
R语言实战学习笔记-高级数据管理
本文将从以下几个方面介绍R语言中的数据管理,1.数据处理函数 2.控制流 3.用户自定义函数 4.整合和重构
1.数据的处理函数
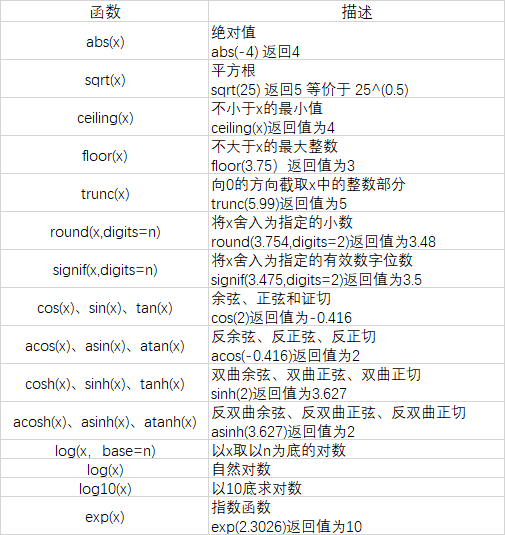
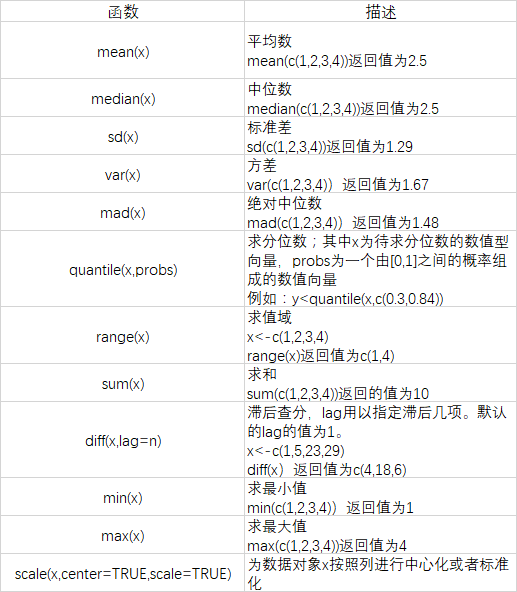
#实例
x<-c(1,2,3,4,5,6,7,8,9)
y<-mean(x)
#冗长的方式
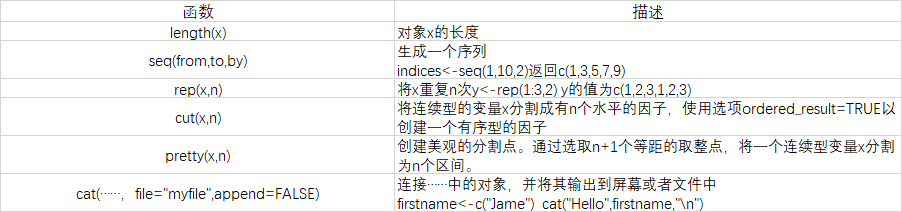
n<-length(x)
#求均值
meanx<-sum(x)/n
#求标准差
css<-sum((x-meanx)^2)
sdx<-sqrt(css/(n-1))
print(sdx)
[1] 2.738613
概率函数:

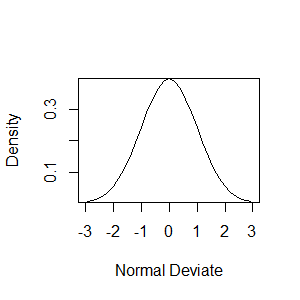
#绘制正太分布曲线
x<-pretty(c(-3,3),30)
y<-dnorm(x)
plot(x,y,type="l",xlab="Normal Deviate",ylab="Density",yaxs="i")
#伪随机数
#生成服从正太分布的伪随机数
runif(5)
#手动设置种子,重现上上次的结果
set.seed(1234)
runif(5)
[1] 0.1137034 0.6222994 0.6092747 0.6233794 0.8609154
set.seed(1234)
runif(5)
[1] 0.1137034 0.6222994 0.6092747 0.6233794 0.8609154
在模拟研究和蒙特卡洛方法中,经常需要获取来自给定均值向量和协方差阵的多元正太分布的数据,MASS中mvrnorm()函数可以让这个问题变得容易:
library(MASS)
options(digits=3)
#设置随机数种子
set.seed(1234)
mean<-c(230.7,146.7,3.6)
#制定均值向量、协方差阵
sigma<-matrix(c(15360.8,6721.2,-47.1,6721.2,4700.9,-16.5,-47.1,-16.5,0.3),nrow=3,ncol=3)
#生成数据
mydata<-mvrnorm(500,mean,sigma)
mydata<-as.data.frame(mydata)
names(mydata)<-c("y","x1","x2")
#查看结果
dim(mydata)
head(mydata,n=10)
y x1 x2
1 98.8 41.3 3.43
2 244.5 205.2 3.80
3 375.7 186.7 2.51
4 -59.2 11.2 4.71
5 313.0 111.0 3.45
6 288.8 185.1 2.72
7 134.8 165.0 4.39
8 171.7 97.4 3.64
9 167.2 101.0 3.50
10 121.1 94.5 4.10
字符处理函数: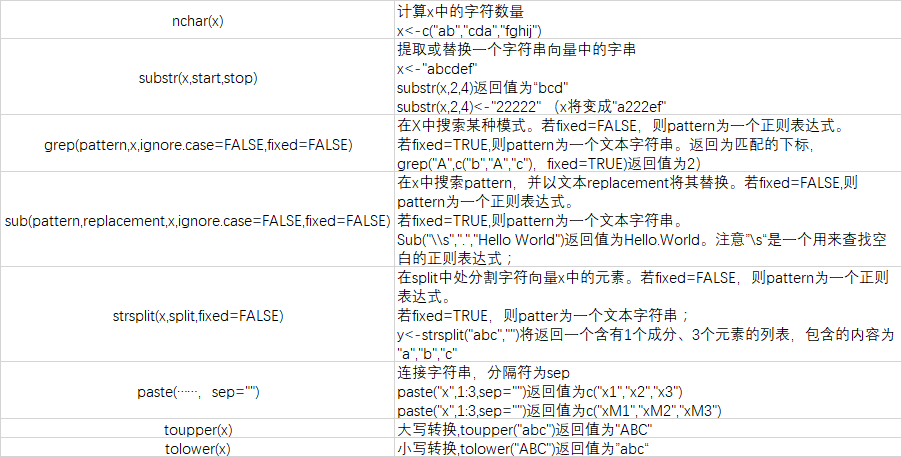
a<-5
sqrt(a)
[1] 2.24
b<-c(1.243,5.654,2.99)
round(b)
[1] 1 6 3
c<-matrix(runif(12),nrow=3)
c
[,1] [,2] [,3] [,4]
[1,] 0.9636 0.216 0.289 0.913
[2,] 0.2068 0.240 0.804 0.353
[3,] 0.0862 0.197 0.378 0.931
log(c)
[,1] [,2] [,3] [,4]
[1,] -0.0371 -1.53 -1.241 -0.0912
[2,] -1.5762 -1.43 -0.218 -1.0402
[3,] -2.4511 -1.62 -0.972 -0.0710
mean(c)
[1] 0.465
#apply()函数的应用
apply(x,MARGIN,FUN,……)
x为数据对象,margin是维度的下标,FUN为自己制定的函数
mydata<-matrix(rnorm(30),nrow=6)
mydata
[,1] [,2] [,3] [,4] [,5]
[1,] 0.459 1.203 1.234 0.591 -0.281
[2,] -1.261 0.769 -1.891 -0.435 0.812
[3,] -0.527 0.238 -0.223 -0.251 -0.208
[4,] -0.557 -1.415 0.768 -0.926 1.451
[5,] -0.374 2.934 0.388 1.087 0.841
[6,] -0.604 0.935 0.609 -1.944 -0.866
#计算每行的平均值
apply(mydata,1,mean)
[1] 0.641 -0.401 -0.194 -0.136 0.975 -0.374
#计算每列的平均值
apply(mydata,2, mean)
[1] -0.478 0.777 0.148 -0.313 0.292
#计算每行的结尾均值
apply(mydata,2,mean,trim=0.2)
[1] -0.516 0.786 0.386 -0.255 0.291
数据处理难题的解决方案:
#限定输出的小数点后的数字的位数为2
options(digits=2)
Student<-c("John Davis","Angela Williams","Bullwinkle Moose","David Jones","Janice Markhammer","Cheryl Cushing","Reuven Ytzrhak","Greg Knox","Joel England","Joel England")
Math<-c(502,600,412,538,512,492,410,625,573,522)
Science<-c(95,99,80,82,75,85,80,95,89,86)
English<-c(25,22,18,15,20,28,15,30,27,18)
roster<-data.frame(Student,Math,Science,English)
#将变量标准化
z<-scale(roster[,2:4])
#输出的结果为:
Math Science English
[1,] -0.234 1.078 0.587
[2,] 1.145 1.591 0.037
[3,] -1.500 -0.847 -0.697
[4,] 0.273 -0.590 -1.247
[5,] -0.093 -1.489 -0.330
[6,] -0.374 -0.205 1.137
[7,] -1.528 -0.847 -1.247
[8,] 1.497 1.078 1.504
[9,] 0.765 0.308 0.954
[10,] 0.048 -0.077 -0.697
#求各行的平均值
score<-apply(z,1,mean)
#将平均值放到花名册中
roster<-cbind(roster,score)
#寻找成绩的分界点
y<-quantile(score,c(0.8,0.6,0.4,0.2))
roster$grade[score>=y[1]]<-"A"
roster$grade[score<y[1]&score>=y[2]]<-"B"
roster$grade[score<y[2]&score>=y[3]]<-"C"
roster$grade[score<y[3]&score>=y[4]]<-"D"
#拆分字符串
name<-strsplit((roster$Student)," ")
#提取拆分的字符串
Lastname<-sapply(name, "[",2)
Firstname<-sapply(name, "[",1)
#将拆分的字符串添加到花名册中,并删除name
roster<-cbind(Firstname,Lastname,roster[,-1])
roster<-roster[order(Lastname,Firstname),]
roster
#输出结果
Student Math Science English score grade
1 John Davis 502 95 25 0.48 B
2 Angela Williams 600 99 22 0.92 A
3 Bullwinkle Moose 412 80 18 -1.01 <NA>
4 David Jones 538 82 15 -0.52 D
5 Janice Markhammer 512 75 20 -0.64 D
6 Cheryl Cushing 492 85 28 0.19 C
7 Reuven Ytzrhak 410 80 15 -1.21 <NA>
8 Greg Knox 625 95 30 1.36 A
9 Joel England 573 89 27 0.68 B
10 Joel England 522 86 18 -0.24 C
2.控制流
- 语句(statement)是一条单独的R语句或者一组符合的语句(包含在花括号{}中的一组R语句,使用分号分隔)
- 条件(cond)是一条最终被解释为真或假的表达式
- 表达式(expr)是一天数值或字符串的求值语句
- 序列(seq)是一个数值或字符串序列
#for循环重复执行一个语句,直到某个变量的值不再包含在序列seq中为止。
for(var in seq) statement
for(i in 1:10) print("Hello")
#单词Hello被输出了10次
#while结构
#while循环从重复地执行一个语句,直到条件不为真为止。
while(cond) statement
i<-10
while(i>0){print("Hello");i<-i-1}
#if-else结构
#控制结构if-else在某个给定条件为真时执行语句。也可以同时在条件为假时执行另一条语句。
if(cond) statement
if(cond) statement1 else statement2
if(is.character(grade)) grade<-as.factor(grade)
if(!is.factor(grade)) grade<-as.factor(grade) else print("Grade already is a factor")
#ifelse结构是if-else结构比较紧凑的向量画版本
ifelse(cond,statement1,statement2)
ifelse(score>0.5,print("Passed"),print("Failed"))
#switch根据一个表达式的值选择语句执行
switch(expr,……)
feelings<-c("sad","afraid")
feelings<-c("sad","afraid")
for(i in feelings)
print(
switch(i,
happy="I am glad you are happy",
afraid="There is nothing to fear",
sad="Cheer up",
angry="Calm down now"
)
)
[1] "Cheer up"
[1] "There is nothing to fear"
3.用户自定义函数
#函数的基本结构
myfunction<-function(arg1,arg2,……){
statements
return(object)
}
#函数实例
#函数实例
mystats<-function(x,parametric=TRUE,print=FALSE){
if(parametric){
center<-mean(x);
spread<-sd(x)
}else{
center<-median(x);
spread<-mad(x)
}
if(print¶metric){
cat("Mean=",center,"\n","SD=",spread,"\n")
}else if(print&!parametric){
cat("Median=",center,"\n","MAD=",spread,"\n")
}
result<-list(center=center,spread=spread)
return(result)
}
set.seed(1234)
x<rnorm(500)
y<-mystats(x)
print(y)
#输出结果
print(y)
80% 60% 40% 20%
0.73 0.30 -0.35 -0.71
#含有switch的自定义函数
mydate<-function(type="long"){
switch(type,
long=format(Sys.time(),"%A %B %Y"),
short=format(Sys.time(),"%m-%d-%y"),
cat(type,"is not a recognized type\n"))
}
mydate("long")
[1] "星期四 四月 2018"
mydate("short")
[1] "04-19-18"
mydate()
[1] "星期四 四月 2018"
mydate("medium")
medium is not a recognized type
4.整合与重构
#数据集的转置
cars<-mtcars[1:5,1:4]
cars
#输出结果
mpg cyl disp hp
Mazda RX4 21 6 160 110
Mazda RX4 Wag 21 6 160 110
Datsun 710 23 4 108 93
Hornet 4 Drive 21 6 258 110
Hornet Sportabout 19 8 360 175
#利用t()函数转置
t(cars)
Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive Hornet Sportabout
mpg 21 21 23 21 19
cyl 6 6 4 6 8
disp 160 160 108 258 360
hp 110 110 93 110 175
#数据集的整合
options(digits=3)
attach(mtcars)
aggdata<-aggregate(mtcars,by=list(cyl,gear),FUN=mean,na.rm=TRUE)
aggdata
#输出的结果集
Group.1 Group.2 mpg cyl disp hp drat wt qsec vs am gear
1 4 3 21.5 4 120 97 3.70 2.46 20.0 1.0 0.00 3
2 6 3 19.8 6 242 108 2.92 3.34 19.8 1.0 0.00 3
3 8 3 15.1 8 358 194 3.12 4.10 17.1 0.0 0.00 3
4 4 4 26.9 4 103 76 4.11 2.38 19.6 1.0 0.75 4
5 6 4 19.8 6 164 116 3.91 3.09 17.7 0.5 0.50 4
6 4 5 28.2 4 108 102 4.10 1.83 16.8 0.5 1.00 5
7 6 5 19.7 6 145 175 3.62 2.77 15.5 0.0 1.00 5
8 8 5 15.4 8 326 300 3.88 3.37 14.6 0.0 1.00 5
在结果中,Group.1表示气缸数量(4,6,8),Group.2代表档位数(3,4,5)。举例来说,拥有4个气缸和3个档位车型的每加仑汽油行驶英里数均值为21.5
重构和整合数据集的万能工具-reshape2
ID<-c(1,1,2,2)
Time<-c(1,2,1,2)
X1<-c(5,3,6,2)
X2<-c(6,5,1,4)
mydata<-data.frame(ID,Time,X1,X2)
mydata
#输出结果为
ID Time X1 X2
1 1 1 5 6
2 1 2 3 5
3 2 1 6 1
4 2 2 2 4
library(reshape2)
md<-melt(mydata,id=c("ID","Time"))
md
#输出结果
ID Time variable value
1 1 1 X1 5
2 1 2 X1 3
3 2 1 X1 6
4 2 2 X1 2
5 1 1 X2 6
6 1 2 X2 5
7 2 1 X2 1
8 2 2 X2 4
#执行整合
dcast(md,ID~variable,mean)
ID X1 X2
1 1 4 5.5
2 2 4 2.5
dcast(md,Time~variable,mean)
Time X1 X2
1 1 5.5 3.5
2 2 2.5 4.5
dcast(md,ID~Time,mean)
ID 1 2
1 1 5.5 4
2 2 3.5 3
dcast(md,ID+Time~variable)
ID Time X1 X2
1 1 1 5 6
2 1 2 3 5
3 2 1 6 1
4 2 2 2 4
dcast(md,ID+variable~Time)
ID variable 1 2
1 1 X1 5 3
2 1 X2 6 5
3 2 X1 6 2
4 2 X2 1 4
dcast(md,ID~variable+Time)
ID X1_1 X1_2 X2_1 X2_2
1 1 5 3 6 5
2 2 6 2 1 4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号