1.Python字符编码
1.编码简介
编码的种类情况
- ASCII 占1个字节,只支持英文
- GB2312 占2个字节,支持6700+汉字
- GBK GB2312的升级版,支持21000+汉字
- ks_c_5601-1987 韩国编码
由于每个国家都有自己的字符,所以其对应关系也涵盖了自己国家的字符,但是以上编码都存在局限性,即:仅涵盖本国字符,无其他国家字符的对应关系。应运而生出现了万国码,他涵盖了全球所有的文字和二进制的对应关系,Unicode解决了字符和二进制的对应关系,但是使用unicode表示一个字符,太浪费空间。
为了解决存储和网络传输的问题,出现了Unicode Transformation Format,学术名UTF,即:对unicode中的进行转换,以便于在存储和网络传输时可以节省空间!
- UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个
2.字符在硬盘的储存
无论以什么编码在内存里显示字符,存到硬盘上都是2进制。
ascii编码(美国):
l 0b1101100
o 0b1101111
GBK编码(中国):
老 0b11000000 0b11001111
男 0b11000100 0b11010000
Shift_JIS编码(日本):
私 0b10001110 0b10000100
は 0b10000010 0b11001101
要注意的是,存到硬盘上时是以何种编码存的,再从硬盘上读出来时,就必须以何种编码读,要不然就乱了。
3.编码的转换
编码也一样,虽然有了unicode and utf-8 , 但是由于历史问题,各个国家依然在大量使用自己的编码,比如中国的windows,默认编码依然是gbk,而不是utf-8。
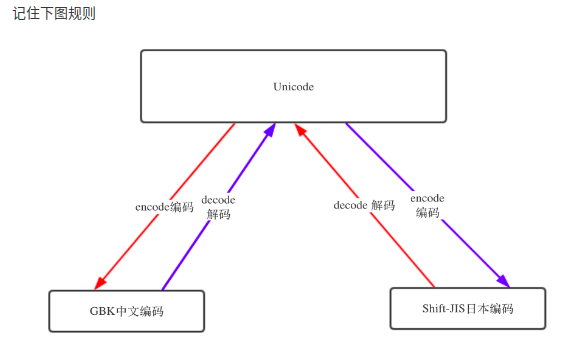
只要用python3,无论你的程序是以哪种编码开发的,都可以在全球各国电脑上正常显示,真是太棒啦!
PY3 除了把字符串的编码改成了unicode, 还把str 和bytes 做了明确区分, str 就是unicode格式的字符, bytes就是单纯二进制啦。
字节码bytes
python3中bytes用b’xxx’表示,其中的x可以用字符,也可以用ascii表示。
bytes与str类型的相互转换
str(unicode)类型是基准!要将str类型转化为bytes类型,使用encode()内置函数;反过来,使用decode()函数。使用实例如下:
>>>oath = ‘我爱妞’ >>>type(oath) <class 'str'> >>>oath = oath.encode(‘utf-8’) >>> type(oath) <class 'bytes'> >>> oath b'\xe6\x88\x91\xe7\x88\xb1\xe5\xa6\x9e' >>> oath = oath.decode() >>> oath '我爱妞'
文件的编码
with open(‘sun.bin’,’wb’) as f:
f.write(b‘sui’)
在open文件的时候用“wb”方式打开,即二进制写的方式,所以下面的write函数对象用的是bytes类型的b’sui’,这个时候如果使用f.write(‘sui’)就会出错的。
字节码bytes与字符之间的关系
将表示二进制的bytes进行适当编码就可以变为字符了,比如utf-8或是gbk等等编码格式都可以。(理解就是:有utf-8格式的bytes,也有gbk格式的bytes等等)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号