p);
}
std::vector<int> res;
res.push_back(1);
for(int i = 0; i < cnt; i ++)
for(int j = 0; j < sum[i]; j ++)
res = mul(res, primes[i]);
for(int i = (int)res.size() - 1; i >= 0; i --) std::cout << res[i];
}
容斥原理
复杂度计算
\(C_n^1 + C_n^2 + ... + C_n^3 + ... + C_n^n = 2^n - C_n^0 = 2^n - 1\)
\(O(2^n)\)
\(\abs{S_1 \cup S_2 \cup S_3 ... \cup S_n} = \sum \limits_i\abs{S_i} - \sum \limits_{i \cdot j}\abs{S_i \cup S_j} + \sum \limits_{i \cdot j \cdot k}\abs{S_i \cup S_j \cup S_k} - ...\)
简单证明: 假设集合中的某个元素\(x\),在上述等式中被算了\(k\)次, 则
\(C_k^1 - C_k^2 + C_k^3 - C_k^4 + ... + (-1)^{k - 1}C_k^k = 1\)
#include <bits/stdc++.h>
using i64 = long long;
const int N = 1e5 + 10;
int p[N], n, m, res = 0;
int main() {
int n, m, ans = 0;
std::cin >> n >> m;
for(int i = 0; i < m; i ++) {
std::cin >> p[i];
}
for(int i = 1; i < 1 << m; i ++) {
int t = 1;
int s = 0;
for(int j = 0; j <= m - 1; j ++) {
if(i >> j & 1) {
if((i64)p[j] * t > n) {
s = -1;
break;
}
s ++;
t *= p[j];
}
}
if(s == -1) continue;
if(s & 1) ans += n / t;
else ans -= n / t;
}
std::cout << ans << "\n";
}
勒让那多定理
Legendre 定理
在正数\(n!\)的质因数分解中, 质数\(p\) 的指数记作\(v_p(n!)\),则有等式\(v_p(n!)=\sum\limits_{j=1}^{\infty} \lfloor\frac{n}{p^k} \rfloor\)
LL f(LL n, LL p) {
if (n == 0) return 0;
n /= p;
return n + f(n, p);
}
博弈
对称博弈
下模仿棋就不会吃亏
公平组合游戏 ICG
两个玩家交替游戏,每个玩家可执行操作相同,不能行动玩家判负
有向图游戏
给定有向无环图,图中有唯一起点,在起点放有一枚棋子。两名玩家交替行动,每次移动一个边,无法移动玩家为负。任何公平组合游戏可以转化为有向图游戏。
Nim Game
\(a_1 \oplus a_2 .. . \oplus ... a_n = 0\)为必败态,否则为必胜态
#include <bits/stdc++.h>
using i64 = long long;
const int N = 1e5 + 10;
int a[N];
int main() {
int n, ok = 0;
std::cin >> n;
for(int i = 1; i <= n; i ++) {
std::cin >> a[i];
ok ^= a[i];
}
std::cout << (ok?"Yes":"No");
}
台阶NIM
集合NIM
指定取数集合\(S\),进行NIM游戏
单个\(SG(a_i)\)为0时为必败,否则必胜,对所有\(i\)转为都为0时为必败态,此时转为NIM游戏问题
\(SG(a_1) \oplus SG(a_2) \oplus ... SG(a_n) = 0\) 必胜,否则必败
#include <bits/stdc++.h>
#include <cstring>
#define FOR(i, n) for(int i = 1; i <= n; i ++)
using i64 = long long;
const int N = 110, M = 10010;
int n, m;
int s[N], f[M];
int sg(int x) {
if(f[x] != -1) return f[x];
std::unordered_set<int> S;
for(int i = 0; i < m; i ++) {
int sum = s[i];
if(x >= sum) S.insert(sg(x - sum));
}
for(int i = 0; ; i ++) {
if(!S.count(i))
return f[x] = i;
}
}
int main() {
std::cin >> m;
for(int i = 0; i < m; i ++) std::cin >> s[i];
std::cin >> n;
memset(f, -1, sizeof f);
int res = 0;
for(int i = 0; i < n; i ++) {
int x;
std::cin >> x;
res ^= sg(x);
}
std::cout << (res?"Yes":"No");
}
SG函数
有向图游戏中,对于每个节点\(x\),设从\(x\)出发共有\(k\)条有向边,分别到达节点\(y_1, y_2, ...,y_k\)的SG函数构成的集合在执行\(Mex(S)\)运算的结果即
\(SG(x) = Mex({SG(y_1), SG(y_2), ..., SG(y_k)})\)
特别地,整个有向图游戏\(G\)的\(SG\)函数值被定义为有向图的起点\(s\)的\(SG\)函数值,即\(SG(G) = x\)
有向图游戏的某个局面必胜,当且仅当该局面对应节点的SG函数值大于0
有向图游戏的某个局面必败,当且仅当该局面对应节点的SG函数值等于0
Mex运算
设\(S\)表示一个非负整数集合。定义\(Mex(S)\)为不属于集合\(S\)的最小最非负整数运算。
即 \(Mex(S) = min(x)\), \(x\)属于自然数,且\(x\)不属于\(S\)
如\(Mex(\{0, 1, 3\})\)为\(2\)
卡特兰特数
给定 \(n\) 个 \(0\) 和 \(n\) 个 \(1\),它们将按照某种顺序排成长度为 \(2n\) 的序列,求它们能排列成的所有序列中,能够满足任意前缀序列中 \(0\) 的个数都不少于 \(1\) 的个数的序列有多少个。
\(C_{2n}^{n} - C_{2n}^{n - 1} = \frac{C_{2n}^{n}}{n + 1}\)
勒让那多定理
Legendre 定理
在正数\(n!\)的质因数分解中, 质数\(p\) 的指数记作\(v_p(n!)\),则有等式\(v_p(n!)=\sum\limits_{j=1}^{\infty} \lfloor\frac{n}{p^k} \rfloor\)
LL f(LL n, LL p) {
if (n == 0) return 0;
n /= p;
return n + f(n, p);
}
Geometry
二维几何
坐标旋转
对于平面直角坐标系下的坐标\((x, y)\) 顺时针旋转\(\theta°\) 后的坐标
\begin{pmatrix}
x & y
\end{pmatrix}
\times
\begin{pmatrix}
cos\theta & sin\theta \
-sin\theta & cos\theta \
\end{pmatrix}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号