风控模型指标全解:KS、LIFT、GINI等
实习接触到的数据大多来自于金融公司,这类模型关注风险,目的是降低风险而使得在风险和收益的博弈中最大化利润。模型评价指标不局限于准确率等常规指标,往往引入了更复杂的指标衡量模型的效果。以下介绍风控场景下常见的模型评价指标。
数据含义
模型处理的数据是客户的身份信息(性别、年龄、教育程度等)、存款情况、交易行为等信息。原始数据标签一般为二分类,其中0代表好客户,1代表坏客户。建模时最常用到逻辑回归,模型预测这个客户是坏的概率(如表示信用不良、贷款逾期等)。
风控场景下关注的模型指标包括但不限于以下表格:

其中统计学/机器学习中通用的概念,如混淆矩阵、AUC,ROC等不再赘述。
KS值
定义:
KS全称Kolmogorov-Smirnov,是信用评分和其他很多学科中常见的统计量,用于衡量模型对正负样本的区分度。KS值为累计坏人占比与累计好人占比的差值绝对值的最大值。
KS检验:比较频率分布f(x)与理论分布g(x)或两个观测值分布的是否一致检验方法,原假设两个数据分布一致或数据符合理论分布,统计量D=max|f(x)−g(x)|。
计算方式:
与ROC曲线类似,我们可以将累计坏人占比与累计好人看作不同阈值下的TPR和FPR,则
取值说明:
- KS<0.2 模型的区分能力不高,价值不大;
- 0.2<=KS<0.4 一般金融机构开发的评分模型KS大部分都集中在这个区间内,模型具备一定的区分能力和使用价值,此时可以结合其他指标继续观察调优模型;
- 0.4<=KS<=0.7 模型区分能力比较好,模型有应用价值;
- KS>0.7 模型好的难以令人置信,可能在变量中加入了业务目标衍生指标,需要对模型特征工程进行排查。
根据KS,可以选择对应阈值作为分界,最大化过滤坏人比例。

LIFT提升度
定义:
模型对坏样本的预测能力相比随机选择的倍数,当LIFT>1则说明模型表现优于随机选择。
计算方式:
将样本划分多个桶/组/区间,计算每个区间内样本的坏样本率与整体坏样本率的比值。
通常将模型的输出信用评分以bucket=10相等分位数(quantile)分箱,按照从低到高排序(违约概率从高到低),计算累计坏样本占比与累计总样本占比的比值。如下表,其中
%Bad = 当前行#Bad / sum(#Bad)
%CumBad = 上一行%Bad + 上一行%CumBad
LIFT = %Bad / %CumBad

第一行 LIFT=4.1013表示,我们使用这个模型相比随机选择对坏样本的预测能力提升的倍数。比如对于金融应用中的贷款场景,如果直接不加筛选,10000人中可能遇到100个坏客户;我们选择大于655信用分作为放贷条件阈值,则模型选择的10000个客户中可能只有60个坏客户。模型虽然不能完全过滤全部坏客户,但能坏客户的比例,从而降低风险。
以toad库提供的KS_bucket函数为例:
该函数实现的源码可见toad/metrics.py,从源码上可以看到,计算lift使用
agg2['lift'] = agg2['bad_prop'] / agg2['total_prop'],即下表中 bad_prop 与 total_prop 比值。与前面定义稍有不同,计算的bad_prop并不是累计值,因此得到的lift为每一组内的提升值。其中
bad_rate = 每一组bads / 每一组总数
odds = 每一组bads / 每一组goods
bad_prop = 每一组bads / 所有bads总数
lift = bad_prop / total_prop(每一组总数占全部比例)
而 cum_lift 的结果与上面的定义一致。
reverse_suffix = '_rev' (或为空,根据ks调整)
agg2['cum_lift'] = agg2['cum_bads_prop' + reverse_suffix] / agg2['cum_total_prop' + reverse_suffix]

Gini
Gini系数与洛伦兹曲线有关。在经济学中,洛伦兹曲线(Lorenz curve)是指收入或财富的分布曲线,其中横轴为累计人数占比(由低收入到高收入),纵轴为累计财富占比。
在绝对公平(perfect equality)的条件下,所有人收入一致,那么曲线为 Y=X。Gini系数定义为下图中 A 的面积与Y=X曲线下面积(A+B)的比值。
Gini系数越大,分布越不平衡。另一个极端是,Y=0%,当前仅当 X=100% 时 Y=100%。即一个人拥有全部的财富,而其他人无收入,Gini系数为1,达到perfect inequality。
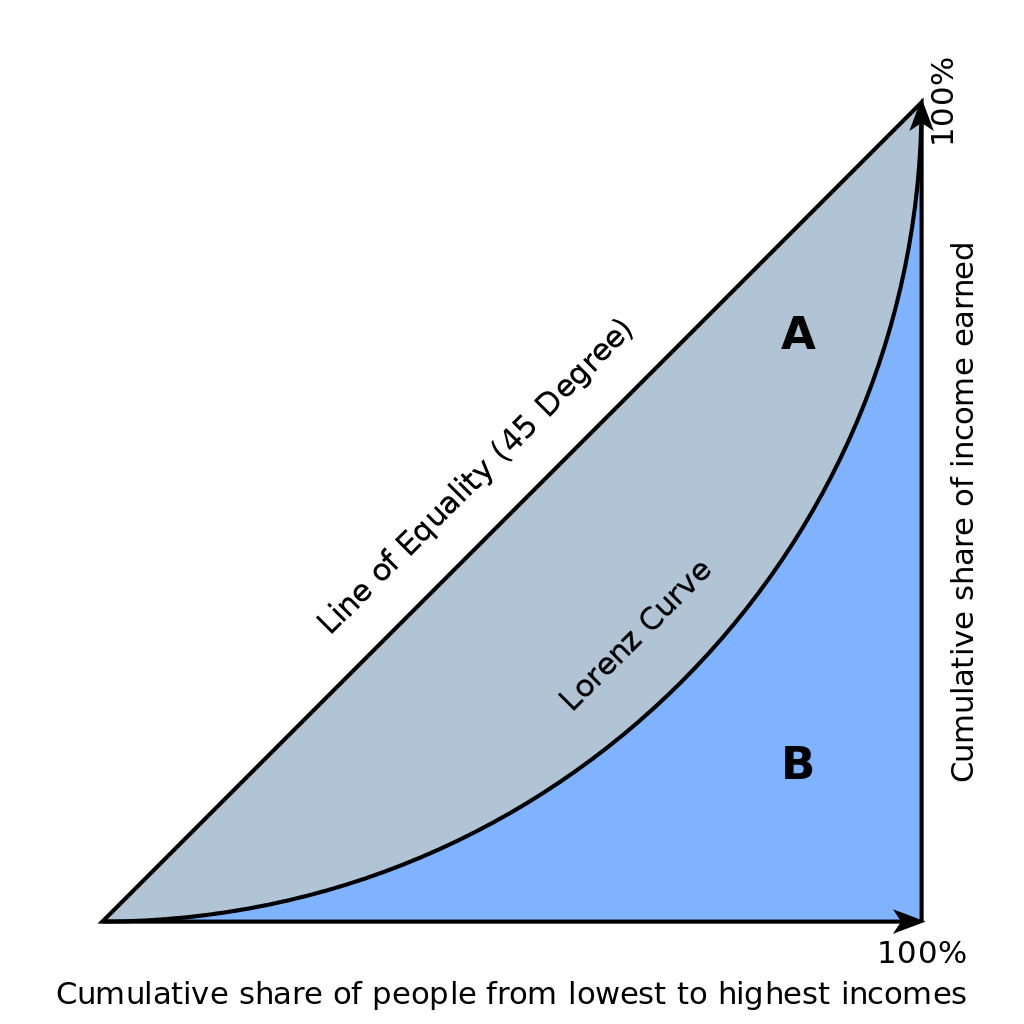
在风控场景下,类似的,定义洛伦兹曲线的横坐标为累计样本占比,纵坐标为累计坏样本占比。
设基于某个累计阈值点的样本预测为坏样本,此时预测正确的样本数为TP,预测错误的样本数为FP,样本总数为TP+FP。
当负样本很少时,TP和FN的值很小,可忽略不计,则累计样本占比=FP/(FP+TN)=FPR。此时,洛伦兹曲线与ROC曲线的横纵坐标取值基本一致。
参考资料
指标表格:风控领域常用评估指标:ROC/AUC、KS、Gain、Lift等 - penny618 - 博客园 (cnblogs.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号