MapReduce实例(数据去重)
数据去重:
原理(理解):Mapreduce程序首先应该确认<k3,v3>,根据<k3,v3>确定<k2,v2>,原始数据中出现次数超过一次的数据在输出文件中只出现一次。Reduce的输出是不重复的数据,也就是每一行数据作为key,即k3。而v3为空或不需要设值。根据<k3,v3>得到k2为每一行的数据,v2为空。根据MapReduce框架设值可知,k1为每行的起始位置,v1为每行的内容。因此,v1需要赋值给k2,使得原来的v1作为新的k2,从而两个或更多文件通过在Reduce端聚合,得到去重后的数据。
数据:
file1.txt
2016-6-1 b
2016-6-2 a
2016-6-3 b
2016-6-4 d
2016-6-5 a
2016-6-6 c
2016-6-7 d
2016-6-3 c
file2.txt
2016-6-1 a
2016-6-2 b
2016-6-3 c
2016-6-4 d
2016-6-5 a
2016-6-6 b
2016-6-7 c
2016-6-3 c
*创建文件夹dedup_in并创建上述两文件,将该文件夹上传到HDFS中
[root@neusoft-master filecontent]# hadoop dfs -put dedup_in/ /neusoft/

[root@neusoft-master filecontent]# hadoop dfs -ls /neusoft

(1)自定义Mapper任务
1 private static class MyMapper extends Mapper<Object, Text, Text, Text>{ 2 private static Text line=new Text(); 3 @Override 4 protected void map(Object k1, Text v1, 5 Mapper<Object, Text, Text, Text>.Context context) 6 throws IOException, InterruptedException { 7 line=v1;//v1为每行数据,赋值给line 8 context.write(line, new Text("")); 9 } 10 }
(2)自定义Reduce任务
1 private static class MyReducer extends Reducer<Text, Text, Text, Text> 2 { 3 @Override 4 protected void reduce(Text k2, Iterable<Text> v2s, 5 Reducer<Text, Text, Text, Text>.Context context) 6 throws IOException, InterruptedException { 7 context.write(k2, new Text("")); 8 } 9 }
(3)主函数(组织map和reduce)
1 public static void main(String[] args) throws Exception { 2 //必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定 3 //2将自定义的MyMapper和MyReducer组装在一起 4 Configuration conf=new Configuration(); 5 String jobName=DataDeduplication.class.getSimpleName(); 6 //1首先寫job,知道需要conf和jobname在去創建即可 7 Job job = Job.getInstance(conf, jobName); 8 9 //*13最后,如果要打包运行改程序,则需要调用如下行 10 job.setJarByClass(DataDeduplication.class); 11 12 //3读取HDFS內容:FileInputFormat在mapreduce.lib包下 13 FileInputFormat.setInputPaths(job, new Path(args[0])); 14 //4指定解析<k1,v1>的类(谁来解析键值对) 15 //*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class 16 job.setInputFormatClass(TextInputFormat.class); 17 //5指定自定义mapper类 18 job.setMapperClass(MyMapper.class); 19 //6指定map输出的key2的类型和value2的类型 <k2,v2> 20 //*下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定 21 job.setMapOutputKeyClass(Text.class); 22 job.setMapOutputValueClass(Text.class); 23 //7分区(默认1个),排序,分组,规约 采用 默认 24 job.setCombinerClass(MyReducer.class); 25 //接下来采用reduce步骤 26 //8指定自定义的reduce类 27 job.setReducerClass(MyReducer.class); 28 //9指定输出的<k3,v3>类型 29 job.setOutputKeyClass(Text.class); 30 job.setOutputValueClass(Text.class); 31 //10指定输出<K3,V3>的类 32 //*下面这一步可以省 33 job.setOutputFormatClass(TextOutputFormat.class); 34 //11指定输出路径 35 FileOutputFormat.setOutputPath(job, new Path(args[1])); 36 37 //12写的mapreduce程序要交给resource manager运行 38 job.waitForCompletion(true); 39 }
数据去重源代码:


1 package Mapreduce; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.Job; 9 import org.apache.hadoop.mapreduce.Mapper; 10 import org.apache.hadoop.mapreduce.Reducer; 11 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 12 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 13 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 14 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 15 16 public class DataDeduplication { 17 public static void main(String[] args) throws Exception { 18 //必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定 19 //2将自定义的MyMapper和MyReducer组装在一起 20 Configuration conf=new Configuration(); 21 String jobName=DataDeduplication.class.getSimpleName(); 22 //1首先寫job,知道需要conf和jobname在去創建即可 23 Job job = Job.getInstance(conf, jobName); 24 25 //*13最后,如果要打包运行改程序,则需要调用如下行 26 job.setJarByClass(DataDeduplication.class); 27 28 //3读取HDFS內容:FileInputFormat在mapreduce.lib包下 29 FileInputFormat.setInputPaths(job, new Path(args[0])); 30 //4指定解析<k1,v1>的类(谁来解析键值对) 31 //*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class 32 job.setInputFormatClass(TextInputFormat.class); 33 //5指定自定义mapper类 34 job.setMapperClass(MyMapper.class); 35 //6指定map输出的key2的类型和value2的类型 <k2,v2> 36 //*下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定 37 job.setMapOutputKeyClass(Text.class); 38 job.setMapOutputValueClass(Text.class); 39 //7分区(默认1个),排序,分组,规约 采用 默认 40 job.setCombinerClass(MyReducer.class); 41 //接下来采用reduce步骤 42 //8指定自定义的reduce类 43 job.setReducerClass(MyReducer.class); 44 //9指定输出的<k3,v3>类型 45 job.setOutputKeyClass(Text.class); 46 job.setOutputValueClass(Text.class); 47 //10指定输出<K3,V3>的类 48 //*下面这一步可以省 49 job.setOutputFormatClass(TextOutputFormat.class); 50 //11指定输出路径 51 FileOutputFormat.setOutputPath(job, new Path(args[1])); 52 53 //12写的mapreduce程序要交给resource manager运行 54 job.waitForCompletion(true); 55 } 56 private static class MyMapper extends Mapper<Object, Text, Text, Text>{ 57 private static Text line=new Text(); 58 @Override 59 protected void map(Object k1, Text v1, 60 Mapper<Object, Text, Text, Text>.Context context) 61 throws IOException, InterruptedException { 62 line=v1;//v1为每行数据,赋值给line 63 context.write(line, new Text("")); 64 } 65 } 66 private static class MyReducer extends Reducer<Text, Text, Text, Text> 67 { 68 @Override 69 protected void reduce(Text k2, Iterable<Text> v2s, 70 Reducer<Text, Text, Text, Text>.Context context) 71 throws IOException, InterruptedException { 72 context.write(k2, new Text("")); 73 } 74 } 75 }
运行结果:
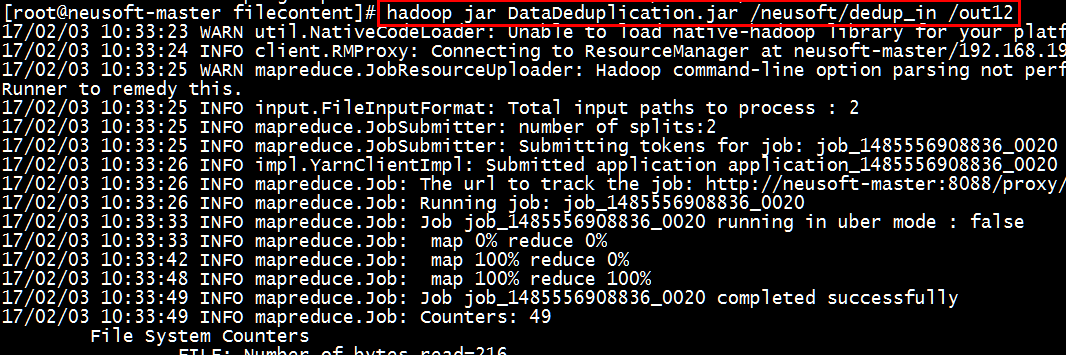
[root@neusoft-master filecontent]# hadoop jar DataDeduplication.jar /neusoft/dedup_in /out12
[root@neusoft-master filecontent]# hadoop dfs -text /out12/part-r-00000
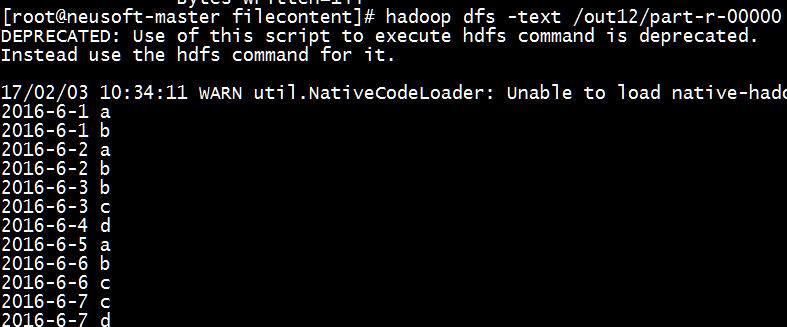
结果验证正确~
注意:HDFS的显示形式
[root@neusoft-master filecontent]# hadoop dfs -ls hdfs://neusoft-master:9000/out12
[root@neusoft-master filecontent]# hadoop dfs -ls /out12

等价表示形式

/out12的完整表达形式hdfs://neusoft-master:9000/out12

 浙公网安备 33010602011771号
浙公网安备 33010602011771号