
Gumbel_Softmax 概要
Gumble_Softmax 可以解决的问题
场景:对于一个分类任务,通常会使用softmax函数来将模型的输出值转换为概率的形式,并通过argmax函数取最大的概率值标签作为模型的预测标签。在分类任务中,argmax可以不参与反向传播过程(即直接通过softmax值和true_label计算loss),而在其他任务中,例如利用GAN生成文本则需要利用argmax的结果去生成loss,此时argmax是位于反向传播中的。
-
解决argmax输出值不能反应模型输出的概率分布的问题
出现问题的原因: 当训练过程中,softmax的输出值为 p = [0.7, 0.2, 0.1], 其表示 p([1, 0, 0]) = 0.7; p([0, 1, 0]) = 0.2; p([0, 0, 1]) = 0.1; 若采用argmax(p), 其结果为 [1, 0, 0] , 且若 p 的值一直维持这样一种概率分布,那么argmax的值将一直保持 [1, 0, 0], 且概率为 1, 这不符合输出的概率分布[0.7, 0.2, 0.1],即100次取值中, [1, 0, 0] 出现70次, [0, 1, 0] 出现20次, [0, 0, 1] 出现10次。
解决: 在argmax函数中引入随机性,即在argmax函数在引入一个符合gumble分布的噪声值G, G=-log(-log(ξ)), ξ是从[0,1]均匀分布中随机取样的,最后的 argmax函数变为 y = argmax(log§ + G), 最后加上onehot的操作获得输出的采样值 y = onehot(argmax[log§ + G]); § 是模型的逻辑输出值(非softmax后的概率分布), 这样最终获得的值是符合模型逻辑值§经过softmax后的概率分布的,也就是说,100次采样中, [1, 0, 0] 出现70次, [0, 1, 0] 出现20次, [0, 0, 1] 出现10次。
证明最后的结果是符合模型输出的概率分布的
理论证明:
https://blog.csdn.net/u011345885/article/details/122610352
实例证明:
参考: https://zhuanlan.zhihu.com/p/495806343
logits = torch.Tensor([0.7, 0.2, 0.1]) q1 = {0:0,1:0,2:0} for i in range(10000): t = torch.nn.functional.gumbel_softmax(logits, tau=0.2).argmax().item() q1[t] += 1 q2 = torch.softmax(logits, -1) print("q1", q1) print("q2", q2) >> q1 {0: 4670, 1: 2757, 2: 2573} >> q2 tensor([0.464, 0.281, 0.255]) -
解决argmax不可导,无法进行反向传播的问题
出现的原因: argmax(x,y)不可导的根本原因是其向量空间不是光滑的,有尖锐的点和面;而是某些任务中,argmax会被插入到反向传播的计算图中。
解决: 在解决上个问题的基础上,我们可以获得one_hot形式的符合模型输出概率分布的采样值 y = onehot(argmax[log§ + G]), 但是其中的 one(argmax()) 还是不可导的操作,所以可以使用softmax 来近似 one(argmax()), 并增加一个温度函数 tau 来控制最后的结果和 真实onehot的近似程度。为什么softmax操作是可导的,其实softmax 就是 one(argmax()) 的光滑化。
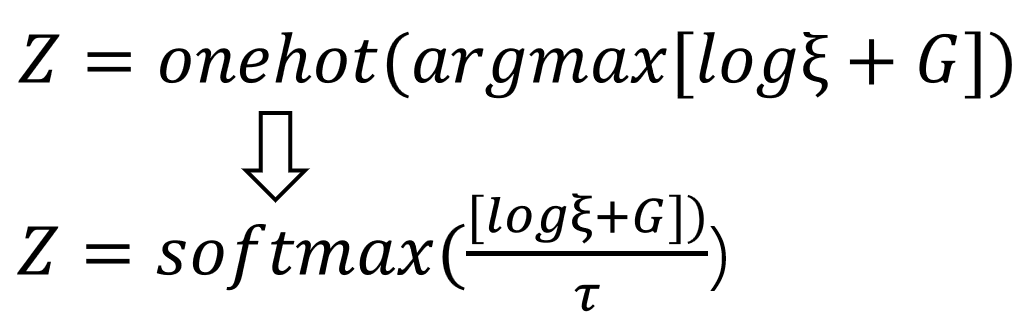
当 tau 足够小时,采样出来的向量十分接近 onehot 形式(类onehot但是不是真实的onehot), 而 tau 比较大时,采样的值接近于均匀分布。一般在训练初期,设置较大的tau,保证模型的充足的探索性;而在训练后期,一般设置较小的tau,生成比较稳定的 类似onehot向量。下图是原论文[https://arxiv.org/pdf/1611.01144.pdf] 中对于 tau 参数大小的实验结果。
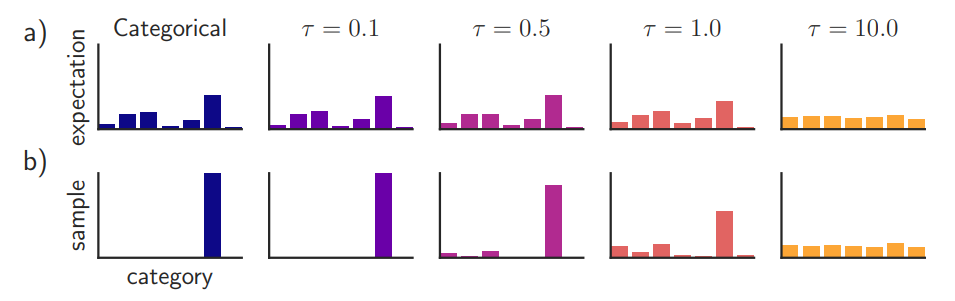
可以看出随着温度参数的增大采样值的分布逐渐由类onehot分布转换为均匀分布。
在 pytorch的 gumbel_softmax 的源码中可以对于其实现原理有一个清晰的认识。
其中有一个 hard 参数,当hard = False,函数直接返回采样值,当 hard = True, 函数是对采样值进行了一个 max 的操作,最后再和采样值组合在一起。这样的操作使得,在 forward 阶段, 传播的是 onehot值 y_hard; 而在 backpropagation 阶段,传播的是 y_soft 的梯度信息,因为 detach() 函数截断了其余的梯度传播。def gumbel_softmax(logits: Tensor, tau: float = 1, hard: bool = False, eps: float = 1e-10, dim: int = -1) -> Tensor: ######### gumbels = ( -torch.empty_like(logits, memory_format=torch.legacy_contiguous_format).exponential_().log() ) # ~Gumbel(0,1) gumbels = (logits + gumbels) / tau # ~Gumbel(logits,tau) y_soft = gumbels.softmax(dim) if hard: # Straight through. index = y_soft.max(dim, keepdim=True)[1] y_hard = torch.zeros_like(logits, memory_format=torch.legacy_contiguous_format).scatter_(dim, index, 1.0) ret = y_hard - y_soft.detach() + y_soft else: # Reparametrization trick. ret = y_soft return ret

