

马哥教育Linux-第02周作业
学号:N74058
1. 总结linux安全模型
通过3A(认证、授权、审计)实现资源分配
1、用户:Linux中每个用户是通过UID来唯一标识的
2、用户组:Linux中可以将一个或多个用户加入用户组中,用户组是通过GID来唯一标识的
3、Linux安全上下文:运行中的程序,即进程,以进程发起者的身份运行,进程所能访问资源的权限取决于进程的运行者身份
2. 总结学过的权限,属性及ACL相关命令及选项,示例。
1、acl与ugo的区别 ugo(是指 user(也称为 owner)、group 和 other 三个单词的首字母组合。)设置基本权限:只能一个用户一个组和其他人。ACL文件权限管理:设置不同的用户,不同的基本权限(r / w / x),对象数量不同。
2、语法
命令:setfacl -m u: alice: rw /home/jack/test.txt (设置alice用户对文件具有读写的权限)
解释:命令 设置 用户或组:用户名:权限 文件对象
命令:getfacl /home/jack/test.txt (查看文件有哪些acl权限)
命令:setfacl -m g: hr: rw /home/jack/test.txt (设置acl权限,使组hr对test文件有读写权限)
命令:setfacl -x g: hr /home/jack/test.txt (删除组hr的acl权限)
命令:setfacl -b /home/jack/test.txt (删除所有的acl权限)
3. 结合vim几种模式,学会使用vim几个常见操作。
1)如何打开文件。并在打开文件(命令模式)之后如何退出文件。
VIM 打开文件 [root@localhost ~]# vim test.txt 命令模式,键盘“:q”或“:q!”
2)打开文件(命令模式)之后,进入插入模式。并在插入模式中如何回到打开文件的状态(命令模式),并在命令模式之后如何退出文件。
1、VIM打开文件后,按键盘“i”,进入插入模式 2、按键盘“ESC”键退出插入模式 3、在输入键盘“:q”或“:q!”退出文件
3)打开文件(命令模式)之后,进入插入模式,编写一段话,"马哥出品,必属精品", 之后从插入模式中如何回到打开文件的状态(命令模式),并在命令模式之后如何退出文件。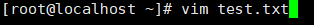
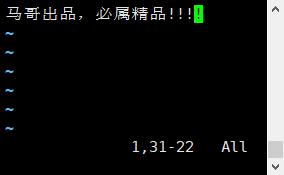
4)使用cat命令验证文件内容,是刚刚自己写的内容。

5)(可选),命令模式下,光标在单词,句子上进行前后,上下跳转。行复制粘贴。行删除。
4. 总结学过的文本处理工具,文件查找工具,文本处理三剑客, 文本格式化命令(printf)的相关命令及选项,示例。
grep 作用:过滤。用法:grep [选项] “关键字” 文件名
如:find / -name *.conf | grep "sys"
sed 作用:流处理,行处理,结果输出屏幕,默认不改变源文件。用法:sed [选项] ‘处理动作’ 文件
如:ip a | grep inet | sed -n '3p'
find 作用:在目录结构中搜索文件,并执行指定的操作。用法:find 路径 -选项 [ -显示 ]
如:find /var/log/httpd/ -mtime +60 -name "*.log" -exec rm -rf {} \;
printf 作用:格式化参数并输出结果。用法:printf [选项] 输出格式 [一到多个参数]
如图所示:
5. 总结文本处理的grep命令相关的基本正则和扩展正则表达式。
| grep命令选项 | |
| 选项 | 解释 |
| --color=auto | 高亮显示匹配到的关键字 |
| -i 或 --ignore-case | 忽略字符大小写差别 |
| -n 或 --line-number | 在显示符合样式的那一行之前,标示出改行的列数编号 |
| -E 或 --extend-regexp | 将样式为延伸的正则表达式来使用 |
| -w 或 --word-regexp | 只显示全字符合的列 |
| -o 或 --only-matching | 只显示匹配PATTERN部分 |
| -v 或 --revert-match | 显示不包含匹配文本的所有行(反向匹配) |
| -A<显示行数>或--after-context=<显示行数> | 除了显示符合范本样式的那一列之外,并显示该行之后的内容。 |
| -B<显示行数>或 --before-contest=<显示行数> | 除了显示符合范本样式的那一列之外,并显示该行之前的内容。 |
| -C<显示行数> 或 --context=<显示行数> | 除了显示符合范本样式的那一列之外,并显示该行之后前后的内容。 |
字符匹配
. 任意字符
[jack] 指定范围的字符
[^jack] 不在指定范围的字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z,a-z
[:lower:] 小写字母,实例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃。。。)
[:digit:] 十进制数字
[:xdigit:] 十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
次数匹配
* 匹配前面字符任意次
? 0或1次
+ 1次或多次
{n} 匹配n次
{m,n} 至少m,至多n次
位置锚定
^ 行首
$ 行尾
\<, \b 语首
\>, \b 语尾
分组其他
() 分组
| 或者
6. 总结变量命名规则,不同类型变量(环境变量,位置变量,只读变量,局部变量,状态变量)如何使用。
1、不能使程序中的保留字:如: if for
2、只能使用数字、字母及下划线,且不能以数学开头,注意:不支持短横线
3、见名知义,用英文名字,并体现出实际作用
4、统一名称规则:驼峰命名法,大驼峰,小驼峰
5、变量名大写
6、局部变量小写
7、函数名小写
7. 通过shell编程完成,30鸡和兔的头,80鸡和兔的脚,分别有几只鸡,几只兔?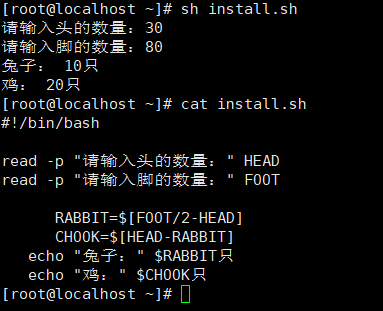
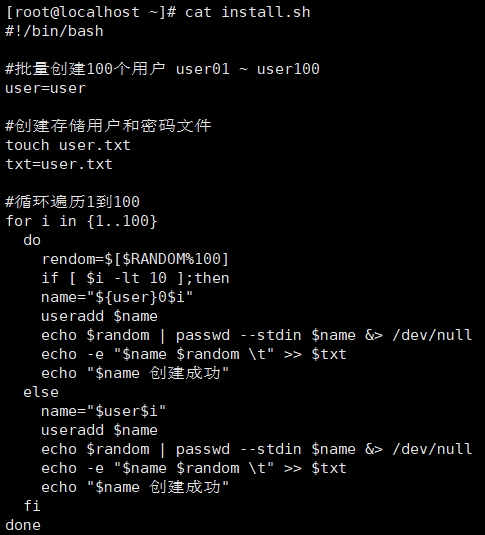
8. 结合编程的for循环,条件测试,条件组合,完成批量创建100个用户,
1)for遍历1..100
2)先id判断是否存在,3)用户存在则说明存在,用户不存在则添加用户并说明已添加。
9. 磁盘存储术语总结: head, track, sector, sylinder.
head 磁头 磁头数=盘面数
track 磁道 = 柱面数
sector 扇区,512bytes
cylinder 柱面 1柱面=512 * sector数/track*head数=512*63*255=7.84M
10. 总结MBR,GPT结构。
1、MBR磁盘分区是一种使用最为广泛的分区结构,它也被称为DOS分区结构,但它并不仅仅应用用于Windows系统平台,也应用于Linux,基于X86的unix等系统平台。它位于磁盘的0号扇区(一扇区等于512字节),是一个重要的扇区(简称MBR扇区)。
2、GPT磁盘分区结构解决了MBR只能分4个主分区的缺点,理论上说,GPT磁盘分区结构对分区的数量好像是没有限制的。但某些操作系统可能会对此有限制。
11. 总结学过的分区,文件系统管理,SWAP管理相关的命令及选项,示例
fdisk, parted, mkfs, tune2fs, xfs_info, fsck, mount, umount, swapon, swapoff
fdisk是一个创建和维护分区的命令,常用用法:fdisk [选项] <disk> 改变分区,fdisk [选项] -l <disk> 列出所有分区
parted [选项] [设备] [指令] 将带有“参数”的命令应用于“设备”。如果没有给出“命令”,则以交互模式运行
mkfs(英文全拼:make file system)命令用于在特定的分区上建立 linux 文件系统。
tune2fs是调整和查看ext2/ext3文件系统的文件系统参数,Windows下面如果出现意外断电死机情况,下次开机一般都会出现系统自检。Linux系统下面也有文件系统自检,而且是可以通过tune2fs命令,自行定义自检周期及方式。
xfs_info命令用来查看xfs文件系统的具体信息。其中该命令的装载点参数是装载文件系统的目录的路径名。必须装入文件系统才能进行增长文件系统的现有内容不受干扰,并且添加的空间可用于其他文件存储。 语法格式:xfs_info [挂载点] | [设备文件名]
fsck(file system check)用来检查和维护不一致的文件系统。若系统掉电或磁盘发生问题,可利用fsck命令对文件系统进行检查。
mount [选项] [磁盘或分区的设备名] [载入点]
umount 命令可以卸载已经挂载的文件系统。umount [选项] [目录|设备]
swapon命令用于激活Linux系统中交换空间,Linux系统的内存管理必须使用交换区来建立虚拟内存。
swapoff命令用于关闭指定的交换空间(包括交换文件和交换分区)。swapoff实际上为swapon的符号连接,可用来关闭系统的交换区。
12. 总结raid 0, 1, 5, 10, 01的工作原理。总结各自的利用率,冗余性,性能,至少几个硬盘实现。
1、RAID0模式
优点:在RAID 0状态下,存储数据被分割成两部分,分别存储在两块硬盘上,此时移动硬盘的理论存储速度是单块硬盘的2倍,实际容量等于两块硬盘中较小一块硬盘的容量的2倍。
缺点:任何一块硬盘发生故障,整个RAID上的数据将不可恢复。
备注:存储高清电影比较适合。
2、RAID1模式
优点:此模式下,两块硬盘互为镜像。当一个硬盘受损时,换上一块全新硬盘(大于或等于原硬盘容量)替代原硬盘即可自动恢复资料和继续使用,移动硬盘的实际容量等于较小一块硬盘的容量,存储速度与单块硬盘相同。RAID 1的优势在于任何一块硬盘出现故障是,所存储的数据都不会丢失。
缺点:该模式可使用的硬盘实际容量比较小,仅仅为两颗硬盘中最小硬盘的容量。
备注:非常重要的资料,如数据库,个人资料,是万无一失的存储方案。
3、RAID 0+1模式
RAID 0+1是磁盘分段及镜像的结合,采用2组RAID0的磁盘阵列互为镜像,它们之间又成为一个RAID1的阵列。硬盘使用率只有50%,但是提供最佳的速度及可靠度。
4、RAID 5模式
RAID5不对存储的数据进行备份,而是把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上。当RAID5的一个磁盘数据发生损坏后,利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。
5、RAID 10模式
RAID10最少需要4块硬盘才能完成。把2块硬盘组成一个RAID1,然后两组RAID1组成一个RAID0。虽然RAID10方案造成了50%的磁盘浪费,但是它提供了200%的速度和单磁盘损坏的数据安全性。
13. 完成不影响业务对LVM磁盘扩容及缩容示例。
扩容:
pvcreate /dev/sdd
pvs
pvdisplay
vgextend -r -L +15G /dev/myvg/mylv
lvs
lvdisplay
df-h
resize2fs /dev/myvg/mylv
缩减:
umount /mnt/mylvm
fsck -f /dev/myvg/mylv
resize2fs /dev/myvg/mylv 10G
lvreduce -L 10G /dev/myvg/mylv
mount -a
df -h
lvdisplay

 浙公网安备 33010602011771号
浙公网安备 33010602011771号