消息队列 —— Kafka
一. Kafka 简介
1. 概述
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
主要的应用场景是:日志手机系统和消息系统
2. Kafka 的主要设计目标
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输
- 支持离线数据处理和实时数据处理
- 支持在线水平扩展
3. 消息系统介绍
一个消息系统负责将数据从一个用用传递到另一个应用,应用只需关注于数据,无需关注在两个或多个应用间是如何传递的。分布式消息传递基于可靠的消息队列,在客户端应用和消息系统之间异步传递消息。有两种主要的消息传递模式:
3.1 点对点的消息传递模式
在点对点消息系统中,消息持久化到一个队列中。此时,将有一个或多个消费者消费队列中的数据。但是一条消息只能被消费一次。当一个消费者消费了队列中的某条数据之后,该条数据则从消息队列中删除。该模式即使有多个消费者同时消费数据,也能保证数据处理的顺序。这种结构描述示意图如下:
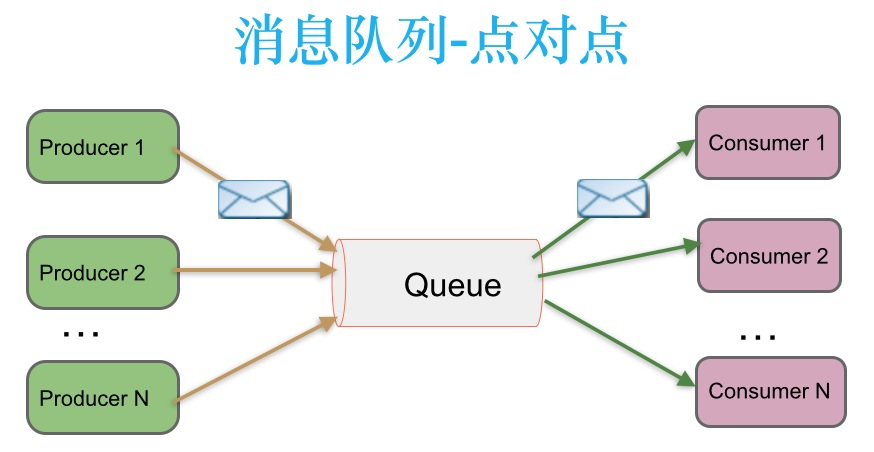
生产者发送一条消息到 queue 队列中,只有一个消费者可以收到。
3.2 发布-订阅消息传递模式
在发布-订阅消息系统中,消息被持久化到一个 topic 中。与点对点消息系统不同的是,消费者可以订阅一个或多个 topic,消费者可以消费该 topic 中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。在发布-订阅消息系统中,消息的生产者被称为发布者,消费者成为订阅者。该模式的示例图如下:
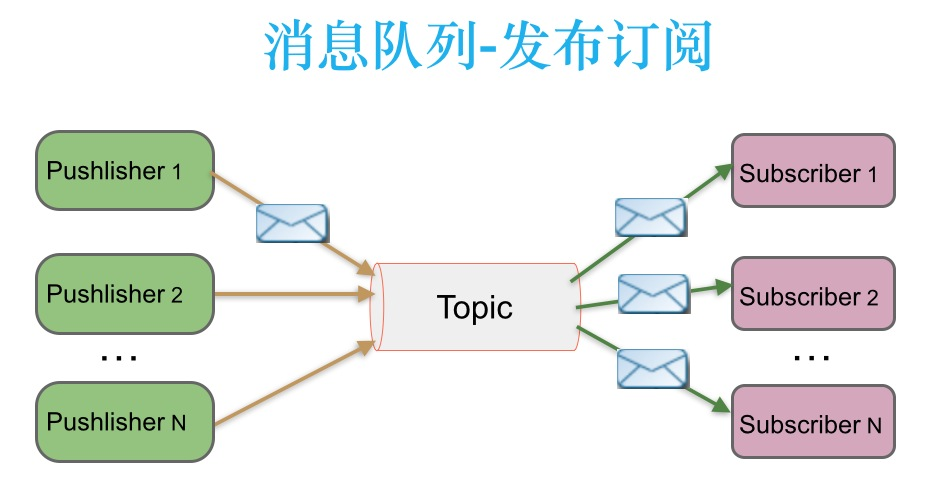
发布者发送到 topic 的消息,只有订阅了 topic 的订阅者才会收到消息。
4. Kafka 的优势
- 高吞吐量
- 高性能
- 持久化顺序存储
- 零拷贝
- 顺序读写
- 页缓存
- 分布式系统
- 可靠性
- 支持 online 和 offline 的场景
- 支持多种客户端语言
5. Kafka 的应用场景
- 日志收集:一个公司可以用 kafka 收集各个服务的 log,通过 kafka 以统一接口服务的方式,开放给各个消费者(consumer)
- 消息系统:解耦生产者和消费者、缓存消息等
- 用户活动跟踪:kafka 经常被用来记录 web 用户或者 app 用户的各种活动,入浏览网页、搜索、点击等活动,这些活动信息呗各个服务器发不到 kafka 的 topic 中,然后消费者通过订阅这些 topic 来做实时的监控分析,也可以保存到数据库
- 运营指标:kafka 也经常用来记录运营监控数据。包括搜集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告
二. Kafka 架构
1. Kafka 基本架构
(1)消息和批次
Kafka 的数据单元被称为“消息”,相当于数据库表的一行记录。消息可以拥有一个可选的元数据,也就是键。通过键可以将消息写入不同的分区。
为了提高效率,消息可以分批次写入 kafka,批次就是一组消息,这些消息属于同一个主题和分区。
(2)消息模式
对于Kafka来说,消息不过是晦涩难懂的字节数组,所以有人建议用一些额外的结构来定义消息的内容,让它们更易于理解。根据应用程序的需求,消息模式(schema)有许多可用的选项,像JSON和XML这些简单的系统不仅易用,而且可读性好。
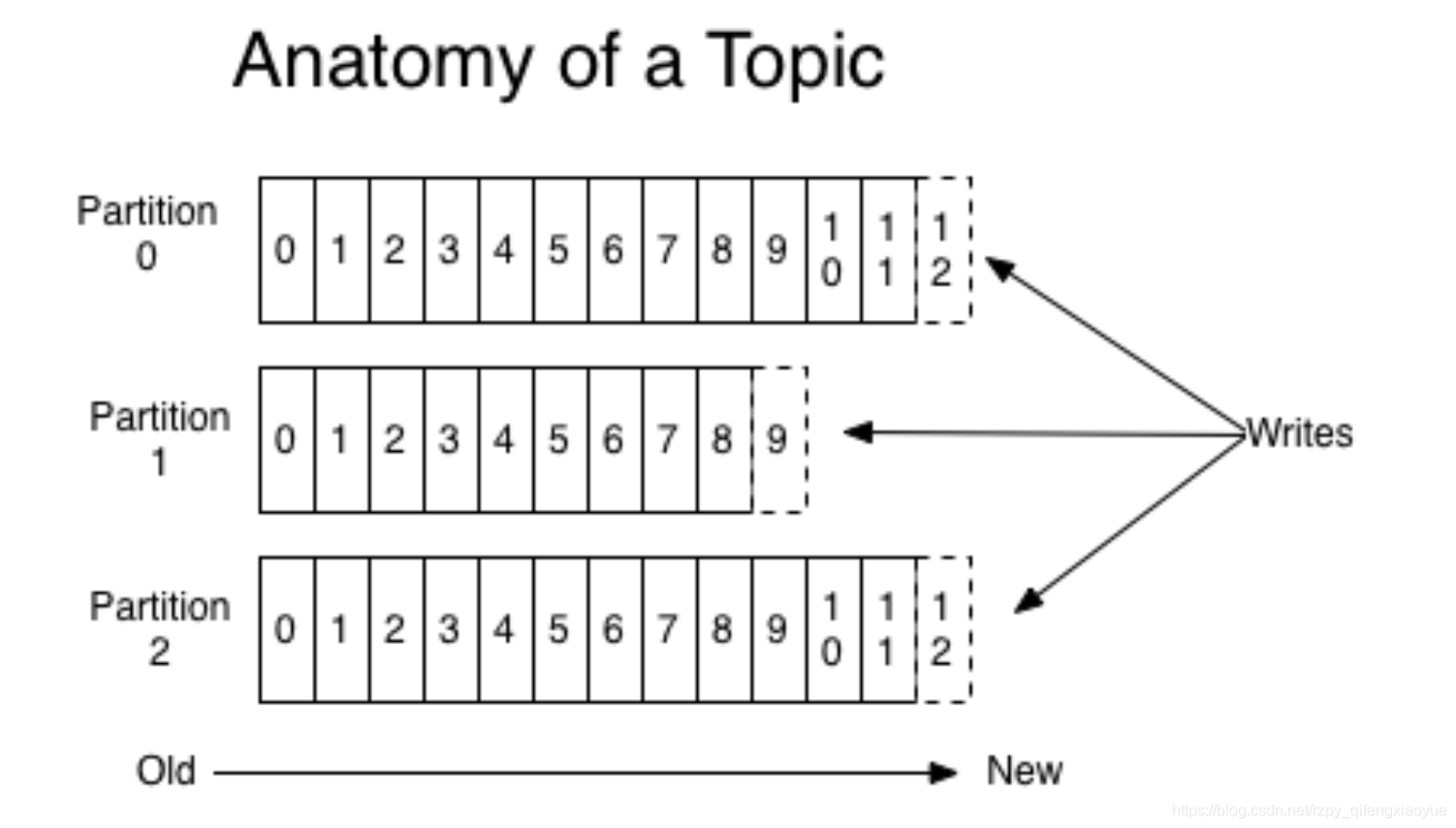
(3)主题和分区
Kafka的消息通过主题进行分类。主题就好比数据库的表,或者文件系统里面的文件夹。主题可以被分为弱哦干个分区,一个分区就是一个提交日志。消息以追加的方式写入分区,然后以先入先出的顺序读取。一般一个主题包含几个分区,因此无法整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。如下图所示的主题有四个分区,消息被追加写入每个分区的尾部。kafka通过分区来实现数据冗余和伸缩性。分区可以分布在不同的服务器上,也就是一个主题可以横跨多个服务器,以此来提供比单个服务器更大的性能
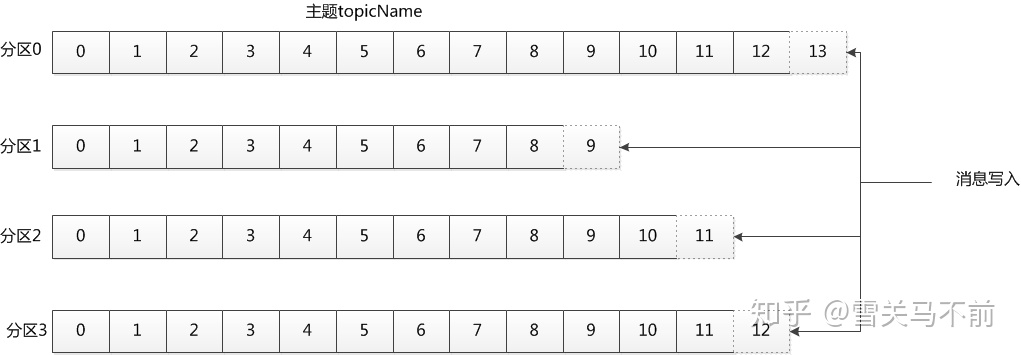
(4)生产者和消费者
Kafka的客户端就是Kafka的系统的用户,它们被分为两种基本类型:生产者和消费者。除此之外,还有其他高级客户端API---用于数据继承的Kafka Connect API和用于流式处理的Kafka Streams。这些高级客户端API使用生产者和消费者作为内部组件,通过了高级功能
生产者创建消息。在其他发布和订阅系统中,生产者可能被称为发布者或写入者。一般情况下,一个消息被发布到一个特定的主题上。生产者默认情况下把消息均衡地分布到主题的所有分区上,而并不关心特定消息会被写到哪个分区。不过,在某些情况下,生产者会把消息直接写到指定的分区。通常是通过消息键和分区器来实现的,分区器为键生成一个散列值,并将其映射到指定的分区上,这样可以保证包含同一个键的消息会被写到同一个分区上。生产者也可以使用自定义的分区器,根据不同的业务规则将消息映射到分区。
消费者读取消息。消费者订阅一个或多个主题,并按照消息生成的顺序读取它们。消费者通过检查消息的偏移量来区分已经读过的消息。偏移量是另一种元数据,它是一个不断递增的整数值,在创建消息时,Kafka会把它添加到消息里面,在给定的分区里,每个消息的偏移量都是唯一的。消费者把每个分区最后读取的消息偏移量保存在Zookeeper或Kafka上,如果消费者关闭或重启,它的读取状态不会丢失。 消费者是消费者群组的一部分,一个或多个消费者共同读取一个主题。群组保证每个分区只能被一个消费者使用
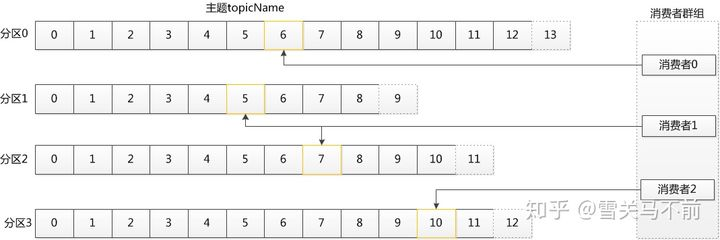
(5)broker和集群
一个独立的Kafka服务器称为broker,broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。根据特定的硬件及其性能特征,单个broker可以轻松处理数千个分区以及每秒百万级的消息量。
broker是集群的组成部分。每个集群都有一个broker同时充当了集群控制器的角色(自动从集群的活跃成员中选举出来)。控制器负责管理工作,包括将分区分配给broker和监控broker。在集群中,一个分区从属于一个broker,该broker被称为分区的首领。一个分区可以分配多个broker,这个时候会发生分区复制。这种复制机制为分区提供了消息冗余,如果一个broker失效,其他broker可以接管领导权。不过,相关的消费者和生产者都要重新连接到新的首领。
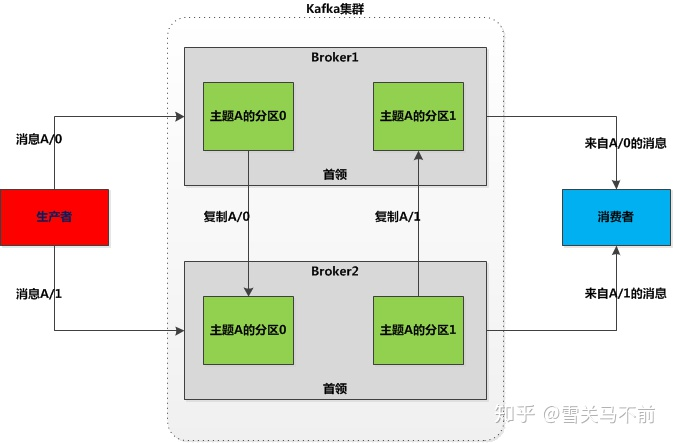
保留消息是Kafka的一个重要特性。Kafka broker默认的消息保留策略有两种。
- 保留一段固定的时间。比如7天
- 保留到消息达到一定大小的字节数,如1GB 当达到上限后,旧的消息会被过期删除。所以在任何时刻,可用消息的总量不会超过配置参数所指定的大小。
(6)多集群
Kafka的消息复制机制只能在单个集群里面进行,不能在多个集群之间进行。Kafka提供了一个叫做MirrorMaker的工具,可以用它来实现集群间的消息复制。MirrorMaker的核心组件包含了一个生产者和一个消费者,两者通过一个队列相连。消费者从一个集群读取消息,生产者把消息发送到另一个集群。
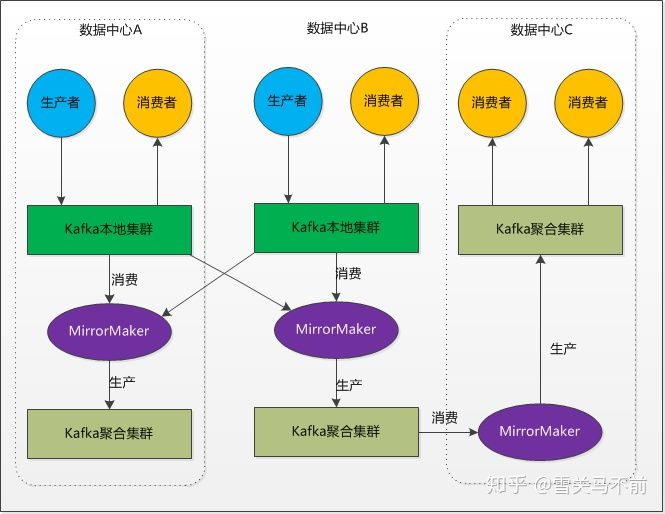
2. Kafka 核心概念
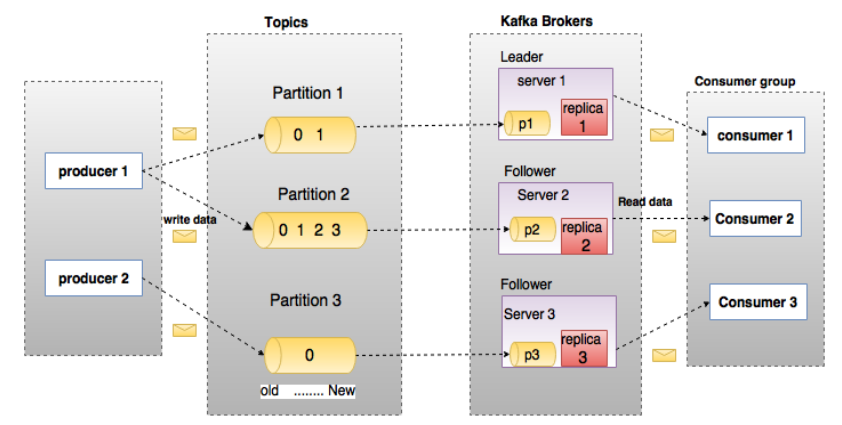
1. broker
Kafka 集群包含一个或多个服务器,服务器节点称为 broker
broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据
如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡
2. Topic
每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
3. Partition
topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1
4. Producer(生产者)
生产者创建消息。
该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的 segment 文件中。一般情况下,一个消息会被发布到一个特定的主题上。
Ⅰ. 默认情况下通过轮询吧消息均衡地分布到主题的所有分区上。
Ⅱ. 在某些情况下,生产者会吧消息直接写到指定的分区。这通常是通过消息键和分区器来实现的,分区器为键生成一个散裂值,并将其映射到指定的分区上。这样可以保证包含同一个键的消息会被写到同一个分区上。
Ⅲ. 生产者也可以使用自定义的分区器,根据不同的业务规则将消息映射到分区。
5. Consumer(消费者)
消费者读取消息。
A. 消费者订阅一个或多个主题,并按照消息生成的顺序读取它们。
B. 消费者通过检查消息的偏移量来区分已经读取过的消息。偏移量是另一种元数据,它是一个不断递增的整数值,在创建消息时,Kafka 会把它添加到消息里。在给定的分区里,每个消息的偏移量都是唯一的。消费者把分每个分区最后读取的消息偏移量保存在 Zookeeper 或 Kafka 上,如果消费者关闭或重启,它的读取状态不会丢失。
C. 消费者是消费组的一部分。群组保证每个分区只能被一个消费者使用。
D. 如果一个消费者失效,消费组里其它消费者可以接管失效消费者的工作,再平衡,分区重新分配。
6. Consumer Group
Kafka 和其他消息系统有一个不一样的设计,在 consumer 之上加了一层 group。同一个group的consumer可以并行消费同一个topic的消息,但是同group的consumer,不会重复消费。这就好比多个consumer组成了一个团队,一起干活,当然干活的速度就上来了。group中的consumer是如何配合协调的,其实和topic的分区相关联。
如果同一个topic需要被多次消费,可以通过设立多个consumer group来实现。每个group分别消费,互不影响。
7. Replicas
Kafka 使用主题来组织数据,每个主题被分为若干个分区,每个分区有多个副本。那些副本被保存 在broker 上,每个broker 可以保存成百上千个属于不同主题和分区的副本。副本有以下两种类型:
- Leader(首领副本)
每个分区都有一个首领副本,为了保证一致性,所有生产者请求和消费者请求都会经过这个副本。 - Follower(跟随者副本)
首领以外的副本都是跟随者副本。跟随者副本不处理来自客户端的请求,他们唯一的任务就是从首领副本那里复制消息,保持与首领副本一致的状态。如果首领发生崩溃,其中一个跟随者会被提升为新首领。
跟随者副本包括同步副本和不同步副本,在发生首领副本切换的过程中,只有同步副本可以切换为首领副本。
A. AR
分区中的所有副本统称为AR(Assigned Replicas)。AR=ISR+OSR
B. ISR
所有与 leader 副本保持一定程度同步的副本(包括leader)组成ISR(In-Sync Replicas),ISR 集合是 AR 集合中的一个子集。消息会先发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步,同步期间 follower 副本相对于 leader 副本而言会有一定程度的之后。前面所说的“一定程度”是指可以忍受的之后范围,这个范围可以通过参数进行配置。
C. OSR
与 leader 副本同步滞后过多的副本(不包括 leader)副本,组成 OSR(Out-Sync Replicas)。在正常情况下,所有的follower 副本都应该与 leader 副本保持一定程度的同步,即 AR=ISR,OSR 集合为空。
8. HW
HW 是 High Watermak 的缩写,缩成高水位,它表示了一个特定消息的偏移量(offset),消费者只能拉取到这个 offset 之前的消息。
9. LEO
LEO 是 Log End Offset 的缩写,它表示了当前日志文件中下一条待写入消息的 offset。
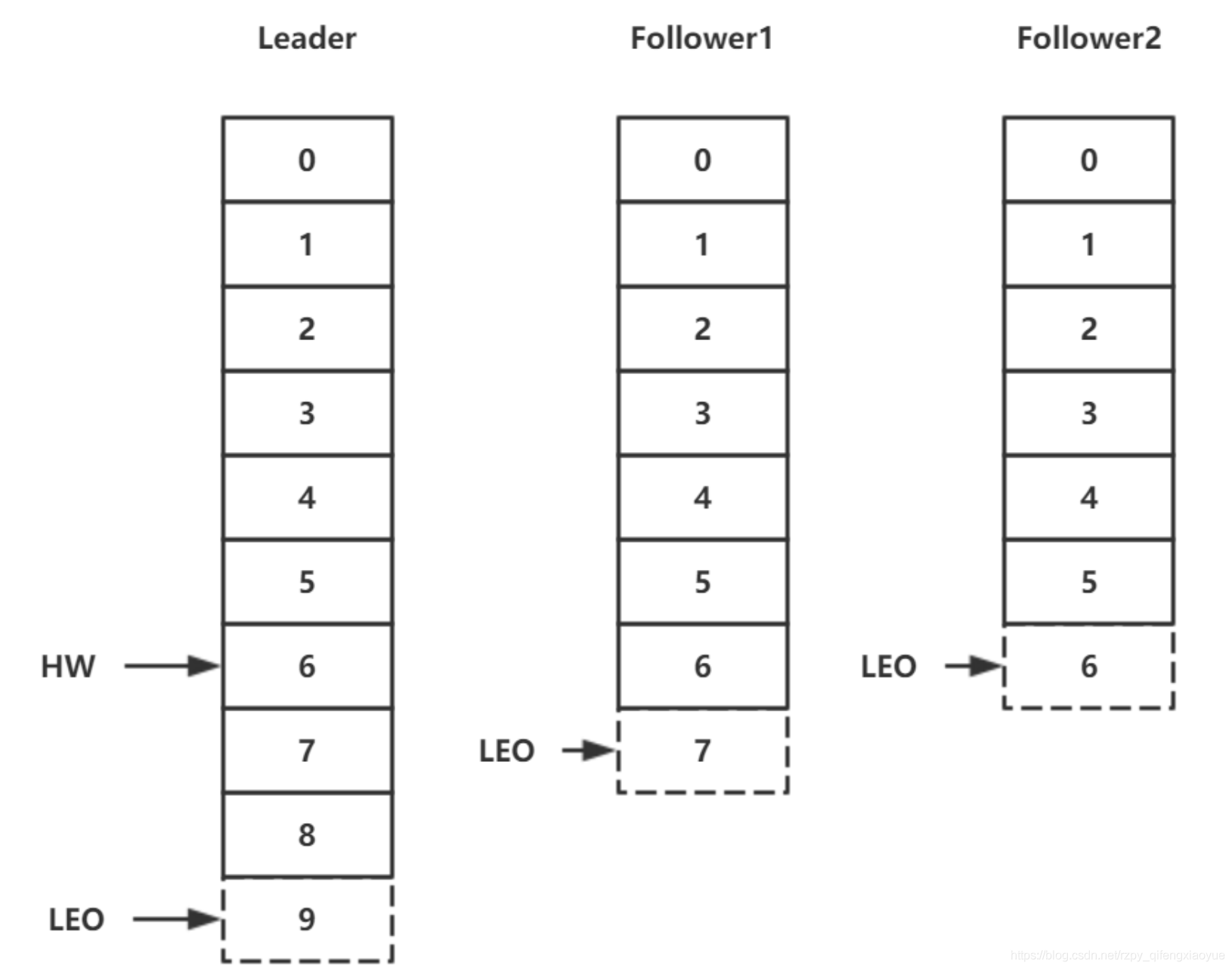
10. Offset 消息偏移量
- 生产者 Offset
消息写入的时候,每一个分区都有一个 offset,这个 offset 就是生产者 offset,同时也是这个分区的最新最大的 offset。有些时候没有指定某一个分区的 offset,这个工作 kafka 帮我们完成。
- 消费者 Offset
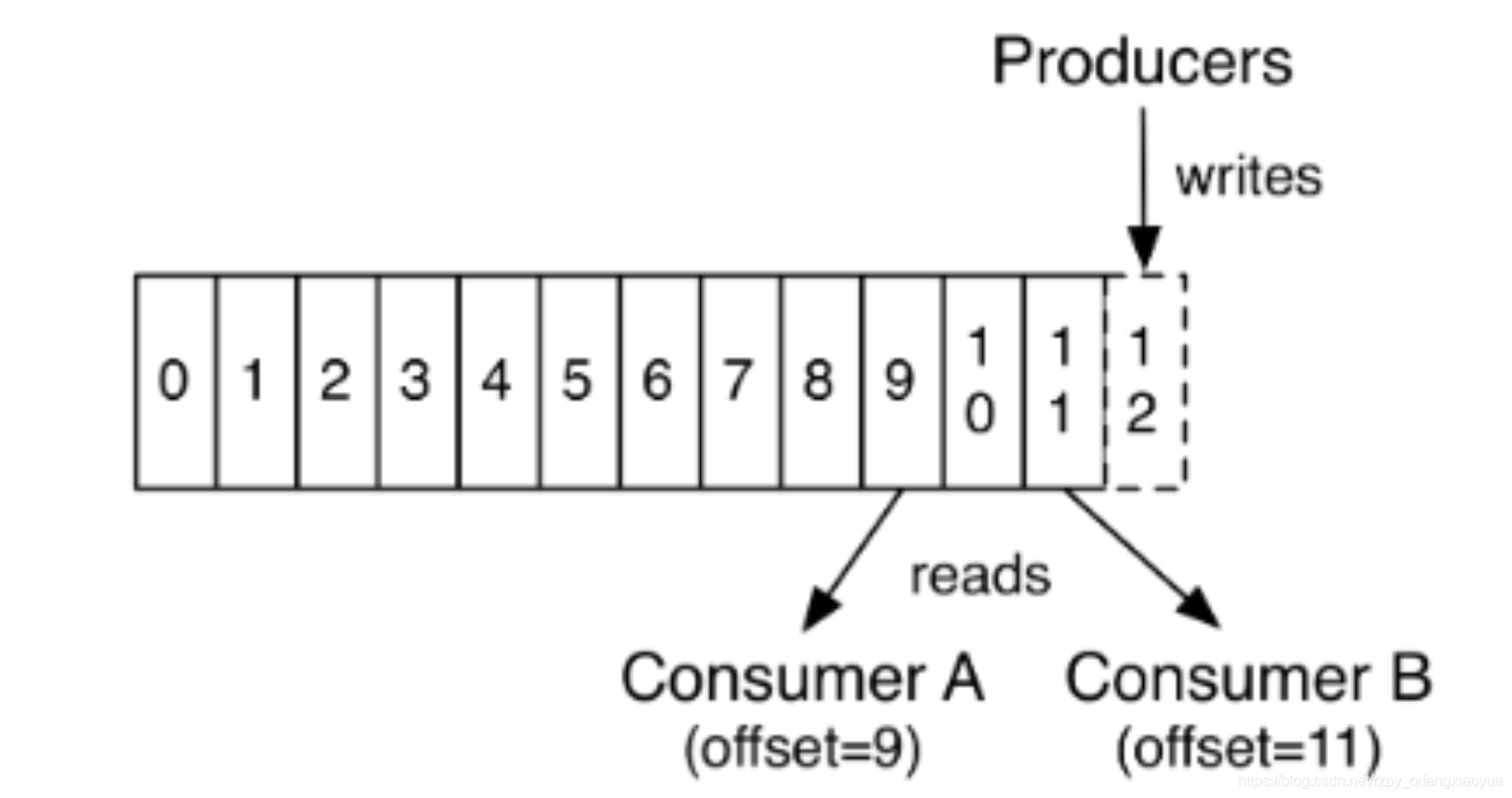
这是一个分区的 offset 情况,生产者写入的 offset 是最新最大的值是 12,而当 Consumer A 进行消费时,从 0 开始消费,一直消费到了 9,消费者的 offset 就记录到 9,Consumer B 就记录在了 11,。等一次他们在来消费时,他们可以选择接着上一次的位置消费,当然也可以选择从头消费,或者跳到最近的记录并从“现在”开始消费。
三. Kafka 的安装与配置
1. Java 环境的安装与配置(JDK 版本为 1.8)
2. Zookeeper 的安装与配置(版本为 3.4.14)
3. Kafka 的安装与配置
(1)下载 Kafka
wget https://archive.apache.org/dist/kafka/1.0.2/kafka_2.12-1.0.2.tgz
(2)解压下载的文件到指定的安装目录
tar -zxvf kafka_2.12-1.0.2.tgz -C 安装目录
(3)配置 Kafka 的环境变量以及其他相关配置
# 配置 kafka 的环境变量
vim /etc.profile
# 在 etc.profile 的文件末尾增加如下配置:
export KAFKA_HOME=kafka 的安装目录
export PATH=$PATH:$KAFKA_HOME/bin
# 使得环境变量生效
source /etc/profile
# 修改 kafka 的其他配置
# 进入到 kafka 的配置文件的目录
cd kafka 的安装目录/config
# 编辑 server.properties 文件
vim server.properties
# 修改 zookeeper 的连接(指定连接的zookeeper)
zookeeper.connect=linux121:2181/myKafka
# 修改日志存储位置
log.dirs=指定 log 文件存储位置
# 修改控制器
broker.id=0
# 修改监听信息
listeners=PLAINTEXT://:9092
(4)启动 kafka
- 前台启动(不推荐)
kafka-server-start.sh ../config/server.properties
- 后台启动
kafka-server-start.sh -daemon /opt/lagou/servers/kafka_2.12-1.0.2/config/server.properties

四. Kafka 的应用
1. 脚本应用-主题管理
(1)创建主题
kafka-topics.sh --create --zookeeper linux121:2181 --replication-factor 2 --partitions 3 --topic kafka-action
- --zookeeper 表示 zookeeper 所在的ip,--zookeeper 为必传参数,多个 zookeeper 用 ‘,’分开
--zookeeper 参数是之前版本的用法,从kafka 2.2 版本开始,社区推荐使用 --bootstrap-server 参数替换 --zoookeeper ,并且显式地将后者标记为 “已过期”,因此,如果你已经在使用 2.2 版本了,那么创建主题请指定 --bootstrap-server 参数。
推荐使用 --bootstrap-server 而非 --zookeeper 的原因主要有两个。 - 使用 --zookeeper 会绕过 Kafka 的安全体系。这就是说,即使你为 Kafka 集群设置了安全认证,限制了主题的创建,如果你使用 --zookeeper 的命令,依然能成功创建任意主题,不受认证体系的约束。这显然是 Kafka 集群的运维人员不希望看到的。
- 使用 --bootstrap-server 与集群进行交互,越来越成为使用 Kafka 的标准姿势。换句话说,以后会有越来越少的命令和 API 需要与 ZooKeeper 进行连接。这样,我们只需要一套连接信息,就能与 Kafka 进行全方位的交互,不用像以前一样,必须同时维护 ZooKeeper 和 Broker 的连接信息。
--partitions 用于设置主题分区数,每个线程处理一个分区数据
--replication-factor 用于设置主题副本数,每个副本分布在不同的节点,不能超过总结点数。如你只有一个节点,但是创建时指定副本数为2,就会报错。
(2)查询主题 - 查看所有主题
kafka-topics.sh --zookeeper linux121:2181/clusterKafka --list

- 查看某个特定主题信息,不指定 topic 则查询所有
kafka-topics.sh --zookeeper linux121:2181/clusterKafka --describe --topic 主题名称

(3)修改主题
- 修改主题分区(增加分区)
kafka-topics.sh --zookeeper zookeeper的 ip:port --alter --topic <topic_name> --partitions < 新分区数 >
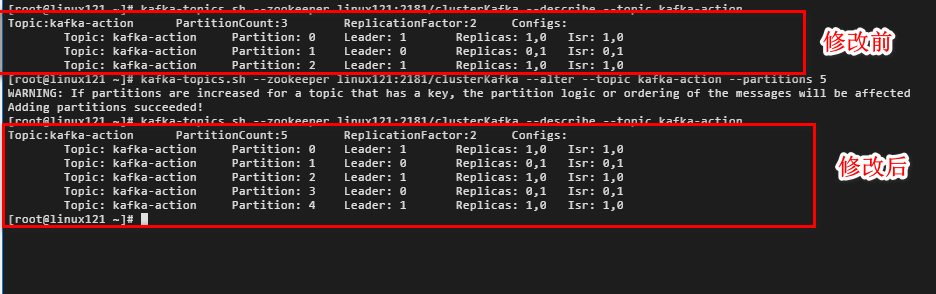
注意:指定的分区数一定要比原有的分区数大,否则 Kafka 会抛出 InvalidPartitionsException 异常

- 修改主题级别参数
在主题创建之后,我们可以使用kafka-configs脚本修改对应的参数。
kafka-configs.sh --zookeeper zookeeper_host:port --entity-type topics --entity-name <topic_name> --alter --add-config max.message.bytes=10485760
- 变更副本数
使用自带的kafka-reassign-partitions脚本,帮助我们增加主题的副本数。
假设kafka的内部主题 __consumer_offsets 只有 1 个副本,现在我们想要增加至 3 个副本。下面是操作: -
- 1.创建一个 json 文件,显示提供 50 个分区对应的副本数。注意:replicas 中的 3 台 Broker 排列顺序不同,目的是将 Leader 副本均匀地分散在 Broker 上。该文件具体格式如下:
{"version":1, "partitions":[
{"topic":"__consumer_offsets","partition":0,"replicas":[0,1,2]},
{"topic":"__consumer_offsets","partition":1,"replicas":[0,2,1]},
{"topic":"__consumer_offsets","partition":2,"replicas":[1,0,2]},
{"topic":"__consumer_offsets","partition":3,"replicas":[1,2,0]},
...
{"topic":"__consumer_offsets","partition":49,"replicas":[0,1,2]}
]}
-
- 2.执行
kafka-reassign-partitions脚本,命令如下:
- 2.执行
kafka-reassign-partitions.sh --zookeeper zookeeper_host:port --reassignment-json-file reassign.json --execute
- 查看消费者提交的位移数据
kafka-console-consumer.sh --bootstrap-server kafka_host:port --topic __consumer_offsets --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning
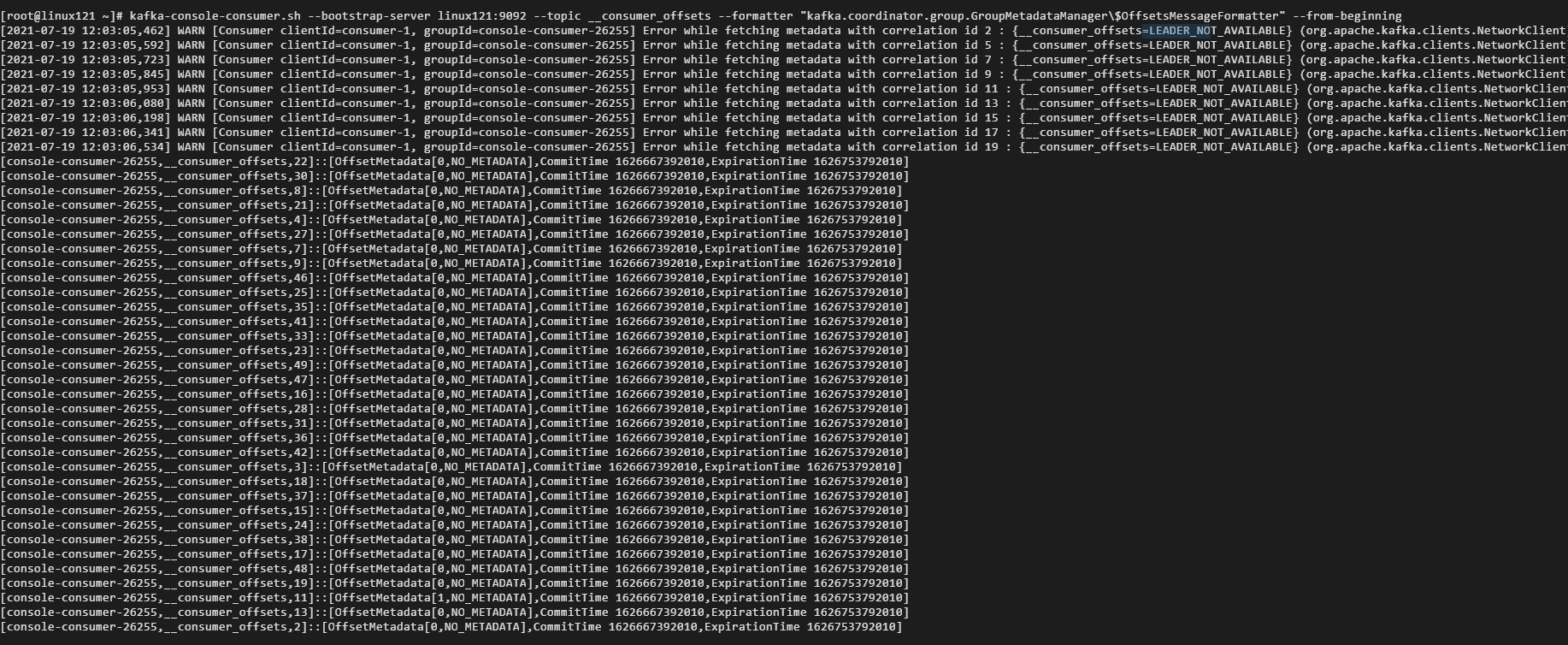
- 查看消费者组的状态信息
kafka-console-consumer.sh --bootstrap-server kafka_host:port --topic __consumer_offsets --formatter "kafka.coordinator.group.GroupMetadataManager\$GroupMetadataMessageFormatter" --from-beginning

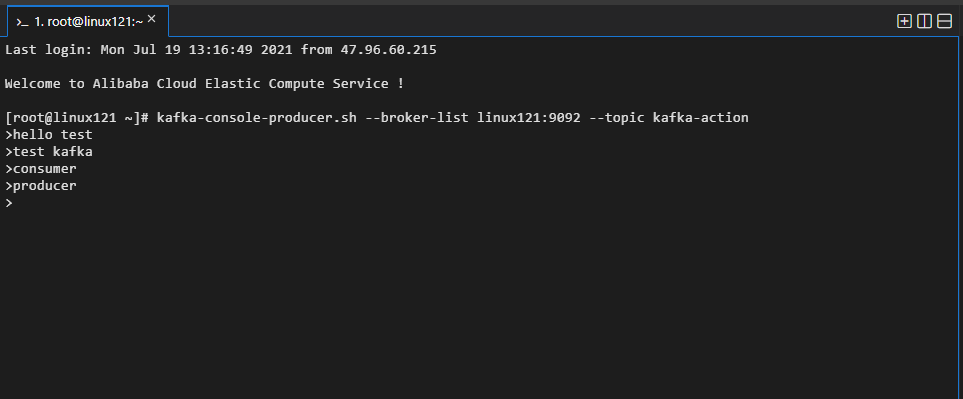
2. 脚本应用-生产者操作
kafka-console-producer.sh --broker-list kafka_host:port --topic <topic_name>
3. 脚本应用-消费者操作
kafka-console-consumer.sh --bootstrap-server kafka_host:port --topic <topic_name>

kafka-console-consumer.sh --bootstrap-server kafka_host:port --topic <topic_name> --from-beginning
--from-beginning 添加后可以接收到所有的消息,包括中断前的消息
4.客户端应用-生产者
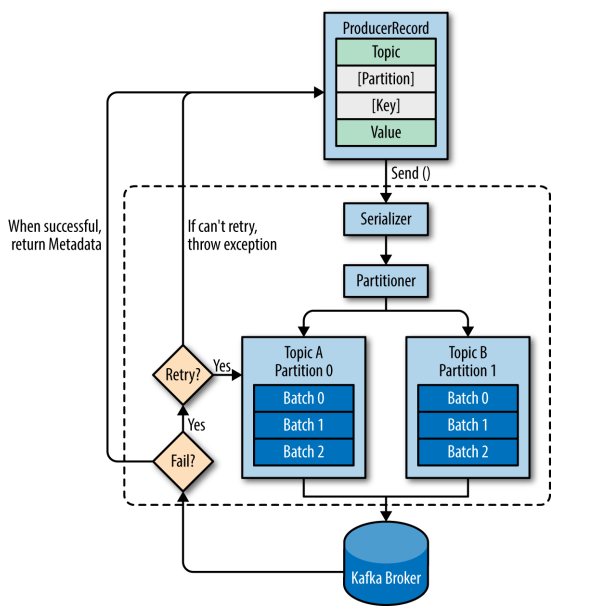
(1)生产者发送消息的过程
- Kafka 会将发送消息包装为
ProducerRecord对象,ProducerRecord对象包含了目标主题和要发送的内容,同时还可以指定键和分区。在发送ProducerRecord对象前,生产者会先把键和值对象序列化成字节数组,这样它们才能够在网络上传输。 - 接下来,数据被传给分区器。如果之前已经在
ProducerRecord对象里指定了分区,那么分区器就不会再做任何事情。如果没有指定分区,那么分区器会根据ProducerRecord对象的键来选择一个分区,紧接着,这条记录被添加到一个记录批次里,这个批次里的所有消息会被发送到相同的主题和分区上。有一个独立的线程负责把这些记录批次发送到相应的broker上。 - 服务器在收到这些消息时会返回一个响应。如果消息成功写入
Kafka,就返回一个RecordMetaData对象,它包含了主题和分区信息,以及记录在分区里的偏移量。如果写入失败,则会返回一个错误。生产者在收到错误之后会尝试重新发送消息,如果达到指定的重试次数还没有成功,则直接抛出异常,不在重试。
(2)创建生产者
- 项目依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.0.2</version>
</dependency>
- 创建生产者
创建Kafka生产者时,以下三个属性是必须指定的:bootstrap.servers:指定 broker 的地址清单,清单里不需要包含所有的 broker 地址,生产者会从给定的 broker 里查找 broker 的信息。不过建议至少要提供两个 broker 的信息作为容错key.serializer:指定键的序列化器value.serializer:指定值的序列化器
package com.lagou.kafka.demo;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class SimpleProducer {
public static void main(String[] args) {
String topicName = "Hello-Kafka";
// 创建属性类
Properties props = new Properties();
// 指定 broker 的地址清单
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"47.95.26.48:9092");
// 指定键的序列化器
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 指定值的序列化器
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class);
// 创建生产者
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topicName, "hello" + i, "world" + i);
// 发送消息
producer.send(producerRecord);
}
// 关闭生产者
producer.close();
}
}
(3)发送消息
上面的示例程序调用了 send 方法发送消息后没有做任何操作,在这种情况下,我们没有办法知道消息发送的结果。想要知道消息发送的结果,可以使用同步发送或者异步发送来实现。
- 同步发送消息
在调用send方法后可以接着调用get()方法,send方法的返回值是一个Future<RecordMetadata>对象,RecordMetadata里面包含了发送消息的主题、分区、偏移量等信息。该写后的代码如下:
package com.lagou.kafka.demo;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class SimpleProducer {
public static void main(String[] args) {
String topicName = "Hello-Kafka";
// 创建属性类
Properties props = new Properties();
// 指定 broker 的地址清单
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"47.95.26.48:9092");
// 指定键的序列化器
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 指定值的序列化器
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class);
// 创建生产者
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
try {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topicName, "hello" + i, "world" + i);
// 同步发送消息
RecordMetadata metadata = producer.send(producerRecord).get();
System.out.printf("topic=%s, partition=%d, offset=%s \n",
metadata.topic(), metadata.partition(), metadata.offset());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
// 关闭生产者
producer.close();
}
}
- 异步发送消息
通常我们并不关心发送成功的情况,更多关注的是失败的情况,因此Kafka提供了异步发送和回调函数。代码如下:
package com.lagou.kafka.demo;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class SimpleProducer {
public static void main(String[] args) {
String topicName = "Hello-Kafka";
// 创建属性类
Properties props = new Properties();
// 指定 broker 的地址清单
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"47.95.26.48:9092");
// 指定键的序列化器
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 指定值的序列化器
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class);
// 创建生产者
Producer<String, String> producer = new KafkaProducer<>(props);
// 异步发送消息
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topicName, "异步" + i, "world" + i);
producer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e != null) {
System.out.println("进行异常处理");
} else {
System.out.printf("topic=%s, partition=%d, offset=%s \n",
metadata.topic(), metadata.partition(), metadata.offset());
}
}
});
}
// 关闭生产者
producer.close();
}
}
(4)自定义分区器
Kafka 有默认的分区机制:
- 如果键值为 null,则是用轮询(Round Robin)算法将消息均衡地分布到各个分区上;
- 如果键值不为 null,那么 Kafka 会使用内置的散列算法对键进行散列,然后分不到各个分区上。
- 但在某些情况下,我们需要按照自己的需求进行分区,这时候可以采用自定义分区器实现。
- 创建自定义分区器
package com.lagou.kafka.demo;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.utils.Utils;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.atomic.AtomicInteger;
public class CustomPartitioner implements Partitioner {
private final ConcurrentMap<String, AtomicInteger> topicCounterMap = new ConcurrentHashMap();
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if(keyBytes == null) {
int nextValue = this.nextValue(topic);
List availablePartitions = cluster.availablePartitionsForTopic(topic);
if(availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return ((PartitionInfo)availablePartitions.get(part)).partition();
} else {
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
@Override
public void close() {
System.out.println("分区器关闭");
}
@Override
public void configure(Map<String, ?> map) {
}
private int nextValue(String topic) {
AtomicInteger counter = (AtomicInteger)this.topicCounterMap.get(topic);
if(null == counter) {
counter = new AtomicInteger((new Random()).nextInt());
AtomicInteger currentCounter = (AtomicInteger)this.topicCounterMap.putIfAbsent(topic, counter);
if(currentCounter != null) {
counter = currentCounter;
}
}
return counter.getAndIncrement();
}
}
- 在创建生产者时指定分区器
// 指定自定义分区器 props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.lagou.kafka.demo.CustomPartitioner");
5.客户端应用-消费者
(1)消费者和消费者组
Kafka为这两种模型提供了单一的消费者抽象模型: 消费者组 (consumer group)。 消费者用一个消费者组名标记自己。 一个发布在Topic上消息被分发给此消费者组中的一个消费者。 假如所有的消费者都在一个组中,那么这就变成了队列模型。 假如所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型。 一个消费者组中消费者订阅同一个Topic,每个消费者接受Topic的一部分分区的消息,从而实现对消费者的横向扩展,对消息进行分流。
注意:当单个消费者无法跟上数据生成的速度,就可以增加更多的消费者分担负载,每个消费者只处理部分partition的消息,从而实现单个应用程序的横向伸缩。但是不要让消费者的数量多于partition的数量,此时多余的消费者会空闲。此外,Kafka还允许多个应用程序从同一个Topic读取所有的消息,此时只要保证每个应用程序有自己的消费者组即可。
消费者组的概念就是:当有多个应用程序都需要从Kafka获取消息时,让每个app对应一个消费者组,从而使每个应用程序都能获取一个或多个Topic的全部消息;在每个消费者组中,往消费者组中添加消费者来伸缩读取能力和处理能力,消费者组中的每个消费者只处理每个Topic的一部分的消息,每个消费者对应一个线程。
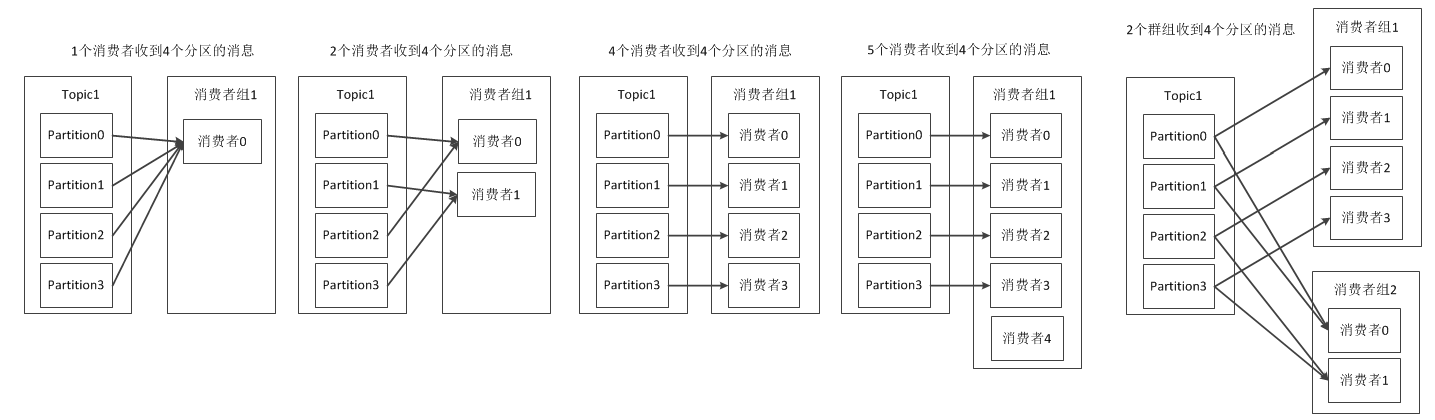
在同一个群组中,无法让一个线程运行多个消费者,也无法让多线线程安全地共享一个消费者。按照规则,一个消费者使用一个线程,如果要在同一个消费者组中运行多个消费者,需要让每个消费者运行在自己的线程中。最好把消费者的逻辑封装在自己的对象中,然后使用java的ExecutorService启动多个线程,使每个消费者运行在自己的线程上,可参考https://www.confluent.io/blog
(2)创建Kafka消费者、订阅主题、轮询
package com.lagou.demo.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Collections;
import java.util.Properties;
public class SimpleConsumer {
public static void main(String[] args) {
// 配置消费者的参数
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"linux121:9092");
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"consumer_kafka");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
// 创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
// 订阅主题
consumer.subscribe(Collections.singleton("Hello-Kafka"));
// 轮询
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.topic() + record.partition() + record.offset() + record.key() + record.value());
//统计各个地区的客户数量,即模拟对消息的处理
// int updatedCount = 1;
// updatedCount += custCountryMap.getOrDefault(record.value(), 0) + 1;
// custCountryMap.put(record.value(), updatedCount);
//
// //真实场景中,结果一般会被保存到数据存储系统中
// JSONObject json = new JSONObject(custCountryMap);
// System.out.println(json.toString(4));
}
}
} finally {
// 关闭消费者
consumer.close();
}
}
}
五. Kafka 高级特性
1. 生产者
(1)数据生产流程
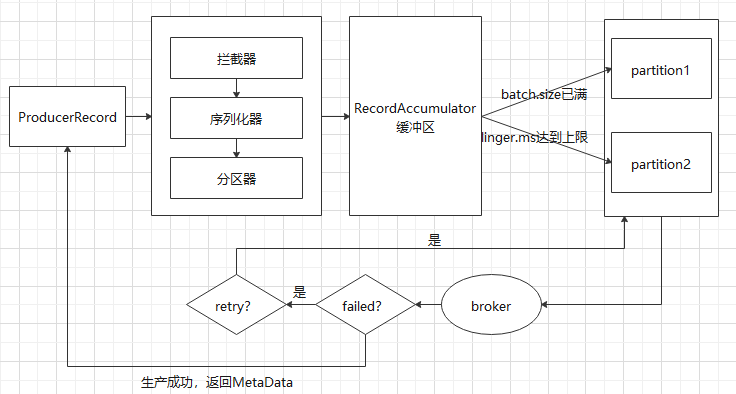
- Producer创建时,会创建一个Sender线程并设置为守护线程
- 生产消息时,内部其实是异步流程;生产的消息先经过拦截器->序列化器->分区器,然后将消息缓存在缓冲区(该缓冲区也是在Producer创建时创建)
- 批次发送的条件为:缓冲区数据大小达到batch.size或者linger.ms达到上限
- 批次发送后,发往指定分区,然后落盘到broker;如果生产者配置了retrires参数大于0并且失败原因允许重试,那么客户端内部会对该消息进行重试
- 落盘到broker成功,返回生产元数据给生产者
元数据返回有两种方式:一种是通过阻塞直接返回,另一种是通过回调返回
(2)自定义序列化器
- 创建自定义序列化器
package com.lagou.demo.serializer;
import org.apache.kafka.common.serialization.Serializer;
import org.codehaus.jackson.map.ObjectMapper;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Map;
public class UserSerializer implements Serializer {
private ObjectMapper objectMapper;
@Override
public void configure(Map configs, boolean isKey) {
objectMapper = new ObjectMapper();
}
@Override
public byte[] serialize(String s, Object o) {
byte[] ret = null;
try {
ret = objectMapper.writeValueAsString(o).getBytes(StandardCharsets.UTF_8);
} catch (IOException e) {
System.out.println("序列化失败");
e.printStackTrace();
}
return ret;
}
@Override
public void close() {
}
}
- 构建生产者属性时指定使用自定义序列化器
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "com.lagou.demo.serializer.UserSerializer");
(3)分区器
- 分区的原因
方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了
可以提高并发,因为可以以Partition为单位读写了 - 分区的原则
- 指定了 partition,则直接使用
- 未指定 partition 但指定 key,通过对 key 的 value 进行 hash 出一个 partition
- partition 和 key 都未指定,使用轮询选出一个 partition
(4)拦截器
-
简介
kafka生产者拦截器主要用于在消息发送前对消息内容进行定制化修改,以便满足相应的业务需求,也可用于在消息发送后获取消息的发送状态,所在分区和偏移量等信息。同时,用户可以在生产者中指定多个拦截器形成一个拦截器链,生产者会根据指定顺序先后调用。 -
kafka 生产者拦截器的访问流程
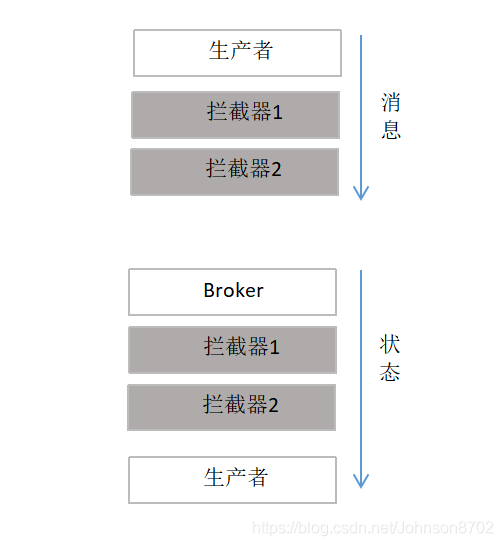
-
生产者拦截器的实现
- 自定义拦截器类,实现
org.apache.kafka.clients.producer.ProducerInterceptor接口- 时间拦截器
- 自定义拦截器类,实现
package com.lagou.demo.interceptors;
import com.lagou.demo.entity.User;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
/**
* 时间拦截器,发送消息之前,在消息内容前面加入时间戳
*/
public class TimeInterceptor implements ProducerInterceptor<String, User> {
/**
* 该方法在消息发送之前调用
* 对原消息记录进行修改,在消息内容最前边添加时间戳
* @param producerRecord 生产者发送的消息记录,并自动传入
* @return 修改后的消息记录
*/
@Override
public ProducerRecord<String, User> onSend(ProducerRecord<String, User> producerRecord) {
System.out.println("TimeInterceptor--------------->onSend方法被调用");
// 创建一个新的 producerRecord,把时间戳写到消息体的最前面
User user = producerRecord.value();
user.setFirstName(System.currentTimeMillis() + user.getFirstName());
ProducerRecord record = new ProducerRecord<String,User>(producerRecord.topic(), producerRecord.key(),producerRecord.value() );
return record;
}
/**
* 该方法在消息发送完毕后调用
* 当发送到服务器的记录已被确认,或者记录发送失败时,将调用此方法
* @param recordMetadata
* @param e
*/
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
System.out.println("TimeInterceptor-------onAcknowledgement方法被调用");
}
@Override
public void close() {
}
/**
* 获取生产者配置信息
* @param map
*/
@Override
public void configure(Map<String, ?> map) {
System.out.println(map.get(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG));
}
}
-
-
- 状态拦截器
-
package com.lagou.demo.interceptors;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
public class CounterInterceptor implements ProducerInterceptor<String,String> {
// 发送成功的消息数量
private int successCounter = 0;
// 发送失败的消息数量
private int errCounter = 0;
/**
* 该方法在消息发送之前调用
* 对原消息记录进行修改,在消息内容最前边添加时间戳
* @param producerRecord 生产者发送的消息记录,并自动传入
* @return 修改后的消息记录
*/
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> producerRecord) {
System.out.println("CounterInterceptor------------------->onSend方法被调用了");
return producerRecord;
}
/**
* 该方法在消息发送完毕后调用
* 当发送到服务器的记录已被确认,或者记录发送失败时,将调用此方法
* @param recordMetadata
* @param exception
*/
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception exception) {
System.out.println("CounterInterceptor-------onAcknowledgement方法被调用");
// 统计成功和失败的次数
if (exception == null) {
successCounter ++;
}else{
errCounter ++;
}
}
/**
* 当生产者关闭时调用该方法,可以在此将结果进行持久化保存
*/
@Override
public void close() {
System.out.println("CounterInterceptor------->close方法被调用");
// 打印统计结果
System.out.println("发送成功的消息数量: " + successCounter);
System.out.println("发送失败的消息数量: " + errCounter);
}
/**
* 获取生产者消息的配置信息
* @param map
*/
@Override
public void configure(Map<String, ?> map) {
System.out.println(map.get(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG));
}
}
-
- 在定义生产者属性的时候指定拦截器
List<String> interceptors = new ArrayList<>();
interceptors.add("com.lagou.demo.interceptors.CounterInterceptor");
interceptors.add("com.lagou.demo.interceptors.TimeInterceptor");
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,interceptors);
-
- 启动消费者
kafka-console-consumer.sh --bootstrap-server linux121:9092 --topic Hello-Kafka-Interceptor
-
- 运行生产者程序,观察 kafka 消费端和 IDEA 控制台输出信息

2. 消费者
(1)订阅主题
(2)反序列化
(3)消费者位移
(4)心跳机制
(5)再均衡
(6)拦截器
3. 主题管理
(1)副本分割机制
(2)分区重新分配
4. 物理存储
(1)日志索引文件
(2)日志清理机制
- 日志压缩
- 日志删除
5. 磁盘存储
(1)零拷贝
(2)页缓存
(3)顺序写入
六. Kafka 集群配置
1.集群配置规划
| linux121 | linux122 | linux123 |
|---|---|---|
| zookeeper1 | zookeeper2 | zookeeper3 |
| broker0 | broker1 | broker2 |
2. 集群配置
(1)配置 java 环境变量
(2)配置 zookeeper 集群环境
(3)配置 kafka 集群环境
- 配置 kafka 环境变量
# 修改 环境变量的配置文件
vim /etc/profile
# 在文件的末端添加如下内容
# KAFKA_HOME
export KAFKA_HOME=/opt/lagou/servers/kafka_2.12-1.0.2
export PATH=$PATH:${KAFKA_HOME}/bin
- 修改 kafka 配置文件
# linux121
# 进入到 kafka 的安装目录的配置文件目录下
cd /opt/lagou/servers/kafka_2.12-1.0.2/config
# 编辑 server.properties
vim server.properties
broker.id=0
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://linux121:9092
log.dirs=/var/lagou/kafka/kafka-cluster-logs
zookeeper.connect=linux121:2181,linux122:2181,linux123:2181/clusterKafka
- 发送消息
# linux122
# 进入到 kafka 的安装目录的配置文件目录下
cd /opt/lagou/servers/kafka_2.12-1.0.2/config
# 编辑 server.properties
vim server.properties
broker.id=1
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://linux122:9092
log.dirs=/var/lagou/kafka/kafka-cluster-logs
zookeeper.connect=linux121:2181,linux122:2181,linux123:2181/clusterKafka
# linux123
# 进入到 kafka 的安装目录的配置文件目录下
cd /opt/lagou/servers/kafka_2.12-1.0.2/config
# 编辑 server.properties
vim server.properties
broker.id=2
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://linux123:9092
log.dirs=/var/lagou/kafka/kafka-cluster-logs
zookeeper.connect=linux121:2181,linux122:2181,linux123:2181/clusterKafka
# 分别启动三台服务器上的 kafka 服务
kafka-server-start.sh /opt/lagou/servers/kafka_2.12-1.0.2/config/server.properties
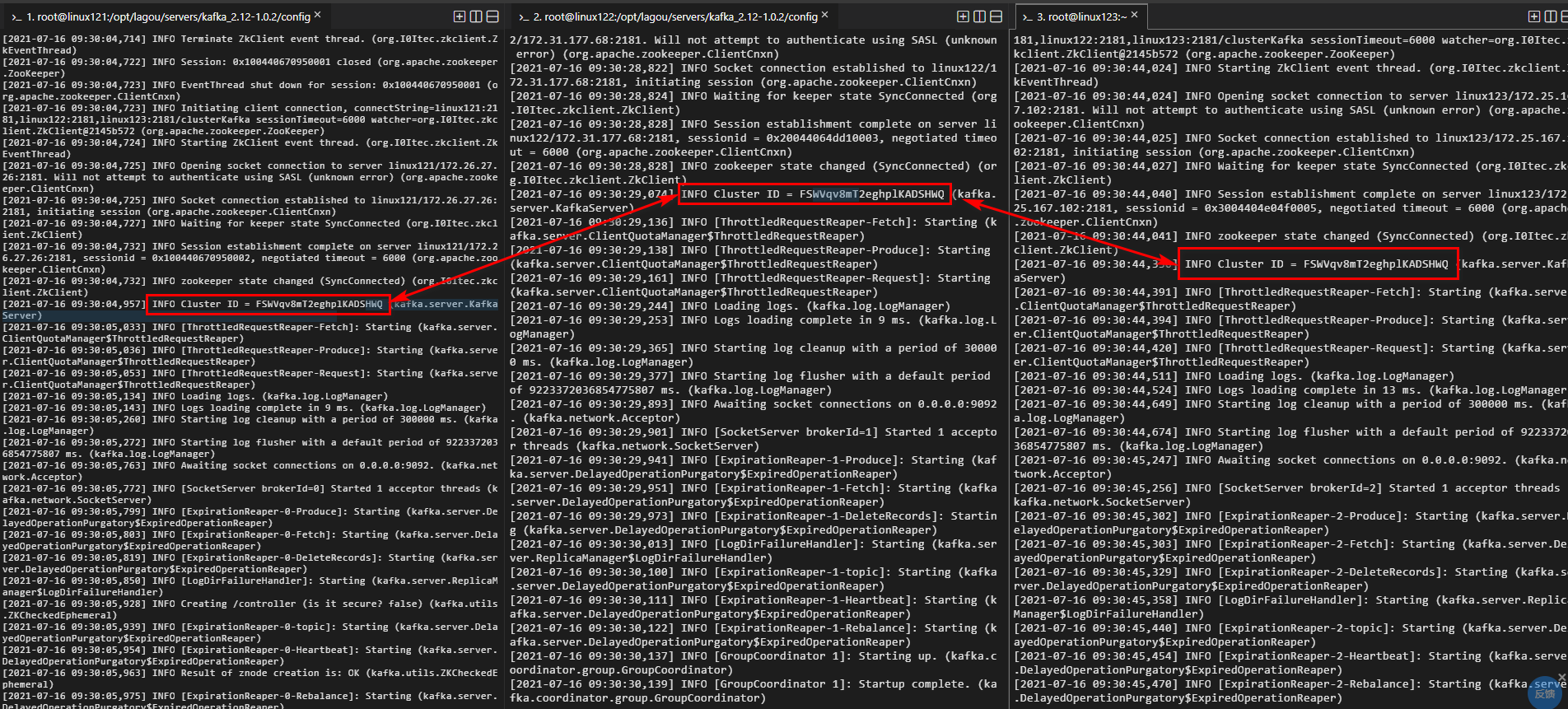
如何确认三个 KAFKA 服务在一个集群中?