MapRedece(单表关联)
源数据:Child--Parent表
| Tom | Lucy |
| Tom | Jack |
| Jone | Lucy |
| Jone | Jack |
| Lucy | Marry |
| Lucy | Ben |
| Jack | Alice |
| Jack | Jesse |
| Terry | Alice |
| Terry | Jesse |
| Philop | Terry |
| Philop | Alma |
| Mark | Terry |
| Mark | Alma |
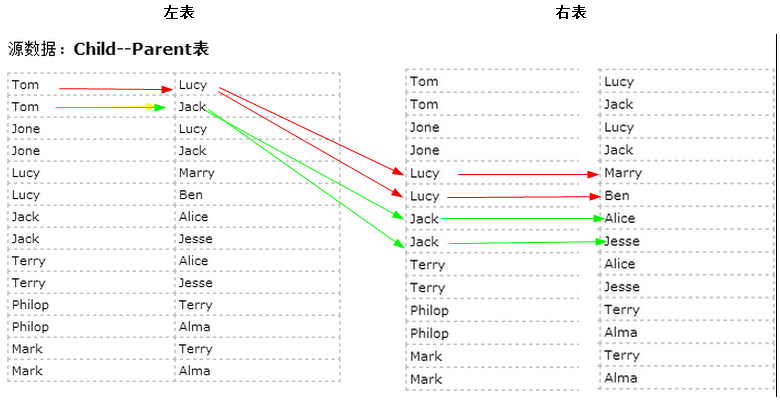
目标:表的自连接:从图中可以找出Tom的grandparent为Marry和Ben,同理可以找出其他的人的grandparent

根据Child--Parent表推断grandchild和grandparent
左表 右表
将一张表分解为两张表的连接:从图中可以找出Tom的grandparent为Marry和Ben,同理可以找出其他的人的grandparent
思路与步骤:
只有连接 左表的parent列和右表的child列,才能得到grandchild和grandparent的信息。
因此需要将源数据的一张表拆分成两张表,且左表和右表是同一个表,如上图。
- 所以在map阶段将读入数据分割成child和parent之后,将parent设置成key,child设置成value进行输出,并作为左表;
- 再将同一对child和parent中的child设置成key,parent设置成value进行输出,作为右表。
- 为了区分输出中的左右表,需要在输出的value中再加上左右表的信息,比如在value的String最开始处加上字符1表示左表,加上字符2表示右表。
- 这样在map的结果中就形成了左表和右表,然后在shuffle过程中完成连接。
- reduce接收到连接的结果,其中每个key的value-list就包含了"grandchild--grandparent"关系。
- 取出每个key的value-list进行解析,将左表中的child放入一个数组,右表中的parent放入一个数组,
- 最后对两个数组求笛卡尔积得到最后的结果
代码1:
(1)自定义Mapper类
1 private static class MyMapper extends Mapper<Object, Text, Text, Text> { 2 @Override 3 protected void map(Object k1, Text v1, 4 Mapper<Object, Text, Text, Text>.Context context) 5 throws IOException, InterruptedException { 6 String childName = new String(); 7 String parentName = new String(); 8 String relationType = new String(); 9 Text k2 = new Text(); 10 Text v2 = new Text(); 11 // 輸入一行预处理的文本 12 StringTokenizer items = new StringTokenizer(v1.toString()); 13 String[] values = new String[2]; 14 int i = 0; 15 while (items.hasMoreTokens()) { 16 values[i] = items.nextToken(); 17 i++; 18 } 19 if (values[0].compareTo("child") != 0) { 20 childName = values[0]; 21 parentName = values[1]; 22 // 输出左表,左表加1的标识 23 relationType = "1"; 24 k2 = new Text(values[1]); // parent作为key,作为表1的key 25 v2 = new Text(relationType + "+" + childName + "+" + parentName);//<1+Lucy+Tom> 26 context.write(k2, v2); 27 // 输出右表,右表加2的标识 28 relationType = "2"; 29 k2 = new Text(values[0]);// child作为key,作为表2的key 30 v2 = new Text(relationType + "+" + childName + "+" + parentName);//<2+Jone+Lucy> 31 context.write(k2, v2); 32 } 33 } 34 }
(2)自定义Reduce
1 private static class MyReducer extends Reducer<Text, Text, Text, Text> { 2 Text k3 = new Text(); 3 Text v3 = new Text(); 4 5 @Override 6 protected void reduce(Text k2, Iterable<Text> v2s, 7 Reducer<Text, Text, Text, Text>.Context context) 8 throws IOException, InterruptedException { 9 if (0 == time) { 10 context.write(new Text("grandchild"), new Text("grandparent")); 11 time++; 12 } 13 int grandchildnum = 0; 14 String[] grandchild = new String[10];//孙子 15 int grandparentnum = 0; 16 String[] grandparent = new String[10];//爷爷 17 Iterator items = v2s.iterator();//["1 Tom","2 Mary","2 Ben"] 18 while (items.hasNext()) { 19 String record = items.next().toString(); 20 int len = record.length(); 21 int i = 2; 22 if (0 == len) { 23 continue; 24 } 25 26 // 取得左右表的标识 27 char relationType = record.charAt(0); 28 // 定义孩子和父母变量 29 String childname = new String(); 30 String parentname = new String(); 31 // 获取value列表中value的child 32 while (record.charAt(i) != '+') { 33 childname += record.charAt(i); 34 i++; 35 } 36 i = i + 1; //越过名字之间的“+”加号 37 // 获取value列表中value的parent 38 while (i < len) { 39 parentname += record.charAt(i); 40 i++; 41 } 42 // 左表,取出child放入grandchildren 43 if ('1' == relationType) { 44 grandchild[grandchildnum] = childname; 45 grandchildnum++; 46 } 47 // 右表,取出parent放入grandparent 48 if ('2' == relationType) { 49 grandparent[grandparentnum] = parentname; 50 grandparentnum++; 51 } 52 } 53 // grandchild和grandparentnum数组求笛卡尔积 54 if (0 != grandchildnum && 0 != grandparentnum) { 55 for (int i = 0; i < grandchildnum; i++) { 56 for (int j = 0; j < grandparentnum; j++) { 57 k3 = new Text(grandchild[i]); 58 v3 = new Text(grandparent[j]); 59 context.write(k3, v3); 60 } 61 } 62 } 63 } 64 }
(3)Map和Reduce组合
1 public static void main(String[] args) throws Exception { 2 //必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定 3 //2将自定义的MyMapper和MyReducer组装在一起 4 Configuration conf=new Configuration(); 5 String jobName=SingleTableLink.class.getSimpleName(); 6 //1首先寫job,知道需要conf和jobname在去創建即可 7 Job job = Job.getInstance(conf, jobName); 8 9 //*13最后,如果要打包运行改程序,则需要调用如下行 10 job.setJarByClass(SingleTableLink.class); 11 12 //3读取HDFS內容:FileInputFormat在mapreduce.lib包下 13 FileInputFormat.setInputPaths(job, new Path(args[0])); 14 //4指定解析<k1,v1>的类(谁来解析键值对) 15 //*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class 16 job.setInputFormatClass(TextInputFormat.class); 17 //5指定自定义mapper类 18 job.setMapperClass(MyMapper.class); 19 //6指定map输出的key2的类型和value2的类型 <k2,v2> 20 //*下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定 21 job.setMapOutputKeyClass(Text.class); 22 job.setMapOutputValueClass(Text.class); 23 //7分区(默认1个),排序,分组,规约 采用 默认 24 25 //接下来采用reduce步骤 26 //8指定自定义的reduce类 27 job.setReducerClass(MyReducer.class); 28 //9指定输出的<k3,v3>类型 29 job.setOutputKeyClass(Text.class); 30 job.setOutputValueClass(Text.class); 31 //10指定输出<K3,V3>的类 32 //*下面这一步可以省 33 job.setOutputFormatClass(TextOutputFormat.class); 34 //11指定输出路径 35 FileOutputFormat.setOutputPath(job, new Path(args[1])); 36 37 //12写的mapreduce程序要交给resource manager运行 38 job.waitForCompletion(true); 39 }
所有源代码:


1 package Mapreduce; 2 3 import java.io.IOException; 4 import java.util.Iterator; 5 import java.util.StringTokenizer; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Job; 11 import org.apache.hadoop.mapreduce.Mapper; 12 import org.apache.hadoop.mapreduce.Reducer; 13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 14 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 17 18 public class SingleTableLink { 19 private static int time = 0; 20 21 public static void main(String[] args) throws Exception { 22 //必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定 23 //2将自定义的MyMapper和MyReducer组装在一起 24 Configuration conf=new Configuration(); 25 String jobName=SingleTableLink.class.getSimpleName(); 26 //1首先寫job,知道需要conf和jobname在去創建即可 27 Job job = Job.getInstance(conf, jobName); 28 29 //*13最后,如果要打包运行改程序,则需要调用如下行 30 job.setJarByClass(SingleTableLink.class); 31 32 //3读取HDFS內容:FileInputFormat在mapreduce.lib包下 33 FileInputFormat.setInputPaths(job, new Path(args[0])); 34 //4指定解析<k1,v1>的类(谁来解析键值对) 35 //*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class 36 job.setInputFormatClass(TextInputFormat.class); 37 //5指定自定义mapper类 38 job.setMapperClass(MyMapper.class); 39 //6指定map输出的key2的类型和value2的类型 <k2,v2> 40 //*下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定 41 job.setMapOutputKeyClass(Text.class); 42 job.setMapOutputValueClass(Text.class); 43 //7分区(默认1个),排序,分组,规约 采用 默认 44 45 //接下来采用reduce步骤 46 //8指定自定义的reduce类 47 job.setReducerClass(MyReducer.class); 48 //9指定输出的<k3,v3>类型 49 job.setOutputKeyClass(Text.class); 50 job.setOutputValueClass(Text.class); 51 //10指定输出<K3,V3>的类 52 //*下面这一步可以省 53 job.setOutputFormatClass(TextOutputFormat.class); 54 //11指定输出路径 55 FileOutputFormat.setOutputPath(job, new Path(args[1])); 56 57 //12写的mapreduce程序要交给resource manager运行 58 job.waitForCompletion(true); 59 } 60 61 private static class MyMapper extends Mapper<Object, Text, Text, Text> { 62 @Override 63 protected void map(Object k1, Text v1, 64 Mapper<Object, Text, Text, Text>.Context context) 65 throws IOException, InterruptedException { 66 String childName = new String(); 67 String parentName = new String(); 68 String relationType = new String(); 69 Text k2 = new Text(); 70 Text v2 = new Text(); 71 // 輸入一行预处理的文本 72 StringTokenizer items = new StringTokenizer(v1.toString()); 73 String[] values = new String[2]; 74 int i = 0; 75 while (items.hasMoreTokens()) { 76 values[i] = items.nextToken(); 77 i++; 78 } 79 if (values[0].compareTo("child") != 0) { 80 childName = values[0]; 81 parentName = values[1]; 82 // 输出左表,左表加1的标识 83 relationType = "1"; 84 k2 = new Text(values[1]); // parent作为key,作为表1的key 85 v2 = new Text(relationType + "+" + childName + "+" + parentName);//<1+Lucy+Tom> 86 context.write(k2, v2); 87 // 输出右表,右表加2的标识 88 relationType = "2"; 89 k2 = new Text(values[0]);// child作为key,作为表2的key 90 v2 = new Text(relationType + "+" + childName + "+" + parentName);//<2+Jone+Lucy> 91 context.write(k2, v2); 92 } 93 } 94 } 95 96 private static class MyReducer extends Reducer<Text, Text, Text, Text> { 97 Text k3 = new Text(); 98 Text v3 = new Text(); 99 100 @Override 101 protected void reduce(Text k2, Iterable<Text> v2s, 102 Reducer<Text, Text, Text, Text>.Context context) 103 throws IOException, InterruptedException { 104 if (0 == time) { 105 context.write(new Text("grandchild"), new Text("grandparent")); 106 time++; 107 } 108 int grandchildnum = 0; 109 String[] grandchild = new String[10];//孙子 110 int grandparentnum = 0; 111 String[] grandparent = new String[10];//爷爷 112 Iterator items = v2s.iterator();//["1 Tom","2 Mary","2 Ben"] 113 while (items.hasNext()) { 114 String record = items.next().toString(); 115 int len = record.length(); 116 int i = 2; 117 if (0 == len) { 118 continue; 119 } 120 121 // 取得左右表的标识 122 char relationType = record.charAt(0); 123 // 定义孩子和父母变量 124 String childname = new String(); 125 String parentname = new String(); 126 // 获取value列表中value的child 127 while (record.charAt(i) != '+') { 128 childname += record.charAt(i); 129 i++; 130 } 131 i = i + 1; //越过名字之间的“+”加号 132 // 获取value列表中value的parent 133 while (i < len) { 134 parentname += record.charAt(i); 135 i++; 136 } 137 // 左表,取出child放入grandchildren 138 if ('1' == relationType) { 139 grandchild[grandchildnum] = childname; 140 grandchildnum++; 141 } 142 // 右表,取出parent放入grandparent 143 if ('2' == relationType) { 144 grandparent[grandparentnum] = parentname; 145 grandparentnum++; 146 } 147 } 148 // grandchild和grandparentnum数组求笛卡尔积 149 if (0 != grandchildnum && 0 != grandparentnum) { 150 for (int i = 0; i < grandchildnum; i++) { 151 for (int j = 0; j < grandparentnum; j++) { 152 k3 = new Text(grandchild[i]); 153 v3 = new Text(grandparent[j]); 154 context.write(k3, v3); 155 } 156 } 157 } 158 } 159 } 160 161 }
代码2:参考的代码
1 package Mapreduce; 2 3 import java.io.IOException; 4 import java.util.ArrayList; 5 import java.util.Iterator; 6 import java.util.List; 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Job; 11 import org.apache.hadoop.mapreduce.Mapper; 12 import org.apache.hadoop.mapreduce.Reducer; 13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 14 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 17 18 public class SingleTableLink2 { 19 20 public static void main(String[] args) throws Exception { 21 // 必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定 22 // 2将自定义的MyMapper和MyReducer组装在一起 23 Configuration conf = new Configuration(); 24 String jobName = SingleTableLink2.class.getSimpleName(); 25 // 1首先寫job,知道需要conf和jobname在去創建即可 26 Job job = Job.getInstance(conf, jobName); 27 28 // *13最后,如果要打包运行改程序,则需要调用如下行 29 job.setJarByClass(SingleTableLink2.class); 30 31 // 3读取HDFS內容:FileInputFormat在mapreduce.lib包下 32 FileInputFormat.setInputPaths(job, new Path(args[0])); 33 // 4指定解析<k1,v1>的类(谁来解析键值对) 34 // *指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class 35 job.setInputFormatClass(TextInputFormat.class); 36 // 5指定自定义mapper类 37 job.setMapperClass(MyMapper.class); 38 // 6指定map输出的key2的类型和value2的类型 <k2,v2> 39 // *下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定 40 job.setMapOutputKeyClass(Text.class); 41 job.setMapOutputValueClass(Text.class); 42 // 7分区(默认1个),排序,分组,规约 采用 默认 43 44 // 接下来采用reduce步骤 45 // 8指定自定义的reduce类 46 job.setReducerClass(MyReducer.class); 47 // 9指定输出的<k3,v3>类型 48 job.setOutputKeyClass(Text.class); 49 job.setOutputValueClass(Text.class); 50 // 10指定输出<K3,V3>的类 51 // *下面这一步可以省 52 job.setOutputFormatClass(TextOutputFormat.class); 53 // 11指定输出路径 54 FileOutputFormat.setOutputPath(job, new Path(args[1])); 55 56 // 12写的mapreduce程序要交给resource manager运行 57 job.waitForCompletion(true); 58 } 59 60 private static class MyMapper extends Mapper<Object, Text, Text, Text> { 61 @Override 62 protected void map(Object k1, Text v1, 63 Mapper<Object, Text, Text, Text>.Context context) 64 throws IOException, InterruptedException { 65 String childName = new String(); 66 String parentName = new String(); 67 String relationType = new String(); 68 Text k2 = new Text(); 69 Text v2 = new Text(); 70 // 輸入一行预处理的文本 71 String line = v1.toString(); 72 String[] values = line.split("\t"); 73 if (values.length >= 2) { 74 if (values[0].compareTo("child") != 0) { 75 childName = values[0]; 76 parentName = values[1]; 77 // 输出左表,左表加1的标识 78 relationType = "1"; 79 k2 = new Text(parentName); // parent作为key,作为表1的key 80 v2 = new Text(relationType + " " + childName);// <"Lucy","1 Tom"> 81 context.write(k2, v2); 82 // 输出右表,右表加2的标识 83 relationType = "2"; 84 k2 = new Text(childName);// child作为key,作为表2的key 85 v2 = new Text(relationType + " " + parentName);// //<"Jone","2 Lucy"> 86 context.write(k2, v2); 87 } 88 } 89 } 90 } 91 92 private static class MyReducer extends Reducer<Text, Text, Text, Text> { 93 94 @Override 95 protected void reduce(Text key, Iterable<Text> values, Context context) 96 throws IOException, InterruptedException { 97 List<String> grandChild = new ArrayList<String>();// 孙子 98 List<String> grandParent = new ArrayList<String>();// 爷爷 99 Iterator<Text> it = values.iterator();// ["1 Tom","2 Mary","2 Ben"] 100 while (it.hasNext()) { 101 String[] record = it.next().toString().split(" ");// "1 Tom"---[1,Tom] 102 if (record.length == 0) 103 continue; 104 if (record[0].equals("1")) {// 左表,取出child放入grandchild 105 grandChild.add(record[1]); 106 } else if (record[0].equals("2")) {// 右表,取出parent放入grandParent 107 grandParent.add(record[1]); 108 } 109 } 110 // grandchild 和 grandparent数组求笛卡尔积 111 if (grandChild.size() != 0 && grandParent.size() != 0) { 112 for (int i = 0; i < grandChild.size(); i++) { 113 for (int j = 0; j < grandParent.size(); j++) { 114 context.write(new Text(grandChild.get(i)), new Text( 115 grandParent.get(j))); 116 } 117 } 118 } 119 } 120 } 121 122 }
代码运行:
(1)准备数据
[root@neusoft-master filecontent]# vi child_parent
Tom Lucy
Tom Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Ben
Jack Alice
Jack Jesses
Terry Alice
Terry Jesses
Philip Terry
Philip Alma
Mark Terry
Mark Alma
(以\t分隔)
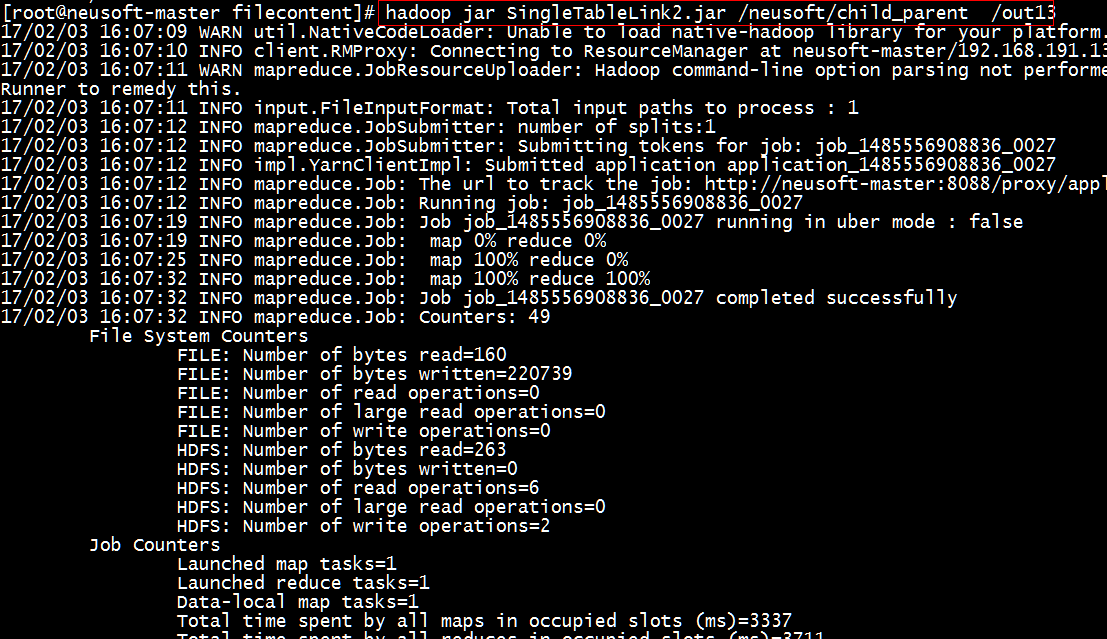
(2)执行jar包
[root@neusoft-master filecontent]# hadoop jar SingleTableLink2.jar /neusoft/child_parent /out13
(3)查看运行结果是否正确
[root@neusoft-master filecontent]# hadoop dfs -text /out13/part-r-00000
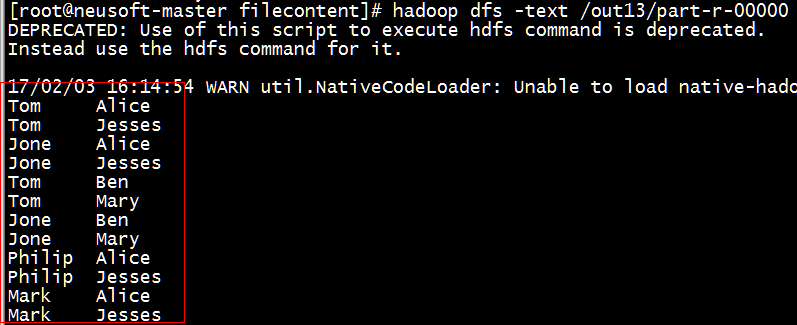
备注:(1)如果显示的多一个+,加号,需要检查程序,在下面两个循环之间加移位操作。
// 获取value列表中value的child 32 while (record.charAt(i) != '+') { 33 childname += record.charAt(i); 34 i++; 35 } 36 i = i + 1; //越过名字之间的“+”加号 37 // 获取value列表中value的parent 38 while (i < len) { 39 parentname += record.charAt(i); 40 i++; 41 }
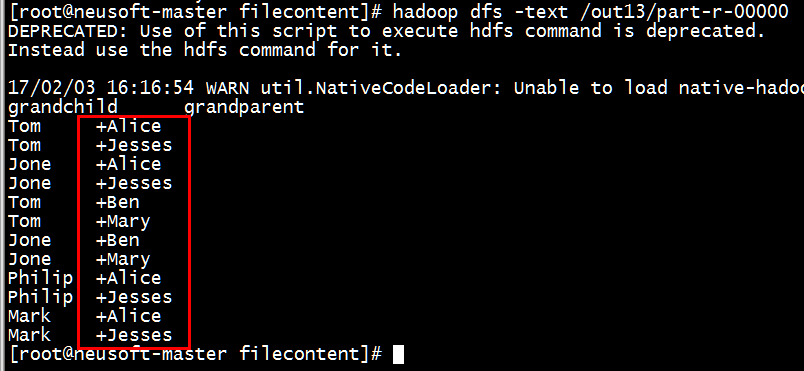
(2)补充点:
charAt
charAt(int index)方法是一个能够用来检索特定索引下的字符的String实例的方法.
charAt()方法返回指定索引位置的char值。索引范围为0~length()-1.
如: str.charAt(0)检索str中的第一个字符,str.charAt(str.length()-1)检索最后一个字符.
StringTokenizer是一个用来分隔String的应用类,相当于VB的split函数。
1.构造函数
public StringTokenizer(String str)
public StringTokenizer(String str, String delim)
public StringTokenizer(String str, String delim, boolean returnDelims)
第一个参数就是要分隔的String,第二个是分隔字符集合,第三个参数表示分隔符号是否作为标记返回,如果不指定分隔字符,默认的是:”\t\n\r\f”
2.核心方法
public boolean hasMoreTokens()
public String nextToken()
public String nextToken(String delim)
public int countTokens()
其实就是三个方法,返回分隔字符块的时候也可以指定分割符,而且以后都是采用最后一次指定的分隔符号。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号