(一)Python入门-3序列:17字典-核心底层原理-内存分析-存储键值对过程
字典核心底层原理(重要)
字典对象的核心是散列表。散列表是一个稀疏数组(总是有空白元素的数组),数组的 每个单元叫做 bucket。每个 bucket 有两部分:一个是键对象的引用,一个是值对象的引 用。
由于,所有bucket 结构和大小一致,我们可以通过偏移量来读取指定 bucket。
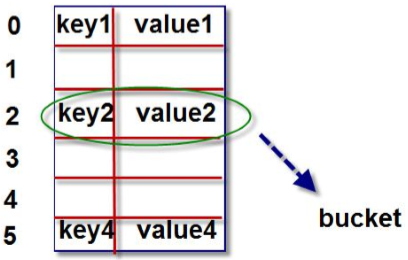
一:将一个键值对放进字典的底层过程
>>> a = {}
>>>
a["name"]="jack"
假设字典 a对象创建完后,数组长度为 8:

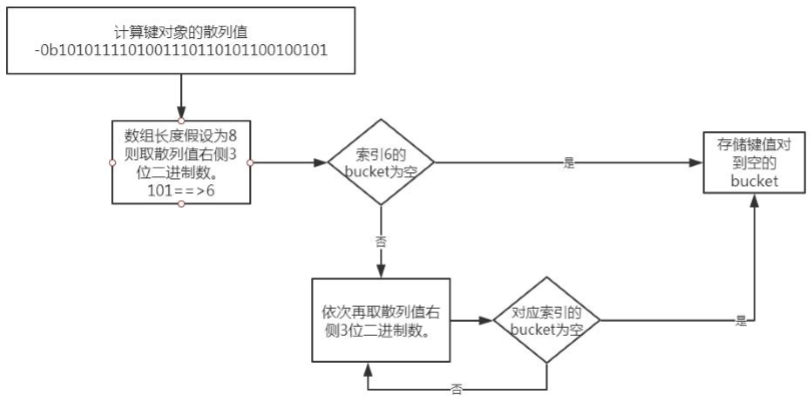
我们要把”name”=”jack”这个键值对放到字典对象 a 中,首先第一步需要计算 键”name”的散列值。Python 中可以通过hash()来计算。
>>> bin(hash("name"))
'-0b1010111101001110110101100100101'
由于数组长度为 8,我们可以拿计算出的散列值的最右边 3 位数字作为偏移量,即 “101”,十进制是数字 5。我们查看偏移量 5,对应的 bucket 是否为空。如果为空,则 将键值对放进去。如果不为空,则依次取右边 3位作为偏移量,即“100”,十进制是数字4。再查看偏移量为 4 的 bucket 是否为空。直到找到为空的 bucket 将键值对放进去。流 程图如下:
二:扩容
python会根据散列表的拥挤程度扩容。“扩容”指的是:创造更大的数组,将原有内容 拷贝到新数组中。
容量接近 2/3 时,数组就会扩容。
posted on 2019-05-11 23:32 JACK#zhang 阅读(1112) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号