推荐系统之最小二乘法ALS的Spark实现
1.ALS算法流程:
初始化数据集和Spark环境---->
切分测试机和检验集------>
训练ALS模型------------>
验证结果----------------->
检验满足结果---->直接推荐商品,否则继续训练ALS模型
2.数据集的含义
Rating是固定的ALS输入格式,要求是一个元组类型的数据,其中数值分别是如下的[Int,Int,Double],在建立数据集的时候,用户名和物品名需要采用数值代替
1 /** 2 * A more compact class to represent a rating than Tuple3[Int, Int, Double]. 3 */ 4 @Since("0.8.0") 5 case class Rating @Since("0.8.0") ( 6 @Since("0.8.0") user: Int, 7 @Since("0.8.0") product: Int, 8 @Since("0.8.0") rating: Double)
如下:第一列位用户编号,第二列位产品编号,第三列的评分Rating为Double类型
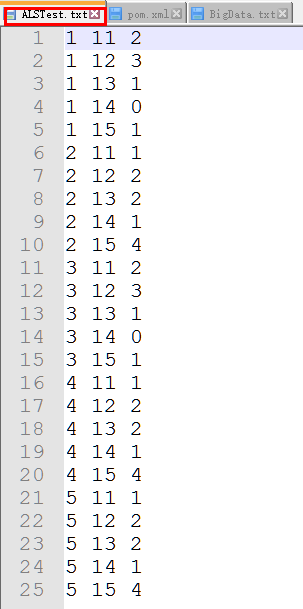
3.ALS的测试数据集源代码解读
3.1ALS类的所有字段如下
@Since("0.8.0")
class ALS private (
private var numUserBlocks: Int,
private var numProductBlocks: Int,
private var rank: Int,
private var iterations: Int,
private var lambda: Double,
private var implicitPrefs: Boolean, 使用显式反馈ALS变量或隐式反馈
private var alpha: Double, ALS隐式反馈变化率用于控制每次拟合修正的幅度
private var seed: Long = System.nanoTime()
) extends Serializable with Logging {
3.2 ALS.train方法
1 /** 2 * Train a matrix factorization model given an RDD of ratings given by users to some products, 3 * in the form of (userID, productID, rating) pairs. We approximate the ratings matrix as the 4 * product of two lower-rank matrices of a given rank (number of features). To solve for these 5 * features, we run a given number of iterations of ALS. This is done using a level of 6 * parallelism given by `blocks`. 7 * 8 * @param ratings RDD of (userID, productID, rating) pairs 9 * @param rank number of features to use 10 * @param iterations number of iterations of ALS (recommended: 10-20) 11 * @param lambda regularization factor (recommended: 0.01) 12 * @param blocks level of parallelism to split computation into 将并行度分解为等级 13 * @param seed random seed 随机种子 14 */ 15 @Since("0.9.1") 16 def train( 17 ratings: RDD[Rating], //RDD序列由用户ID 产品ID和评分组成 18 rank: Int, //模型中的隐藏因子数目 19 iterations: Int, //算法迭代次数 20 lambda: Double, //ALS正则化参数 21 blocks: Int, //块 22 seed: Long 23 ): MatrixFactorizationModel = { 24 new ALS(blocks, blocks, rank, iterations, lambda, false, 1.0, seed).run(ratings) 25 }
3.3 基于ALS算法的协同过滤推荐
1 package com.bigdata.demo 2 3 import org.apache.spark.{SparkContext, SparkConf} 4 import org.apache.spark.mllib.recommendation.ALS 5 import org.apache.spark.mllib.recommendation.Rating 6 7 /** 8 * Created by SimonsZhao on 3/30/2017. 9 * ALS最小二乘法 10 */ 11 object CollaborativeFilter { 12 13 def main(args: Array[String]) { 14 //设置环境变量 15 val conf=new SparkConf().setMaster("local").setAppName("CollaborativeFilter ") 16 //实例化环境 17 val sc = new SparkContext(conf) 18 //设置数据集 19 val data =sc.textFile("E:/scala/spark/testdata/ALSTest.txt") 20 //处理数据 21 val ratings=data.map(_.split(' ') match{ 22 //数据集的转换 23 case Array(user,item,rate) => 24 //将数据集转化为专用的Rating 25 Rating(user.toInt,item.toInt,rate.toDouble) 26 }) 27 //设置隐藏因子 28 val rank=2 29 //设置迭代次数 30 val numIterations=2 31 //进行模型训练 32 val model =ALS.train(ratings,rank,numIterations,0.01) 33 //为用户2推荐一个商品 34 val rs=model.recommendProducts(2,1) 35 //打印结果 36 rs.foreach(println) 37 } 38 39 }
展开代码可复制


1 package com.bigdata.demo 2 3 import org.apache.spark.{SparkContext, SparkConf} 4 import org.apache.spark.mllib.recommendation.ALS 5 import org.apache.spark.mllib.recommendation.Rating 6 7 /** 8 * Created by SimonsZhao on 3/30/2017. 9 * ALS最小二乘法 10 */ 11 object CollaborativeFilter { 12 13 def main(args: Array[String]) { 14 //设置环境变量 15 val conf=new SparkConf().setMaster("local").setAppName("CollaborativeFilter ") 16 //实例化环境 17 val sc = new SparkContext(conf) 18 //设置数据集 19 val data =sc.textFile("E:/scala/spark/testdata/ALSTest.txt") 20 //处理数据 21 val ratings=data.map(_.split(' ') match{ 22 //数据集的转换 23 case Array(user,item,rate) => 24 //将数据集转化为专用的Rating 25 Rating(user.toInt,item.toInt,rate.toDouble) 26 }) 27 //设置隐藏因子 28 val rank=2 29 //设置迭代次数 30 val numIterations=2 31 //进行模型训练 32 val model =ALS.train(ratings,rank,numIterations,0.01) 33 //为用户2推荐一个商品 34 val rs=model.recommendProducts(2,1) 35 //打印结果 36 rs.foreach(println) 37 } 38 39 }
4.测试及分析
根据结果分析为第2个用户推荐了编号为15的商品,预测评分为3.99
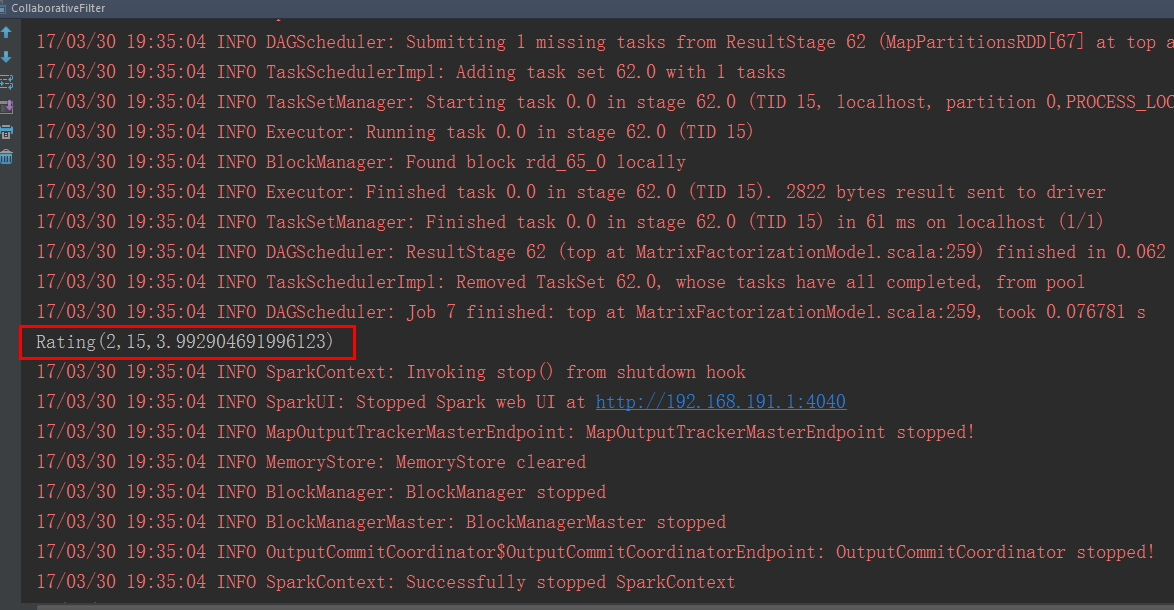
5.基于用户的推荐源代码(mllib)
注释的部分翻译:
用户向用户推荐产品
num返回多少产品。 返回的数字可能少于此值。
[[评分]]对象,每个对象包含给定的用户ID,产品ID和
评分字段中的“得分”。 每个代表一个推荐的产品,并且它们被排序
按分数,减少。 第一个返回的是预测最强的一个
推荐给用户。 分数是一个不透明的值,表示强列推荐的产品。
1 /** 2 * Recommends products to a user. 3 * 4 * @param user the user to recommend products to 5 * @param num how many products to return. The number returned may be less than this. 6 * @return [[Rating]] objects, each of which contains the given user ID, a product ID, and a 7 * "score" in the rating field. Each represents one recommended product, and they are sorted 8 * by score, decreasing. The first returned is the one predicted to be most strongly 9 * recommended to the user. The score is an opaque value that indicates how strongly 10 * recommended the product is. 11 */ 12 @Since("1.1.0") 13 def recommendProducts(user: Int, num: Int): Array[Rating] = 14 MatrixFactorizationModel.recommend(userFeatures.lookup(user).head, productFeatures, num) 15 .map(t => Rating(user, t._1, t._2))
6.基于物品的推荐源代码(mllib)
注释的部分翻译:
推荐用户使用产品,也就是说,这将返回最有可能的用户对产品感兴趣
每个都包含用户ID,给定的产品ID和评分字段中的“得分”。
每个代表一个推荐的用户,并且它们被排序按得分,减少。
第一个返回的是预测最强的一个推荐给产品。
分数是一个不透明的值,表示强烈推荐给用户。
1 /** 2 * Recommends users to a product. That is, this returns users who are most likely to be 3 * interested in a product. 4 * 5 * @param product the product to recommend users to 给用户推荐的产品 6 * @param num how many users to return. The number returned may be less than this. 返回个用户的个数 7 * @return [[Rating]] objects, each of which contains a user ID, the given product ID, and a 8 * "score" in the rating field. Each represents one recommended user, and they are sorted 9 * by score, decreasing. The first returned is the one predicted to be most strongly 10 * recommended to the product. The score is an opaque value that indicates how strongly 11 * recommended the user is. 12 */ 13 @Since("1.1.0") 14 def recommendUsers(product: Int, num: Int): Array[Rating] = 15 MatrixFactorizationModel.recommend(productFeatures.lookup(product).head, userFeatures, num) 16 .map(t => Rating(t._1, product, t._2))
END~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号