

POJ 1470 Closest Common Ancestors (Tarjan)
Closest Common Ancestors
| Time Limit: 2000MS | Memory Limit: 10000K | |
| Total Submissions: 12745 | Accepted: 4162 |
Description
Write a program that takes as input a rooted tree and a list of pairs of vertices. For each pair (u,v) the program determines the closest common ancestor of u and v in the tree. The closest common ancestor of two nodes u and v is the node w that is an ancestor of both u and v and has the greatest depth in the tree. A node can be its own ancestor (for example in Figure 1 the ancestors of node 2 are 2 and 5)
Input
The data set, which is read from a the std input, starts with the tree description, in the form:
nr_of_vertices
vertex:(nr_of_successors) successor1 successor2 ... successorn
...
where vertices are represented as integers from 1 to n ( n <= 900 ). The tree description is followed by a list of pairs of vertices, in the form:
nr_of_pairs
(u v) (x y) ...
The input file contents several data sets (at least one).
Note that white-spaces (tabs, spaces and line breaks) can be used freely in the input.
nr_of_vertices
vertex:(nr_of_successors) successor1 successor2 ... successorn
...
where vertices are represented as integers from 1 to n ( n <= 900 ). The tree description is followed by a list of pairs of vertices, in the form:
nr_of_pairs
(u v) (x y) ...
The input file contents several data sets (at least one).
Note that white-spaces (tabs, spaces and line breaks) can be used freely in the input.
Output
For each common ancestor the program prints the ancestor and the number of pair for which it is an ancestor. The results are printed on the standard output on separate lines, in to the ascending order of the vertices, in the format: ancestor:times
For example, for the following tree:
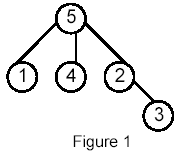
For example, for the following tree:
Sample Input
5
5:(3) 1 4 2
1:(0)
4:(0)
2:(1) 3
3:(0)
6
(1 5) (1 4) (4 2)
(2 3)
(1 3) (4 3)
Sample Output
2:1 5:5
Hint
Huge input, scanf is recommended.
Source
离线算法(Tarjan):
伪代码如下:

注意:
存储树的时候存储的是单向边,所以checked[u] = true 写在中间不会出现死循环, 这样可以避免重复计算公共祖先。
如果存储的树是双向边的话,就必须写在前面,这样子可以避免死循环,双向边的情况如下

但是这道问题确实统计公共祖先的次数的,因此如果将checked[u] = true 放到前面的话,可能会重复计数。随意用单向边放到中间。
完全解决这个纠结的小问题的方法是用两个不同的标记数组标记访问次序。此处略去……

#include<iostream> #include<cstdio> #include<cstring> #include<vector> using namespace std; const int N=1100; vector<int> edge[N]; int query[N][N],father[N],count[N],indeg[N]; int vis[N],n,m; int findSet(int x){ if(x!=father[x]){ father[x]=findSet(father[x]); } return father[x]; } void Tarjan(int u){ father[u]=u; for(int i=0;i<edge[u].size();i++){ Tarjan(edge[u][i]); father[edge[u][i]]=u; } vis[u]=1; for(int i=1;i<=n;i++) if(vis[i] && query[u][i]) count[findSet(i)]+=query[u][i]; } int main(){ //freopen("input.txt","r",stdin); while(~scanf("%d",&n)){ for(int i=1;i<=n;i++) edge[i].clear(); memset(query,0,sizeof(query)); memset(vis,0,sizeof(vis)); memset(count,0,sizeof(count)); memset(indeg,0,sizeof(indeg)); int u,v; for(int i=0;i<n;i++){ scanf("%d:(%d)",&u,&m); while(m--){ scanf(" %d",&v); edge[u].push_back(v); indeg[v]++; } } scanf(" %d",&m); for(int i=0;i<m;i++){ scanf(" (%d %d)",&u,&v); query[u][v]++; query[v][u]++; } for(int i=1;i<=n;i++) if(indeg[i]==0){ Tarjan(i); break; } for(int i=1;i<=n;i++) if(count[i]) printf("%d:%d\n",i,count[i]); } return 0; }
分类:
网络流
标签:
acm/icpc POJ


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架