Mapreduce其他部分
1.hadoop的压缩codec
Codec为压缩,解压缩的算法实现。 在Hadoop中,codec由CompressionCode的实现来表示。下面是一些实现:

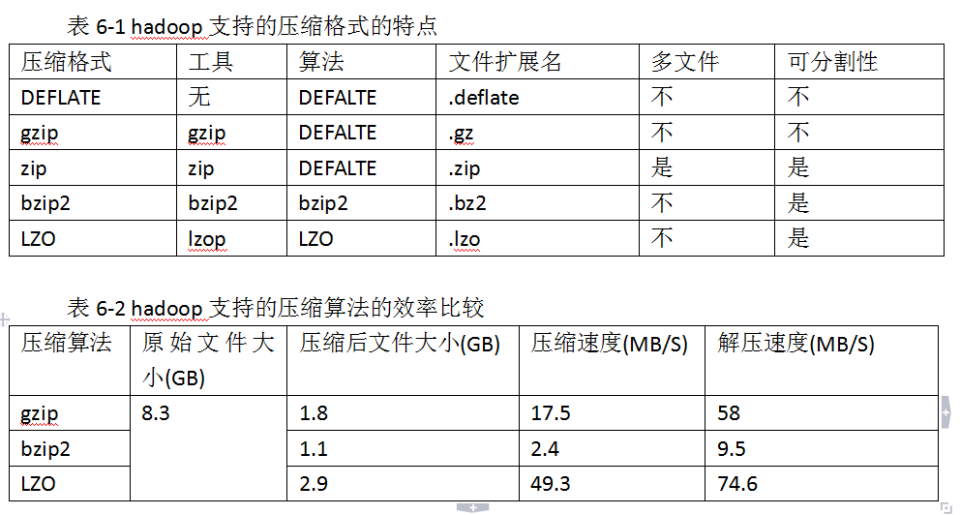
可分割性:可分割与不可分割的区别:文件是否可被切成多个inputsplit。
对于不能切割的文件,如果使用mapreduce算法,需要切割成一个inputsplit,那么这个文件在网络传输的时候必须连着传输
中间一旦传输失败就必须重传,一个inputsplit一般都比较小,对于文件比较大的文件可否分割也是影响性能的重要因素。
压缩比和压缩速度上综合相比LZO好一些,压缩速度是其他的十几倍,但是压缩比相差不大。
mapreduce中那些文件可压缩?
1. 输入文件可能是压缩文件
2.map输出可能是压缩文件
3.reduce输出可以压缩
代码:

完整的测试代码:


1 package Mapreduce; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.io.compress.CompressionCodec; 10 import org.apache.hadoop.io.compress.GzipCodec; 11 import org.apache.hadoop.mapreduce.Job; 12 import org.apache.hadoop.mapreduce.Mapper; 13 import org.apache.hadoop.mapreduce.Reducer; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 16 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 17 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 18 import org.apache.hadoop.yarn.webapp.hamlet.Hamlet.MAP; 19 20 /** 21 * 压缩文件实例 22 * 23 * 24 */ 25 public class CompressTest { 26 public static void main(String[] args) throws Exception { 27 //必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定 28 //2将自定义的MyMapper和MyReducer组装在一起 29 Configuration conf=new Configuration(); 30 String jobName=CompressTest.class.getSimpleName(); 31 //1首先寫job,知道需要conf和jobname在去創建即可 32 Job job = Job.getInstance(conf, jobName); 33 34 //*13最后,如果要打包运行改程序,则需要调用如下行 35 job.setJarByClass(CompressTest.class); 36 37 //3读取HDFS內容:FileInputFormat在mapreduce.lib包下 38 FileInputFormat.setInputPaths(job, new Path("hdfs://neusoft-master:9000/data/hellodemo")); 39 //4指定解析<k1,v1>的类(谁来解析键值对) 40 //*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class 41 job.setInputFormatClass(TextInputFormat.class); 42 //5指定自定义mapper类 43 job.setMapperClass(MyMapper.class); 44 //6指定map输出的key2的类型和value2的类型 <k2,v2> 45 //*下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定 46 job.setMapOutputKeyClass(Text.class); 47 job.setMapOutputValueClass(LongWritable.class); 48 //7分区(默认1个),排序,分组,规约 采用 默认 49 50 //**map端输出进行压缩 51 conf.setBoolean ("mapred.compress.map.output",true); 52 //**reduce端输出进行压缩 53 conf.setBoolean ("mapred.output.compress",true); 54 //**reduce端输出压缩使用的类 55 conf.setClass("mapred.output.compression.codec", GzipCodec.class, CompressionCodec.class); 56 //接下来采用reduce步骤 57 //8指定自定义的reduce类 58 job.setReducerClass(MyReducer.class); 59 //9指定输出的<k3,v3>类型 60 job.setOutputKeyClass(Text.class); 61 job.setOutputValueClass(LongWritable.class); 62 //10指定输出<K3,V3>的类 63 //*下面这一步可以省 64 job.setOutputFormatClass(TextOutputFormat.class); 65 //11指定输出路径 66 FileOutputFormat.setOutputPath(job, new Path("hdfs://neusoft-master:9000/out11")); 67 68 //12写的mapreduce程序要交给resource manager运行 69 job.waitForCompletion(true); 70 } 71 private static class MyMapper extends Mapper<LongWritable, Text, Text,LongWritable>{ 72 Text k2 = new Text(); 73 LongWritable v2 = new LongWritable(); 74 @Override 75 protected void map(LongWritable key, Text value,//三个参数 76 Mapper<LongWritable, Text, Text, LongWritable>.Context context) 77 throws IOException, InterruptedException { 78 String line = value.toString(); 79 String[] splited = line.split("\t");//因为split方法属于string字符的方法,首先应该转化为string类型在使用 80 for (String word : splited) { 81 //word表示每一行中每个单词 82 //对K2和V2赋值 83 k2.set(word); 84 v2.set(1L); 85 context.write(k2, v2); 86 } 87 } 88 } 89 private static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> { 90 LongWritable v3 = new LongWritable(); 91 @Override //k2表示单词,v2s表示不同单词出现的次数,需要对v2s进行迭代 92 protected void reduce(Text k2, Iterable<LongWritable> v2s, //三个参数 93 Reducer<Text, LongWritable, Text, LongWritable>.Context context) 94 throws IOException, InterruptedException { 95 long sum =0; 96 for (LongWritable v2 : v2s) { 97 //LongWritable本身是hadoop类型,sum是java类型 98 //首先将LongWritable转化为字符串,利用get方法 99 sum+=v2.get(); 100 } 101 v3.set(sum); 102 //将k2,v3写出去 103 context.write(k2, v3); 104 } 105 } 106 }
结果对比:
1.无压缩时运行mapreduce的时间
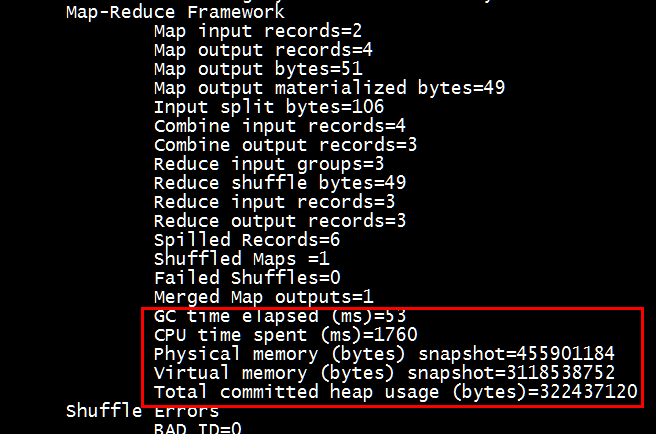
2.带压缩的运行时间
[root@neusoft-master filecontent]# hadoop jar CompressTest.jar
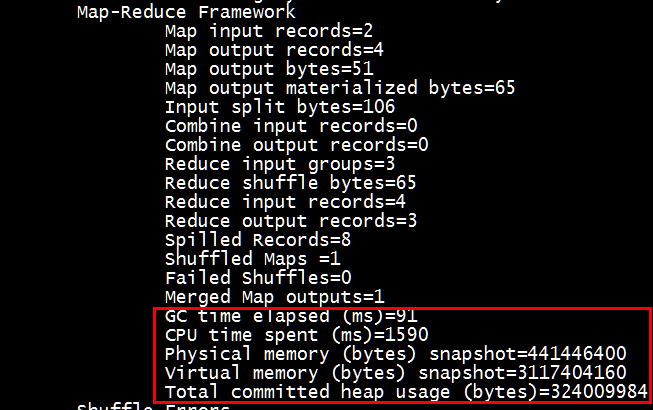
从时间上可以看出,运行时间和效率方面有了很大的提升,可以作为优化的一种。
2.mapreduce调度算法
hadoop目前支持以下三种调度器:
FifoScheduler:最简单的调度器,按照先进先出的方式处理应用。只有一个队列可提交应用,所有用户提交到这个队列。没有应用优先级可以配置。
CapacityScheduler:可以看作是FifoScheduler的多队列版本。每个队列可以限制资源使用量。但是,队列间的资源分配以使用量作排列依据,使得容量小的队列有竞争优势。集群整体吞吐较大。延迟调度机制使得应用可以放弃跨机器或者跨机架的调度机会,争取本地调度。 详情见官网http://hadoop.apache.org/docs/r1.2.1/capacity_scheduler.html
FairScheduler:多队列,多用户共享资源。特有的客户端创建队列的特性,使得权限控制不太完美。根据队列设定的最小共享量或者权重等参数,按比例共享资源。延迟调度机制跟CapacityScheduler的目的类似,但是实现方式稍有不同。资源抢占特性,是指调度器能够依据公平资源共享算法,计算每个队列应得的资源,将超额资源的队列的部分容器释放掉的特性。 详情见官网http://hadoop.apache.org/docs/r1.2.1/fair_scheduler.html

(1) FairScheduler的配置:
修改mapred-site.xml,然后重启集群 更多配置见conf/fair-scheduler.xml

(2)CapacityScheduler配置
修改mapred-site.xml,然后重启集群 更多配置见conf/capacity-scheduler.xml

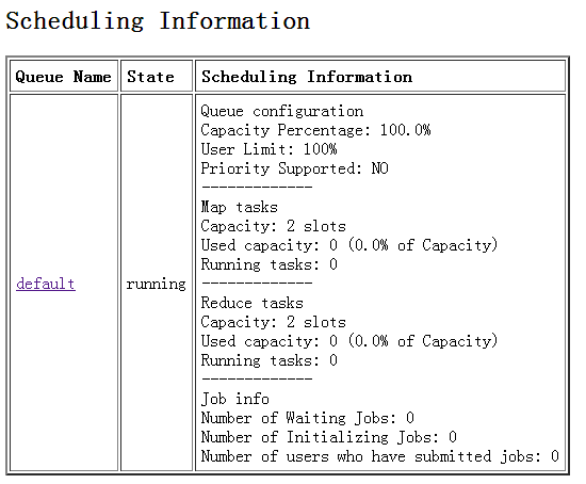
CapacityScheduler运行结果:
3.Hadoop Streaming
Hadoop Streaming是Hadoop提供的一个编程工具,它允许用户使用任何可执行文件或者脚本文件作为Mapper和Reducer,通过Hadoop Streaming编写的MapReduce应用程序中每个任务可以由不同的编程语言环境组成
4.MapReduce的job如何调优
- 如果存在大量的小数据文件,可以使用SequenceFile、自定义的CombineFileInputFormat
- 推测执行在整个集群上关闭,特定需要的作业单独开启,一般可以省下约5%~10%的集群资源
- mapred.map.task.speculative.execution=true; mapred.reduce.task.speculative.execution=false;
- 开启jvm重用 mapred.job.reuse.jvm.num.tasks=-1
- 增加InputSplit大小 mapred.min.split.size=268435456
- 增大map输出的缓存 io.sort.mb=300
- 增加合并spill文件数量 io.sort.factor=50 map端输出压缩,
- 推荐LZO压缩算法 mapred.compress.map.output=true; mapred.map.output.compression.codec=com.hadoop.compression.lzo.LzoCodec;
- 增大shuffle复制线程数 mapred.reduce.parallel.copies=15
- 设置单个节点的map和reduce执行数量(默认值是2) mapred.tasktracker.map.tasks.maxinum=2 mapred.tasktracker.reduce.tasks.maxinum=2
5.MapReduce常见算法
单词计数 数据去重 排序 Top K 选择 投影 分组 多表连接 单表关联
6.MapReduce中的join操作
- reduce side join
- map side join

 浙公网安备 33010602011771号
浙公网安备 33010602011771号