

机器学习总结(四)损失函数的总结
在监督学习中,给定输入x,可根据假设函数f(x)预测输出相应的Y。这个f(x)与Y可能一致,也可能不一致。用损失函数来度量预测错误的程度。通常希望的是损失函数的值越小越好。我们一般是通过优化损失函数,把损失函数的值最小时的参数作为预测函数的参数值。
常见的损失函数有:
一:0-1损失函数
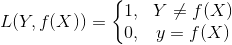
二:平方损失函数
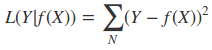
常见用于回归问题,如线性回归,CART树的回归问题,意义就是预测值与真实值之间的差值越小越好。
三:绝对损失函数

与平方损失类似
四:log对数损失函数
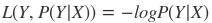
最常见的就是用在逻辑回归中,在逻辑回归中我们希望后验概率P(Y|X)越大越好,在前面加了对数后,不改变其单调性。所以加了负号以后就是我们所想得到的损失函数。
五:指数损失函数
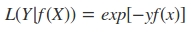
主要是见于Adaboost算法
六:hinge函数(合页损失函数 )
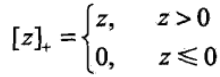
主要见于线性支持向量机算法,

如上式,只有1-y(wx+b)大于0时,即z大于0时,损失为1-y(wx+b)。当z小于0,即1-y(wx+b)小于0时,损失为0。
