计组笔记第四章——指令系统
4.4.1 指令格式
- 指令(又称机器指令):
是指示计算机执行某种操作的命令,是计算机运行的最小功能单位。
一台计算机的所有指令的集合构成该机的指令系统,也称为指令集。
注:一台计算机只能执行自己指令系统的指令,不能执行其他指令系统的指令。如x86架构和ARM架构。
指令格式:
- 一条指令就是机器语言的一个语句,它是一组有意义的二进制代码。
- 一条指令通常要包括操作码字段和地址码字段两个部分。
操作码(op):指明用户要干什么。
地址码(A):指明对谁进行操作。 - 由于不同指令的操作不同,一条指令可能包含的地址码个数也不同,可能为0、1、2、3、4个地址码。根据地址码数目不同,可以将指令分为零地址指令、一地址指令、二地址指令……
零地址指令
- 不需要操作数,如空操作、停机、关中断等指令
- 堆栈计算机,两个操作数隐含存放在栈顶和次栈顶,计算结果压回栈顶。例如数据结构的“后缀表达式的计算”。
一地址指令
- 只需要单操作数,如加1、减1、取反、求补等
指令含义:\(OP(A_1) \rightarrow A_1\)
对\(A_1\)进行操作之后得到的结果存回\(A_1\)的存储单元。 - 需要两个操作数,但其中一个操作数隐含在某个寄存器(如ACC)
指令含义:\((ACC)OP(A_1) \rightarrow ACC\)
完成一条指令需要2次访存,取指令和读\(A_1\)
注:\(A_1\)是某个主存地址,\((A_1)\)表示\(A_1\)所指向的地址中的内容。
二、三地址指令
- 二地址指令:常用于需要两个操作数的算术运算、逻辑运算相关指令
指令含义:\((A_1)OP(A_2) \rightarrow A_1\)
完成一条指令需要访存4次,取指、读\(A_1\)、读\(A_2\)、写\(A_1\) - 三地址指令:常用于需要两个操作数的算术运算、逻辑运算相关指令
指令含义:\((A_1)OP(A_2) \rightarrow A_3\)
最终运算结果存到\(A_3\)中。
完成一条指令需要访存4次,取指、读\(A_1\)、读\(A_2\)、写\(A_3\)
四地址指令
- 指令含义:\((A_1)OP(A_2) \rightarrow A_3\),\(A_4\) = 下一条将要执行指令的地址
完成一条指令需要访存4次,取指、读\(A_1\)、读\(A_2\)、写\(A_3\) - 正常情况下:取指令之后PC+1,指向下一条指令
四地址指令:执行指令后,将PC的值修改为\(A_4\)所指的地址。 - 地址码的位数对指令的执行有什么影响吗?
n位地址码的直接寻址范围 = \(2^n\)
若指令总长度固定不变,则地址码数量越多,寻址能力越差。
指令分类
指令——按指令长度分类
- 指令字长:一条指令的总长度(可能会变),半字长指令、单字长指令、双字长指令表明指令长度是机器字长的多少倍。
- 机器字长:CPU进行一次整数运算所能处理的二进制数的位数(通常和ALU直接相关,是固定不变的)
- 存储字长:一个存储单元中的二进制代价位数(通常和MDR位数相同,固定不变)
- 如果某个计算机指令系统中所有指令的长度相等,则成为定长指令字结构
- 如果某个计算机指令系统中所有指令的长度不相等,则成为变长指令字结构
指令——按操作码长度分类
- 定长操作码:指令系统中所有指令的操作码长度都相同。如果操作码长度为n位,则最多表示\(2^n\)条指令。
控制器的译码电路设计简单,但灵活性较低。 - 可变长操作码:指令系统中各指令的操作码长度可变。
控制器的译码电路设计复杂,但灵活性高。 - 扩展操作码指令格式:
定长指令字结构 + 可变长操作码
指令——按操作类型分类
- 数据传送:
LOAD: 作用:把存储器中的数据放到寄存器中
STORE: 作用:把寄存器中的数据放到存储器中 - 算术逻辑操作:
算术:+、-、*、/、+1、-1、求补、浮点运算、十进制运算
逻辑:&、|、!、异或、位操作、位测试、位清除、位求反 - 移位操作:
算术移位、逻辑移位、循环移位(带进位和不带进位) - 转移操作:
无条件转移: JMP
条件转移:JZ:结果为0时转移;JO:结果溢出时转移;JC结果有进位时转移
调用和返回:CALL和RETURN
陷阱(Trap)与陷阱指令 - 输入输出操作:
CPU寄存器与IO端口之间的数据传送(端口即IO接口中的寄存器)
- 上面的5条可被分为4类:
数据传送类(进行主存与CPU直接的数据传送):1
运算类:2、3
程序控制类(改变程序的执行顺序):4
输入输出类(进行CPU和I/O设备之间的数据传送):5
4.1.2 扩展操作码指令格式
扩展操作码
- 扩展操作码举例:
指令字长为16位,每个地址码占4位:
前4位为基本操作码字段OP,另有3个4位长的地址字段:\(A_1\)、\(A_2\)和\(A_3\)。
4位基本操作码若全部用于3地址指令,则有16条。
但至少须将1111留作扩展操作码之用,即三地址指令为15条:
0000 \(A_1\) \(A_2\) \(A_3\) 到
1110 \(A_1\) \(A_2\) \(A_3\)
二地址指令可以有8位操作码,1111 1111留作扩展,其余二地址指令有15条:
1111 0000 \(A_2\) \(A_3\) 到
1111 1110 \(A_2\) \(A_3\)
一地址指令可以有12位操作码,1111 1111 1111留作扩展,其余一地址指令有15条:
1111 1111 0000 \(A_3\) 到
1111 1111 1110 \(A_3\)
零地址指令的后4位可以取全0到全1共十六种状态,零地址指令共16条:
1111 1111 1111 0000 到
1111 1111 1111 1111 - 在设计扩展操作码指令格式时,必须注意以下两点:
- 不允许短码是长码的前缀,即短操作码不能与长操作码的前面部分代码相同。
- 各指令的操作码不能重复。
- 通常情况下,对使用频率较高的指令,分配较短的操作码;对使用频率较低的指令,分配较长的操作码,从而尽可能减少指令译码和分析的时间。
- 根据上面的结论,设计另一种扩展操作码:
设指令长度固定为16位,试设计一套指令系统满足:- 有15条三地址指令:
0000 \(A_1\) \(A_2\) \(A_3\) 到
1110 \(A_1\) \(A_2\) \(A_3\) - 有12条二地址指令:
以1111开头
1111 0000 \(A_1\) \(A_2\) 到
1111 1011 \(A_1\) \(A_2\) - 有62条一地址指令:
以1111 11开头
1111 1100 0000 \(A_1\) 到
1111 1111 1101 \(A_1\) - 有32条零地址指令:
以1111 1111 111开头
1111 1111 1110 0000 到
1111 1111 1111 1111
- 有15条三地址指令:
- 设地址长度为n,上一层留出m种状态,下一层可扩展出\(m \times 2^n\)种状态。
- 扩展操作码的优点:在指令字长有限的前提下仍保持比较丰富的指令种类
- 扩展操作码的缺点:增加了指令译码和分析的难度,使控制器的设计复杂化。
4.2.1 指令寻址
如何确定下一条指令的存放地址?
顺序寻址
一般情况下,下一条指令的地址:\((PC) + 1 \rightarrow PC\)
注: 按存储字长编址时(PC) + 1, 如果按字节编址,需要(PC) + 存储字长/8
跳跃寻址
由转移指令指出
如果这条指令时条约指令,根据指令的要求修改PC。如JMP指令类似C语言里的goto,它会把这条指令后的PC改为规定的值,之后直接跳转到对应指令。
4.2.2 数据寻址
数据寻址:确定本条指令的地址码指明的真实地址。
指令的地址码有很多种解读方式,有可能是逻辑地址、物理地址还可能是偏移量。所以给定的地址码到底该怎么解读呢?
数据寻址的方式有如下10种:
- 给指令加上寻址特征字段,寻址特征字段负责说明后面的形式地址对应的寻址方式。寻址方式和寻址特征的对应关系如下图:
![知识总览]()
通过形式地址求出的操作数的真实地址,称为有效地址(EA),形式地址用(A)表示。
多地址指令每个地址之前都要加寻址特征。 - 在后续的内容中,假设指令字长 = 机器字长 = 存储字长。
假设操作数为3.
直接寻址
- 指令字中的形式地址A就是操作数的真实地址EA,即EA = A。
- 如:LOAD 寻址特征 A
这条指令就是把主存地址为A的数据存到寄存器ACC中。
这条指令的执行共需访存2次:
取指令 访存一次;
执行指令 访存一次。 - 优点:简单,指令执行阶段只需访问一次主存,不需要专门计算操作数的地址。
缺点:A的位数决定了该指令操作数的寻址范围不会很大。而且操作数地址不易修改。
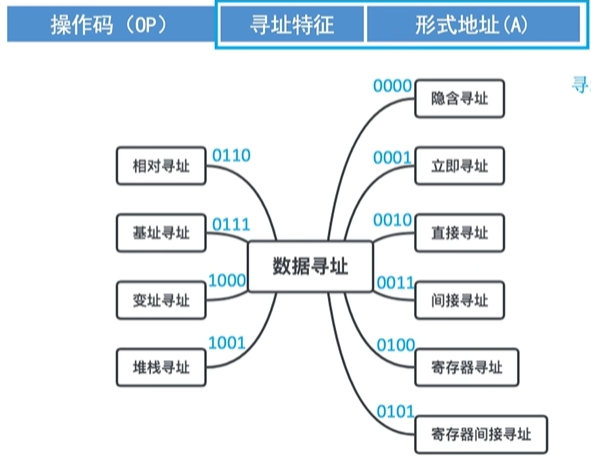
间接寻址
- 间接寻址:指令的地址字段给出的形式地址不是操作数的真正地址,二十操作数有效地址所在的存储单元的地址。也就是操作数地址的地址,即EA = (A)
- 间接寻址示意图(一次间址):
![间接寻址示意图]()
- 不考虑存指令执行结果的情况下,采用一次间址的间接寻址方式,一条指令的执行共访存3次。取指令访存1次,执行指令访存2次。
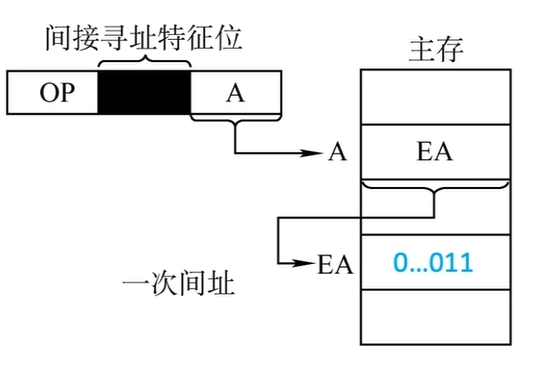
- 间接寻址示意图(两次间址):
![两次间址示意图]()
- 间接寻址的优点:可扩大寻址范围(有效地址的位数可能大于形式地址A的位数)
- 便于编制程序(用间接寻址方式可以方便的完成子程序的返回。)
- 缺点:指令在执行阶段要多次访存,指令的执行效率变低(一次间址需要两次访存,多次寻址需要根据存储字的最高位确定几次访存。)
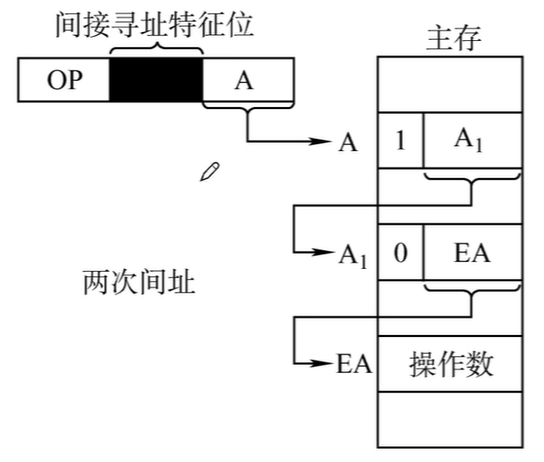
寄存器寻址
- 寄存器寻址:在指令字中直接给出操作数所在的寄存器编号,即\(EA = R_i\),其穿在身上在由\(R_i\)所指的寄存器内。
- 一条指令的执行(不考虑)存结果,共访存1次:取指令访存1次,执行指令访存0次。
- 优点:指令在执行阶段不访问主存,只访问寄存器,指令字短且执行速度快,支持向量和矩阵运算。
- 缺点:寄存器价格昂贵,计算机中寄存器数量有限。
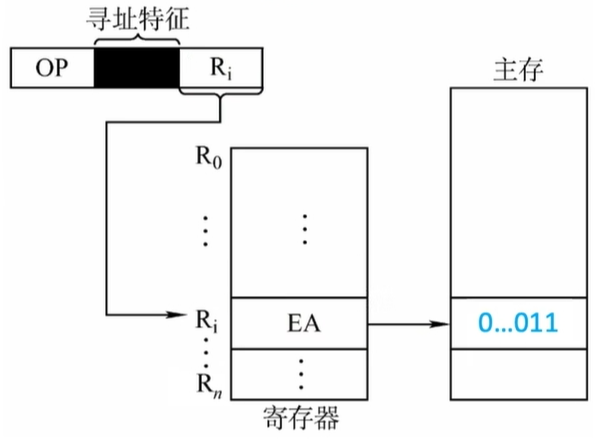
寄存器间接寻址
- 寄存器间接寻址:寄存器\(R_i\)中给出的不是一个操作数,二十操作数所在主存单元的地址,即\(EA = (R_i)\)
- 寄存器间接寻址示意图如下:
![寄存器间接寻址示意图]()
- 不考虑存结果,一条指令的执行需要访存两次:取指令1次,执行指令访存1次。
- 比一般的间接寻址速度更快,但指令的执行阶段需要访问主存(因为操作数在主存中)
隐含寻址
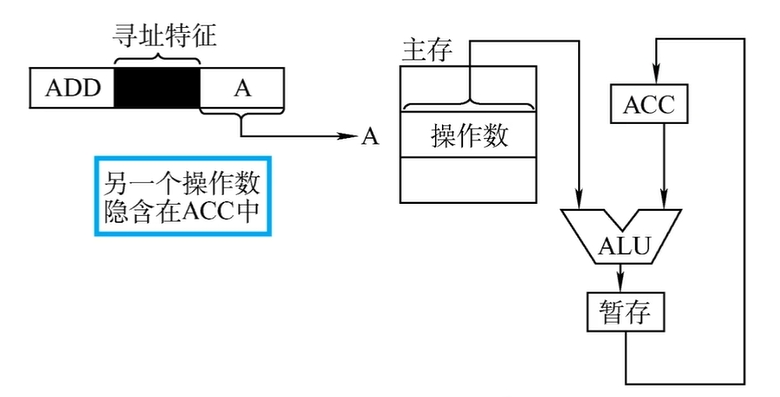
- 隐含寻址:不是明显地给出操作数的地址,而是在指令中隐含着操作数的地址。
- 隐含寻址可以将另一个操作数隐含在ACC中,以ADD指令为例,隐含寻址的示意图如下:
![隐含寻址的示意图]()
- 优点:有利于缩短指令字长
- 缺点:需要增加存储操作数或隐含地址的硬件。
立即寻址
- 立即寻址:形式地址A就是操作数本身,又称为立即数,一般采用补码形式。立即寻址的寻址特征用#表示。
- 不考虑存结果,一条指令的执行共访存1次:取指令1次,执行指令0次。
- 优点:指令执行阶段不访问主存,指令执行时间最短。
- 缺点:A的位数限制了立即数的范围。
如A的位数为n,且立即数采用补码表示,可表示的数据范围为\(-2^{n-1}\)~\(2^{n-1}-1\)
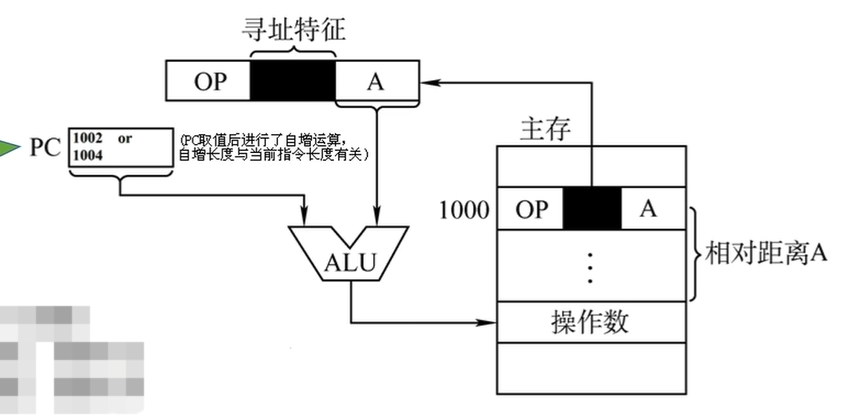
相对寻址
- 属于偏移寻址的一种
- 相对寻址:有效地址是以程序计数器PC所指地址作为“起点”,加上偏移量A。A可正可负,补码表示。
- EA = (PC) + A
- 相对寻址的示意图如下:
![相对寻址的示意图]()
- 注:相对寻址是基于下一条指令的偏移,因为每条指令取出之后PC都会+1,所以(PC) + A相当于在下一条指令的基础上偏移了A。
- 优点:这段代码在程序内浮动时不用更改跳转指令的地址码。相对寻址广泛应用于转移指令。
- 拓展:ACC加法指令的地址码可采用“分段”方式解决,即程序段和数据段分开。
基址寻址
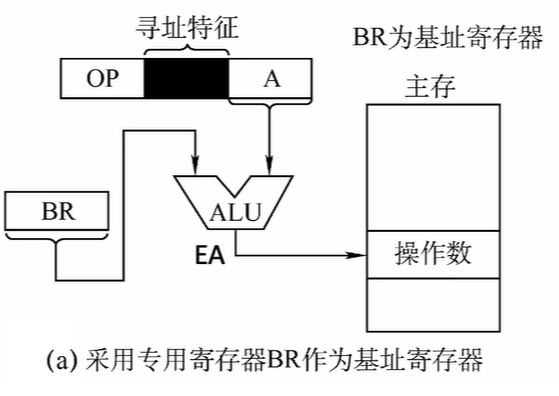
- 属于偏移寻址的一种
- 基址寻址:有效地址是以程序的起始存放地址作为“起点” ,加上偏移量A。将CPU内部基址寄存器(BR,base address register)的内容+指令格式中的形式地址A,而形成操作数的有效地址。
- EA = (BR) + A
- 基址寻址示意图:
![基址寻址示意图]()
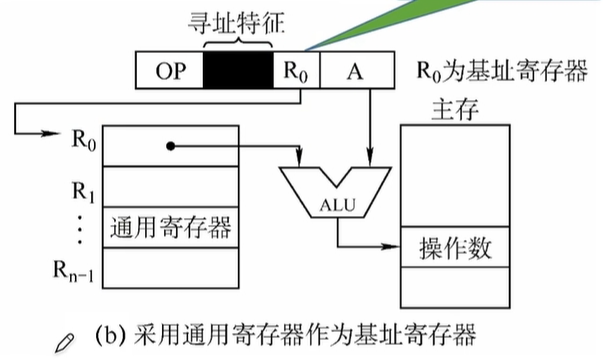
- 当计算机内部没有专用的寄存器BR时,就会采用通用寄存器作为基址寄存器。
这种情况下需要在指令中指明,要将哪个通用寄存器作为基址寄存器使用。示意图如下:
![基址寻址无专用寄存器]()
- 程序运行前,CPU将BR的值修改为该程序的起始地址(存在操作系统PCB中)
- 注:基址寄存器是面向操作系统的,其内容由操作系统或管理程序确定。在程序执行过程中,基址寄存器的内容不变,形式地址可变。当某个通用寄存器被用户指定为基址寄存器后,其内容仍由操作系统确定,用户不可修改。
- 优点:便于程序“浮动”,方便实现多道程序并发运行。可扩大寻址范围,用户不必考虑自己的程序存在主存的哪个位置。
变址寻址
- 属于偏移寻址的一种
- 变址寻址:有效地址是以程序员自己决定从哪里作为“起点”,加上偏移量A。有效地址EA等于指令字中的形式地址A与变址寄存器IX的内容之和,EA = (IX) + A,其中IX为变址寄存器(专用),也可用通用寄存器作为变址寄存器。
- 注:基址寻址和变址寻址的区别是:变址寄存器是面向用户的,在程序执行过程中,变址寄存器的内容可由用户改变。变址寻址过程中,IX一般被视作偏移量,形式地址A不变(作为基地址)
- 优点:在处理数组元素时,可设定A为数组首地址,不断改变变址寄存器IX的内容,便可很容易形成数组中任意数据的地址,特别适合编制循环程序。
- 实际应用中往往需要多种寻址方式复合使用(可理解为复合函数)
堆栈寻址
- 堆栈寻址:操作数存放在堆栈中,隐含使用堆栈指针(SP,stack pointer)作为操作数地址。
- 堆栈是存储器(或专用寄存器组)中一块特定的按“后进先出(LIFO)”原则管理的存储区,该存储区中被读/写单元的堆栈是用一个特定的寄存器给出的,该寄存器称为堆栈指针。
- 入栈/出栈时EA的确定方式不同。
出栈时SP指向EA,入栈的时候先要把(SP)+1,之后的地址才是要写入的地址 - 硬堆栈用寄存器实现,在指令执行期间不访存,软堆栈用主存实现,在指令执行期间访存1次。
扩展:硬件如何实现数的比较
- 通过cmp指令,比较a和b,实际上就是做a-b
- 相减的结果信息会记录在程序状态字寄存器(PSW)中
PSW中有几个比特位记录上次运算的结果:- 进位/借位标志CF: 最高位有进位/借位时CF = 1
- 零标识ZF:运算结果为0则ZF = 1, 否则ZF = 0.
- 符号标志SF: 运算结果为负,SF = 1,否则为0
- 溢出标志OF: 运算结果有溢出OF = 1, 否则为0.
- 根据PSW的某几个标志位进行条件判断,来决定是否转移。
4.3.1 高级语言与机器代码之间的对应
机器语言和汇编语言都是机器级代码
考试要求
- 只需关注x86汇编语言;
- 题目若给出某段简单程序的C语言、汇编语言、机器语言表示。能结合C语言看懂汇编语言的关键语句(常见指令、选择结构、循环结构、函数调用)
- 汇编语言、机器语言一一对应,要能结合汇编语言分析机器语言指令的格式、寻址方式
- 不会考:将C语言人工翻译为汇编语言或机器语言。
汇编语言基础知识
x86汇编语言指令基础
- 指令的作用:处理数据 和 改变程序执行流
- 对于处理数据功能:
指令格式 = 操作码 + 地址码
操作码决定怎么处理数据
地址码决定数据在哪(寄存器,主存或者指令里) - 以mov指令为例:
mov 目的操作数d(destination), 源操作数s(source)
mov指令功能:将源操作数s复制到目的的操作数d所指的位置。
mov eax, ebx #将寄存器ebx的值复制到寄存器eax中
mov eax, 5 #将立即数5复制到寄存器eax中
mov eax, dword ptr[af996h] #将内存地址af996h所指的32bit值复制到寄存器eax中
mov byte ptr[af996h], 5 #将立即数5复制到内存地址af996h所指的一字节中
- 如何指明内存的读写长度?
- dword ptr —— 双字,32bit
- word ptr —— 单字,16bit
- byte ptr —— 字节,8bit
- x86架构CPU有哪些寄存器?
x86寄存器以E开头都表示32位。如果把E去掉,表示使用寄存器的低16位。
AX = AH + AL, BX = BH + BL ...
AL是寄存器低8位,AH是寄存器9~16位。- 通用寄存器(X = 存放内容未知,E = Extended = 32bit):
EAX EBX ECX EDX - 变址寄存器(I = Index, S = Source, D = Destination):
ESI EDI
用来处理线性表和字符串。 - 堆栈基指针(Base Pointer):
EBP - 堆栈顶指针(Stack Pointer):
ESP
- 通用寄存器(X = 存放内容未知,E = Extended = 32bit):
- 更多例子:
mov eax, dword ptr[ebx] #将ebx所指主存地址的32bit复制到eax寄存器中
mov dword ptr[ebx], eax #将eax的内容复制到ebx所指主存地址的32bit
mov eax, byte ptr[ebx] #将ebx所指的主存地址的8bit复制到eax
mov eax, [ebx] #若未指明主存读写长度,默认32bit
mov [af996h], eax #将eax的内容复制到af996h所指的地址(未指明长度默认32bit)
mov eax dword ptr[ebx+8] #将ebx+8所指主存地址的32bit复制到eax寄存器中
mov eax, dword ptr[af996h-12h] #将af996-12所指的主存地址的32bit复制到eax寄存器中
常用的x86汇编指令
算术运算指令
下表中的d是目的操作数,s是源操作数。指令的功能是两个操作数运算之后再存回目的操作数的地址里。d可能是寄存器或主存,s可以是立即数、主存、寄存器。
| 功能 | 汇编指令 | 英文 | 注释 |
|---|---|---|---|
| 加 | add d, s | add | #计算d+s, 结果存入d |
| 减 | sub d, s | subtract | #计算d-s, 结果存入d |
| 乘 | mul d, s / imul d, s | multiply | #无符号数d*s, 乘积存入d; #有符号数d*s, 乘积存入d |
| 除 | div s / idiv s | divide | 被除数默认放在edx和eax两个寄存器中。#无符号数除法edx:eax/s, 商存入eax, 余数存入edx; #有符号数除法 |
| 取负数 | neg d | negative | #将d取负数,结果存入d |
| 自增++ | inc d | increase | #将d++, 结果存入d |
| 自减-- | dec d | decrease | #将d--, 结果存入d |
常见逻辑运算指令

其他指令
- 用于实现分支结构、循环结构的指令:cmp、test、jmp、jxxx
- 用于实现函数调用的指令:push、pop、call、ret
- 用于实现数据转移的指令:mov
AT&T格式和Intel格式
AT&T格式通常在Unix、Linux中使用
Intel是Windows的常用格式。
- AT&T格式的Intel格式的区别:
![AT&T格式的Intel格式的区别]()

选择语句的机器级表示
- 无条件跳转指令 —— jmp
由于不能确定每次程序要跳转到哪里,所以jmp后面跟的数字可以用“标号”代替。下面进行举例(第一段代码的行首数字是指令地址):
100 mov eax, 7
104 mov ebx, 6
108 jmp 116
112 mov ecx, ebx
116 mov ecx, eax
上面的代码可以用下面代码代替:
mov eax, 7
mov ebx, 6
jmp NEXT
mov ecx, ebx
NEXT:
mov ecx, eax
- 条件转移指令 —— jxxx
cpm a, b #比较a,b两个数
je <地址> #jump when equal, 若a==b则跳转
jne <地址> #jump when not equal, 若a!=b则跳转
jg <地址> #jump when greater than, 若a>b跳转
jge <地址> #jump when greater than or equal to, 若a>=b跳转
jl <地址> #jump when less than, 若a<b跳转
jle <地址> #jump when less than or equal to, 若a<=b跳转
- 扩展:cmp指令的底层原理
本质上是进行a-b运算,并生成标志位OF、ZF、CF、SF
其中:
OF: 溢出标志
ZF:符号标志
SF:零标志
CF:进位/错位标志
上面的条件转移指令的条件判断依据如下:
cpm a, b #比较a,b两个数
je <地址> #jump when equal, ZF==1?
jne <地址> #jump when not equal, ZF==0?
jg <地址> #jump when greater than, ZF==0 && SF==OF?
jge <地址> #jump when greater than or equal to, SF==OF?
jl <地址> #jump when less than, SF!=OF?
jle <地址> #jump when less than or equal to, SF!=OF || ZF==1?
循环语句的机器级表示
对于下面C语言代码:
int result = 0;
int i = 1;
while(i <= 100) {
result += i;
i++;
}
编译成汇编语言如下:
mov eax, 0 #eax保存result,初值为0
mov edx, 1 #edx保存i, 初值为1
cmp edx, 100 #比较i和100
jg L2 #若i > 100, 跳转到L2执行
L1: #循环主体
add eax, edx #实现result += i
inc edx #inc 自增指令,实现i++
cmp edx, 100 #比较i和100
jle L1 #若i<=100, 跳转到L1执行
L2: #跳出循环主体
- 总结:用条件转移指令实现循环,需要4个部分构成:
- 循环前的初始化
- 是否直接跳过循环?
- 循环主体
- 是否继续循环?
- 还可以用loop指令实现循环,代码如下:
for(int i = 500; i > 0; i--) {
做某些处理
}
对应汇编语言如下:
mov ecx, 500 #用ecx作为循环计数器
Looptop: #循环开始
...
做某些处理
...
loop Looptop #ecx--, 若ecx!=0, 跳转到Looptop
理论上,能用loop指令实现的功能一定能用条件转移指令实现
使用loop指令可能会使代码更清晰简洁
Call和ret指令
- 函数调用的机器级表示
- 以下面函数调用为例:
在函数调用的过程中,系统会给函数分配一片内存区域,称为函数调用栈。栈底保存一些关于硬件和系统的信息,每一个程序都是从main函数进入的,所以在硬件和系统信息之上存放main的栈帧(保存函数大括号以内定义的局部变量、保存函数调用相关信息),main()中调用了P函数,所以main的栈帧上面有P的栈帧。P()中调用了Q(), 再把Q的栈帧压入函数调用栈,Q()执行结束后,Q的栈帧将从栈顶删除,P()又调用了caller函数,再把caller的栈帧压栈。caller函数大括号内定义了temp1、temp2和sum这三个变量,这些变量就存放在Caller的栈帧里。caller调用了add函数,add函数的栈帧压入栈顶。add函数执行完毕后出栈,当前执行的函数(caller)栈帧位于栈顶。后面逐渐执行,每个函数的栈帧依次出栈。
void main() {
...
P();
...
return;
}
void P() {
...
Q();
...
caller();
...
return;
}
void Q() {
...
return;
}
int caller() {
int temp1 = 125;
int temp2 = 80;
int sum = add(temp1, temp2);
return sum;
}
int add(int x, int y) {
return x+y;
}
- x86汇编语言的函数调用
caller和add的函数汇编代码如下:
caller:
push edp
mov ebp, esp
sub esp, 24
mov [ebp-12], 125
mov [ebp-8], 80
mov eax, [ebp-8]
mov [esp+4], eax
mov eax, [ebp-12]
mov esp, eax
call add
mov [ebp-4], eax
mov eax, [ebp-4]
leave
ret
add:
push ebp
mov ebp, esp
mov eax, [ebp+12]
mov edx, [ebp+8]
add eax, edx
leave
ret
汇编语言中,会用call和ret指令实现函数的调用。
通常用函数名作为函数起始地址的标号。
- call指令的作用:
- 将IP(PC)旧值压栈保存(保存在函数的栈帧顶部)
- 设置IP新值,无条件转移至被调用函数的第一条指令。
- ret指令的作用:
从函数栈帧的顶部找到IP旧值,将其出栈并恢复IP寄存器。
如何访问栈帧
- 函数调用的机器级表示
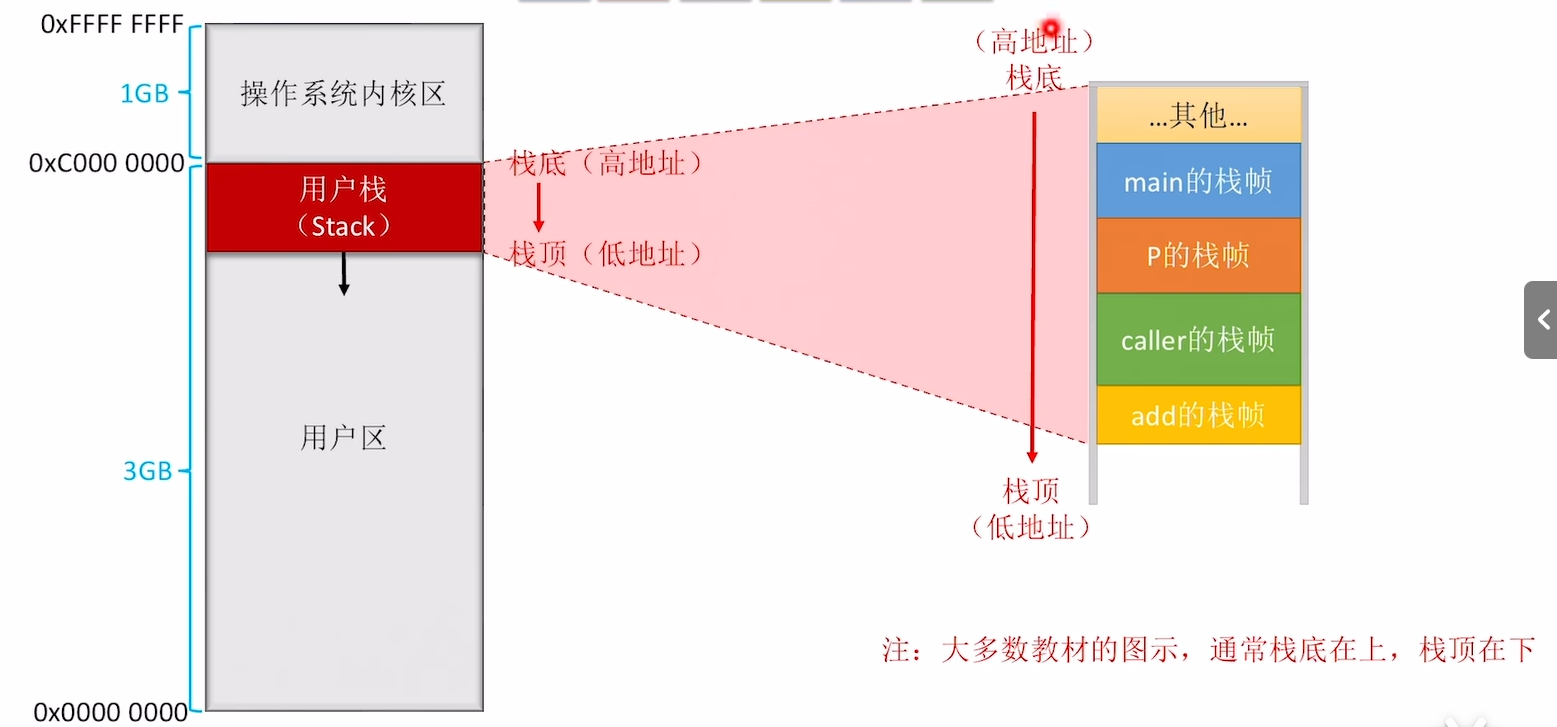
- 为什么函数调用栈在画的时候栈底在上面,栈顶在下面?
![函数调用栈]()
对于一个32位的系统,OS会给每个进程分配4GB的虚拟空间。地址从0x0000 0000到0xFFFF FFFF.高地址的1GB为OD内核曲,低地址的3GB为用户区。函数调用栈在用户区的高地址处,向低地址区延伸。如下图所示:
![4GB的虚拟空间]()
- 标记栈帧范围:EBP、ESP寄存器
寄存器EBP是堆栈基指针,指向栈顶的函数栈帧的底部,ESP是堆栈顶指针,指向栈顶。 - 访问栈帧数据:push和pop指令
push和pop指令实现入栈、出栈操作,x86默认以4字节为单位。
push X #先让ESP-4,再将X压入
pop Y #栈顶元素出栈写入Y,再让ESP+4
注:X可以是立即数、寄存器、主存地址
Y可以是寄存器、主存地址 - 访问栈帧数据:mov指令
通过sub和add指令改变栈顶指针的指向,用mov把栈中元素复制出来或者把别的地方的元素复制到栈里。

如何切换栈帧
- 函数调用的机器级表示
根据caller和add的代码分析:
caller:
push edp
mov ebp, esp
sub esp, 24
mov [ebp-12], 125
mov [ebp-8], 80
mov eax, [ebp-8]
mov [esp+4], eax
mov eax, [ebp-12]
mov esp, eax
call add
mov [ebp-4], eax
mov eax, [ebp-4]
leave
ret
add:
push ebp
mov ebp, esp
mov eax, [ebp+12]
mov edx, [ebp+8]
add eax, edx
leave
ret
caller函数的call语句执行后会把当前的IP值压栈。esp-4, 指向当前IP值。之后跳转到add函数中,add的开始语句是push ebp和mov ebp, esp先把caller函数的ebp压栈,然后把让ebp和esp指向都指向栈顶。每一个函数开头都有这样的指令。保存上一层函数的栈帧基址,并设置当前函数的栈帧基址。
push ebp和mov ebp, esp这两条汇编指令也可以合起来叫enter。
函数返回时如何切换栈帧?
mov esp, ebp #让esp指向当前栈帧的底部
pop ebp #将esp所指元素出栈,写入寄存器ebp
这两条指令可以用leave代替。
ret指令的作用:从函数的栈帧顶部找到IP旧值,将其出栈并恢复IP寄存器。
如何传递参数和返回值
- 函数调用的机器级表示
- 一个函数的栈帧内部可能包含哪些内容?
- 栈帧最底部保存上一层栈帧基址(ebp旧值)
- 栈帧最顶部一定是返回地址(当前函数的栈帧除外)
- 通常将局部变量集中存储在栈帧底部区域。
C语言中越靠前定义的局部变量越靠近栈顶。 - 通常将调用参数集中存储在栈帧顶部区域。
参数列表中越靠前的参数越靠近栈顶。 - gcc编译器将每个栈帧大小设置为16B的整数倍(当前函数的栈帧除外),所以栈帧内可能出现空闲未使用的区域。
- 所以在调用函数传参的时候需要先将参数的值存到栈帧顶部的区域。
- 内层函数给外层函数返回值的时候通过eax寄存器,先将返回值存到eax寄存器中,然后再将eax寄存器里的值复制到外层函数的对应位置。
- 如果调用者用到了一些寄存器,被调用的函数也可能用到,则可以把这些寄存器压栈保存,等被调函数返回后再出栈还原。所以函数调用栈可能还有一部分区域用于保存一些寄存器的值。
4.4 CISC和RISC
CISC
CISC:Complex Instruction Set Computer 复杂指令集的计算机系统
设计思路:一条指令完成一个复杂的基本功能
代表:x86架构,主要用于笔记本、台式机等。
RISC
RISC: Reduced Instruction Set Computer 精简指令集的计算机系统
设计思路:一条指令完成一个基本“动作”;多条指令组合完成一个复杂的基本功能,语句相对简单,便于实现“并行”、“流水线”
代表:ARM架构,主要用于手机、平板等
CISC和RISC的对比
| 对比项目 | CISC | RISC |
|---|---|---|
| 指令系统 | 复杂、庞大 | 简单、精简 |
| 指令数目 | 一般大于200条 | 一般少于100条 |
| 指令字长 | 不固定 | 定长 |
| 可访存指令 | 不加限制 | 只有Load/Store指令 |
| 各种指令执行时间 | 相差较大 | 绝大多数在一个周期内完成 |
| 各种指令使用频度 | 相差很大 | 都比较常用 |
| 通用寄存器数量 | 较少 | 多 |
| 目标代码 | 难以用优化编译生成高效的目标代码程序 | 采用优化的编译程序,生成代码较为高效 |
| 控制方式 | 绝大多数为微程序控制 | 绝大多数为组合逻辑控制 |
| 指令流水线 | 可以通过一定方式实现 | 必须实现 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号