
kafka学习笔记
1.1 初识kafka
kafka 是一款基于发布与订阅的消息系统。
| 名词 | 解释 |
| broker | 消息系统处理的一个节点,一个kafka服务器被称为一个broker,多个broker被称为kafka集群 |
| topic | kafka中的消息归类,相当于mysql的表。发布到kafka的每条消息都要有topic |
| partition | 分区,每个topic由多个partition组成,相当于mysql的分区表,partition是消息物理上的集合,topic是逻辑集合。 |
| producer | 消息生产者,发送消息的客户端 |
| consumer | 消息消费者,消费消息的客户端 |
| offset | 偏移量,记录消费者消费到哪里了。保存在zk上或者kafka上 |
| consumerGroup | 消费者组,每个消费者都属于一个consumerGroup,多个消费者可以组成一个group,同一个组的消费者只能消费一条topic消息,不同组可以重复消费同一条消息,比如对于创建订单消息,A 系统可消费,B系统也可以消费,互相之前不影响。 |
Controller Broker
在分布式系统中,通常需要有一个协调者,该协调者会在分布式系统发生异常时发挥特殊的作用。在Kafka中该协调者称之为控制器(Controller),其实该控制器并没有什么特殊之处,它本身也是一个普通的Broker,只不过需要负责一些额外的工作(追踪集群中的其他Broker,并在合适的时候处理新加入的和失败的Broker节点、Rebalance分区、分配新的leader分区等)。值得注意的是:Kafka集群中始终只有一个Controller Broker。
Controller Broker的主要职责有很多,主要是一些管理行为,主要包括以下几个方面:
- 创建、删除主题,增加分区并分配leader分区
- 集群Broker管理(新增 Broker、Broker 主动关闭、Broker 故障)
- partition leader选举
- 分区重分配
一个简单的kafka集群
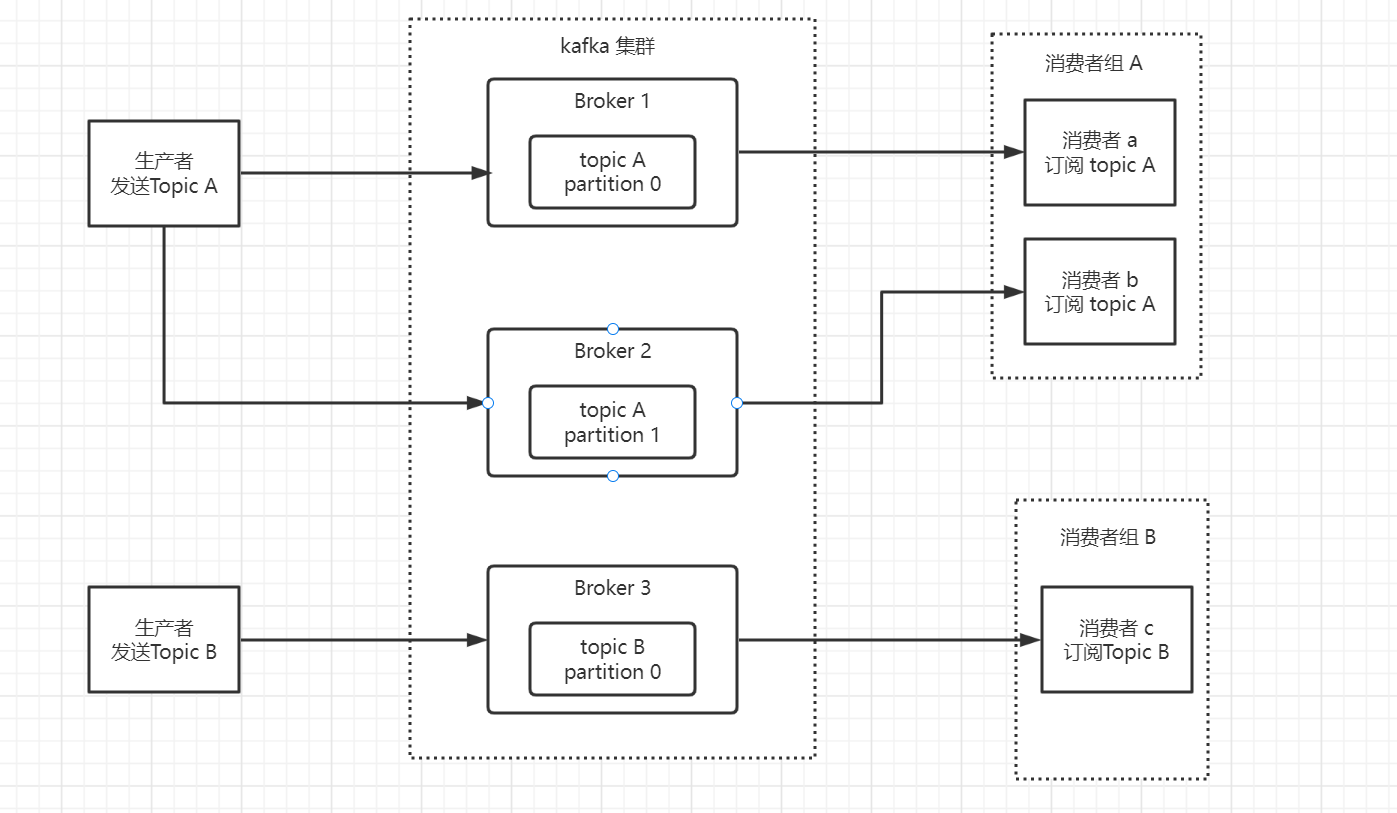
topic 和 partition
kafka的消息是通过topic进行分类的,相当于数据库的表,一类业务的数据集合。topic可以被分成若干个分区,消息以追加的方式写入分区,然后以先进先出的方式顺序读取
注意一个topic包含多个分区,因此无法保持消息的整体顺序性,只能保证单个分区的有序性。多分区设计可以提高程序性能。在我们的流量变大的时候,我们可以增加分区数来提高性能。
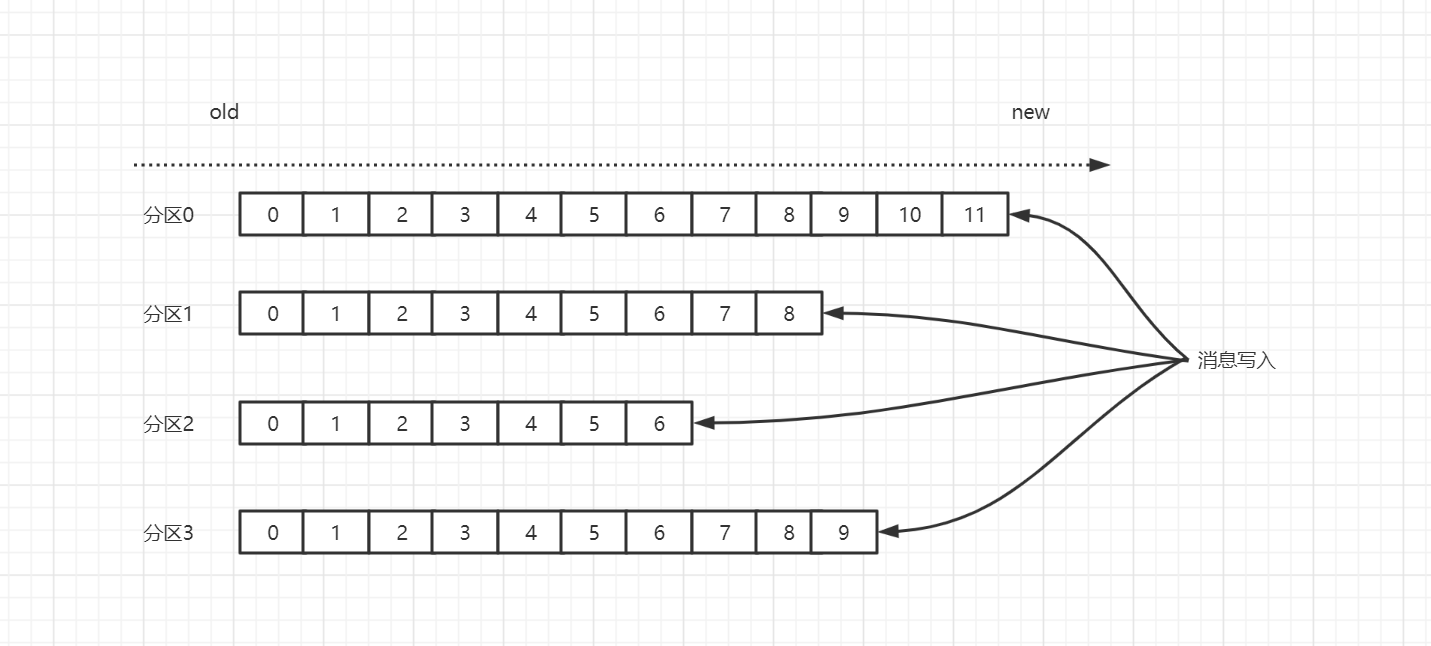
消费者在消费分区里面的消息的时候,会有一个offset来记录消费到哪里了,这里有同学会有疑问,最新加入的消费者应该从哪里消费了,有参数可以控制从哪里开始消费
#earliest
#当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
#latest
#当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
auto-offset-reset: earliest
1.2 生产者
1.2.1发送方式
- 异步发送,我们不关心是否正常到达,可能会丢失一些消息
kafkaTemplate.send(topic, message) - 同步发送,使用send()方法的时候,会返回一个future对象,我们使用get()方法,阻塞线程等待结果的返回
kafkaTemplate.send(topic, message).get(10, TimeUnit.SECONDS);
log.info("kafka消息发送成功:topic:{}, message:{}", topic, message);- 异步回调,kafka api提供回调钩子,使我们可以监听发送成功和失败的事件。
kafkaTemplate.send(topic, JSON.toJSONString(t)).addCallback(new ListenableFutureCallback() {
@Override
public void onFailure(Throwable throwable) {
log.error("发送topic{}产生异常信息:{}", topic, throwable.getMessage(), throwable);
}
@Override
public void onSuccess(Object o) {
log.info("发送成功topic:{}的消息:{}", topic,JSON.toJSONString(t));
}
});1.2.2 生产者参数配置
1.acks 可以保证生产者不丢消息。
- acks=0
意思就是我的KafkaProducer在客户端,只要把消息发送出去,不管发送出去的数据有没有同步完成,都不用管,直接就认为这个消息发送成功了。意味着producer不等待broker同步完成的确认,继续发送下一条(批)信息,提供了最低的延迟,但是持久性最差;当服务器发生故障时,就很可能发生数据丢失。例如leader已经死亡,producer不知情,还会继续发送消息broker接收不到数据就会数据丢失。就比如可能你发送出去的消息还在半路,结果呢,Partition Leader所在的Broker就直接挂了,然后你的客户端还认为消息发送成功了,此时就会导致这条消息就丢失了。 - acks=1
意思就是说只要Partition Leader接收到消息而且写入本地磁盘了,就认为成功了,不管其他的Follower有没有同步过去这条消息了。这种设置其实是kafka默认的设置,大家请注意,划重点!这是默认的设置,也就是说,默认情况下,你要是不重新设置acks这个参数,只要Partition Leader写成功导磁盘就算成功。
但是这里有一个问题,万一Partition Leader刚刚接收到消息,Follower还没来得及同步过去,结果Leader所在的broker宕机了,此时也会导致这条消息丢失,因为客户端已经认为发送成功了。
意味着producer要等待leader成功收到数据并得到确认,才发送下一条message。此选项提供了较好的持久性较低的延迟性。但如果Partition的Leader死亡,follwer尚未复制,数据就会丢失。 - acks=all
这个意思就是说,Partition Leader接收到消息之后,还必须要求ISR列表里跟Leader保持同步的那些Follower都要把消息同步过去,才能认为这条消息是写入成功了。 - acks=-1
这个和all是一样的,只是设置成这样的时候,参数min.insync.replicas才能生效。min.insync.replicas这个参数设定ISR中的最小副本数是多少,默认值为1,为什么要这个参数,就是ISR中如果只有leader的时候,这时候leader也挂了,数据依然丢失,但设置了最小副本数,就能保证最少有一个副本存在。
2.batch.size 和 linger.ms
kafka发送消息,并不是单次发往服务器的,是把多个消息打包成一个批次,一次性发往服务器,该参数指定了同一个批次的大小,如果达到这个阈值,就开始发送到服务器,否则留在内存中,同时还有linger.ms这个参数,这个是同一个批次数据停留在内存的最长时间,如果时间达到了,也会先把批次数据发送到服务器就算消息大小没有达到batch.size阈值。也就是这两个阈值,谁先达到都会把内存的消息发送到服务器。
3. buffer.memory
该参数用来设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。如果应用程序发送消息的速度超过发送到服务器的速度,会导致生产者空间不足。这个时候,send() 方法调用要么被阻塞,要么抛出异常,取决于如何设置 block.on.buffer.full参数(在0.9.0.0版本里被替换成了max.block.ns,表示在抛出异常之前可以阻塞一段时间)。
4.retries
retries 参数的值决定了生产者在发送消息的时候如果遇到错误,可以重发消息的次数,每次重试之间等待100ms,也可以通过retry.backoff.ms来改变。
5.max.in.flight.requests.per.connection
这个参数指定了生产者在收到服务器响应前可以发送多少个消息,把它设置成1可以保证消息是按顺序发送的服务器的,即使发生了重试。第一个批次在发送失败后,第二个批次数据是不能发送到服务器的,会等第一个完成才能进行第二个批次发送,但如果是大于1,第二个批次数据就会发送到服务器,顺序就会反了。=1可以保证消息顺序,但这样设置严重影响吞吐。
6.max.request.size
发送单个消息的最大值,比如1MB
7.request.timeout.ms
指定了生产者在发送数据时等待服务器返回响应的时间
1.2.3 生产者分区策略
kafka有自己的分区策略的,如果未指定,就会使用默认的分区策略,如果没有指定key,那么会使用轮询的随机策略均衡的将消息发送的topic的各分区上。如果指定了key,Kafka根据传递消息的key来进行分区的分配,即hash(key) % numPartitions。如果Key相同的话,那么就会分配到统一分区。当然也可以自定义分区策略,只要实现Partitioner这个接口。
1.3 消费者
想知道如何从kafka消费消息(kafka是拉消息的模式,有些mq是推。),需要先了解消费者和消费者组的概念。
1.3.1 消费者和消费者组
kafka 消费者从属于消费者群组,一个群组里的消费者订阅同一个topic,组里的每个消费者消息topic一部分消息。从而达到高吞吐。在生产者速率大于消费者的时候,我们可以增加消费者来提高消费速率。不同的群组可以消费同一个topic。比如订单创建消息,客服系统可用消费,CRM系统也可以消费,不同群组之间消费互不影响。
下图就展示了消费者组合消费者的关系,一般情况下分区数=消费者数,一个消费者负责消费一个分区消息。如果消费者数小于分区数,就会出现一个消费者消费两个分区的消息。注意如果消费者数大于分区数,多余的消费者将不会消费任何消息(一个分区只能一个消费者消费)
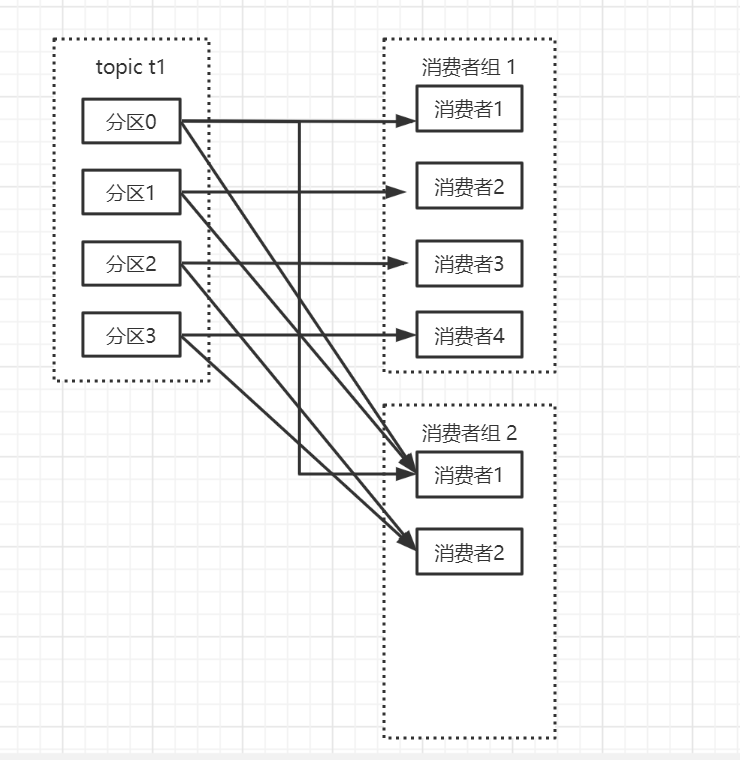
1.3.2 如何保证顺序消费
- 我们知道同一个分区消息是有序的,那我们可以把消息固定发送到同一个分区,但这样的话就失去分布式的特性了。
- max.in.flight.requests.per.connection 设置成1,这个参数指定了生产者在收到服务器响应前可以发送多少个消息,把它设置成1可以保证消息是按顺序发送的服务器的,即使发生了重试
1.3.3 偏移量的提交
我们每次poll()消息的时候,总是返回没有被消费的消息,那kafka是如何做到的,它内部有一个偏移量,记录了当前消费者消费到分区的什么位置。当我们消费完消息更新分区位置的操作叫偏移量提交。
(1)自动提交 enable.auto.commit=true,每隔5s,消费者会自动吧从poll()方法手动的最大偏移量提交上去。这种方式有个问题,如果在最近一次提交后3s发生了rebalance,那么这时候偏移量没有提交上去,这3s内的消息会被重复消费。
(2)手动提交(同步or异步)enable.auto.commit=false,使用commitSync()同步提交这个方法会重试到提交成功,使用commitAsync()异步提交,异步的不会重试。因为可能另外一个更大的线程提交了偏移量,如果我们重试之前比较低的偏移量就会导致重复消费消息。
1.3.4 rebalance
kafka 怎么均匀地分配某个 topic 下的所有 partition 到各个消费者,从而使得消息的消费速度达到最快,这就是平衡(balance)。而 rebalance(重平衡)其实就是重新进行 partition 的分配,从而使得 partition 的分配重新达到平衡状态。以下几种情况会发送rebalance。
- 订阅 Topic 的分区数发生变化。
- 订阅的 Topic 个数发生变化。
- 消费组内成员个数发生变化。例如有新的 consumer 实例加入该消费组或者离开组。
在如下条件下,partition要在consumer中重新分配:
条件1:有新的consumer加入
条件2:旧的consumer挂了
条件3:coordinator挂了,集群选举出新的coordinator
条件4:topic的partition新加
条件5:consumer调用unsubscrible(),取消topic的订阅
特别针对第三种情况说明下,消费者组成员变化也分以下几种情况
- 新成员加入
- 组成员主动离开
- 组成员崩溃,收不到心跳,或者在一定时间内没有完成消费,这篇文章写的挺详细的,可以看下 https://www.cnblogs.com/chanshuyi/p/kafka_rebalance_quick_guide.html
几个重要的消费者参数都会导致rebalance
session.timeout.ms 表示 consumer 向 broker 发送心跳的超时时间。例如 session.timeout.ms = 180000 表示在最长 180 秒内 broker 没收到 consumer 的心跳,那么 broker 就认为该 consumer 死亡了,会启动 rebalance。
heartbeat.interval.ms 表示 consumer 每次向 broker 发送心跳的时间间隔。heartbeat.interval.ms = 60000 表示 consumer 每 60 秒向 broker 发送一次心跳。一般来说,session.timeout.ms 的值是 heartbeat.interval.ms 值 的 3 倍以上。
max.poll.interval.ms 表示 consumer 每两次 poll 消息的时间间隔。简单地说,其实就是 consumer 每次消费消息的时长。如果消息处理的逻辑很重,那么市场就要相应延长。否则如果时间到了 consumer 还么消费完,broker 会默认认为 consumer 死了,发起 rebalance。
max.poll.records 表示每次消费的时候,获取多少条消息。获取的消息条数越多,需要处理的时间越长。所以每次拉取的消息数不能太多,需要保证在 max.poll.interval.ms 设置的时间内能消费完,否则会发生 rebalance。
最后说下kafka高性能的原因。
1.从上面partition可以看出,每个分区都是顺序写盘,这比随机写盘效率高。
2.kafka零拷贝。
3.分布式,多分区提高了写入和消费性能,性能不行的时候可以加broker或者增加分区数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号