python字符编码
1 字符编码原理
计算机只能表示数字,不能表示文本,所以要表示文本,就要把文本转化为数字。最早的计算机用8个位(bit)来表示一个字节(bytes),一个字节最多就能表示的最大整数就是255。两个字节能表示就是65535.
在原本的英文编码设计中,一共127个字符编码,一个字母表示一个数字,比如A的数字就是65。这就是ASCII编码。因为在设计时,只设计了127个字符编码,包含大小写字母和一些特殊字符,所以一个字节就能表示所有的编码。
但到了中文这里,文本的数量显然不是255个够用的。所以需要用两个字节来存储一个中文字符。这就是GB2312字符编码,包括中文字符编码,同时ASCII中的编码对应表依然存在。后又出现gbk中文编码。
由于语言众多,在不同的编码中,虽然都兼容ASCII编码,但其他的,一样的数字可能对应不同的文本字符。所以计算机在做数字-文本转换时,如果编码不对,就找不到正确的文本,就会出现乱码。
unicode(万国码)就是各国语言文本编码的大集合,将所有语言都编码进去。在常用的标准中,也是用连个字节表示一个文本字符。
unicode在表示英文ascii编码时,就在原有的一个字节前面补一个0000 0000 字节。这样就浪费了一倍的存储空间。uft-8就是将unicode转化成可变长编码,把英文字符编码成一个字节,中文3个字节。
现在计算机中字符编码的工作方式是:在内存中使用unicode,在传输和存储时,转化为utf-8节省带宽和容量。
2 python3中的字符编码
python3中最重要的新特性就是对字符数据和二进制数据作了明确的区分。文本总是str数据类型,在内存中用unicode表示。二进制则直接用bytes数据类型,一个字符用一个字节存储。
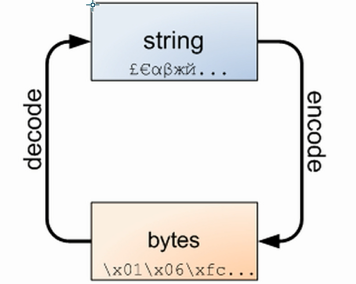
字符串(unicode)可以编码(encode)成字节包(bytes),字节包也可以解码(decode)成字符串。
decode:有些场景下,应用无法处理二进制数据,必须先解码成字符串。
encode:在python2中socket网络传输可以以字符串传输。python3中必须以二进制传输。如果我要请求一个网址,必须把这个网址以二进制传过去。
>>> '信息'.encode('utf-8')
b'\xe4\xbf\xa1\xe6\x81\xaf'
>>> '信息'.encode()
b'\xe4\xbf\xa1\xe6\x81\xaf'
>>> b'\xe4\xbf\xa1\xe6\x81\xaf'.decode()
'信息'
>>> b'\xe4\xbf\xa1\xe6\x81\xaf'.decode('utf-8')
'信息'
#str编码成bytes,然后告诉encode函数str的编码格式为utf-8.(缺省值为utf-8)
#bytes解码成str,告诉decode解码格式为utf-8(缺省值为utf-8)
字符串写入数据库出现乱码时,可以尝试先encode成bytes,然后再解码成unicode或者utf-8。不行就换个编码试试。
#--------------中文字符编码函数------------
def ecoding(chars):
return chars.encode('gbk').decode('unicode_escape')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号