
YOLOv3模型识别车位图片的测试报告(节选)
1,YOLOv3模型简介
YOLO能实现图像或视频中物体的快速识别。在相同的识别类别范围和识别准确率条件下,YOLO识别速度最快。
官网:https://pjreddie.com/darknet/yolo/
知乎:https://zhuanlan.zhihu.com/p/25236464
YOLO有多种模型,包括V1,V2,V3,其中V3识别准确率最高,但对硬件要求也高。还有tiny模型。也可针对特定识别物体类别进行训练,获得应用需要的专用模型。
本次测试采用V3模型。对实际车场图片进行批量检测,对检测结果进行分析,重点是车位中的车辆能否得到正确识别,以探讨YOLO V3模型应用于车场车位状态检测中的可行性。
2,测试环境
|
操作系统 |
Windows7 64位 |
|
|
Cpu |
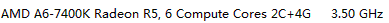 |
|
|
Gpu |
0 |
|
|
内存 |
4GB |
|
|
输入图片的数量和规格 |
2019张,960*1280 |
|
|
运行时间 |
2018-05-23 18:03~~2018-05-24 05:01 |
|
|
执行文件 |
|
|
|
检测模型 |
YOLO v3 |
|
|
物体检测阈值 |
置信度 > 0.25 |
|
|
物体分类模型 |
80种,与车位车辆相关的4种(car, motorbike, truck, bus)。详见coco.names |
|
3,测试数据和结果
|
运行总时间 |
11小时 |
|
|
平均每张图片的分析时间 |
20秒 |
|
|
分析后输出的图片包 |
YOLO对车位图片的检测结果.rar |
|
|
分析输出文字信息 |
|
|
|
车位图片输出结果分析 |
|
识别错误类别统计:
|
错误类别编号 |
错误类别 |
数量 |
比例 |
备注 |
|
1 |
识别到周围停有车辆,因而判断有车 |
118 |
|
此问题与YOLO算法无关 |
|
2 |
未识别出相机识别车位上的车辆 |
74 |
3.66% |
2类错误的文件已打包在文件2类错误.rar |
|
3 |
镜头范围过小,车辆无法体现特征 |
1 |
|
此问题与YOLO算法无关 |
|
4 |
图像变形 |
1 |
|
此问题与YOLO算法无关 |
|
5 |
在无车位置上错误标注 |
6 |
0.3% |
5类错误的文件已打包在文件5类错误.rar |
综上所述,本次测试错误率为3.96%。效果还是令人基本满意的。
4,测试分析
4.1 YOLOv3静态车位图片检测优势
总体来说,识别车辆准确,适应强。具体表现如下:
² 对于多车不会漏检
² 面向镜头的无论是车头、车尾还是车身都能检测到。
² 特种车辆也能识别。
² 只出现一部分的车身也能检测到。但也要看是否能体现车辆特征
² 光线强弱对检测影响不大。
² 强大的物体检测能力,不仅限于车辆检测。
以下具体示例略。
4.2 YOLOv3静态车位图片检测存在的问题
测试中发现的问题可以归纳为以下几类:
² 存在漏检。某些明显的车辆未能检测到
² 在全域范围内能检测到的车辆,区域裁剪后可能导致检测不到
² 同一物体可能检测出多种类别或多台车检测成1台
² 车辆错误识别为其它种类
² 空车位错误识别为车辆
以下具体示例略。
5,后续计划
对于车位车辆的识别,如果速度和准确度达到实用程度,那么可用于简易停车场的车位调度。
如果结合人脸识别或车牌识别,也能做到反向寻车。
也可应用于路边停车,可将车辆进入停车区和离开停车区的信息及时上报。
目前关键还是将车辆识别做到又好又快。以下为思路:
略。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号