
Selenium Grid的原理、配置与使用(转)
Selenium Grid
Selenium Grid在前面介绍Selenium的时候说过它有三大组件,Selenium Grid就是其中之一而作用就是分布式执行测试。讲分布式之前还是要说说UI自动化的优势来突出Selenium Grid,最简单的两点解决重复执行测试、解决多浏览器兼容这是UI自动化的价值;那分布式是什么概念?简单的说就是老大收到任务,分发给手下去干;通过Selenium Grid的可以控制多台机器多个浏览器执行测试用例,分布式上执行的环境在Selenium Grid中称为node节点。
举例说明一下,比如当自动化测试用例达到一定数量的时候,比如上万,一台机器执行全部测试用例耗时5个小时(只是举例,真正的耗时是需要根据测试用例场景的复杂度决定的),而如果需要覆盖主流浏览器比如Chrome、Firefox,加起来就是10个小时;这时候领导跟你说有什么办法可以解决这个执行速度?当然最笨的办法就是另外拿台机器,然后部署环境,把测试用例分开去执行然后合并结果即可。而Selenium也想到了这点,所以有了Selenium Grid的出现,它就是解决分布式执行测试的痛点。
Selenium Grid工作原理
Selenium Grid实际它是基于Selenium RC的,而所谓的分布式结构就是由一个hub节点和若干个node代理节点组成。Hub用来管理各个代理节点的注册信息和状态信息,并且接受远程客户端代码的请求调用,然后把请求的命令转发给代理节点来执行。下面结合环境部署来理解Hub与node节点的关系。
下载selenium-server-standalone-2.53.1.jar
下载地址:http://selenium-release.storage.googleapis.com/index.html
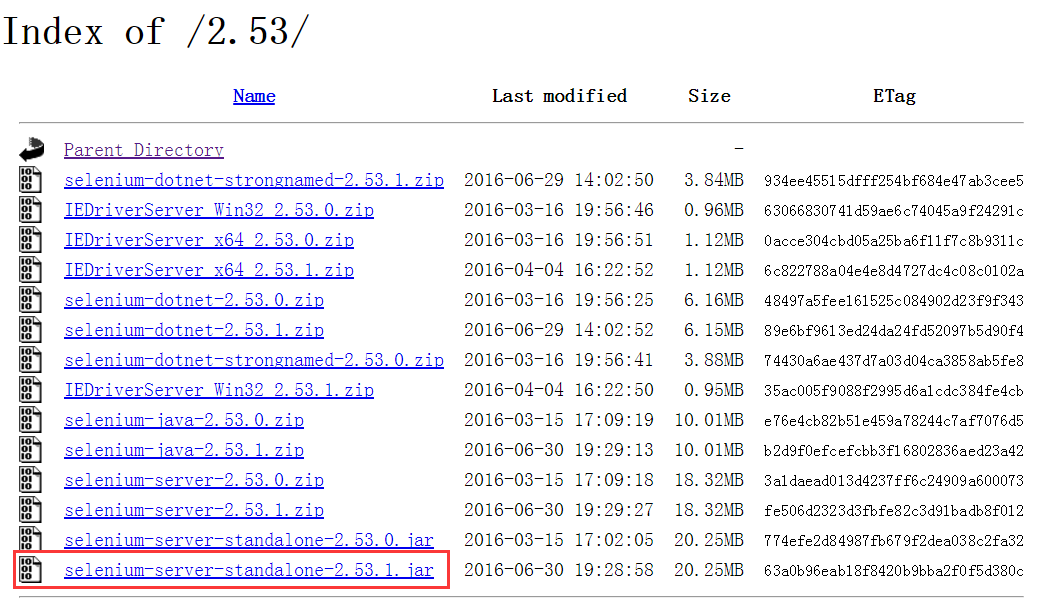
进入selenium-server-standalone-2.53.1.jar包的位置,如E:\selenium
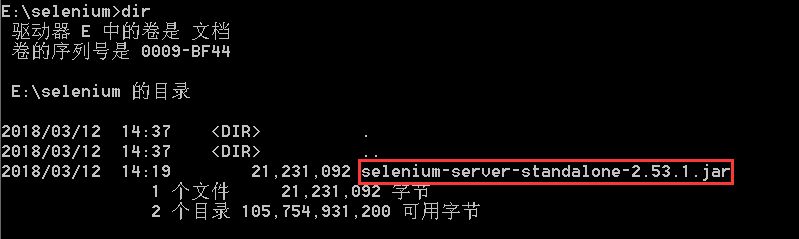
启动hub,命令如下(命令以截图为准,请参考截图中的启动命令):
java -jar selenium-server-standalone-2.53.1.jar -role hub -maxSession 10 -port 4444
参数解析
l -role hub表示启动运行hub;
l -port是设置端口号,hub的默认端口是4444,这里使用的是默认的端口,当然可以自己配置;
l -maxSession为最大会话请求,这个参数主要要用并发执行测试用例,默认是1,建议设置10及以上。
浏览器打开地址:http://localhost:4444/grid/console,出现如下图表示hub启动成功。

启动hub后,就需要运行节点啦,最少都要有一个node节点,不然hub就成空头司令了;而node节点可以与hub在同一台机器上运行,演示一个node节点与hub同机,另一个node节点启动了一台虚拟机。
hub机 ip:192.168.0.245
node1机 ip:192.168.0.245
node2机 ip:192.168.0.183
启动node节点1
node1节点,配置firefox浏览器,运行下面命令(命令以截图为准,请参考截图中的启动命令):
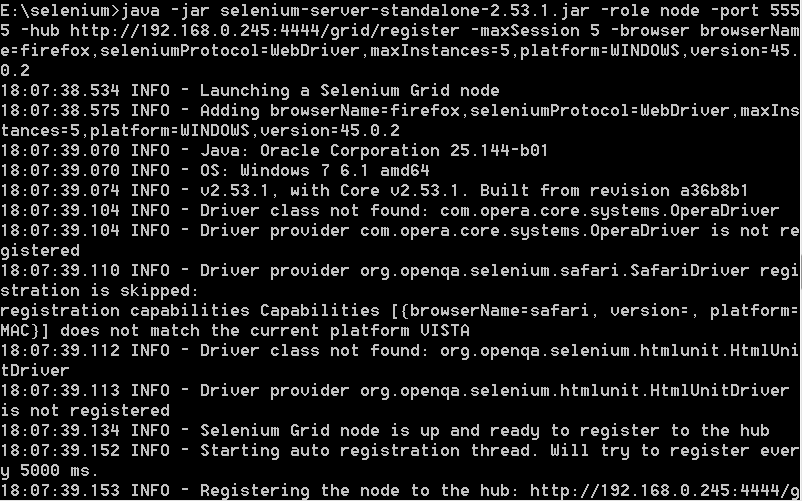
没有报错则再次刷新一下http://localhost:4444/grid/console的访问会发现node节点已经显示,表示启动成功;
参数解析:
l -role node:表示启动的是node节点
l -port 5555:指定node节点端口
l -hub http://192.168.0.245:4444/grid/register:表示hub机地址
l -maxSession 5:node节点最大会话请求
l -browser browserName=firefox,seleniumProtocol=WebDriver,maxInstances=5,platform=WINDOWS,version=45.0.2
这个就是设置浏览器的参数啦,这个很重要;browserName表示浏览器名字,如chrome、firefox、ie;maxInstances表示最大实例,可以理解为最多可运行的浏览器数,这个值很关键,不能大于前面maxSession的值,否则可能会出错;platform表示操作系统;version表示浏览器版本
启动node节点2
node2节点,在目录放了chromedriver.exe文件,这里要提示一下,这个chromedriver.exe文件前面说过下载地址了,主要是版本需要与系统中安装的chrome浏览器匹配
运行下面命令(命令以截图为准,请参考截图中的启动命令):

没有报错则再次刷新一下http://localhost:4444/grid/console的访问会发现node节点已经显示,表示启动成功。
参数解析:
l -Dwebdriver.chrome.driver=chromedriver.exe :浏览器插件,如果是其他浏览器就写对应的名字
如firefox: -Dwebdriver.firefox.driver=geckodriver.exe
注意多了这个参数注意是chromedriver.exe需要指定,而对于Webdriver2是支持geckodriver所以不需要指定geckodriver,但前提是firefox浏览器版本不能大于46,所以看到node节点1使用的是45版本的浏览器
Selenium Grid使用
当实例化Hub远程时,会根据配置去匹配Hub上注册的node代理节点,匹配成功后转发给代理节点,这时候代理节点会生成sessionid启动浏览器,然后响应给Hub说一切准备就绪,Hub也会把这个sessionid响应给客户端,接下来的客户端的代码发来的请求都会被Hub转发给这个代理节点来执行。这里实际上整个流程与Selenium1.0的原理是一样的,只是多了Hub这一层。
DesiredCapabilities capability = new DesiredCapabilities();
capability.setBrowserName("chrome");
capability.setPlatform(Platform.WINDOWS);
try {
WebDriver driver = new RemoteWebDriver(new URL("http://192.168.0.245:4444/wd/hub"), capability);
driver.get("http://www.baidu.com");
driver.quit();
} catch (MalformedURLException e) {
e.printStackTrace();
}
要注意实例化driver对象时填写的服务地址是node节点的地址,这样就会直接去节点运行;还有一个注意的就是DesiredCapabilities配置,一定要设置该节点运行参数正确的浏览器、浏览器版本、系统,如果参数不对都会出现报错。
Selenium Grid总结
通过上面的环境搭建,再回顾一下原理,就是hub接受到客户端的请求然后转发给node节点执行。那hub是怎么转发给node节点的呢?多节点的场景下hub是如何知道转发给那个node节点?这就是运行node节点的参数以及客户端代码来决定的啦。
DesiredCapabilities capability = new DesiredCapabilities();
capability.setBrowserName("chrome");
capability.setPlatform(Platform.WINDOWS);
先来看上面3句话,DesiredCapabilities类可以理解为配置,设置浏览器名称为chrome,设置系统为windows;然后再回到上面看node节点的运行参数,设置浏览器、系统为chrome、windows的是不是node2节点,答案肯定是的。而设置参数的方法不仅仅只有这两个,还有setVersion()方法设置浏览器版本。
而hub怎么知道这些node节点的参数,就是在启动node节点的-hub参数,这表示这个节点注册地址,就理解为绑定的hub地址,这样就形成了hub与node的关系。而如果我们在客户端代码使用的时候,hub去注册的node节点匹配时,匹配失败会报错。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号