Meta最新语言模型LLaMA解读 | Meta版ChatGPT
LLaMA模型调研
1 模型介绍
LLaMA是Facebook AI Research团队于2023年发布的一种语言模型,这是一个基础语言模型的集合,参数范围从7B到65B。该工作表明可以使用公开可用的数据集来训练最先进的模型,而不依赖于专有的和不可访问的数据集。
1.1 数据来源
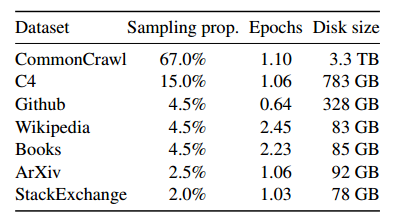
训练数据集是几个来源的混合,如下表所示,涵盖了一组不同的领域。
-
英语CommonCrawl[67%]。预处理了五个CommonCrawl转储,使用CCNet管道在行级重复删除数据,使用fastText线性分类器执行语言识别以删除非英语页面,并使用ngram语言模型过滤低质量内容。
-
C4(15%)。在探索性实验中,观察到使用不同的预处理CommonCrawl数据集可以提高性能。因此,在数据中包括了公开可用的C4数据集(Raffel et al, 2020)。C4的预处理还包含重复数据删除和语言识别步骤:与CCNet的主要区别是质量过滤,它主要依赖于启发式,如标点符号的存在或网页中单词和句子的数量。
-
Github(4.5%)。使用谷歌BigQuery上提供的公共GitHub数据集。只保留Apache、BSD和MIT许可下发布的项目。此外,使用基于行长或字母数字字符比例的启发式过滤低质量文件,并使用正则表达式删除样板文件,如标题。最后,在文件级使用精确匹配的方法对结果数据集进行重复数据删除。
-
维基百科(4.5%)。添加了从2022年6月至8月期间的维基百科转储,涵盖20种语言。处理数据以删除超链接、评论和其他格式样板。
-
图书[4.5%]。在训练数据集中包括两个图书语料库:古腾堡项目,其中包含公共领域的书籍,以及ThePile (Gao et al, 2020)的Books3部分,这是一个用于训练大型语言模型的公开数据集。在图书级别执行重复数据删除,删除内容重叠超过90%的图书。
-
ArXiv[2.5%]。处理arXiv Latex文件,将科学数据添加到数据集。继Lewkowycz等人(2022)之后,删除了第一部分之前的所有内容,以及参考书目。还删除了.tex文件中的注释,以及用户编写的内联扩展定义和宏,以增加论文之间的一致性。
-
StackExchange[2%]。包括Stack Exchange的转储,这是一个高质量的问题和答案的网站,涵盖了从计算机科学到化学的各种领域。保留了来自28个最大网站的数据,删除了文本中的HTML标签,并根据分数(从最高到最低)对答案进行排序。
Tokenizer:使用字节对编码(BPE)算法对数据进行标记,使用来自SentencePiece的实现。
总的来说,整个训练数据集在标记化后大约包含1.4T token。对于大多数训练数据,每个token在训练期间只使用一次,Wikipedia和Books域除外,在这两个域上执行大约两个epoch。
1.2 网络结构
该模型用的Transformer作为decoder,在结构上它与GPT是非常类似的。
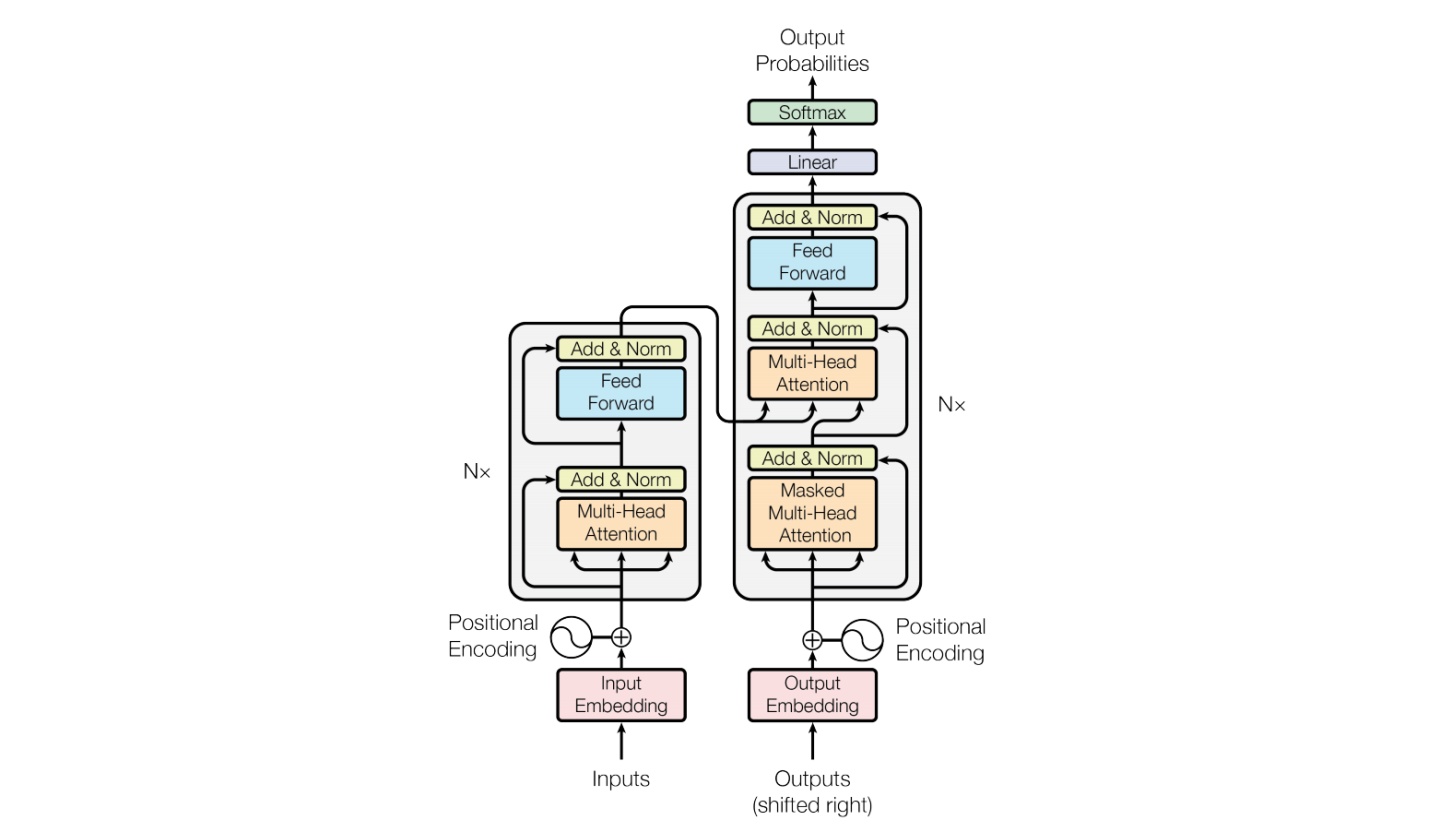
LLaMA的SA与原始Attention区别:
- 旋转嵌入式[GPTNeo]。去掉了绝对位置嵌入,取而代之的是在网络的每一层添加由Su等人(2021)引入的旋转位置嵌入(RoPE)。经过RoPE得到64个特征维度,将它融合到每个Attention head的64个特征中。reshape之后,将位置信息融入query和key中。
- 其中有一个细节就是缓存机制,这个机制在模型的训练过程中其实是不发挥作用的,它设计的目的是在generate时减少token的重复计算。

LLaMA的FFN改进:
-
SwiGLU激活函数[PaLM]。用Shazeer(2020)引入的SwiGLU激活函数来取代ReLU非线性,以提高性能。使用的维度是2/3 4d,而不是PaLM中的4d。
-
与常见模型中的FFN对比,BART中的FFN,用的是
fc->act->fc,用了两层全连接;GPT中的FFN,用的是conv1D->act->conv1D,也是只用了两层;而LLaMA中的FFN采用了三个全连接层以实现FFNSwiGLU,即
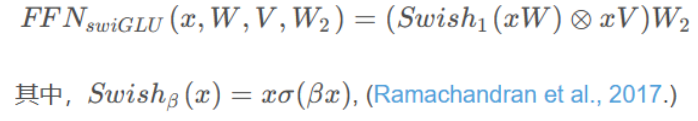
forward部分,输入是token,先做token embedding,然后添加位置信息。对于decoder模型,为了防止标签泄漏,需要mask,所以做了一个上三角的mask矩阵。接下来就是逐层的计算Transformer。
LLaMA的Transformer改进
- 预规范化[GPT3]。为了提高训练的稳定性,将每个Transformer子层的输入归一化,而不是输出归一化。使用由Zhang和Sennrich(2019)引入的RMSNorm归一化函数。
- RMS Norm(Root Mean Square Layer Normalization),是一般LayerNorm的一种变体,可以在梯度下降时令损失更加平滑。与layerNorm相比,RMS Norm的主要区别在于去掉了减去均值的部分(re-centering),只保留方差部分(re-scaling)。

输入是token,先做token embedding,然后添加位置信息。对于decoder模型,为了防止标签泄漏,需要mask,所以做了一个上三角的mask矩阵。接下来就是逐层的计算transformer。根据不同规模的模型,堆叠不同层数的transformerBlock。
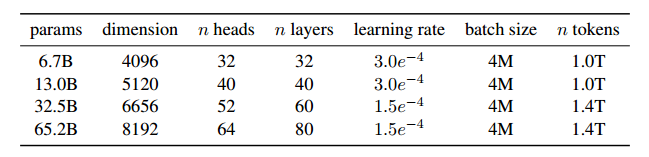
下表给出了不同模型的超参数的详细信息。
模型的Generator
- 对prompts进行tokenize,得到token ids;
- 计算当前batch的最大长度total_len,用来创建输入的token tensor,最大长度不能超过前文所述缓存的大小;
- 从当前batch中,最短的一个prompt的位置,作为生成的开始位置,开始生成;
- 输入的token tensor传入Transformer模型,计算logits,得到形状为(batch_size, hidden_size)的logits(transformer最后一层的输出);
- softmax+top_p采样,得到当前预测的token,并更新当前位置,准备预测下一个token;
- 解码得到生成的文本。
2 模型训练
模型的训练方法类似于之前工作中描述的方法(Brown et al, 2020;Chowdhery等人,2022),使用标准优化器在大量文本数据上训练大型Transformer。模型使用AdamW优化器(Loshchilov和Hutter, 2017)进行训练,具有以下超参数:β1 = 0.9, β2 = 0.95。
使用余弦学习率计划,这样最终的学习率等于最大学习率的10%。使用0.1的权重衰减和1.0的梯度裁剪。使用2000个热身步骤,并根据模型的大小改变学习率和批处理大小(如上表)。
做了一些优化来提高模型的训练速度。
1)首先,使用一个有效的实现的因果多头注意,以减少内存使用和运行时。该实现可在xformers库中获得,并使用了Dao等人(2022)的逆向方法。这是通过不存储注意力权重和不计算由于语言建模任务的因果性质而被掩盖的关键字/查询分数来实现的。
2)为了进一步提高训练效率,减少了使用检查点向后传递期间重新计算的激活量。更准确地说,节省了计算成本高昂的激活,例如线性层的输出。这是通过手动实现转换器层的向后函数来实现的,而不是依赖于PyTorch autograd。
3)为了充分从这种优化中受益,需要通过使用模型和序列并行性来减少模型的内存使用,如Korthikanti等人(2022)所述。此外,还尽可能地重叠了激活的计算和gpu之间的网络通信(由于all_reduce操作)。
在训练65B参数模型时,代码在2048 A100 GPU和80GB RAM上处理大约380个token/秒/GPU。这意味着对包含1.4T token的数据集进行训练大约需要21天。
3 模型部署
3.1 环境设置
在pytorch/cuda可用的conda-env中,运行:
pip install -r requirements.txt
然后在本项目下:
pip install -e .
3.2 下载模型
申请获得批准后,将收到下载 tokenizer 和模型文件的链接。使用电子邮件中提供的签名 url 编辑download.sh脚本,下载模型权重和 tokenizer 。
3.3 模型推理
提供的example.py可以在带有torchrun的单个或多个gpu节点上运行,并将输出两个预定义的prompts。
使用download.sh中定义的TARGET_FOLDER:
torchrun --nproc_per_node MP example.py --ckpt_dir $TARGET_FOLDER/model_size --tokenizer_path $TARGET_FOLDER/tokenizer.model
其中 MP 值由不同的模型所定义,如下表:
| Model | MP |
|---|---|
| 7B | 1 |
| 13B | 2 |
| 33B | 4 |
| 65B | 8 |
4 参考资料
论文链接: https://arxiv.org/abs/2302.13971
半开源地址:https://github.com/facebookresearch/llama
已泄露模型:https://huggingface.co/decapoda-research/llama-13b-hf 或者 https://rentry.org/llama-tard-v2
参考模型解读:Meta最新模型LLaMA细节与代码详解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号