spark-sklearn(spark扩展scikitlearn)
(1)官方规定安装条件:此包装具有以下要求:
-*最新版本的scikit学习。 版本0.17已经过测试,旧版本也可以使用。
- *Spark> = 2.0。 Spark可以从对应官网下载
[Spark官方网站](http://spark.apache.org/)
-*为了使用spark-sklearn,您需要使用pyspark解释器或其他Spark兼容的python解释器。
有关详细信息,请参阅[Spark指南](https://spark.apache.org/docs/latest/programming-guide.html#overview)。
- (https://nose.readthedocs.org)(仅测试依赖关系)
英文原文:This package has the following requirements:
- a recent version of scikit-learn. Version 0.17 has been tested, older versions may work too.
- Spark >= 2.0. Spark may be downloaded from the
[Spark official website](http://spark.apache.org/) In order to use spark-sklearn, you need to use the pyspark interpreter or another Spark-compliant python interpreter. See the [Spark guide](https://spark.apache.org/docs/latest/programming-guide.html#overview) for more details.
- [nose](https://nose.readthedocs.org) (testing dependency only)
(2)首先安装pyspark:
参考为的博客:http://www.cnblogs.com/jackchen-Net/p/6667205.html#_label5
(3)访问网址:https://pypi.python.org/pypi/spark-sklearn
目前Spark集成了Scikit-learn包,这样可以极大的简化了python数据科学家们的工作,这个包可以在Spark集群上自动分配模型参数优化计算任务
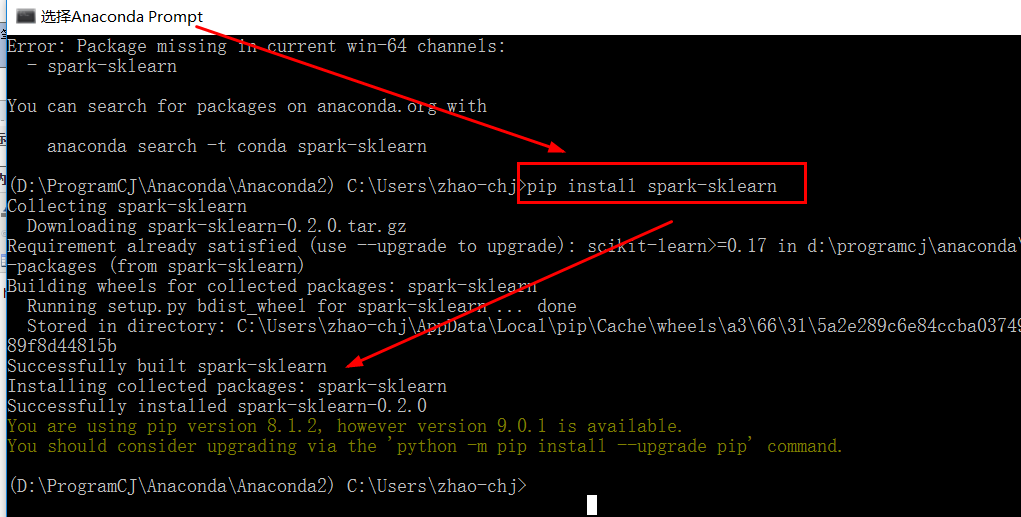
(4)官方文档的例子测试
1 ## Example 2 3 Here is a simple example that runs a grid search with Spark. See the [Installation](#Installation) section on how to install spark-sklearn. 4 5 ```python 6 from sklearn import svm, grid_search, datasets 7 from spark_sklearn import GridSearchCV 8 iris = datasets.load_iris() 9 parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]} 10 svr = svm.SVC() 11 clf = GridSearchCV(sc, svr, parameters) 12 clf.fit(iris.data, iris.target) 13 ``` 14 15 This classifier can be used as a drop-in replacement for any scikit-learn classifier, with the same API.
END~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号