hadoop安装
一,设置SSH
1> 下载ssh:yum install sshl
2> 安装SSH:ssh-keygen -t rsa 四次回车
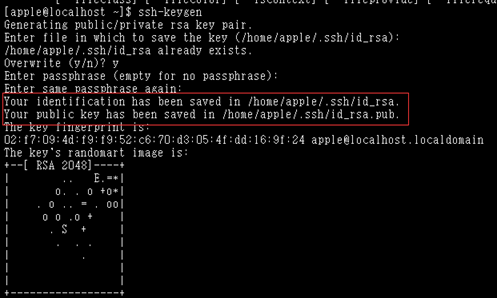
1> 查看:主目录下 ls -al
2> 进入:~cd .ssh
3> 创建: touch文件authorized_keys
4> 将公钥文件复制成authorized_keys文件:
cat id_rsa.pub >> authorized_keys
5> 修改authorized_keys 权限: 修改:chmod 600 authorized_keys
6> 修改sshd_config
root用户登录后,修改/etc/ssh/sshd_config:
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile .ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)
7> 测试
ssh Hadoop(localhost )配置成功后无需密码即可登录

备注:首次无密码登录时,会提示你是否要连接,输入yes,以后登陆不会儿再提示
8> 开启SSH服务
开启service sshd start 或/etc/init.d/sshd start
重启service sshd restart
二,安装jdk
1> 下载linux版的JDK并解压
直接:tar -zxvf jdk1.xxxx
2> 赋予JDK运行的权限
chmod 777 /home/hadoop/jdk1.8.0_144/bin/*
chmod 777 /home/hadoop/jdk1.8.0_144/lib/*
3> root用户打开/etc/profile,添加如下信息:
export JAVA_HOME=/home/hadoop/jdk1.8.0_144
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
4> 执行source /etc/profile 使修改生效
5> 检测JDK环境
执行 java -version ,查看结果,如出现如下提示,则说明JDK已成功配置:

三,安装hadoop
一,安装hadoop
- 解压hadoop-2.8.1到/home/hadoop目录下:tar -zxvf
- 在/home/hadoop/hadoop-2.8.1下创建目录:hdfs
- 配置:/home/hadoop/hadoop-2.8.1/etc/hadoop目录下的hadoop-env.sh文件:
export JAVA_HOME=/home/hadoop/jdk1.8.0_144
export HADOOP_PID_DIR=/home/hadoop/hadoop-2.8.1/hdfs/tmp
配置:/home/hadoop/hadoop-2.8.1/etc/hadoop目录下的mapred-env.sh文件:
export HADOOP_PID_DIR=/home/hadoop/hadoop-2.8.1/hdfs/tmp
配置: /home/hadoop/hadoop-2.8.1/etc/hadoop目录下的yarn-env.sh文件:
export YARN_PID_DIR=/home/hadoop/hadoop-2.8.1/hdfs/tmp
配置环境变量
root用户打开/etc/profile,添加如下信息:
export HADOOP_HOME=/home/hadoop/hadoop-2.8.1
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/sbin:$PATH
执行source /etc/profile 使修改生效
配置core-site.xml
~/etc/hadoop/core-site.xml添加以下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.8.1/tmp</value>
</property>
</configuration>
说明:master1为你namenode节点的服务名,就是你在network中配置的 HOSTNAME。
配置hdfs-site.xml
~/etc/hadoop/hdfs-site.xml添加以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/jdk1.8.0_144/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>file:/home/hadoop/jdk1.8.0_144/hdfs/data</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
配置mapred-site.xml
mapred-site.xml.template改为mapred-site.xml,添加以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置yarn-site.xml
~/etc/hadoop/yarn-site.xml添加以下内容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
配置slaves
添加所有slaves节点名称:hadoop
配置: hadoop相关环境变量,配置~/.bash_profile文件
进入:Vi ~/.bash_profile
添加:
##JDK
export JAVA_HOME=/home/hadoop/jdk1.8.0_144
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
##HADOOP
export HADOOP_HOME=/home/hadoop/hadoop-2.8.1
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_HDFS_HOME=$HADOOP_HOME
- 全部保存:source ~/.bash_profile
- 查看是否安装成功:hadoop version.
二,启动hadoop
1,格式化hadoop命令: hadoop namenode -format
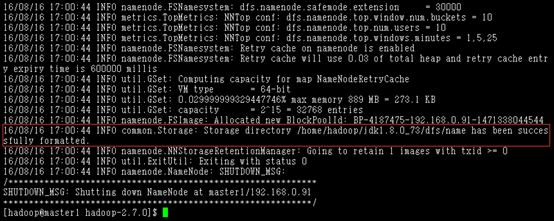
出现has been successfully formatted表示格式化完成。
注意:格式化命令往往只用于初次部署和需要重置集群时使用,它会清除hdfs上所有数据,请注意。
- 启动hadoop
在master机器上,进入hadoop主目录,运行hadoop启动命令:
cd /home/hadoop/hadoop-2.8.1
sbin/start-all.sh
启动成功后,在master上运行jps命令,可以查看到ResourceManager、SecondaryNameNode和NameNode三个进程
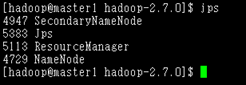
启动MapReduce JobHistory Server服务:
在namenode上执行命令: mr-jobhistory-daemon.sh start historyserver
在各个slave上,运行jps,可以查看到DataNode和NodeManager两个进程
访问job监控页面:http://hadoopip:8088/
访问namenode监控页面:http://master1ip:50070/
2.停止hadoop服务
在master机器上,进入hadoop主目录,运行hadoop停止命令:
cd /home/hadoop/hadoop-2.7.0
sbin/stop-all.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号