Spark中的数据本地性
分布式数据并行环境下,保持数据的本地性是非常重要的内容,事关分布式系统性能高下。
概念:
block : HDFS的物理空间概念,固定大小,最小是64M,可以是128,256 。。也就是说单个文件大于block的大小,肯定会被切分,被切分的数目大概是:比如文件是250M,block是64M,就会被分为4个block,64+64+64+58,最后一个block没有满,一个block只能有一个文件的内容,加上每个block一般有3个副本存在,那么这个文件在HDFS集群就有12个block分布,可能分布在datanode1,2,3,4 可能分布在datanode4,5,6,7 所以并不是所有的datanode都有这个文件的block
最理想的情况,我们希望一个文件的所有block在一个datanode上面都可以找到,这样可以在读数据的时候避免网络传输
partition: spark的计算数据概念,是RDD的最小单位,它的大小不是固定的,一般是根据集群的计算能力,以及block的数量来决定的,也就是说partition的个数我们是可以自己指定的
spark内部有2种分区策略,一种是hashpartition,一种是rangepartition,其实就是根据key,把k-v数据合理的划分为多个partition,然后对数据进行规划和计算
worker:spark计算集群中,非master节点,它的分布也是在某些node上面
rack:数据中心由一堆堆的rack组成,一个rack由多个datanode组成,在rack中的datanode可以看做本地数据,因为网络比较好
所以有data的node不一定上面有worker,同样有worker的node上面不一定有合适的数据,这样问题就抽象成为,如何让读取HDFS的时候,spark整体开销最小,这就是本地性的问题
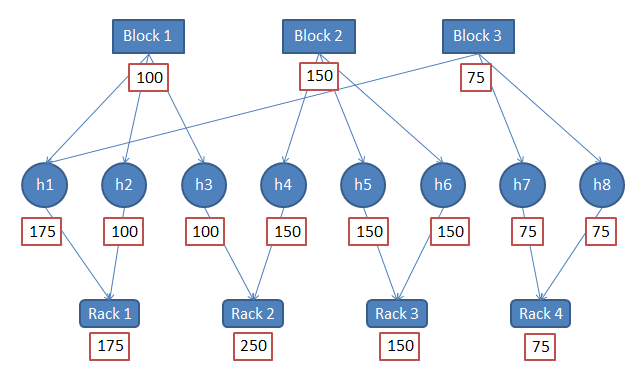
因为上面3个block的数据不一样,所以我们在选择worker(h)的时候,要考虑哪个是最佳计算worker
考虑rack的网络本地性,h4 h3 h1 h2 h5 h6 h7 h8
不考虑rack的网络本地性,h1 h4 h5 h6 h2 h3 h7 h8
task运行在哪个机器h上面,是在DAGscheduler在进行stage的划分的时候,确定的
选出了计算节点的顺序,就可以告诉spark的partition(RDD),然后在h上启动executor/tasker,然后读取数据,h从哪个节点获得block呢?block的几个副本离h的远近不同,网络开销不一样


 浙公网安备 33010602011771号
浙公网安备 33010602011771号